性能测试知识问题整理(三)
续上一篇《性能测试知识问题整理(二)》
二十一、Ramp-up配置有什么作用?为什么压力工具中TPS和响应时间曲线抖动过大不易于分析?
问题一:Jmeter中Ramp-up 配置有什么样的作用?
Ramp-up 配置的时间是指启动所有配置的线程总数所用的时间,例如设置的线程总数为500,Ramp-up设置的时间为50s,意为:启动500个线程数需要50s,平均为每一秒启动10个线程。
另外整个压力持续时间Duration是包括Ramp-up的时间,很多人理解为是then hold load for的时间(线程全部启动完之后持续运行多长时间)。
设置ramp-up period 容易出现的问题
1.如果设置成零,Jmeter将会在测试的开始就建立全部线程并立即发送访问请求, 这样一来就很容易使服务器饱和,更重要的是会隐性地增加了负载,这就意味着服务器将可能过载,不是因为平均访问率高而是因为所有线程的第一次并发访问而引起的不正常的初始访问峰值。这种异常不是我们需要的,因此,确定一个合理的ramp-up period 的规则就是让初始点击率接近平均点击率。当然,也许需要运行一些测试来确定合理访问量。如果要使用大量线程,ramp-up period 一般不要设置成零。
注意:很多人把ramp-up设置成为0错误的理解成是秒杀测试,其实秒杀也是有个过程的,是指系统运行一段时间后的突然高并发,而且这个高并发量可能持续或是反复出现(现实中也是这样的,要站在服务端的角度去理解,不是站在客户端想当然的体验上去理解),一般系统第一个访问都会很慢,需要给个预热过程,就算要秒杀也是在系统正常运行情况下模拟出秒杀的陡增。另外,说到秒杀场景,有人觉得用大线程并发是合理的,其实这也属于认识上的错误。因为即使线程数增加得再多,对已达到 TPS 上限的系统来说,除了会增加响应时间之外,并无其他作用。所以我们描述系统的容量是用系统当前能处理的业务量(你用 TPS 也好,RPS 也好,HPS 也好,它们都是用来描述服务端的处理能力的),而不是压力工具中的线程数。
2.如果ramp-up period 过大也是不恰当的,因为将会降低访问峰值的负载,换句话说,在一些线程还未启动时,初期启动的部分线程可能已经结束了。
3.合理的ramp-up period,首先推测一下平均点击率并用总线程除点击率来计算初始的ramp-up period。例如,假设线程数为100, 估计的点击率为每秒10次, 那么估计的理想ramp-up period 就是 100/10 = 10 秒。
问题二:为什么说压力工具中 TPS 和响应时间曲线抖动过大会不易于分析?
性能分析一定要分析曲线的趋势,通过趋势的合理性来判断性能瓶颈所在的原因,光靠平均值、最大值、最小值、中位数是无法确切的分析压测过程中服务器的具体情况,只有通过分析曲线趋势,增加对趋势的敏感程度才是压测过程中更好的保障和前提。趋势图有助于分析性能瓶颈,而曲线抖动大了,不容易分析异常和趋势之间的关系。如果出现曲线抖动过大,我们是需要查找原因,这个原因不一定是异常,但一定是影响性能分析的因素,多少需要交待一些。
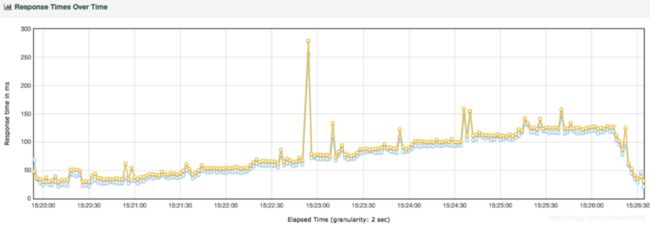
抖动的原因有非常多种,而且很多时候出现的时间点不一样,需要分析是否是系统设置或是测试参数设置的不合理导致的,一般会有几种可能性:1. 资源的动态分配不合理,像后端线程池、内存、缓存等等;2. 数据没有预热;3.测试参数设置或分布不合理,导致缓存命中率突降,或是请求返回的数据量陡增,或是请求发生异常或超时等等;4.遇到JVM内存集中释放(可能是第1种原因导致FULL GC太过频繁,也可能只是碰巧的偶然现象);5.压测工具或压力机的问题(一般不可能,但也不能排除,比如压力机不稳定);其他突发状况(比如网络突然延迟)。
二十二、网络的瓶颈如何判断?有哪几个队列?
