基于Netty使用1200行/4000行代码实现分布式RPC框架
基于Netty使用1200行/4000行代码实现分布式RPC框架
先放出Github 链接
目前可用的有两个版本,对应releases中的v2.0和v3.2,代码量分别为1200行和4000行。这两个版本都是可以运行的。稍后介绍它们的区别以及功能等。
前置知识
- 对RPC有一定了解,使用过Dubbo或类似RPC框架的会理解地更容易一些。推荐一本书《大型网站系统与JAVA中间件实践》,其中服务框架这一章就是在讲RPC的概念与实现的大概介绍。
- 对Netty有一定了解,如果之前不了解,现在学起来更好,Dubbo、RocketMQ等知名互联网中间件都在使用该网络编程框架。推荐一本书《Netty实战》。
- 熟悉Java多线程、NIO、反射等基础。推荐一本书《Java并发编程的艺术》。
- 熟悉Spring和SpringBoot,主要是依赖注入和AutoConfig部分。
1200LOC Version(V2.0)
1200行的版本还是实现的比较简陋,比如某个应用只能作为consumer或provider,如果作为provider就必须提供全部的接口服务。另外负载均衡其实有点可笑,因为某个客户端只能连接到一个服务器,也就是说只能保证连接数的负载均衡,无法实现调用的负载均衡。另外功能点也比较有限,可以说只是实现了RPC的基本功能。另一个主要问题,也是在下一个版本中大幅改进的,就是没有分层,各个组件之间直接依赖实现,代码强耦合。
功能列表
- 基于Netty实现长连接式的RPC,包括心跳保持、断线重连、解决粘包半包等
- 基于Protostuff实现消息的序列化
- 基于Zookeeper实现分布式服务注册与发现,并实现了几种负载均衡算法
- 基于动态代理实现透明RPC,并为其编写了Spring Boot Starter
运行环境
- 安装Zookeeper,具体安装过程请自行搜索
- 安装ZooInspector或类似软件,用于作为可视化Zookeeper客户端,使用ZK的命令行客户端也可以
- IDE安装lombok相关的插件,idea和eclipse都有相关的插件。没有接触过这个项目的可以搜一下,是用来简化POJO开发的非常好用的工具,目前项目是强依赖这个工具。
- 如果发现sample-spring模块无法被Maven识别,可以在根pom.xml中的modules里把这个模块加进来。
- 修改sample-spring-server和sample-spring-client中的application.properties中的rpc.registryAddress=127.0.0.1:2181(这部分改成你的ZK的监听地址,默认就是这个)
- 对sample-spring-server中的ServerApplication配置启动参数,启动参数为监听的地址,比如127.0.0.1:8000。在idea中可以这样配置:

- 启动server,如果抛了java.lang.NoClassDefFoundError: org/apache/commons/logging/LogFactory,那么在根pom.xml中加一个依赖
commons-logging
commons-logging
1.2
- 启动client,不需要配置任何参数。可以启动多个服务器(前提是监听在不同端口上,如果是在本地的话),也可以启动多个客户端。
实现细节
本来是3月份打算写的,正在准备春招一时抽不出时间,最近的话在重新维护这个项目,就不太想写老旧的实现了。
但还是有一定参考价值的,代码量比较小,并且具备基本的功能,虽然有一些功能字面上和主流RPC框架一样,但在实现还是打了一些折扣的。
这个版本实现如果读者有兴趣的烦请自行阅读源码。
4000LOC Version(V3.2)
目前版本与V2.0的区别当时不仅仅是名字改成了toy-rpc,主要是在分层抽象上下了很大功夫。
功能列表
- 基于Netty实现长连接式的RPC,包括心跳保持、断线重连、解决粘包半包等
- 基于Zookeeper实现分布式服务注册与发现,并实现了轮询、随机、加权随机、一致性哈希等负载均衡
算法,以及FailOver、FailFast、FailSafe等多种集群容错方式 - 参考Dubbo实现了分层结构,如
config,proxy,cluster,protocol,filter,invocation,registry,transport,executor,serialize等层 - 实现了同步、异步、回调、Oneway等多种调用方式
- 实现了TCP、HTTP、InJvm等多种协议
- 实现了客户端侧的Filter,并基于此实现了LeastActive负载均衡算法
- 实现了简易扩展点,泛化调用等功能
- 基于动态代理实现透明RPC,并为其编写了Spring Boot Starter
V2.0的很多问题也被纠正的了,比如一个应用即可以提供远程服务,也可以调用远程服务;负载均衡也实现了每次远程服务调用的时候进行负载均衡;每个应用也不必一定要提供全部的接口服务了。
应该主流RPC框架提供的大部分功能都有了,未来可能会再完善的点有下面这些:
- 优雅停机
- 服务限流、熔断
- 结果缓存
- 多版本,分组
- Router
- 网络层分层、
- Monitor,持久化配置
运行环境
与V2.0基本一致,区别就是server的启动参数配置方式不同:

这个-D是用来覆盖SpringBoot中application.properties配置项的,其实这个地址也可以直接写死在配置文件里,但是如果要启动多个服务器的时候需要改文件,用启动参数就可以提前配置几个idea中的Run Configuration,这样就直接运行即可。

使用方法(独立项目)
在自己的项目中首先引入spring-boot,然后加入toy-rpc-spring-boot-starter的Jar包(本地引入),最后使用@RPCService和@RPCReference来引入,application.properties的配置可以参考几个示例项目,下面也会有介绍。
1.、创建一个SpringBoot项目
2.、对toy-rpc进行打包(maven-install),得到一个toy-spring-boot-starter的jar包(比如路径为D:/idea/toy-rpc/toy-rpc-spring-boot-starter/target/toy-rpc-spring-boot-starter-1.0-SNAPSHOT-jar-with-dependencies.jar),注意要选择这个with-dependencies的jar包。
3.、在你的项目中引入该jar包,使用本地依赖的方式。
<dependency>
<groupId>com.sinjinsonggroupId>
<artifactId>toy-rpc-spring-boot-starterartifactId>
<version>1.0-SNAPSHOTversion>
<scope>systemscope>
<systemPath>D:/idea/toy-rpc/toy-rpc-spring-boot-starter/target/toy-rpc-spring-boot-starter-1.0-SNAPSHOT-jar-with-dependencies.jarsystemPath>
dependency>4.、配置application.properties
rpc.application.name=app-1
rpc.application.serialize=protostuff
rpc.application.proxy=jdk
rpc.protocol.type=injvm
rpc.protocol.executor.server.threads=100
rpc.protocol.executor.server.type=threadpool
#rpc.protocol.executor.client.threads=2
rpc.protocol.executor.client.type=threadpool
rpc.registry.address=127.0.0.1:2181
rpc.cluster.loadbalance=LEAST_ACTIVE5.、使用@RPCServicce来暴露一个服务,使用@RPCReference来引用一个服务。
@RPCService
public class HelloServiceImpl implements HelloService {
public String hello(User user) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello, " + user.getUsername();
}
}@Slf4j
@Service
public class SyncCallService {
@RPCReference
private HelloService helloService;
public void test() throws Exception {
log.info("sync:{}",helloService.hello(new User("1")));
log.info("sync:{}",helloService.hello(new User("2")));
Thread.sleep(3000);
log.info("sync:{}",helloService.hello(new User("3")));
Thread.sleep(8000);
log.info("sync:{}",helloService.hello(new User("4")));
}
}给一个示例的pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>1.5.9.RELEASEversion>
parent>
<groupId>com.sinjinsonggroupId>
<artifactId>hello-toyartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
<slf4j.version>1.7.25slf4j.version>
<log4j.version>1.2.17log4j.version>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.18version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>${log4j.version}version>
dependency>
<dependency>
<groupId>com.sinjinsonggroupId>
<artifactId>toy-rpc-spring-boot-starterartifactId>
<version>1.0-SNAPSHOTversion>
<scope>systemscope>
<systemPath>D:/idea/toy-rpc/toy-rpc-spring-boot-starter/target/toy-rpc-spring-boot-starter-1.0-SNAPSHOT-jar-with-dependencies.jarsystemPath>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-bootartifactId>
<version>1.5.9.RELEASEversion>
dependency>
dependencies>
project>独立的示例项目代码如果有需要的话可以跟我要一下,如果只是抱着学习源码的态度,项目中的sample-spring下面的示例也足够了。
实现细节
分层抽象
先看一张非常有名的图,相信熟悉Dubbo的同学一定见过:

在V3.2的版本中,分层抽象有相当一部分是借鉴了Dubbo的实现,因为我认为Dubbo的分层是我所见过的软件项目做得非常优秀的。优秀的分层不仅仅使项目的可读性、可维护性更好,其可扩展性(对于RPC框架来说是非常重要的)也会变得非常出色。我在实习期间也略看了一点阿里巴巴内部使用的HSF(High-Speed Service Framework),其功能也和Dubbo大同小异,但是分层、架构设计明显还是Dubbo更优秀一些。
首先要澄清的一点是,toy-rpc不是把Dubbo直接拷贝过来,这明显意义也不大,主要目的还是进一步熟悉RPC,实现更多的功能点(在代码量尽量小的前提下)以及提高工程能力。但功能与Dubbo非常类似,架构设计也有参考的地方,在重构V2.0的时候主要是参考了上面这张图以及部分接口定义,在实现遇到困难的时候也参考了一部分Dubbo源码实现。
在实现的时候遇到的主要问题还是分层的问题,在如何实现组件、层次、模块之间低内聚、高耦合方面花了很多心思,也经历了反复迭代、优化的过程。
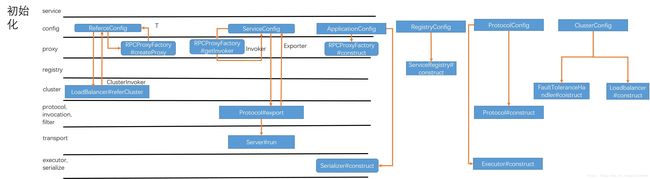
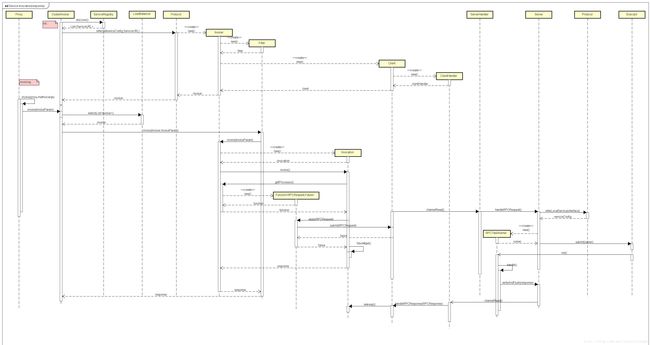
现在给大家看几张图,描述了整体架构,有点模仿Dubbo的那张架构图,但是不知道怎么画一起:)
初始化
服务调用之ConsumerSide
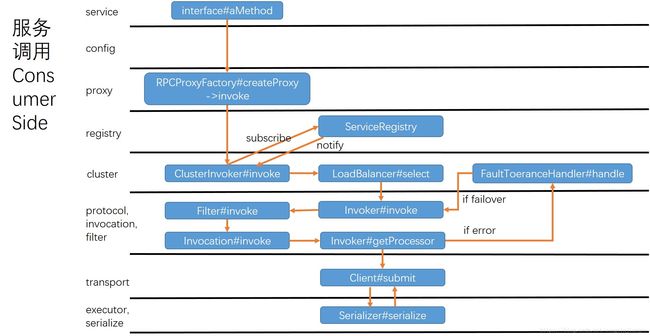
服务调用之ProviderSide

同步调用的完整时序图
各层介绍
扩展点:用户可以为某个接口添加自己的实现,在不改变框架源码的前提下,对部分实现进行定制。
最常见的是Filter扩展点。
config
配置层。
设计准则是Instance wrapped by config,一个配置类中持有了它相关的配置的实例。
对应的核心类:
- ReferenceConfig(对应一个服务接口的引用,持有接口代理实例)
- ServiceConfig(对应一个服务接口的暴露,持有接口实现类实例)
- GlobalConfig(全局配置)
- ApplicationConfig(应用配置,持有ProxyFactory实例、Serializer实例)
- RegistryConfig(注册中心配置,持有ServiceRegistry实例)
