基于Tensorflow2.0的简单人脸识别实验
基于Tensorflow2.0的简单人脸识别实验
- 运行环境
Windows10
Pycharm - 需要用到的库
opencv4.1.2_python3.7
模型的训练
我上一篇文章有提到如何制作自己的数据集,当时就是以人脸为例做的,这篇文章我们利用上篇已经做好的数据集来进行训练。
首先我们需要确定自己的模型,我们这里采用6层卷积,2层全连接层,代码如下。
from tensorflow.keras import layers, optimizers, datasets, Sequential
import tensorflow as tf
# 由卷积层和全连接层组成,中间用Flatten层进行平铺, inputs: [None, 64, 64, 3]
my_layers = [
layers.Conv2D(32, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(32, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding="same"),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding="same"),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding="same"),
layers.Flatten(),
layers.Dense(512, activation=tf.nn.relu),
layers.Dropout(rate=0.5),
layers.Dense(2, activation=None)
]
my_net = Sequential(my_layers)
my_net.build(input_shape=[None, 64, 64, 3])
my_net.summary()
optimizer = optimizers.Adam(lr=1e-3)
然后开始进行训练,这里自己来编写训练代码,总训练次数为50次,当训练过程出现10次准确率没有提高的情况,那么自动跳出循环结束训练过程。这里出现的db_train,db_test就是上一篇文章提到的制作完成的数据集。
acc_best = 0
patience_num = 10
no_improved_num = 0
for epoch in range(50):
for step, (x, y) in enumerate(db_train):
with tf.GradientTape() as tape:
out = my_net(x)
# print('out', out.shape)
logits = out
y_onehot = tf.one_hot(y, depth=2)
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, my_net.trainable_variables)
optimizer.apply_gradients(zip(grads, my_net.trainable_variables))
if step % 5 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x2, y2 in db_test:
out = my_net(x2)
logits = out
prob = tf.nn.softmax(logits, axis=1)
# tf.argmax() : axis=1 表示返回每一行最大值对应的索引, axis=0 表示返回每一列最大值对应的索引
pred = tf.argmax(prob, axis=1)
# 将pred转化为int32数据类型,便于后面与y2进行比较
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y2), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x2.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
if acc > acc_best:
acc_best = acc
no_improved_num = 0
my_net.save('model.h5')
else:
no_improved_num += 1
print(epoch, 'acc:', acc, 'no_improved_num:', no_improved_num)
if no_improved_num >= patience_num:
break
训练结果如图所示
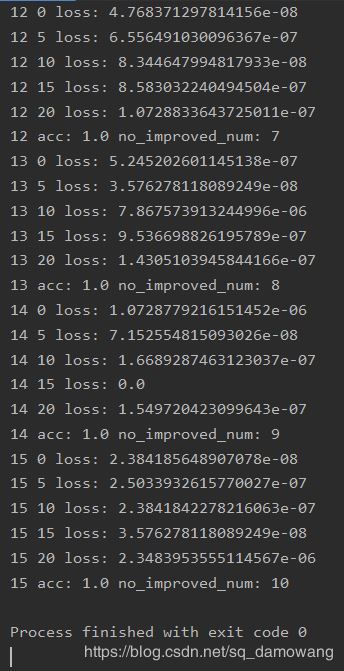