带宽问题是性能分析中常见的问题之一,其难点就在于,带宽不像 CPU 使用率那么清晰可理解,它和 TCP/IP 协议的很多细节有关,像三次握手,四次挥手,队列长度,网络抖动、丢包、延时等等,都会影响性能,关键是这些判断点还不在同一个界面中,所以需要做分析的人有非常明确的分析思路才可以做得到。而且现在的监控分析工具中,对网络的判断也是非常薄弱的。
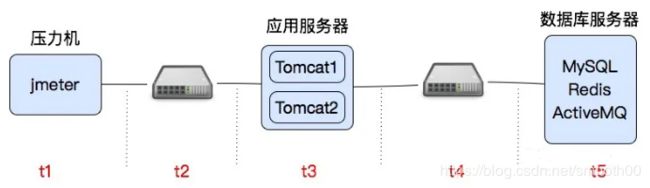
问题一:你能说一下网络的瓶颈如何判断吗?
通常情况可以查看jmeter聚合报告上面客户端接收数据量是否已经接近宽带的限制。判断网络是否出现瓶颈,主要依据两个数据来判断,外加一个网卡队列的判断:
1、确定本次压测链路上网络流量上限值是多少?
在压测之前,提前确定本地压测的数据流向,即压测请求从压力机上发出后,经过了哪些环节,最终到达服务器上。响应数据经过哪些环节,又返回到压力机。并且每个环节中的网络上限是多少,最终我们整个网络环路的流量上限,就取决于环路中最低的那个上限值(木桶原理)。举例说明,如下图所示:
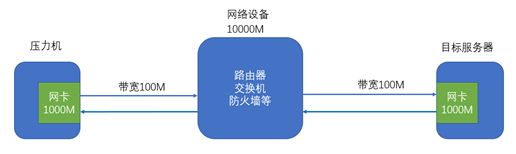
网络请求数据首先是从压力机的网卡发出,一般的网卡都是千兆网卡,然后网络带宽也会有限制,比如是100Mb,可能还会经过一些网络设备,如路由器、交换机、防火墙等,这些设备也都有网络上限,假如都是10000Mb,最后到达目标服务器的网卡(千兆网卡)。所以从上面的网络架构来看,整体链路最高支持100Mb的数据流量,大约是100/8=12.5MB。
如果在局域网内,几乎就不用考虑带宽和网络设备的问题了,所以局域网内网卡的上限就是整个链路的网络上限。
2、压测过程中,当前网络上的流量大小是多少
一般在目标服务器上,通过一些工具对网络进行监控,如nmon、dstat、sar、nload等,可以查看到实时的网络数据。按照上面图中的分析,假如通过监控Linux服务器,发现服务器的网卡流量已经达到12.5MB左右,那么就说明当前网络链路上的流量已经达到上限了,当前网络已经出现了瓶颈。在客户端上(压测工具),可以通过接收的数据量(假设接收数据量总和 = 服务端发送的数据量),以测试者的角度来判断是否达到网卡流量限制。
3、网卡队列对性能的影响考虑
网卡多队列是一种技术手段,可以解决网络I/O带宽QoS(Quality of Service)问题。网卡多队列驱动将各个队列通过中断绑定到不同的核上,从而解决网络I/O带宽升高时单核CPU的处理瓶颈,提升网络PPS和带宽性能。经测试,在相同的网络PPS和网络带宽的条件下,与1个队列相比,2个队列最多可提升性能达50%到100%,4个队列的性能提升更大。一般适用于Linux系统ECS实例(云服务器),Windows系统使用网卡多队列后其网络性能也会提升,但是提升效果不如 Linux 系统(Windows需要索要并安装相关驱动)。多队列网卡的硬件逻辑图:
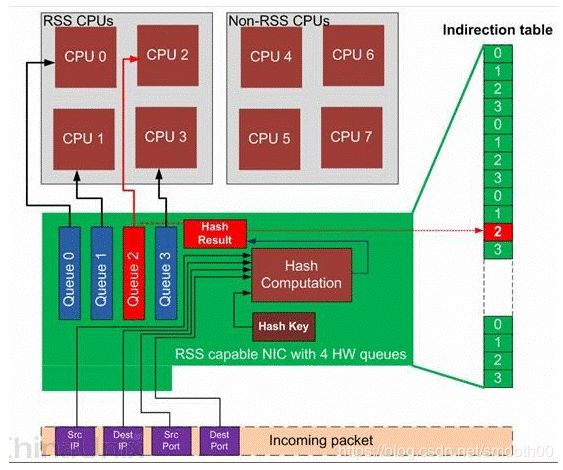
一般我们用的普通机器只有一个网卡队列,通过以下命令就能看出来:

或通过以下命令查看队列数(一行就是一个队列):
[root@bogon ~]# cat /proc/interrupts | grep eth0
19: 2644 0 0 2416109274 IO-APIC-fasteoi eth0问题二:要关注的有哪几个队列?