- ProtocolConfig(协议配置,持有Protocol实例、Executor实例)
- ClusterConfig(集群配置,持有LoadBalancer实例、FaultToleranceHandler实例)
proxy
代理层,主要是为ReferenceConfig生成接口的代理实例(抽象为Invoker,底层是RPC),以及为ServiceConfig生成接口的代理实例(抽象为Invoker,底层直接委托给实现类实例)。
对应的核心类:
- RPCProxyFactory(扩展点,目前有Jdk一种实现)
registry
注册中心层,主要是服务注册与服务发现,比如对于provider而言,在服务暴露的时候将自己的地址写入到注册中心;对于consumer而言,在服务发现的时候获取服务器的地址,并建立连接,并订阅地址列表,当服务器上下线时,consumer可以感知。
对应的核心类:
- ServiceRegistry(扩展点,目前有Zookeeper一种实现)
cluster
集群层,主要是将一个接口的集群实现对外暴露为单个实现,屏蔽集群的细节。在集群内部主要是做负载均衡以及集群容错。
对应的核心类:
- LoadBalancer(扩展点,必须继承自AbstractLoadBalancer,目前有随机、加权随机、轮询、一致性哈希、最小活跃度五种实现)
- FaultToleranceHandler(扩展点,目前有FailOver、FailFast、FailSafe三种实现)
protocol、invocaiton、filter
协议层,也是最核心的一层。
对应的核心类:
- Protocol(扩展点,目前有TCP、HTTP、InJvm三种实现,需要实现响应的Invoker)
- Filter(扩展点,目前有一个为了实现LeastActive算法的ActiveLimitFilter实现)
- Invocation(扩展点,一般不需要扩展,目前有同步、异步、Oneway、Callback四种实现)
transport
通信层,需要配合协议层,自定义协议实现需要相应的自定义通信实现。
对应的核心类:
- Server(在协议export时如果需要,需要启动服务器)
- Client(在协议refer时如果需要,需要启动客户端)
它们不是扩展点,只是Protocol在执行相应操作时依赖的组件。
executor、serialize
其他的较为独立的组件,如任务执行器和序列化器。
对应的核心类:
- TaskExecutor(扩展点,服务器的接口的调用任务线程池,或者客户端的callback线程池,目前有线程池和Disruptor两种实现)
- Serialzer(扩展点,目前有Jdk和Protostuff两种实现)
如何扩展一个扩展点
举两个例子,一个是暂时不需要设置alias别名的,一个是需要设置的。
- Filter
- 在resources目录下创建一个toy目录,然后创建一个名为com.sinjinsong.toy.filter.Filter的文件,文件内容是k=v的格式,k是一个实现类的别名,v是实现类的全类名,比如:bizlog=com.sinjinsong.toy.sample.spring.client.filter.BizLogFilter。这个和Dubbo的实现非常像。
- Serializer
- 同上,文件名为com.sinjinsong.toy.serialize.api.Serializer,文件内容也是k=v的格式。另外,需要修改application.properties中的rpc.application.serialize={你在文件里写的k}。
必备概念
Invoker:抽象的服务调用者,包括consumer端的代理实例和provider端的真正的服务实现类实例。对于consumer端而言,一个协议Invoker(由某个Protocol调用其refer生成的实例)是对应于一个接口的一个服务器实现(interface,address);一个ClusterInvoker是对应于一个接口的所有服务器实现的(interface)。现在这一点不太理解的可以往后看,后面有更详细的解释。
Exporter:Invoker暴露之后的抽象,是抽象的服务暴露后的调用者。
Config层实现细节
GlobalConfig
全局的配置实例,是单例的,持有四个同样是全局单例的配置类。
public class GlobalConfig {
private ApplicationConfig applicationConfig;
private ClusterConfig clusterConfig;
private RegistryConfig registryConfig;
private ProtocolConfig protocolConfig;
}应用内的依赖注入
整个应用中的依赖注入都是在toy-rpc-spring-boot-starter的RPCAutoConfiguration中完成的。这里其实涉及一个问题,就是业务系统通常是会依赖Spring来完成bean的加载、依赖注入等,而中间件或者轮子,它们同样也有着依赖注入的需求,那能不能也用Spring呢?答案是能,但是非常不建议这样做,原因是:
1、重。我们这个rpc本身只有4k行代码,但是一个Spring就有几百万行代码,无疑是会增加体积、降低初始化速度等。
2、依赖冲突。假设我们轮子里引入了Spring,那业务系统直接依赖了Spring,用来做依赖注入,又依赖了我们这样轮子,间接依赖了Spring,版本不同的话很容易出现依赖冲突,这会对使用者带来非常大的困扰。
那Dubbo是如何解决这个问题的呢?Dubbo针对JDK提供的SPI机制,自己重写了SPI,可以动态地根据URL来获取同一接口的不同实现类。我们toy-rpc暂时不需要运行时来获取实现类,只需要根据配置文件的配置来决定使用哪个实现类,所以这里是用枚举单例的方式来做依赖注入。
以ApplicationConfig的加载为例:
@Bean
public ApplicationConfig applicationConfig() {
ApplicationConfig application = properties.getApplication();
if (application == null) {
throw new RPCException(ErrorEnum.APP_CONFIG_FILE_ERROR, "必须配置applicationConfig");
}
// TODO 根据类型创建proxyFactory和serializer
application.setProxyFactoryInstance(new JdkRPCProxyFactory());
application.setSerializerInstance(extensionLoader.load(Serializer.class, SerializerType.class, application.getSerialize()));
log.info("{}", application);
return application;
}Serializer是可以根据配置文件来选择不同实现的,这里有一个相关的枚举类SerializerType:
public enum SerializerType implements ExtensionBaseType {
PROTOSTUFF(new ProtostuffSerializer()),
JDK(new JdkSerializer());
private Serializer serializer;
SerializerType(Serializer serializer) {
this.serializer = serializer;
}
@Override
public Serializer getInstance() {
return serializer;
}
}
我们看一下extensionLoader是怎么处理的。
public T load(Class interfaceClass, Class enumType, String type) {
ExtensionBaseType extensionBaseType = ExtensionBaseType.valueOf(enumType, type.toUpperCase());
if (extensionBaseType != null) {
return extensionBaseType.getInstance();
}
if (!extensionMap.containsKey(interfaceClass.getName())) {
throw new RPCException(ErrorEnum.NO_SUPPORTED_INSTANCE, "{} 没有可用的实现类", interfaceClass);
}
Object o = extensionMap.get(interfaceClass.getName()).get(type);
if (o == null) {
throw new RPCException(ErrorEnum.NO_SUPPORTED_INSTANCE, "{} 没有可用的实现类", interfaceClass);
}
return interfaceClass.cast(o);
} 其实就是先用valueOf来找枚举,如果能找到,那么getInstance获取实例即可。后面那部分代码是用来实现扩展点的。
应用外的依赖注入
比如说用户自己定义了一个Filter,会在com.sinjinsong.toy.filter.Filter文件里配置一行bizlog=com.sinjinsong.toy.sample.spring.client.filter.BizLogFilter。
在RPCAutoConfiguration的afterPropertiesSet中会使用extensionLoader来加载扩展点。
public void loadResources() {
URL parent = this.getClass().getClassLoader().getResource("toy");
if (parent != null) {
log.info("/toy配置文件存在,开始读取...");
File dir = new File(parent.getFile());
File[] files = dir.listFiles();
for (File file : files) {
handleFile(file);
}
log.info("配置文件读取完毕!");
}
}
private void handleFile(File file) {
log.info("开始读取文件:{}", file);
String interfaceName = file.getName();
try {
Class interfaceClass = Class.forName(interfaceName);
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
while ((line = br.readLine()) != null) {
String[] kv = line.split("=");
if (kv.length != 2) {
log.error("配置行不是x=y的格式的:{}", line);
throw new RPCException(ErrorEnum.EXTENSION_CONFIG_FILE_ERROR, "配置行不是x=y的格式的:{}", line);
}
// 如果有任何异常,则跳过这一行
try {
Class impl = Class.forName(kv[1]);
if (!interfaceClass.isAssignableFrom(impl)) {
log.error("实现类{}不是该接口{}的子类", impl, interfaceClass);
throw new RPCException(ErrorEnum.EXTENSION_CONFIG_FILE_ERROR, "实现类{}不是该接口{}的子类", impl, interfaceClass);
}
Object o = impl.newInstance();
register(interfaceClass, kv[0], o);
} catch (Throwable e) {
e.printStackTrace();
throw new RPCException(ErrorEnum.EXTENSION_CONFIG_FILE_ERROR, "实现类对象{}加载类或实例化失败", kv[1]);
}
}
br.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
throw new RPCException(e, ErrorEnum.EXTENSION_CONFIG_FILE_ERROR, "接口对象{}加载类失败", file.getName());
} catch (IOException e) {
e.printStackTrace();
throw new RPCException(e, ErrorEnum.EXTENSION_CONFIG_FILE_ERROR, "配置文件{}读取失败", file.getName());
}
}简单地说就是把配置文件都读进来,然后对对象进行实例化,缓存起来,在load的时候可以返回用户提供的扩展点对象。
public List load(Class interfaceClass) {
if (!extensionMap.containsKey(interfaceClass.getName())) {
return Collections.EMPTY_LIST;
}
Collection ReferenceConfig
ReferenceConfig是一个服务接口的引用配置类,对应一个接口,是接口维度的,对同一个接口的创建是有缓存的。
我们知道一个服务引用的调用是从代理类开始的,那么@RPCReference是怎么被解析的呢?