人脸识别
训练完成后可以发现当前目录下出现了一个model.h5的文件,这个就是你训练完成的模型,我们利用它完成我们的预测工作。
import cv2
import tensorflow as tf
# 这里用数字0代表xu,数字1代表zheng,并将其转化为tensor便于之后与预测值做比较
xu = [0]
zheng = [1]
zheng = tf.convert_to_tensor(zheng, dtype=tf.int32)
xu = tf.convert_to_tensor(xu, dtype=tf.int32)
my_net = tf.keras.models.load_model('my_net.h5')
# 调用计算机自带的摄像头
camera = cv2.VideoCapture(0)
# 这个人脸特征识别文件我在上篇文章有提到,这里写下它的绝对路径就行
haar = cv2.CascadeClassifier('D:/OpenCV/haarcascades/haarcascade_frontalface_default.xml')
n = 1
while 1:
if n <= 20000:
print('It`s processing %s image.' % n)
success, img = camera.read()
# 做灰度转换
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 获取图片中的所有人脸信息
faces = haar.detectMultiScale(gray_img, 1.3, 5)
for f_x, f_y, f_w, f_h in faces:
# 截取得到人脸图片
face = img[f_y:f_y + f_h, f_x:f_x + f_w]
# 修改图片大小为64*64
face = cv2.resize(face, (64, 64))
# 将图片数据类型转换为tensor类型,完成后shape为[64, 64, 3]
face_tensor = tf.convert_to_tensor(face)
# 在0维度左侧增加一个维度,即[64, 64, 3]=>[1, 64, 64, 3]
face_tensor = tf.expand_dims(face_tensor, axis=0)
# 将tensor类型从uint8转换为float32
face_tensor = tf.cast(face_tensor, dtype=tf.float32)
# print('face_tensor', face_tensor)
# 输入至训练好的网络
logits = my_net(face_tensor)
# 将每一行进行softmax
prob = tf.nn.softmax(logits, axis=1)
print('prob:', prob)
# 取出prob中每一行最大值对应的索引
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
print('pred:', pred)
# 把预测值与xu和zheng的标签做比较,并将结果写在图像上
if tf.equal(pred, zheng):
cv2.putText(img, 'zheng', (f_x, f_y - 20), cv2.FONT_HERSHEY_COMPLEX, 1, 255, 2)
if tf.equal(pred, xu):
cv2.putText(img, 'xu', (f_x, f_y - 20), cv2.FONT_HERSHEY_COMPLEX, 1, 255, 2)
img = cv2.rectangle(img, (f_x, f_y), (f_x + f_w, f_y + f_h), (255, 0, 0), 2)
n += 1
cv2.imshow('img', img)
key = cv2.waitKey(30) & 0xff
if key == 27:
break
else:
break
camera.release()
cv2.destroyAllWindows()
预测效果图如下
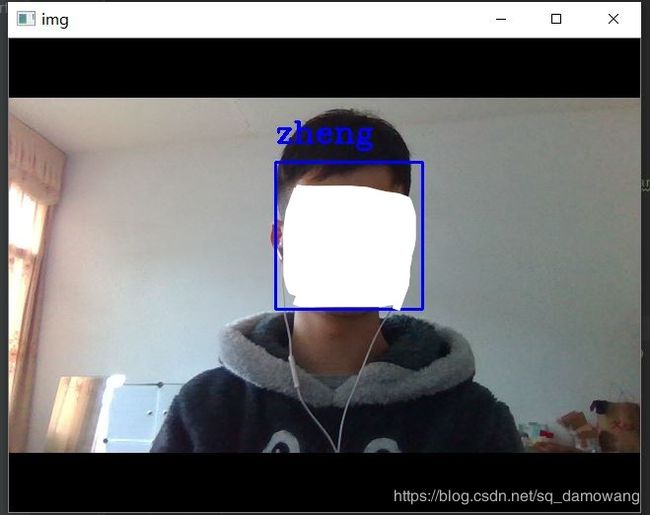
由于xu不在身边,这里体现不出来同时检测两个人的效果,而且我上一篇文章给的数据量太少,很不全面,所以还是有出现识别出错的情况,如果大家的识别效果不明显,大家可以多取一些不同场景下的人脸信息,并将其作为数据集来训练,这样可以提高识别率。
所有代码部分已经上传到github了,地址如下,有需要的朋友可以参考一下,这篇文章需要用到的库或者是文件在我上一篇文章都有给出,若有不正确的地方或者是建议还请大家指正。
https://github.com/fracnaive/face_classification.git