服务端消息发送队列
客户端接收数据的队列
服务端超时队列
网卡信息查询及设置命令举例:
(1) 查看网卡,在接收/发送数据时,查看收发包统计和有没有出错,命令格式:
ethtool -S eth0(2) 将千兆网卡的速度降为百兆,命令格式:
ethtool -s eth0 speed 100(3)查看收发队列:
ethtool -g eth0Ring parameters for eth0:
Pre-set maximums:
RX: 4096 #预设最大接收队列大小
RX Mini: 0
RX Jumbo: 0
TX: 4096 #预设最大发送队列大小
Current hardware settings:
RX: 256 #当前接收队列大小
RX Mini: 0
RX Jumbo: 0
TX: 256 #当前发送队列大小
(4)设置收发队列:
ethtool -G eth0 rx 4096 #设置发送队列大小Current hardware settings:
RX: 4096 #修改后的接收队列大小,网卡丢包的一个原因就是接收队列不够大。
RX Mini: 0
RX Jumbo: 0
TX: 256
二十三、Swap 的原理和逻辑,以及分析思路是什么?
我们一般所说的swap,指的是一个交换分区或文件。从功能上讲,交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。所以,当内存使用存在压力,开始触发内存回收的行为时,就可能会使用swap空间。内核对swap的使用实际上是跟内存回收行为紧密结合的。
很多人应该都知道 /proc/sys/vm/swappiness 这个文件,是个可以用来调整跟swap相关的参数。这个文件的默认值是60,可以的取值范围是0-100(这个值是个百分比)。
这个文件的值用来定义内核使用swap的积极程度:
- 值越高,内核就会越积极的使用swap;这只是个倾向性,是指在内存和swap都够用的情况下,更愿意用哪个,如果不够用了,那么该交换还是要交换。
- 值越低,就会降低对swap的使用积极性。
- 如果这个值为0,那么内存在free和file-backed使用的页面总量小于高水位标记(high water mark)之前,不会发生交换。
- 如果swappiness设置为100,那么匿名页和文件将用同样的优先级进行回收。
1、Swap配置对性能的影响:
分配太多的Swap空间会浪费磁盘空间,而Swap空间太少,则系统会发生错误。
如果系统的物理内存用光了,系统就会跑得很慢,但仍能运行;如果Swap空间用光了,那么系统就会发生错误。例如,Web服务器能根据不同的请求数量衍生出多个服务进程(或线程),如果Swap空间用完,则服务进程无法启动,通常会出现“application is out of memory”的错误,严重时会造成服务进程的死锁。因此Swap空间的分配是很重要的。
通常情况下,Swap空间应大于或等于物理内存的大小,最小不应小于64M,通常Swap空间的大小应是物理内存的2-2.5倍。但根据不同的应用,应有不同的配置:如果是小的桌面系统,则只需要较小的Swap空间,而大的服务器系统则视情况不同需要不同大小的Swap空间。特别是数据库服务器和Web服务器,随着访问量的增加,对Swap空间的要求也会增加,具体配置参见各服务器产品的说明。
另外,Swap分区的数量对性能也有很大的影响。因为Swap交换的操作是磁盘IO 的操作,如果有多个Swap交换区,Swap空间的分配会以轮流的方式操作于所有的Swap,这样会大大均衡IO的负载,加快Swap交换的速度。如果只有一个交换区,所有的交换操作会使交换区变得很忙,使系统大多数时间处于等待状态,效率很低。用性能监视工具就会发现,此时的CPU并不很忙,而系统却慢。这说明,瓶颈在IO上,依靠提高CPU的速度是解决不了问题的。
2、系统性能监视