public class RPCConsumerBeanPostProcessor extends AbstractRPCBeanPostProcessor{
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Class beanClass = bean.getClass();
Field[] fields = beanClass.getDeclaredFields();
for (Field field : fields) {
if (!field.isAccessible()) {
field.setAccessible(true);
}
Class interfaceClass = field.getType();
RPCReference reference = field.getAnnotation(RPCReference.class);
if (reference != null) {
ReferenceConfig config = ReferenceConfig.createReferenceConfig(
interfaceClass.getName(),
interfaceClass,
reference.async(),
reference.callback(),
reference.oneway(),
reference.timeout(),
reference.callbackMethod(),
reference.callbackParamIndex(),
false,
ExtensionLoader.getInstance().load(Filter.class)
);
initConfig(config);
try {
field.set(bean,config.get());
} catch (IllegalAccessException e) {
throw new RPCException(e,ErrorEnum.AUTOWIRE_REFERENCE_PROXY_ERROR,"set proxy failed");
}
log.info("注入依赖:{}",interfaceClass);
}
}
return bean;
}
}
对Spring启动比较熟悉的同学应该知道,对每个bean调用getBean时有一步对是每个bean应用所有的后置处理器,比如我们编写的这个后置处理器,我们会读取该类中的所有字段中是否有@RPCReference注解,如果有,则将该字段值替换为我们生成的代理。
可以看出是先创建了一个ReferenceConfig,然后调用get来获取代理实例。
get方法其实是调用了init,我们看一下初始化ReferenceConfig的过程:
private void init() {
if (initialized) {
return;
}
initialized = true;
// ClusterInvoker
invoker = clusterConfig.getLoadBalanceInstance().referCluster(this);
if (!isGeneric) {
ref = applicationConfig.getProxyFactoryInstance().createProxy(invoker);
}
}第一步是创建一个ClusterInvoker,第二步是根据第一步生成的ClusterInvoker由ProxyFactory生成代理对象。
ClusterInvoker是config、cluster层都频繁出现的核心类,它同样也是一个Invoker,但对应的是一个接口。
第二步是生成代理,具体实现在proxy层有介绍。
ServiceConfig
ServiceConfig是对应一个接口的provider端实现类的,每个@RPCService的类都会被映射到一个ServiceConfig实例上。
类似于ReferenceConfig,@RPCService同样是基于BeanPostProcessor来解析的。
public class RPCProviderBeanPostProcessor extends AbstractRPCBeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Class beanClass = bean.getClass();
if (!beanClass.isAnnotationPresent(RPCService.class)) {
return bean;
}
RPCService rpcService = beanClass.getAnnotation(RPCService.class);
Class interfaceClass = rpcService.interfaceClass();
if (interfaceClass == void.class) {
Class[] interfaces = beanClass.getInterfaces();
if (interfaces.length >= 1) {
interfaceClass = interfaces[0];
} else {
throw new RPCException(ErrorEnum.SERVICE_DID_NOT_IMPLEMENT_ANY_INTERFACE,"该服务 {} 未实现任何服务接口", beanClass);
}
}
ServiceConfig注意ServiceConfig在初始化之后会马上调用export把这个服务在本地暴露出去。
public void export() {
Invoker invoker = applicationConfig.getProxyFactoryInstance().getInvoker(ref, interfaceClass);
exporter = protocolConfig.getProtocolInstance().export(invoker, this);
} 同样分为两步,第一步是获取对接口实现类抽象了之后的Invoker,第二步是在Protocol处将invoker进行本地暴露。具体实现看下面各层。
Proxy层实现细节
先看提供给上层的接口:
public interface RPCProxyFactory {
<T> T createProxy(Invoker<T> invoker);
<T> Invoker<T> getInvoker(T proxy, Class<T> type);
}createProxy是提供给consumer端,用于对一个ClusterInvoker生成一个代理。
public <T> T createProxy(Invoker<T> invoker) {
if (cache.containsKey(invoker.getInterface())) {
return (T) cache.get(invoker.getInterface());
}
T t = doCreateProxy(invoker.getInterface(),invoker);
cache.put(invoker.getInterface(),t);
return t;
}createProxy(ConsumerSide)
因为ClusterInvoker是接口维度的,代理也会跟着ClusterInvoker变为接口维度的,所以这里做了一层缓存,下面看doCreateProxy:
protected T doCreateProxy(Class interfaceClass, Invoker invoker) {
return (T) Proxy.newProxyInstance(
invoker.getInterface().getClassLoader(),
new Class[]{invoker.getInterface()},
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 创建并初始化 RPC 请求
if ("toString".equals(method.getName()) && method.getParameterTypes().length == 0) {
return invoker.toString();
}
if ("hashCode".equals(method.getName()) && method.getParameterTypes().length == 0) {
return invoker.hashCode();
}
if ("equals".equals(method.getName()) && method.getParameterTypes().length == 1) {
return invoker.equals(args[0]);
}
RPCRequest request = new RPCRequest();
log.info("调用服务:{} {}", method.getDeclaringClass().getName(), method.getName());
request.setRequestId(UUID.randomUUID().toString());
request.setInterfaceName(method.getDeclaringClass().getName());
request.setMethodName(method.getName());
request.setParameterTypes(method.getParameterTypes());
request.setParameters(args);
// 通过 RPC 客户端发送 RPC 请求并获取 RPC 响应
// ClusterInvoker
RPCInvokeParam invokeParam = RPCInvokeParam.builder()
.rpcRequest(request)
.referenceConfig(ReferenceConfig.getReferenceConfigByInterfaceName(method.getDeclaringClass().getName()))
.build();
RPCResponse response = invoker.invoke(invokeParam);
if (response == null) {
// callback,oneway,async
return null;
} else {
return response.getResult();
}
}
}
);
} 这里就可以看到我们整个服务调用的入口点了,生成的代理做的事情就是把参数等包装为RPCRequest,然后交给ClusterInvoker来进行下一步的调用。
getInvoker(ProviderSide)
public Invoker getInvoker(T proxy, Class type) {
return new AbstractInvoker() {
@Override
public Class getInterface() {
return type;
}
@Override
public String getInterfaceName() {
return type.getName();
}
@Override
public RPCResponse invoke(InvokeParam invokeParam) throws RPCException {
RPCResponse response = new RPCResponse();
try {
Method method = proxy.getClass().getMethod(invokeParam.getMethodName(), invokeParam.getParameterTypes());
response.setRequestId(invokeParam.getRequestId());
response.setResult(method.invoke(proxy, invokeParam.getParameters()));
} catch (Exception e) {
response.setCause(e);
}
return response;
}
};
} 对provider来说,接口的实现类是已有的,我们这里做的没有实际作用,只是为了抽象,把所有调用者都封装为Invoker。
Registry层实现细节
先看一下向上层提供的接口:
public interface ServiceRegistry {
void init();
void discover(String interfaceName, ServiceURLRemovalCallback callback, ServiceURLAddOrUpdateCallback serviceURLAddOrUpdateCallback);
void register(String address,String interfaceName);
void close();
}discover是针对于consumer的,根据接口来从注册中心发现提供了该接口服务的所有服务器,然后调用回调方法进行相应处理;register是针对于provider的,将本地地址以及接口注册到注册中心。
这里分层其实做的不够好,调用Registry的其实是Cluster层的ClusterInvoker以及Protocol层。这里先介绍一下Registry的实现吧。
目前ServiceRegistry只有Zookeeper一种实现。
discover调用的方法是watchInterface。
/**
* 数据格式:
* /toy/AService/192.168.1.1:1221 -> 192.168.1.1:1221
* /toy/AService/192.168.1.2:1221 -> 192.168.1.2:1221
* /toy/BService/192.168.1.3:1221 -> 192.168.1.3:1221
*
*
* 两个回调方法,ServiceURLRemovalCallback
*/
private void watchInterface(String interfaceName, ServiceURLRemovalCallback serviceURLRemovalCallback, ServiceURLAddOrUpdateCallback serviceURLAddOrUpdateCallback) {
try {
String path = generatePath(interfaceName);
List addresses = zkSupport.getChildren(path, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeChildrenChanged) {
watchInterface(interfaceName, serviceURLRemovalCallback, serviceURLAddOrUpdateCallback);
}
}
});
log.info("interfaceName:{} -> addresses:{}", interfaceName, addresses);
List dataList = new ArrayList<>();
for (String node : addresses) {
dataList.add(watchService(interfaceName, node, serviceURLAddOrUpdateCallback));
}
log.info("node data: {}", dataList);
serviceURLRemovalCallback.removeNotExisted(dataList);
LockSupport.unpark(discoveringThread);
} catch (KeeperException | InterruptedException e) {
throw new RPCException(ErrorEnum.REGISTRY_ERROR,"ZK故障", e);
}
}
private ServiceURL watchService(String interfaceName, String address, ServiceURLAddOrUpdateCallback serviceURLAddOrUpdateCallback) {
String path = generatePath(interfaceName);
try {
byte[] bytes = zkSupport.getData(path + "/" + address, new Watcher() {
@Override
public void process(WatchedEvent event) {
if (event.getType() == Event.EventType.NodeDataChanged) {
watchService(interfaceName, address, serviceURLAddOrUpdateCallback);
}
}
});
ServiceURL serviceURL = ServiceURL.parse(new String(bytes, CharsetConst.UTF_8));
serviceURLAddOrUpdateCallback.addOrUpdate(serviceURL);
return serviceURL;
} catch (KeeperException | InterruptedException e) {
throw new RPCException(ErrorEnum.REGISTRY_ERROR,"ZK故障", e);
}
}
private static String generatePath(String interfaceName) {
return new StringBuilder(ZK_REGISTRY_PATH).append("/").append(interfaceName).toString();
} 主要逻辑是在/toy/interface这个目录下面寻找所有的目录节点,每个目录节点代表了一个服务器,然后读取每个目录节点下的数据节点,拿到地址以及配置信息。并且会监听/toy/interface的子节点变更事件,如果有服务器上线或下线,将会通知我们应用来开启/关闭相应的Client(transport层);如果有某个服务器的配置信息变更,也会通知应用来修改Client的配置(后面我们会介绍ServiceURL这个概念)。
Cluster层实现细节
该层主要分为三个组件,一个是ClusterInvoker,也就是集群的服务调用者,负责维护该接口的所有的服务器实现;另一个是LoadBalancer,主要负责维护所有接口以及其对应的ClusterInvoker,以及进行负载均衡的选择,即多个协议Invoker(该接口的具体某个服务器实现)中如何选择一个Invoker去进行调用;还有一个是FaultToleranceHandler,它是无状态的,仅负责集群容错。
LoadBalancer
主要关注两点,一点是在ReferenceConfig中的referCluster方法的具体实现,即创建ClusterInvoker;另一点是若干负载均衡算法的实现。
public abstract class AbstractLoadBalancer implements LoadBalancer {
private GlobalConfig globalConfig;
/**
* key是接口名,value的key是IP地址,value是Endpoint
*
* 一种可能的格式:
* key : AService, value: 192.168.1.1,Endpoint1
* 192.168.1.2,Endpoint2
* key : BService, value: 192.168.1.1,Endpoint1
*/
private Map interfaceInvokers = new ConcurrentHashMap<>();
/**
* 分配address的形式
*
* @param referenceConfig
* @param
* @return
*/
@Override
public Invoker referCluster(ReferenceConfig referenceConfig) {
String interfaceName = referenceConfig.getInterfaceName();
ClusterInvoker clusterInvoker;
if (!interfaceInvokers.containsKey(interfaceName)) {
clusterInvoker = new ClusterInvoker(referenceConfig.getInterfaceClass(), interfaceName, globalConfig);
interfaceInvokers.put(interfaceName, clusterInvoker);
return clusterInvoker;
}
return interfaceInvokers.get(interfaceName);
}
} referCluster与ReferenceConfig、ProxyFactory类似,都做了接口维度的缓存,避免重复创建。
下面介绍几种负载均衡算法:
LeastActiveLoadBalancer(最小活跃度)
简单地说,就是在一个服务方法的调用前计数++,调用后计数–。当我们选择Invoker时,会选择计数值最小的,一般就是处理速度最快的Invoker,主要看中负载这个点。
这个算法是基于一个ActiveLimitFilter收集的数据进行判断的。
public class ActiveLimitFilter implements Filter {
@Override
public RPCResponse invoke(Invoker invoker, InvokeParam invokerParam) throws RPCException {
RPCResponse result = null;
try {
log.info("starting,incCount...,{}",invokerParam);
RPCStatus.incCount(invokerParam.getInterfaceName(), invokerParam.getMethodName(), invoker.getServiceURL().getAddress());