Swap空间的分配固然很重要,而系统运行时的性能监控却更加有价值。通过性能监视工具,可以检查系统的各项性能指标,找到系统性能的瓶颈。最常用的是Vmstat命令(在大多数Unix平台下都有这样一些命令),此命令可以查看大多数性能指标:
# vmstat 3
procs memory swap io system cpu
r b w swpd free buff cache si so bi bo in cs us sy id
0 0 0 0 93880 3304 19372 0 0 10 2 131 10 0 0 99
0 0 0 0 93880 3304 19372 0 0 0 0 109 8 0 0 100
0 0 0 0 93880 3304 19372 0 0 0 0 112 6 0 0 100
…………命令说明:
vmstat 后面的参数指定了性能指标捕获的时间间隔。3表示每三秒钟捕获一次。第一行数据不用看,没有价值,它仅反映开机以来的平均性能。从第二行开始,反映每三秒钟之内的系统性能指标。这些性能指标中和Swap有关的包括以下几项:
- procs下的w:它表示当前(三秒钟之内)需要释放内存、交换出去的进程数量。
- memory下的swpd:它表示使用的Swap空间的大小。
- Swap下的si,so:si表示当前(三秒钟之内)每秒交换回内存(Swap in)的总量,单位为kbytes;so表示当前(三秒钟之内)每秒交换出内存(Swap out)的总量,单位为kbytes。
以上的指标数量越大,表示系统越忙。这些指标所表现的系统繁忙程度,与系统具体的配置有关。系统管理员应该在平时系统正常运行时,记下这些指标的数值,在系统发生问题的时候,再进行比较,就会很快发现问题,并制定本系统正常运行的标准指标值,以供性能监控使用。
另外,使用Swapon-s也能简单地查看当前Swap资源的使用情况。例如:
[root@bogon ~]# swapon -s
文件名 类型 大小 已用 权限
/dev/dm-1 partition 4063228 6796 -1能够方便地看出Swap空间的已用和未用资源的大小。
应该使Swap负载保持在30%以下,这样才能保证系统的良好性能。
二十四、为什么通过抓包可以判断出响应时间的拆分?
通过谷歌浏览器的F12开发者工具进行抓包分析,我们可以站在前端的角度来细分http请求的响应时间:

不同颜色的横向柱条表示不同的含义:
(1).Stalled(阻塞)
浏览器得到要发出这个请求的指令,到请求可以发出的等待时间,一般是代理协商、以及等待可复用的TCP连接释放的时间,不包括DNS查询、建立TCP连接等时间等。
(2)DNS Lookup(域名解析)
请求某域名下的资源,浏览器需要先通过DNS解析器得到该域名服务器的IP地址。在DNS查找完成之前,浏览器不能从主机名那里下载到任何东西
(3)Initial connection(初始化连接)
TCP建立连接的三次握手时间。
(4)Request sent(发送请求)
请求第一个字节发出前到最后一个字节发出后的时间,也就是上传时间。 发送HTTP请求的时间(从第一个bit到最后一个bit)
(3)Waiting(等待响应)
请求发出后,到收到响应的第一个字节所花费的时间(Time To First Byte)。
通常是耗费时间最长的。从发送请求到收到响应之间的空隙,会受到线路、服务器距离等因素的影响。这部分时间可以到下一个链路(服务端 + 网络)进行进一步拆分(以定位出是哪个环节占用时间高)。
(4)Content Download(下载)
收到响应的第一个字节,到接受完最后一个字节的时间,就是下载时间。下载HTTP响应的时间(包含头部和响应体)。
除了谷歌浏览器,其他浏览器也都有相关的功能,比如火狐、IE等,另外除了这种前端的角度拆分时间,还需要配合后端监控的响应时间拆分,具体看我的另一篇文章《关于Web事务响应时间的细分以及深入分析》。
二十五、数据分布不均衡会带来哪些性能问题?
1、数据分布不均衡会导致一些SQL的性能下降
最常见的影响是,数据分布不均衡,可能会导致查询不走索引;其次数据分布不均衡,会和一些SQL的优化规则冲突,比如针对多表连接查询时,数据量要从左往右依次减少(如果数据分布不均衡,遇到这样的规则就会出现性能波动);数据分布不均衡,在遇到多表关联查或视图合并时,出现笛卡尔积的概率增加,从而导致性能下降(笛卡尔集需要大量内存存储中间结果,从而产生大量IO开销)。
2、数据不均衡在测试过程中的性能影响
数据分布不均衡,会导致同样的SQL语句或业务功能,在不同的参数化条件下查到的数据量偏差很大(比如有时候返回10条记录,有时候返回1万条记录),对IO和网络传输,直至压测的TPS都会造成明显的抖动现象。所以测试前对数据的分布情况要有个基本掌握,能用生产数据最好用生产数据,没有生产数据,造也要造出满足一定离散分布的数据,或最好是能模拟出真实环境的数据分布。
3、数据不均衡对机器学习的性能影响
在数据不均衡的情况下,少数类样本的数量远少于多数类样本,会产生更多的稀疏样本(那些样本数很少的子类中的样本)。由于缺乏足够的数据,分类器对稀疏样本的刻画能力不足,难以有效的对这些稀疏样本进行分类。数据不均衡导致的分类器决策边界偏移也会影响到最终的分类效果,随着数据不平衡程度的增加,分类器分类边界偏移也逐渐增加,导致最终分类性能下降明显。所以对于不均衡数据,需要有专门的处理方式。
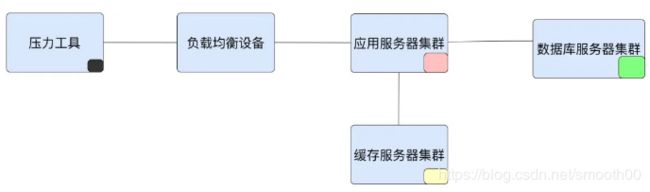
二十六、为什么 TPS 上不去时,资源用不上才是更让人着急的问题?TPS上不去的原因有哪些?
问题一:为什么 TPS 上不去时,资源用不上才是更让人着急的问题?
该问题要从正面角度思考,假设TPS上去了,资源使用也上去了,此时资源情况与TPS正相关,符合常理。但若TPS上不去时,肯定是有多方面原因导致,通常资源的使用是一个定位问题的好方向。
一般情况下,资源以及TPS上不去,说明压力的流量没有完整的打到服务器上,资源没有能够有效的利用,可能存在很多种原因导致的这个问题,也不知道我们系统到底能支持什么量级。举个例子就像我们有一个电视,但是一年下来只看了几个小时,那么这个电视是没有什么用的,白花了钱。
这种情况,需要进行一次完整的链路分析,要有充足的知识储备量。资源用不上,肯定会导致排查难度极度增大,不容易分析与定位问题(毕竟监控工具看不出的问题,分析起来费劲)。以下罗列了各种原因(仅供参考):
问题二:TPS上不去的原因都有哪些?
1、网络带宽
在压力测试中,有时候要模拟大量的用户请求,如果单位时间内传递的数据包过大,超过了带宽的传输能力,那么就会造成网络资源竞争,间接导致服务端接收到的请求数达不到服务端的处理能力上限。
2、连接池
可用的连接数太少,造成请求等待。连接池一般分为服务器连接池(比如Tomcat)和数据库连接池(或者理解为最大允许连接数也行)。
(关于连接池的具体内容,可参考博客:性能测试:连接池和线程)
3、垃圾回收机制
从常见的应用服务器来说,比如Tomcat,因为java的的堆栈内存是动态分配,具体的回收机制是基于算法,如果新生代的Eden和Survivor区频繁的进行Minor GC,老年代的full GC也回收较频繁,那么对TPS也是有一定影响的,因为垃圾回收其本身就会占用一定的资源。
4、数据库配置
高并发情况下,如果请求数据需要写入数据库,且需要写入多个表的时候,如果数据库的最大连接数不够,或者写入数据的SQL没有索引没有绑定变量,抑或没有主从分离、读写分离等,就会导致数据库事务处理过慢,影响到TPS。
5、数据库死锁
如果数据库有大量锁等待的情况,比如多个客户端试图更新同一行,则这个过程会非常缓慢。以mysql为例,整个innodb层就由并行变成了串行,大幅降低TPS。应该让锁等待尽量少,可以优化SQL,也可以通过在数据库层设置等待队列来达到提升TPS的效果。
6、通信连接机制
串行、并行、长连接、管道连接等,不同的连接情况,也间接的会对TPS造成影响。
(关于协议的连接,可参考博客:HTTP协议进阶:连接管理)
7、硬件资源
包括CPU(配置、使用率等)、内存(占用率等)、磁盘(I/O、页交换等),这块一般有很多监控工具支持,比较容易直观的看出来。