result = invoker.invoke(invokerParam);
} catch (RPCException e) {
log.info("catch exception,decCount...,{}",invokerParam);
RPCStatus.decCount(invokerParam.getInterfaceName(), invokerParam.getMethodName(), invoker.getServiceURL().getAddress());
throw e;
}
log.info("finished,decCount...,{}",invokerParam);
RPCStatus.decCount(invokerParam.getInterfaceName(), invokerParam.getMethodName(), invoker.getServiceURL().getAddress());
return result;
}
}然后是算法实现:
public class LeastActiveLoadBalancer extends AbstractLoadBalancer {
@Override
protected Invoker doSelect(List invokers, RPCRequest request) {
Invoker target = null;
int least = 0;
for (Invoker invoker : invokers) {
int current = RPCStatus.getCount(request.getInterfaceName(), request.getMethodName(), invoker.getServiceURL().getAddress());
log.info("requestId:" + request.getRequestId() + ",invoker:{},count:{}", invoker.getServiceURL().getAddress(), Integer.valueOf(current));
if (target == null || current < least) {
target = invoker;
least = current;
}
}
return target;
}
} 遍历一遍Invoker,返回计数值最小的那个invoker,时间复杂度为O(n)。
WeightedRandomLoadBalancer(带权重的随机)
简单地说就是每个Invoker都对应一个权重值,默认值为100,取值范围是0~100,0就是不会被调用。我们在所有Invoker的权重值之和的区间内随机一个数字,看它是落在哪个Invoker对应的区间内即可。
它同样也是需要依赖注册中心的配置信息的,即ServiceURL。数据节点(对应一个接口的一个服务器实现)的格式是address?param1=value1¶m2=value2,即queryString格式。
public final class ServiceURL {
private String address;
private Map> params = new HashMap<>();
public static ServiceURL DEFAULT_SERVICE_URL;
static {
try {
DEFAULT_SERVICE_URL = new ServiceURL(InetAddress.getLocalHost().getHostAddress());
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
/**
* 获取地址
*
* @return
*/
public String getAddress() {
return address;
}
/**
* 是否存在该key
*
* @param key
* @return
*/
public boolean containsKey(Key key) {
return params.containsKey(key);
}
/**
* 获取key对应的value,如果不存在,则返回默认值,默认值至少是一个空的List,不会是null
*
* @param key
* @return
*/
public List getKey(Key key) {
return params.containsKey(key) ? params.get(key) : key.getDefaultValues();
}
private ServiceURL() {
}
private ServiceURL(String address) {
this.address = address;
}
public static ServiceURL parse(String data) {
ServiceURL serviceURL = new ServiceURL();
String[] urlSlices = data.split("\\?");
serviceURL.address = urlSlices[0];
//解析URL参数
if (urlSlices.length > 1) {
String params = urlSlices[1];
String[] urlParams = params.split("&");
for (String param : urlParams) {
String[] kv = param.split("=");
String key = kv[0];
Key keyEnum = Key.valueOf(key.toUpperCase());
if (keyEnum != null) {
String[] values = kv[1].split(",");
serviceURL.params.put(keyEnum, Arrays.asList(values));
} else {
log.error("key {} 不存在 ", key);
}
}
}
return serviceURL;
}
public enum Key {
WEIGHT(Arrays.asList("100"));
private List defaultValues;
Key() {
}
Key(List defaultValues) {
this.defaultValues = defaultValues;
}
public List getDefaultValues() {
return defaultValues == null ? Collections.EMPTY_LIST : defaultValues;
}
}
}
然后看一下算法实现:
public class WeightedRandomLoadBalancer extends AbstractLoadBalancer {
/**
* 每个invoker有一个权值,从0~100,默认值均为100
* 假设有n个invoker,第i个invoker的权值为weight[i]。那么随机到该invoker的概率为
* weight[i]/sigma 0->n(weight[i])
*
* 比如说有4个invoker,权值分别为1,2,3,4
* 随机一个值,范围为[0,10)
* 如果是在[0,1) -> invoker[0]
* 如果是在[1,3) -> invoker[1]
* 如果是在[3,6) -> invoker[2]
* 如果是在[6.10) -> invoker[3]
* @param invokers
* @param request
* @return
*/
@Override
protected Invoker doSelect(List invokers, RPCRequest request) {
int sum = invokers.stream().mapToInt(invoker -> Integer.parseInt(invoker.getServiceURL().getKey(ServiceURL.Key.WEIGHT).get(0))).sum();
// 值不包含sum,所以最后一定有一个小于0的
int randomValue = ThreadLocalRandom.current().nextInt(sum);
for (Invoker invoker : invokers) {
int currentWeight = Integer.parseInt(invoker.getServiceURL().getKey(ServiceURL.Key.WEIGHT).get(0));
log.info("invoker:{},weight:{}",invoker.getServiceURL().getAddress(),currentWeight);
randomValue -= currentWeight;
if(randomValue < 0) {
return invoker;
}
}
return null;
}
} ClusterInvoker
ClusterInvoker与其他组件不同,它是一个实现类,只是实现了Invoker接口。其实ClusterInvoker是直接和注册中心打交道的组件,在初始化的时候就从注册中心拿到了该接口对应的服务器实现,并且都建立了客户端连接(为什么在初始化的时候而不是在初次进行方法调用的时候建立连接呢?其实这里就是对应了Dubbo中reference标签中的check=true/false配置,如果是true,那么就意味着consumer启动的时候,相应的provider就必须启动起来了。如果是在服务循环依赖的情况下,就只能设置check为false了。这点的可配置化后面会考虑做,现在就是默认check=true)。
注册中心
下面是与注册中心有关的代码,主要是看回调方法:
public class ClusterInvoker<T> implements Invoker<T> {
private Class interfaceClass;
private String interfaceName;
/**
* key是address,value是一个invoker
*/
private Map> addressInvokers = new ConcurrentHashMap<>();
private GlobalConfig globalConfig;
public ClusterInvoker(Class interfaceClass, String interfaceName, GlobalConfig globalConfig) {
this.interfaceClass = interfaceClass;
this.interfaceName = interfaceName;
this.globalConfig = globalConfig;
init();
}
//TODO 这里写的比较僵硬,如果是injvm协议,就完全不考虑注册中心了
private void init() {
if (globalConfig.getProtocol() instanceof InJvmProtocol) {
addOrUpdate(ServiceURL.DEFAULT_SERVICE_URL);
} else {
globalConfig.getServiceRegistry().discover(interfaceName, (newServiceURLs -> {
removeNotExisted(newServiceURLs);
}), (serviceURL -> {
addOrUpdate(serviceURL);
}));
}
}
/**
* addr1,addr2,addr3 -> addr2?weight=20,addr3,addr4
*
* 1) addOrUpdate(addr2) -> updateEndpointConfig(addr2)
* 2) addOrUpdate(addr3) -> updateEndpointConfig(addr3)
* 3) addOrUpdate(addr4) -> add(addr4)
* 4) removeNotExisted(addr2,addr3,addr4) -> remove(addr1)
*
* @param serviceURL
*/
private synchronized void addOrUpdate(ServiceURL serviceURL) {
// 地址多了/更新
// 更新
if (addressInvokers.containsKey(serviceURL.getAddress())) {
// 我们知道只有远程服务才有可能会更新
// 更新配置与invoker无关,只需要Protocol负责
//TODO refactor this
if (globalConfig.getProtocol() instanceof AbstractRemoteProtocol) {
AbstractRemoteProtocol protocol = (AbstractRemoteProtocol) globalConfig.getProtocol();
log.info("update config:{},当前interface为:{}", serviceURL, interfaceName);
protocol.updateEndpointConfig(serviceURL);
}
} else {
// 添加
// 需要修改
log.info("add invoker:{},serviceURL:{}", interfaceName, serviceURL);
Invoker invoker = globalConfig.getProtocol().refer(ReferenceConfig.getReferenceConfigByInterfaceName(interfaceName), serviceURL);
// refer拿到的是InvokerDelegate
addressInvokers.put(serviceURL.getAddress(), invoker);
}
}
public List getInvokers() {
// 拷贝一份返回
return new ArrayList<>(addressInvokers.values());
}
/**
* 在该方法调用前,会将新的加进来,所以这里只需要去掉新的没有的。
* 旧的一定包含了新的,遍历旧的,如果不在新的里面,则需要删掉
*
* @param newServiceURLs
*/
public synchronized void removeNotExisted(List newServiceURLs) {
Map newAddressesMap = newServiceURLs.stream().collect(Collectors.toMap(
url -> url.getAddress(), url -> url
));
// 地址少了
// 说明一个服务器挂掉了或出故障了,我们需要把该服务器对应的所有invoker都关掉。
for (Iterator>> it = addressInvokers.entrySet().iterator(); it.hasNext(); ) {
Map.Entry> curr = it.next();
if (!newAddressesMap.containsKey(curr.getKey())) {
log.info("remove address:{},当前interface为:{}", curr.getKey(), interfaceName);
if (globalConfig.getProtocol() instanceof AbstractRemoteProtocol) {
AbstractRemoteProtocol protocol = (AbstractRemoteProtocol) globalConfig.getProtocol();
protocol.closeEndpoint(curr.getKey());
}
it.remove();
}
}
}
} 我们这里设置了两个回调还是有点绕的,举个栗子解释一下:
假设存在这样一种情况,本接口原来有三个服务器提供服务,分别是addr1,addr2,addr3,后面变更为addr2?weght=20,addr3,addr4。
其实变化就是addr1挂掉了,修改了addr2的配置,然后新增了addr4。这个变更反应在回调上,就会调用以下方法:
1、addOrUpdate(addr2) -> updateEndpointConfig(addr2)
2、addOrUpdate(addr3) -> updateEndpointConfig(addr3)
3、addOrUpdate(addr4) -> add(addr4)
4、removeNotExisted(addr2,addr3,addr4) -> remove(addr1)
这样便会将ClusterInvoker下面维护的address与invoker的映射修改为最新的配置。
注意在新增的时候会调用Protocol层来创建协议Invoker,有可能还会创建响应的客户端连接。
服务调用
另一部分是服务调用,这部分会调用LoadBalancer进行invoker的选择,如果i调用失败,则会调用集群容错处理器来进行相应的处理。
/**
* 从可用的invoker中选择一个,如果没有或者不可用,则抛出异常
*
* @param availableInvokers
* @param invokeParam
* @return
*/
private Invoker doSelect(List availableInvokers, InvokeParam invokeParam) {
if (availableInvokers.size() == 0) {
log.error("未找到可用服务器");
throw new RPCException(ErrorEnum.NO_SERVER_AVAILABLE, "未找到可用服务器");
}
Invoker invoker;
if (availableInvokers.size() == 1) {
invoker = availableInvokers.get(0);
if (invoker.isAvailable()) {
return invoker;
} else {
log.error("未找到可用服务器");
throw new RPCException(ErrorEnum.NO_SERVER_AVAILABLE, "未找到可用服务器");
}
}
invoker = globalConfig.getLoadBalancer().select(availableInvokers, InvokeParamUtil.extractRequestFromInvokeParam(invokeParam));
if (invoker.isAvailable()) {
return invoker;
} else {
availableInvokers.remove(invoker);
return doSelect(availableInvokers, invokeParam);
}
}
@Override
public RPCResponse invoke(InvokeParam invokeParam) throws RPCException {
Invoker invoker = doSelect(getInvokers(), invokeParam);
RPCThreadLocalContext.getContext().setInvoker(invoker);
try {
// 这里只会抛出RPCException
RPCResponse response = invoker.invoke(invokeParam);
// response有可能是null,比如callback、oneway和future
if (response == null) {
return null;
}
// 不管是传输时候抛异常,还是服务端抛出异常,都算异常
if (response.hasError()) {
throw new RPCException(response.getCause(), ErrorEnum.SERVICE_INVOCATION_FAILURE, "invocation failed");
}
// 第一次就OK
return response;
} catch (RPCException e) {
// 重试后OK
// 在这里再抛出异常,就没有返回值了
return globalConfig.getFaultToleranceHandler().handle(this, invokeParam, e);
}
}
/**
* 这里不需要捕获invoker#invoke的异常,会由retryer来捕获
*
* @param availableInvokers
* @param invokeParam
* @return
*/
public RPCResponse invokeForFaultTolerance(List availableInvokers, InvokeParam invokeParam) {
Invoker invoker = doSelect(availableInvokers, invokeParam);
RPCThreadLocalContext.getContext().setInvoker(invoker);
// 这里只会抛出RPCException
RPCResponse response = invoker.invoke(invokeParam);
if (response == null) {
return null;
}
// 不管是传输时候抛异常,还是服务端抛出异常,都算异常
if (response.hasError()) {
throw new RPCException(response.getCause(), ErrorEnum.SERVICE_INVOCATION_FAILURE, "invocation failed");
}
return response;
} 逻辑很清晰,如果是初次调用失败(比如网络传输请求失败,以及服务端调用服务失败),那么交给FaultToleranceHandler来处理。
在ThreadLocal中设置当前Invoker是为了FailOver而设置的。
FaultToleranceHandler
先看一下接口定义:
/**
* @author sinjinsong
* @date 2018/7/22
* 无状态
* 注意!