8、压力机
比如jmeter,单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会间接影响TPS(这个时候就需要进行分布式压测来解决其单机负载的问题)。
9、压测脚本
还是以jemter举个例子,之前工作中同事遇到的,进行阶梯式加压测试,最大的模拟请求数超过了设置的线程数,导致线程不足。提到这个原因,想表达意思是:有时候测试脚本参数配置等原因,也会影响测试结果。
10、业务逻辑
业务解耦度较低,较为复杂,整个事务处理线被拉长导致的问题。另外也可能由于代码中涉及到业务锁(比如一秒只接受10个请求,其它请求拒绝;或一个部门只允许一个用户操作等等),锁的存在直接限制了并发,导致TPS上不去。
11、服务假死
运行一个时间后(一般是过载执行一段时间),处于假死状态,这时候,可能所有的请求都会失败的;遇到多节点服务(高可用),某个节点假死,系统还能继续运行,但明显会导致TPS降低。
线程死锁也有可能会造成所有的请求等待的问题,直接导致TPS上不去;服务器假死,这时候会造成请求异常(包括拒绝服务或超时异常),由于一般这样的错误都是链接失败之类的,还是比较容易看出来。
12、黑白名单
路由器网络安全配置或是防火墙设置等原因,比如IP请求次数过多,造成访问的异常;一个用户1秒请求次数太多,被限流。
13、系统架构
比如是否有缓存服务,缓存服务器配置,缓存命中率、缓存穿透以及缓存过期、第三方或外接服务接口的并发限制等,都会影响到测试结果。
性能瓶颈分析不能单从局部分析,要综合起来,多维度分析问题原因。上面列出的几点,可能有描述不当或者遗漏的,仅供参考......
不管是什么样的性能问题,其实从分析思路上仍然逃不开我们一直提到的思路——那就是一个分析的完整链路。当你一层一层往下找问题时,只要抓住了重点,思路不断,找到根本原因就可以解决问题。
应该说,不管是谁,都不能保证自己的知识体系是完整的,那怎么办呢?查资料,各种学习,看源码,看逻辑。实在看不懂,那也没办法,接着修炼基础内功呗。
所以说性能测试行业中,经常只测不分析,也是因为做性能分析需要的背景知识量有点大,还要不断分析各种新的知识点。不过也就是因为如此,性能测试和性能分析才真的有价值。只测不调只是做了一半工作,价值完全体现不出来。
二十七、为什么要在 CPU 高时查看 CPU 热点函数?
在CPU高时,查看CPU热点函数(通过CPU热点函数可以看到系统哪个模块的CPU利用率高),能使我们深究原因时的整体方向不会偏离(全局-定向的分析思路,逐层分析,找到问题并且解决问题)。在全局方向不出错的前提下,找到根本原因及提出相应的解决方案才能真正的解决CPU高的问题。
可以通过perf top查看cpu热点信息(perf可能需要安装),我们需要分析的是占用CPU高的进程ID,如 perf top -g -p 1379:

第一列[“Children”和“Self”]:符号引发的性能事件的比例,默认指占用的cpu周期比例。
“self”开销只是通过所有入口(通常是一个函数,也就是符号)的所有周期值相加来计算的。这是perf传统显示方式,所有“self”开销值之和应为100%。
“children”开销是通过将子函数的所有周期值相加来计算的,这样它就可以显示更高级别函数的总开销,即使它们不直接参与更多的执行。这里的“Children”表示从另一个(父)函数调用的函数。
所有“children”开销值之和超过100%可能会令人困惑,因为它们中的每一个已经是其子函数的“self”开销的累积。但是如果启用了这个功能,用户可以找到哪一个函数的开销最大,即使样本分布在子函数上。
第二列[“Shared”]:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
第三列[“Object”]:DSO的类型。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库)。[k]表述此符号属于内核或模块。
第四列[“Symbol”]:符号名。有些符号不能解析为函数名,只能用地址表示。
二十八、为什么加大 buffer 可以减少磁盘 I/O 的压力?

有必要说一下Cache和Buffer,一个是缓存,一个是缓冲(cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到**加快访问速度**的作用。而 buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以**减少响应次数**),无论缓冲还是缓存,其实本质上解决的都是读写速度不匹配的问题,虽然原理不一样,但我们也不用去纠结技术细节了,就统称Buffer Cache。
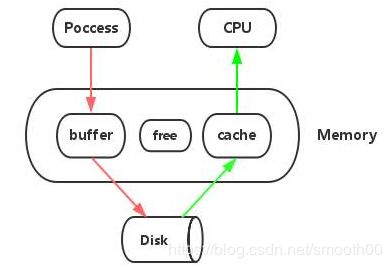
Buffer 和 Cache 分别缓存的是对磁盘和文件系统的读写数据。从写的角度来说,不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就返回去做其他工作,提高的是速度;从读的角度来说,不仅可以提高那些频繁访问数据的读取速度,也降低了频繁 I/O 对磁盘的压力。
我们性能测试关注的Buffer Cache应该包括两方面:操作系统的和数据库的。它俩作用都是为了把经常访问的数据(也就是热点数据),提前读入到内存中。这样,下次访问时就可以直接从内存读取数据,而不需要经过硬盘,从而加速I/O 的访问速度。
以Linux下的Postgresql为例:
- 1. 在访问数据时,数据会先加载到操作系统缓存,然后再加载到数据库的shared_buffers,这个加载过程可能是一些查询,也可以使用pg_prewarm预热缓存。
- 2. 当然也可能同时存在操作系统和shared_buffers两份一样的缓存(双缓存)。
- 3. 查找到的时候会先在shared_buffers查找是否有缓存,如果没有再到操作系统缓存查找,最后再从磁盘获取。
- 4. 操作系统缓存使用简单的LRU(移除最近最久未使用的缓存),而PostgreSQL采用的优化的时钟扫描,即缓存使用频率高的会被保存,低的被移除。
PostgreSQL缓存读顺序share_buffers -> 操作系统缓存 -> 硬盘。那么也可能是操作系统缓存不足,不一定是share_buffers。假设通过vmstat命令看到cache充足,free值也很稳定,那么就应该检查PostgreSQL的缓存。
二十九、为什么说 TPS 趋势要在预期之内?那要如何通过TPS跑性能?
问题一:为什么说 TPS 趋势要在预期之内?
首先我们要把握TPS和整体性能的关系,只有心中有数,自然就能形成预期。TPS和响应时间在理想状态下都是紧密相关的,如果我们对响应时间是有预期的,那么对TPS自然也会有预期,换句话说,我们对系统的处理能力是有预期的,那么自然对TPS和响应时间也会有预期。加上我们对整体系统架构和系统的性能有预期把握,那么我们自然也就要求对TPS的趋势有所把握。
TPS的预期值基本来自两个方向:老系统可以通过历史业务量来预估;新系统通过跑出来形成基准测试的依据。
对TPS趋势要在预期之内,好处就是能形成具体的测试目标和优化方向(最基本的预期就是TPS随着用户数或线程数的增加,而不断增长,达到性能拐点后就不再增长,甚至还会因为性能衰减而降低;并且TPS趋势与响应时间趋势紧密相关;TPS趋势线在外界压力稳定情况下不会出现明显抖动)。事出反常必有妖,超出预期就需要引起关注,做好分析介入,分层分段分析性能瓶颈。
问题二:如何通过TPS跑性能?
首先不清楚到底并发多少虚拟用户是合理的,那就不要从并发多少虚拟用户考虑;网上能找到所有关于并发用户的计算方法,那些公式都是不可靠的,就当它无任何参考价值(前面也提到过,很多人对并发数的认识是有偏差的)。
新、老系统如何跑性能:
1. 老系统通过历史业务评估TPS,得出TPS后要略高于当前评估的标准,以保证在较大压力,系统可以正常运行。
2. 新业务系统,什么业务数据都没有,怎么办?