* 集群容错只对同步调用有效
*/
public interface FaultToleranceHandler {
RPCResponse handle(ClusterInvoker clusterInvoker, InvokeParam invokeParam,RPCException e);
}这里注意一点,如果是oneway、callback、future等方式,协议invoker(负载均衡选出来的invoker)的invoke返回值是null,没有办法去根据是否响应信息里有异常来判断是否OK,所以作用不大,只能照顾到网络传输失败的情况了。
这里以FailOver,也就是失败自动切换为例,看一下实现:
/**
* @author sinjinsong
* @date 2018/7/22
*
* 如果有4个invoker,invoker0~invoker3
* 先调用loadbalancer选出一个invoker,如果失败,则retry
* retry0:从全部invoker去掉调用失败的invoker,再调用loadbalancer,选出一个invoker
* 如果全部去掉,还没有调用成功;或者超时重试次数,则抛出RPCException,结束
*/
@Slf4j
public class FailOverFaultToleranceHandler implements FaultToleranceHandler {
@Override
public RPCResponse handle(ClusterInvoker clusterInvoker, InvokeParam invokeParam,RPCException e) {
log.error("出错,FailOver! requestId:{}", invokeParam.getRequestId());
Invoker failedInvoker = RPCThreadLocalContext.getContext().getInvoker();
Map excludedInvokers = new HashMap<>();
excludedInvokers.put(failedInvoker.getServiceURL().getAddress(), failedInvoker);
try {
return retry(excludedInvokers, clusterInvoker, invokeParam);
} catch (ExecutionException e1) {
e1.printStackTrace();
} catch (RetryException e1) {
e1.printStackTrace();
log.info("超过出错重试次数,不再重试 requestId:{}", invokeParam.getRequestId());
throw new RPCException(e1,ErrorEnum.RETRY_EXCEED_MAX_TIMES, "超过出错重试次数 requestId:{}", invokeParam.getRequestId());
}
return null;
}
/**
* 实现重新连接的重试策略
* 一开始是等待5s,第二次是等待10s,再下一次是等待15s
* 但是在发现服务器地址时会等待10s,如果一直没有服务器信息变动的话
*
* @return
* @throws ExecutionException
* @throws RetryException
*/
private RPCResponse retry(Map excludedInvokers, ClusterInvoker clusterInvoker, InvokeParam invokeParam) throws ExecutionException, RetryException {
Retryer retryer = RetryerBuilder.newBuilder()
.retryIfException(
t -> {
// 如果一个异常是RPCException并且是没有服务,则不再重试
// 其他情况俊辉重试
if (t instanceof RPCException) {
RPCException rpcException = (RPCException) t;
if (rpcException.getErrorEnum() == ErrorEnum.NO_SERVER_AVAILABLE) {
return false;
}
}
return true;
}
) // 抛出Throwable时重试
.withWaitStrategy(WaitStrategies.incrementingWait(0, TimeUnit.SECONDS, 0, TimeUnit.SECONDS))
.withStopStrategy(StopStrategies.stopAfterAttempt(3)) // 重试3次后停止
.build();
return retryer.call(() -> {
log.info("开始本次重试...");
// 先拿到可用的invoker
List invokers = clusterInvoker.getInvokers();
for (Iterator it = invokers.iterator(); it.hasNext(); ) {
if (excludedInvokers.containsKey(it.next().getServiceURL().getAddress())) {
it.remove();
}
}
try {
return clusterInvoker.invokeForFaultTolerance(invokers, invokeParam);
} catch (RPCException e) {
Invoker failedInvoker = RPCThreadLocalContext.getContext().getInvoker();
// 再次调用失败,添加到排除列表中
excludedInvokers.put(failedInvoker.getServiceURL().getAddress(), failedInvoker);
throw e;
}
});
}
} FailOver的实现逻辑是如果当前invoker调用失败了,那么就把它放到黑名单里,进行重试,重新负载均衡,服务调用,如果再失败就继续重试,直至调用成功,或重试次数达到最大重试次数(默认3次),或没有可用的Invoker/服务器可以调用了。
这里设计其实是有一点问题的,为了实现FailOver,ClusterInvoker还专门提供了一个public方法来进行容错处理。而且接口中传入的也是ClusterInvoker类型的invoker,这其实是不够面向接口编程的,以后可以把它优化掉。
Protocol、Invocation、Filter层实现细节
协议层是整个rpc的核心,有几个比较重要的组件,比如Invoker、Filter、Invocation、Client、Server,都是和协议有关的。
我们先简单梳理一下它们之间的关系:
- Protocol会创建协议Invoker,比如ToyProtocol会创建一个ToyInvoker
- Protocol创建Invoker后返回的不是真正的Invoker,而是InvokerDelegate,这层代理主要是用于在Invoker外层包装Filter链实现的。
- Invoker是(interface,address)维度的,而Client则是address维度的,这一点说明有可能是多个Invoker,底层依赖是同一个Client。这就需要我们控制一下Client的创建,不能交给具体Protocol来做,需要由Abstract抽象层提供,避免对同一个服务器创建多个Client、连接多个连接。在大多数的情况下,对一个服务器只需要一个客户端连接,更多连接只会带来内存等消耗。
- 在Invoker调用时会创建一个Invocation对象,对应某一种调用方式,如同步、Future、Callback、Oneway等,由它进行调用,invocation之后会回调invoker,由invoker来处理与Client的交互(即发送数据),invocation不接触Client,仅由Invoker来与Client交互
- Protocol中如果有服务暴露,并且不是injvm协议的话,则会开启服务器,注意服务器也是不需要被开启多次的,同样需要有缓存机制来控制。另外比较重要的一点是,远程服务暴露必须要先启动服务器,然后再在注册中心中写入地址,否则会出现consumer能发现provider但是连接失败的情况。
Protocol
先看一下Protocol等组件的接口:
public interface Protocol {
/**
* 暴露服务
*
* @param invoker
* @param
* @return
* @throws RPCException
*/
Exporter export(Invoker invoker, ServiceConfig serviceConfig) throws RPCException;
/**
* 引用服务
*
* @param referenceConfig
* @param
* @return
* @throws RPCException
*/
Invoker refer(ReferenceConfig referenceConfig,ServiceURL serviceURL) throws RPCException;
/**
* 查找暴露的服务
*
* @param interfaceMame
* @param
* @return
* @throws RPCException
*/
ServiceConfig referLocalService(String interfaceMame) throws RPCException;
void close();
}
refer是引用远程服务,export是暴露本地服务,referLocalService是引用本地服务。
AbstractProtocol对Protocol提供了一层基础功能:
public abstract class AbstractProtocol implements Protocol {
private Map> exporters = new ConcurrentHashMap<>();
private GlobalConfig globalConfig;
public void init(GlobalConfig globalConfig) {
this.globalConfig = globalConfig;
}
protected GlobalConfig getGlobalConfig() {
return globalConfig;
}
protected void putExporter(Class interfaceClass, Exporter exporter) {
this.exporters.put(interfaceClass.getName(), exporter);
}
@Override
public ServiceConfig referLocalService(String interfaceMame) throws RPCException {
if (!exporters.containsKey(interfaceMame)) {
throw new RPCException(ErrorEnum.EXPOSED_SERVICE_NOT_FOUND,"未找到暴露的服务:{}", interfaceMame);
}
return (ServiceConfig) exporters.get(interfaceMame).getServiceConfig();
}
@Override
public void close() {
}
} 在服务器启动后接收到客户端的RPC请求后,会调用referLocalService方法来获得本地暴露出来的服务,从ServiceConfig中取出Invoker(对实现类实例进行了一层包装)进行服务调用。
在AbstractInvoker基础上还有一层抽象AbstractRemoteInvoker,对网络通信有一层支持,适用于非injvm协议的Protocol:
/**
* 为了更好地管理客户端连接,决定把endpoint移到protocol中。一个invoker对应一个endpoint的话是会对一个服务器
* 多出很多不必要的连接。
* 一个服务器只需要一个连接即可。
*
* @author sinjinsong
* @date 2018/7/26
*/
@Slf4j
public abstract class AbstractRemoteProtocol extends AbstractProtocol {
/**
* key是address,value是连接到该address上的Endpoint
*/
private Map clients = new ConcurrentHashMap<>();
private Map locks = new ConcurrentHashMap<>();
private Server server;
/**
* 初始化一个客户端
* 初始化客户端必须放在Protocol,不能放在invoker中,否则无法控制重复初始化的问题。
*
* @param serviceURL
* @return
*/
public final Client initClient(ServiceURL serviceURL) {
String address = serviceURL.getAddress();
locks.putIfAbsent(address, new Object());
synchronized (locks.get(address)) {
if (clients.containsKey(address)) {
return clients.get(address);
}
Client client = doInitClient(serviceURL);
clients.put(address, client);
locks.remove(address);
return client;
}
}
/**
* 更新一个客户端的配置
*
* @param serviceURL
*/
public final void updateClientConfig(ServiceURL serviceURL) {
if (!clients.containsKey(serviceURL.getAddress())) {
throw new RPCException(ErrorEnum.PROTOCOL_CANNOT_FIND_THE_SERVER_ADDRESS, "无法找到该地址{}", serviceURL);
}
clients.get(serviceURL.getAddress()).updateServiceConfig(serviceURL);
}
/**
* 关闭一个客户段
*
* @param address
*/
public final void closeEndpoint(String address) {
Client client = clients.remove(address);
if (client != null) {
log.info("首次关闭客户端:{}", address);
client.close();
} else {
log.info("重复关闭客户端:{}", address);
}
}
protected abstract Client doInitClient(ServiceURL serviceURL);
protected synchronized final void openServer() {
if(server == null) {
server = doOpenServer();
}
}
protected abstract Server doOpenServer();
@Override
public void close() {
clients.values().forEach(client -> client.close());
if(server != null) {
server.close();
}
}
} 然后以ToyProtocol为例,看它是如何refer和export的:
public class ToyProtocol extends AbstractRemoteProtocol {
@Override
public Exporter export(Invoker invoker, ServiceConfig serviceConfig) throws RPCException {
ToyExporter exporter = new ToyExporter<>();
exporter.setInvoker(invoker);
exporter.setServiceConfig(serviceConfig);
putExporter(invoker.getInterface(), exporter);
openServer();
// export
try {
serviceConfig.getRegistryConfig().getRegistryInstance().register(InetAddress.getLocalHost().getHostAddress() + ":" + getGlobalConfig().getPort(), serviceConfig.getInterfaceName());
} catch (UnknownHostException e) {
throw new RPCException(e, ErrorEnum.READ_LOCALHOST_ERROR, "获取本地Host失败");
}
return exporter;
}
@Override
public Invoker refer(ReferenceConfig referenceConfig, ServiceURL serviceURL) throws RPCException {
ToyInvoker invoker = new ToyInvoker<>();
invoker.setInterfaceClass(referenceConfig.getInterfaceClass());
invoker.setInterfaceName(referenceConfig.getInterfaceName());
invoker.setGlobalConfig(getGlobalConfig());