所有的评估都是猜想没有任何根据,只能通过动态的方法,通过现有系统环境跑性能(尤其在客户也不清楚的情况下)评估得出最佳和最大的用户数,系统的最大处理能力是多少。得出来以后,在上线后及时监控客户系统,有没有达到最佳用户数、最大用户数,系统资源怎么样,出现性能瓶颈,该添加硬件添加硬件,该调优调优。在内部跑性能目的不是为了验证合格不合格,而是发现能不能优化,有没有漏洞的地方,如果有明显缺陷的地方,把能优化的优化,进行参数调优(也可以事先把不合理的参数都先撸一遍再测试),优化前优化后,有没有提高。最后上线后实时跟踪根据情况并实时处理。
常用步骤:
1. 将配置调到最优,找系统的最大处理能力;
2. 控制TPS;
3. 没有性能需求,先将系统调到最优;
4. 已经上线的系统做性能调研步骤:年排序找最大》月排序找最大》星期排序,找最大》某一天找最大》24小时找哪个小时最大的业务量;找业务的成功率;说一类业务,不是一些业务;取核心业务场景(交易占比最高,比如占80%的业务场景),做性能;
单业务一个用户跑TPS;
关注优化前的TPS,优化后的TPS;
think time统计,不会用,就最好不要用;
TPS上不去,CPU上不去,找问题;
内存消耗看堆,CPU耗的高,看栈。
举例:
1. 从TPS业务处理量来看,预估每天、每小时处理N万笔业务除以3600秒,得到TPS每秒可以处理多少笔就可以了,并发用户数是多少无所谓,只要达到3600秒N万就可以了。
2. 预测试,用Ramp Up递增的方式,看看能支撑多少用户数。慢慢增加用户,监控系统资源(在最佳的资源下)得到最佳用户数。根据最佳用户数,反回来看能不能达到业务需求的目标 『每秒( N万/3600 )笔』。
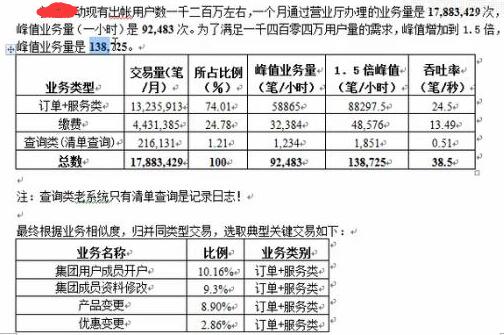
三十、性能测试过程中性能分析的思路是什么?
这才是核心的话题,也算是对前面知识的总结,可以看这张 性能测试分析的能力阶梯图:
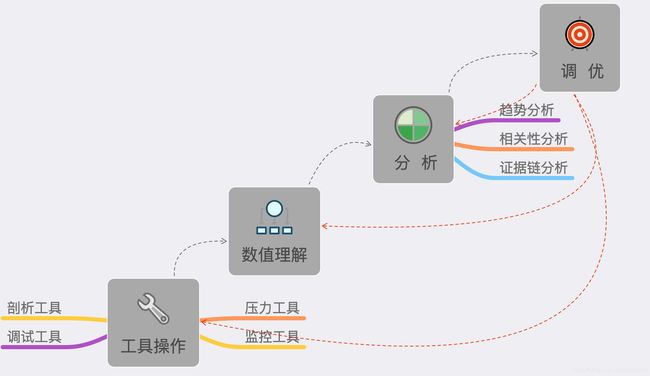
工具操作:包括压力工具、监控工具、剖析工具、调试工具。
数值理解:包括上面工具中所有输出的数据。
趋势分析、相关性分析、证据链分析:就是理解了工具产生的数值之后,还要把它们的逻辑关系想明白。这才是性能测试分析中最重要的一环。
最后才是调优:有了第 3 步之后,调优的方案策略就有很多种了,具体选择取决于调优成本和产生的效果。
具体内容见转载自高楼的文章 https://smooth.blog.csdn.net/article/details/106143176
另外性能分析这个话题确实太大了,有关性能问题分析的方法及案例,可以参考网上的一些文章:
https://www.cnblogs.com/unknows/p/8534642.html
https://www.cnblogs.com/L-Test/p/9534951.html
http://www.7dtest.com/7DGroup/?p=638
http://www.7dtest.com/7DGroup/?p=358
https://www.cnblogs.com/scy251147/p/9809915.html
https://www.cnblogs.com/geaozhang/p/7184712.html
https://www.cnblogs.com/huantianxing/p/8137378.html
https://www.cnblogs.com/Alexr/p/10572611.html