invoker.setClient(initClient(serviceURL));
return invoker.buildFilterChain(referenceConfig.getFilters());
}
@Override
protected Client doInitClient(ServiceURL serviceURL) {
ToyClient toyClient = new ToyClient();
toyClient.init(getGlobalConfig(), serviceURL);
return toyClient;
}
@Override
protected Server doOpenServer() {
ToyServer toyServer = new ToyServer();
toyServer.init(getGlobalConfig());
toyServer.run();
return toyServer;
}
}
refer方法有几个关键的步骤:
1、初始化客户端,注意这里的initClient的调用是考虑了缓存了,如果对该服务器已经了连接,则复用之前创建的链接
2、封装Filter链,这部分功能是在Invoker提供的,比在Protocol中提供更合适一些。返回的是封装了之后的Invoker对象,并不是简单的协议Protocol类型了。
export方法中需要关注的是先开启服务器,然后注册至注册中心的步骤。
Invoker
先看一下接口:
public interface Invoker {
Class getInterface();
String getInterfaceName();
RPCResponse invoke(InvokeParam invokeParam) throws RPCException;
/**
* 本地服务返回本地IP地址,参数为空;集群服务抛出异常;远程服务返回注册中心中的ServiceURL
* @return
*/
ServiceURL getServiceURL();
boolean isAvailable();
} 主要方法就是invoke,进行服务调用。下面看一下类似于Protocol的几层抽象。
AbstractInvoker提供了较多的功能,比如invoke方法的框架,以及封装Filter链等特性。
public RPCResponse invoke(InvokeParam invokeParam) throws RPCException {
Function> logic = getProcessor();
if(logic == null) {
// TODO 想办法在编译时检查
throw new RPCException(ErrorEnum.GET_PROCESSOR_MUST_BE_OVERRIDE_WHEN_INVOKE_DID_NOT_OVERRIDE,"没有重写AbstractInvoker#invoke方法的时候,必须重写getProcessor方法");
}
// 如果提交任务失败,则删掉该Endpoint,再次提交的话必须重新创建Endpoint
AbstractInvocation invocation;
ReferenceConfig referenceConfig = InvokeParamUtil.extractReferenceConfigFromInvokeParam(invokeParam);
RPCRequest rpcRequest = InvokeParamUtil.extractRequestFromInvokeParam(invokeParam);
if (referenceConfig.isAsync()) {
invocation = new AsyncInvocation() {
@Override
protected Future doCustomProcess() {
return logic.apply(rpcRequest);
}
};
} else if (referenceConfig.isCallback()) {
invocation = new CallbackInvocation() {
@Override
protected Future doCustomProcess() {
return logic.apply(rpcRequest);
}
};
} else if (referenceConfig.isOneWay()) {
invocation = new OneWayInvocation() {
@Override
protected Future doCustomProcess() {
return logic.apply(rpcRequest);
}
};
} else {
invocation = new SyncInvocation() {
@Override
protected Future doCustomProcess() {
return logic.apply(rpcRequest);
}
};
}
invocation.setReferenceConfig(referenceConfig);
invocation.setRpcRequest(rpcRequest);
return invocation.invoke();
}
/**
* 如果没有重写invoke方法,则必须重写该方法
*
* @return
*/
protected Function> getProcessor() {
return null;
}
/**
* 最终给ClusterInvoker的invoker,是用户接触到的invoker
*
* @param filters
* @param
* @return
*/
public Invoker buildFilterChain(List filters) {
// refer 得到的,包含了endpoint
return new InvokerDelegate((Invoker) this) {
// 比较的时候就是在比较interfaceClass
private ThreadLocal filterIndex = new ThreadLocal() {
@Override
protected Object initialValue() {
return new AtomicInteger(0);
}
};
@Override
public RPCResponse invoke(InvokeParam invokeParam) throws RPCException {
log.info("filterIndex:{}, invokeParam:{}", filterIndex.get().get(), invokeParam);
final Invoker invokerWrappedFilters = this;
if (filterIndex.get().get() < filters.size()) {
return filters.get(filterIndex.get().getAndIncrement()).invoke(new AbstractInvoker() {
@Override
public Class getInterface() {
return getDelegate().getInterface();
}
@Override
public String getInterfaceName() {
return getDelegate().getInterfaceName();
}
@Override
public ServiceURL getServiceURL() {
return getDelegate().getServiceURL();
}
@Override
public RPCResponse invoke(InvokeParam invokeParam) throws RPCException {
return invokerWrappedFilters.invoke(invokeParam);
}
}, invokeParam);
}
filterIndex.get().set(0);
return getDelegate().invoke(invokeParam);
}
};
} 有一点比较关键,也是之后的优化点,就是如果不覆盖getProcessor方法的话,就必须重写invoke方法,希望能做到编译时检测这一点,目前只能在运行时检测。原因很简单,invoke提供了调用方法的框架,它需要getProcessor来处理网络传输/本地调用,具体的Client是和传输层有关系了,应该放到更上一层来封装这一点。
另外是Filter链的封装,这里调用Filter的invoke方法时传入的Invoker不是真正的Invoker,而是对下一个Filter的调用,如此反复,直到最后一个Filter,它传入的invoker就是真正的协议Invoker。
在调用过程中需要记录Filter的索引,它是一个共享变量,需要保证并发环境下方法调用不会受到其他线程影响,所以用了ThreadLocal来存储这个index,性能也是不会影响多少的。
然后看一下AbstractRemoteInvoker,它是在AbstractInvoker基础上维护了一个Client对象,正式和传输层打交道。
public abstract class AbstractRemoteInvoker<T> extends AbstractInvoker<T> {
private Client client;
@Override
public ServiceURL getServiceURL() {
return getClient().getServiceURL();
}
/**
* 拿到一个invoker
* @return
*/
protected Client getClient() {
return client;
}
@Override
public boolean isAvailable() {
return getClient().isAvailable();
}
public void setClient(Client client) {
this.client = client;
}
}然后看一下ToyInvoker的getProcessor的实现:
public class ToyInvoker<T> extends AbstractRemoteInvoker<T> {
@Override
protected Function<RPCRequest, Future<RPCResponse>> getProcessor() {
return rpcRequest -> getClient().submit(rpcRequest);
}
}
其实这里逻辑就足够简化了,就是如何进行网络传输的问题了,直接交给client去传输就可以。
这一点HTTP协议和Toy协议的Invoker都基本是空的实现了,后面可以再抽象一下,还是有重复代码存在的。
Invocation
Invocation在toy-rpc里是调用方式的抽象,如同步、异步等,每个请求都会创建一个Invocation对象。
接口是非常简单的:
public interface Invocation {
RPCResponse invoke() throws RPCException;
}先看一下抽象的Invocation:
public abstract class AbstractInvocation implements Invocation {
private ReferenceConfig referenceConfig;
private RPCRequest rpcRequest;
public final void setReferenceConfig(ReferenceConfig referenceConfig) {
this.referenceConfig = referenceConfig;
}
public final void setRpcRequest(RPCRequest rpcRequest) {
this.rpcRequest = rpcRequest;
}
/**
* 留给Sync/Oneway/Async/Callback的子类去覆盖,用来获取远程调用结果
*
* @return
*/
protected abstract Future doCustomProcess();
@Override
public final RPCResponse invoke() throws RPCException {
RPCResponse response;
try {
response = doInvoke();
} catch (Throwable e) {
e.printStackTrace();
throw new RPCException(e,ErrorEnum.TRANSPORT_FAILURE, "transport异常");
}
return response;
}
/**
* 执行对应子类的调用逻辑,可以抛出任何异常
*
* @return
* @throws Throwable
*/
protected abstract RPCResponse doInvoke() throws Throwable;
public final ReferenceConfig getReferenceConfig() {
return referenceConfig;
}
public final RPCRequest getRpcRequest() {
return rpcRequest;
}
}
doInvoke方法由子类实现,也是模板方法模式的应用。
以同步调用为例:
public abstract class SyncInvocation extends AbstractInvocation {
@Override
protected RPCResponse doInvoke() throws Throwable {
Future future = doCustomProcess();
RPCResponse response = future.get(getReferenceConfig().getTimeout(), TimeUnit.MILLISECONDS);
log.info("客户端读到响应:{}", response);
return response;
}
} 注意同步、异步等Invocation还是一个Invocaiton,其doCustomProcess其实就是Invoker的回调,需要Invoker拿到Client来进行网络传输,Invocation不适合直接接触Client。
然后是同步调用的特性,就是在请求传输之后对当前线程进行阻塞,在读取到服务器的响应时再唤醒该线程,其实就是一个Future的运用,把Future放在一个全局的Map中,收到响应根据唯一的RequestId取出这个Future,设置response。
在Client层会有这样的实现:
CompletableFuture responseFuture = new CompletableFuture<>();
RPCThreadSharedContext.registerResponseFuture(request.getRequestId(), responseFuture); 这里就是创建future,然后放到全局Map中,如果我们调用future的get方法,那么在没有收到响应前,当前线程是阻塞的。CompletableFuture是设计得比较好的一种Future,get时会先尝试自旋,而不是直接阻塞,自旋一定时间后还没有拿到response,再进行阻塞。
在实际创建Invocation时去覆盖doCustomProcess方法,看一个例子:
invocation = new SyncInvocation() {
@Override
protected Future doCustomProcess() {
return logic.apply(rpcRequest);
}
}; logic是Function 就是Invoker的getProcessor返回的Function,它来调用Client进行数据传输。
#### Transport层实现细节
传输层简单地说就是Client和Server。Client是在Protocol#refer时被创建,然后被Protocol和RemoteInvoker持有。Server是在Protocol#export时被创建,然后被Protocol持有。
Client
Client是consumer用来向provider发送请求的,处理provider的响应(有可能是回调请求)。
先看一下Client的接口:
public interface Client {
Future submit(RPCRequest request);
void close();
ServiceURL getServiceURL();
void handleException(Throwable throwable);
void handleCallbackRequest(RPCRequest request, ChannelHandlerContext ctx);
void handleRPCResponse(RPCResponse response);
boolean isAvailable();
void updateServiceConfig(ServiceURL serviceURL);
}
submit用来发送请求,handleRPCResponse用来处理正常响应,handleCallbackRequest用来处理回调请求,updateServiceConfig是用来更新ServiceURL的,其中封装了参数信息。
Client类似于Protocol和Invoker,也有两层的抽象,AbstractClient用来维护GlobalConfig和ServiceURL。
public abstract class AbstractClient implements Client {
private ServiceURL serviceURL;
private GlobalConfig globalConfig;
public void init(GlobalConfig globalConfig, ServiceURL serviceURL) {
this.serviceURL = serviceURL;
this.globalConfig = globalConfig;
// 初始化的时候建立连接,才能检测到服务器是否可用
connect();
}
protected abstract void connect();
protected GlobalConfig getGlobalConfig() {
return globalConfig;
}
public ServiceURL getServiceURL() {
return serviceURL;
}
@Override
public void updateServiceConfig(ServiceURL serviceURL) {
this.serviceURL = serviceURL;
}
}
我们支持了HTTP和TCP协议,底层都是基于Netty实现的,Netty本身的pipeline机制使得创建一个不同协议的服务器只需要关心handler即可。所以我们把Netty的Client又进行了一层抽象,抽象为AbstractNettyClient:
public abstract class AbstractNettyClient extends AbstractClient {
private Bootstrap bootstrap;
private Channel futureChannel;
private EventLoopGroup group;
private volatile boolean initialized = false;
private volatile boolean destroyed = false;
private MessageConverter converter;
/**
* 与Handler相关
*
* @return
*/
protected abstract ChannelInitializer initPipeline();
/**
* 与将Message转为Object类型的data相关
*
* @return
*/
protected abstract ClientMessageConverter initConverter();
@Override
public boolean isAvailable() {
return initialized && !destroyed;
}
@Override
protected synchronized void connect() {
if (initialized) {
return;
}
this.converter = initConverter();
this.group = new NioEventLoopGroup();
this.bootstrap = new Bootstrap();
this.bootstrap.group(group).channel(NioSocketChannel.class)
.handler(initPipeline())
.option(ChannelOption.SO_KEEPALIVE, true);
try {
ChannelFuture future;
String address = getServiceURL().getAddress();
String host = address.split(":")[0];
Integer port = Integer.parseInt(address.split(":")[1]);
future = bootstrap.connect(host, port).sync();
this.futureChannel = future.channel();
log.info("客户端已连接至 {}", address);
log.info("客户端初始化完毕");
initialized = true;
} catch (Exception e) {
log.error("与服务器的连接出现故障");
e.printStackTrace();
handleException(e);
}
}
/**
* 连接失败或IO时失败均会调此方法处理异常
*/
@Override
public void handleException(Throwable throwable) {
log.info("连接失败策略为直接关闭,关闭客户端");
log.error("",throwable);
close();
throw new RPCException(ErrorEnum.CONNECT_TO_SERVER_FAILURE, "连接失败,关闭客户端");
}
@Override
public void handleCallbackRequest(RPCRequest request, ChannelHandlerContext ctx) {
// callback
ServiceConfig serviceConfig = RPCThreadSharedContext.getAndRemoveHandler(
CallbackInvocation.generateCallbackHandlerKey(request)
);
getGlobalConfig().getClientExecutor()
.submit(new RPCTaskRunner(ctx, request, serviceConfig, converter));
}
@Override
public void handleRPCResponse(RPCResponse response) {
CompletableFuture future = RPCThreadSharedContext.getAndRemoveResponseFuture(response.getRequestId());
future.complete(response);
}
/**
* 提交请求
*
* @param request
* @return
*/
@Override
public Future submit(RPCRequest request) {
if (!initialized) {
connect();
initialized = true;
}
if (destroyed) {
throw new RPCException(ErrorEnum.SUBMIT_AFTER_ENDPOINT_CLOSED, "当前Endpoint: {} 关闭后仍在提交任务", getServiceURL().getAddress());
}
log.info("客户端发起请求: {},请求的服务器为: {}", request, getServiceURL().getAddress());
CompletableFuture responseFuture = new CompletableFuture<>();
RPCThreadSharedContext.registerResponseFuture(request.getRequestId(), responseFuture);
Object data = converter.convert2Object(Message.buildRequest(request));
this.futureChannel.writeAndFlush(data);
log.info("请求已发送至{}", getServiceURL().getAddress());
return responseFuture;
}
/**
* 如果该Endpoint不提供任何服务,则将其关闭
* 要做成幂等的,因为多个invoker都对应一个endpoint,当某个服务器下线时,可能会有多个interface(ClusterInvoker)
* 都检测到地址变更,所以会关闭对应的invoker。
*/
@Override
public void close() {
try {
if (this.futureChannel != null && futureChannel.isOpen()) {
this.futureChannel.close().sync();
}
destroyed = true;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (group != null && !group.isShuttingDown() && !group.isShutdown() && !group.isTerminated()) {
group.shutdownGracefully();
}
}
}
} 我们设置了两个抽象方法必须让子类实现,一个是pipeline,一个是converter。
converter不是编解码,编解码是对象与字节数组之间的转换,而converter是对象与对象之间的转换。对于TCP协议来说,converter是空的实现,不需要进行对象转换;对于HTTP协议来说,需要把请求对象(Message)转为DefaultFullHttpRequest,以及把FullHttpResponse转为响应对象(Message)。
以HTTP协议为例,看一下HTTPClient的实现:
public class HttpClient extends AbstractNettyClient {
@Override
protected ChannelInitializer initPipeline() {
HttpClientHandler.init(HttpClient.this, HttpClientMessageConverter.getInstance(getGlobalConfig().getSerializer()));
log.info("HttpClient initPipeline...");
return new ChannelInitializer() {
@Override
public void initChannel(SocketChannel channel) throws Exception {
channel.pipeline()
// 客户端会发出请求,接收响应;也有可能会接收请求(但消息体也是响应,callback)
// 服务器会接收请求,发出响应,也有可能会发出请求(但消息体也是响应,callback)
.addLast("HttpRequestEncoder", new HttpRequestEncoder())
.addLast("HttpResponseDecoder", new HttpResponseDecoder())
.addLast("HttpObjectAggregator",new HttpObjectAggregator(10*1024*1024))
.addLast("HttpClientHandler", HttpClientHandler.getInstance());
}
};
}
@Override
protected HttpClientMessageConverter initConverter() {
return HttpClientMessageConverter.getInstance(getGlobalConfig().getSerializer());
}
} 注意pipeline中有两个inboundHandler,分别是HttpResponseDecoder和HttpObjectAggregator,经过这两个handler的处理,我们就可以拿到一个FullHttpRequest对象。
然后看下一下converter的实现。
public class HttpClientMessageConverter extends ClientMessageConverter {
private static HttpClientMessageConverter ourInstance = new HttpClientMessageConverter();
private Serializer serializer;
public static HttpClientMessageConverter getInstance(Serializer serializer) {
ourInstance.serializer = serializer;
return ourInstance;
}
/**
* 对于服务器,返回的一定是响应;
* 对于客户端,返回的一定是请求;
* 而不是根据message是request 或者 response
*
*
* 把消息转为request
* @param message
* @return
*/
@Override
public Object convertMessage2Request(Message message) {
byte[] body = serializer.serialize(message);
DefaultFullHttpRequest request;
try {
String uri = "http://" + message.getRequest().getInterfaceName();
request = new DefaultFullHttpRequest(
HttpVersion.HTTP_1_1, HttpMethod.POST, uri, Unpooled.wrappedBuffer(body));
request.headers().set(HttpHeaders.Names.HOST, InetAddress.getLocalHost().getHostAddress());
request.headers().set(HttpHeaders.Names.CONTENT_LENGTH, request.content().readableBytes());
return request;
} catch (UnknownHostException e) {
e.printStackTrace();
}
return null;
}
/**
* 把response转为消息
* @param response
* @return
*/
@Override
public Message convertResponse2Message(Object response) {
if (response instanceof FullHttpResponse) {
FullHttpResponse fullHttpResponse = (FullHttpResponse) response;
byte[] body = new byte[fullHttpResponse.content().readableBytes()];
fullHttpResponse.content().getBytes(0, body);
log.info("response:{}", fullHttpResponse);
return serializer.deserialize(body, Message.class);
}
return null;
}
}对于TCP协议而言,直接把Message转为字节数组传输过去即可,但是HTTP协议需要符合HTTP协议标准,将Message转为字节数组是需要放在HTTP的body里的,除此之外还要设置HTTP的header,最后把整个HTTPRequest转为字节数组传输过去。响应同理。
Server
凡是当前应用有一处暴露了远程服务,我们就会启动服务器。
先看一下Server的接口:
public interface Server {
void run();
void handleRPCRequest(RPCRequest request, ChannelHandlerContext ctx);
void close();
}分别是启动,处理来自客户端的RPC请求,最后是关闭。
这里其实还是可以再优化一下,不要让Server接口强依赖于Netty的实现细节,把ChannelHandlerContext再封装一下。
public abstract class AbstractServer implements Server {
private GlobalConfig globalConfig;
public void init(GlobalConfig globalConfig) {
this.globalConfig = globalConfig;
doInit();
}
protected GlobalConfig getGlobalConfig() {
return globalConfig;
}
protected abstract void doInit();
}
同样是两层抽象,再看一下AbstractNettyServer:
public abstract class AbstractNettyServer extends AbstractServer {
private ChannelInitializer channelInitializer;
private ServerMessageConverter serverMessageConverter;
private ChannelFuture channelFuture;
private EventLoopGroup bossGroup;
private EventLoopGroup workerGroup;
@Override
protected void doInit() {
this.channelInitializer = initPipeline();
this.serverMessageConverter = initConverter();
}
protected abstract ChannelInitializer initPipeline();
/**
* 与将Message转为Object类型的data相关
*
* @return
*/
protected abstract ServerMessageConverter initConverter();
@Override
public void run() {
//两个事件循环器,第一个用于接收客户端连接,第二个用于处理客户端的读写请求
//是线程组,持有一组线程
bossGroup = new NioEventLoopGroup(1);
workerGroup = new NioEventLoopGroup();
try {
//服务器辅助类,用于配置服务器
ServerBootstrap bootstrap = new ServerBootstrap();
//配置服务器参数
bootstrap.group(bossGroup, workerGroup)
//使用这种类型的NIO通道,现在是基于TCP协议的
.channel(NioServerSocketChannel.class)
//对Channel进行初始化,绑定实际的事件处理器,要么实现ChannelHandler接口,要么继承ChannelHandlerAdapter类
.childHandler(channelInitializer)
//服务器配置项
//BACKLOG
//TCP维护有两个队列,分别称为A和B
//客户端发送SYN,服务器接收到后发送SYN ACK,将客户端放入到A队列
//客户端接收到后再次发送ACK,服务器接收到后将客户端从A队列移至B队列,服务器的accept返回。
//A和B队列长度之和为backlog
//当A和B队列长度之和大于backlog时,新的连接会被TCP内核拒绝
//注意:backlog对程序的连接数并无影响,影响的只是还没有被accept取出的连接数。
.option(ChannelOption.SO_BACKLOG, 128)
//指定发送缓冲区大小
.option(ChannelOption.SO_SNDBUF, 32 * 1024)
//指定接收缓冲区大小
.option(ChannelOption.SO_RCVBUF, 32 * 1024);
//这里的option是针对于上面的NioServerSocketChannel
//复杂的时候可能会设置多个Channel
//.sync表示是一个同步阻塞执行,普通的Netty的IO操作都是异步执行的
//一个ChannelFuture代表了一个还没有发生的I/O操作。这意味着任何一个请求操作都不会马上被执行
//Netty强烈建议直接通过添加监听器的方式获取I/O结果,而不是通过同步等待(.sync)的方式
//如果用户操作调用了sync或者await方法,会在对应的future对象上阻塞用户线程
//绑定端口,开始监听
//注意这里可以绑定多个端口,每个端口都针对某一种类型的数据(控制消息,数据消息)
String host = InetAddress.getLocalHost().getHostAddress();
this.channelFuture = bootstrap.bind(host, getGlobalConfig().getPort()).sync();
//应用程序会一直等待,直到channel关闭
log.info("服务器启动,当前服务器类型为:{}",this.getClass().getSimpleName());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
@Override
public void close() {
getGlobalConfig().getRegistryConfig().close();
if(workerGroup != null) {
workerGroup.shutdownGracefully();
}
if(bossGroup != null) {
bossGroup.shutdownGracefully();
}
if(channelFuture != null) {
channelFuture.channel().close();
}
}
@Override
public void handleRPCRequest(RPCRequest request, ChannelHandlerContext ctx) {
getGlobalConfig().getServerExecutor().submit(new RPCTaskRunner(ctx, request, getGlobalConfig().getProtocol().referLocalService(request.getInterfaceName()), serverMessageConverter));
}
}
这里就涉及了请求是如何处理的,分为两步:
1、获取本地暴露的服务
2、放入业务线程池来进行方法调用、响应写回。
RPCTaskRunner是一个Runnable,客户端、服务器都会依赖它来进行方法调用。
public class RPCTaskRunner implements Runnable {
private ChannelHandlerContext ctx;
private RPCRequest request;
private ServiceConfig serviceConfig;
private MessageConverter messageConverter;
public RPCTaskRunner(ChannelHandlerContext ctx, RPCRequest request, ServiceConfig serviceConfig, MessageConverter messageConverter) {
this.ctx = ctx;
this.request = request;
this.serviceConfig = serviceConfig;
this.messageConverter = messageConverter;
}
@Override
public void run() {
// callback的会以代理的方式调用
if (serviceConfig.isCallback()) {
try {
handle(request);
} catch (Throwable t) {
t.printStackTrace();
}
return;
}
RPCResponse response = new RPCResponse();
response.setRequestId(request.getRequestId());
try {
Object result = handle(request);
response.setResult(result);
} catch (Throwable t) {
t.printStackTrace();
response.setCause(t);
}
log.info("已调用完毕服务,结果为: {}", response);
if (!serviceConfig.isCallbackInterface()) {
// 如果自己这个接口是一个回调接口,则无需响应
Object data = messageConverter.convert2Object(Message.buildResponse(response));
// 这里调用ctx的write方法并不是同步的,也是异步的,将该写入操作放入到pipeline中
ctx.writeAndFlush(data);
}
}
/**
* 反射调用方法
*
* @param request
* @return
* @throws Throwable
*/
private Object handle(RPCRequest request) throws Throwable {
Object serviceBean = serviceConfig.getRef();
Class serviceClass = serviceBean.getClass();
String methodName = request.getMethodName();
Class[] parameterTypes = request.getParameterTypes();
Object[] parameters = request.getParameters();
Method method = serviceClass.getMethod(methodName, parameterTypes);
method.setAccessible(true);
// 针对callback参数,要将其设置为代理对象
if (serviceConfig.isCallback()) {
Class interfaceClass = parameterTypes[serviceConfig.getCallbackParamIndex()];
parameters[serviceConfig.getCallbackParamIndex()] = Proxy.newProxyInstance(
interfaceClass.getClassLoader(),
new Class[]{interfaceClass},
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals(serviceConfig.getCallbackMethod())) {
// 创建并初始化 RPC 请求
RPCRequest callbackRequest = new RPCRequest();
log.info("调用callback:{} {}", method.getDeclaringClass().getName(), method.getName());
log.info("requestId: {}", request.getRequestId());
// 这里requestId是一样的
callbackRequest.setRequestId(request.getRequestId());
callbackRequest.setInterfaceName(method.getDeclaringClass().getName());
callbackRequest.setMethodName(method.getName());
callbackRequest.setParameterTypes(method.getParameterTypes());
callbackRequest.setParameters(args);
// 发起callback请求
Object data = messageConverter.convert2Object(Message.buildRequest(callbackRequest));
ctx.writeAndFlush(data);
return null;
} else {
return method.invoke(proxy, args);
}
}
}
);
}
try {
return method.invoke(serviceBean, parameters);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
throw e.getCause();
}
return null;
}
}大致逻辑就是,如果是普通的方法,则直接调用,然后写回响应;如果该方法中有回调参数(serviceConfig.isCallback=true),则先进行方法调用,然后构造一个Request,对回调参数这个接口进行RPC调用,然后写回;如果是回调方法(serviceConfig.isCallbackInterface=true),则进行方法调用,然后不写回响应。
值得注意的一点是,标记了@RPCService的实现类我们会在扫描bean的时候就暴露出去,但是回调接口的实现类是在什么时候暴露出去的呢?
看一下CallbackInvocation的实现:
/**
* @author sinjinsong
* @date 2018/6/10
* 客户端会给出callback接口的接口名、方法名
* 服务端会给出callback接口的接口名、方法名以及callback参数在service方法中参数的索引
* 在客户端发出请求前,会将该回调方法暴露出来,就像服务端一样。
* 在服务端接收到请求后,会先执行service方法,当拿到结果后,RPC请求客户端的进行回调方法调用。
* 虽然方法是在客户端被调用的,但占用了服务端的CPU,是在服务端的线程中完成的。
* 简言之就是客户端RPC服务器,服务器RPC客户端。
* 这里约定,客户端rpc服务器,服务器不会影响该request;服务器转而会rpc服务器,两个request的id是一样的。
* 通过这个相同的requestid来定位callback实例。
*
* 注意!如果调用失败,则callback不会被调用
*/
public abstract class CallbackInvocation extends AbstractInvocation {
@Override
protected RPCResponse doInvoke() throws Throwable {
RPCRequest rpcRequest = getRpcRequest();
ReferenceConfig referenceConfig = getReferenceConfig();
Object callbackInstance = rpcRequest.getParameters()[referenceConfig.getCallbackParamIndex()];
// 该实例无需序列化
rpcRequest.getParameters()[referenceConfig.getCallbackParamIndex()] = null;
registerCallbackHandler(rpcRequest, callbackInstance);
doCustomProcess();
return null;
}
private void registerCallbackHandler(RPCRequest request, Object callbackInstance) {
Class interfaceClass = callbackInstance.getClass().getInterfaces()[0];
ServiceConfig config = ServiceConfig.builder()
.interfaceName(interfaceClass.getName())
.interfaceClass((Class其实客户端在进行callback调用时也会进行本地暴露,只是不是被Protocol管理的,而是放到全局的Map中,类似于同步调用的Future。在客户端收到响应的时候会从全局Map中取出这个ServiceConfig,相当于本地服务发现。
最后看一下HttpServer的实现:
@Slf4j
public class HttpServer extends AbstractNettyServer {
@Override
protected ChannelInitializer initPipeline() {
HttpServerHandler.init(HttpServer.this,HttpServerMessageConverter.getInstance(getGlobalConfig().getSerializer()));
return new ChannelInitializer() {
protected void initChannel(SocketChannel ch) throws Exception {
//编码是其他格式转为字节
//解码是从字节转到其他格式
//服务器是把先请求转为POJO(解码),再把响应转为字节(编码)
//而客户端是先把请求转为字节(编码),再把响应转为POJO(解码)
// 在InboundHandler执行完成需要调用Outbound的时候,比如ChannelHandlerContext.write()方法,
// Netty是直接从该InboundHandler返回逆序的查找该InboundHandler之前的OutboundHandler,并非从Pipeline的最后一项Handler开始查找
ch.pipeline()
// 客户端会发出请求,接收响应;也有可能会接收请求(但消息体也是响应,callback)
// 服务器会接收请求,发出响应,也有可能会发出请求(但消息体也是响应,callback)
.addLast("HttpResponseEncoder", new HttpResponseEncoder())
.addLast("HttpRequestDecoder", new HttpRequestDecoder())
// 接收请求时,作为一个decoder,将http request转为full http request
.addLast("HttpObjectAggregator",new HttpObjectAggregator(10*1024*1024))
.addLast("HttpServerHandler", HttpServerHandler.getInstance());
}
};
}
@Override
protected ServerMessageConverter initConverter() {
return HttpServerMessageConverter.getInstance(getGlobalConfig().getSerializer());
}
} 比较尴尬的一点是,HTTP协议只是传输协议变成了HTTP,但是服务发现仍然是基于注册中心,基于IP:PORT直连服务器的方式,而非根据URL来发现服务,其实相较于TCP协议是毫无优势的。这一点Dubbo也是提供了REST协议的支持,就是将暴露的服务以某种规则暴露为HTTP服务,HTTPClient可以根据URL来找到该服务器,进行服务调用。
Executor、Serializer层实现细节
这一层是比较简单的,不做过多介绍了,看一下接口即可:
public interface TaskExecutor {
void init(Integer threads);
void submit(Runnable runnable);
void close();
}public interface Serializer {
byte[] serialize(T obj) throws RPCException;
T deserialize(byte[] data, Class cls) throws RPCException;
} 值得注意的一点是,配置文件中我们设置了client和server两个executor,一般情况下我们会为server端的executor设置较多的线程数,比如200个,因为服务端是用来提供服务的,通常我们认为性能是比较好的,负载也是比较重的;但是client端的executor是用来处理callback的,通常我们认为性能是一般的,callback可能更偏CPU密集型一些,所以一般设置CPU核数个线程就足够了。
开发体感
项目是迭代出来的,而非设计出来的。
这个是感受最深的一点。功能增强、设计优化是一步步走的,toy-rpc中部分的设计经过了很多次的推翻重写,直到还算满意的程度。
造轮子是有快感的
我们在造轮子的时候往往是不会把像我们在JavaEE编程中的一堆套路直接怼上去的,很多时候都是需要自己去想怎么设计才好,并且会不自觉地往设计模式上靠,确实是对代码能力有提升的。
站在用户的角度设计
这个点不去自己造轮子是感受不到的,轮子好不好是一方面,好不好用是另一方面,在设计的时候应该尽可能地去考虑用户使用时的感受,隐藏内部实现细节,暴露简单的接口出来。
学习优秀的软件项目
Dubbo中很多设计是非常好的,尤其是分层抽象的部分,如果我们不去读这些好的软件项目的源码,我们就永远不知道什么才是好的设计、好的代码。在这里列举几个我认为代码质量非常高的软件:Tomcat,Dubbo,以及Netty。