Cycle GAN 论文解析
本文中,作者认为在图片转换中,desired output可能代价高昂(例如艺术作品)或者难以被很好的定义(例如下图斑马与马的转换),因此提出了一个能在匹配的训练样本缺失的情况下,完成捕获一类图片集合特殊特征并将其转化进入另一类图片集合中的方法。可以将其广义地解释为图像转换,例如灰白图像变彩色,图片转化为语义标签,描边图转化为照片等等。
附上开头的效果图:
以及作者对匹配和不匹配的解释:
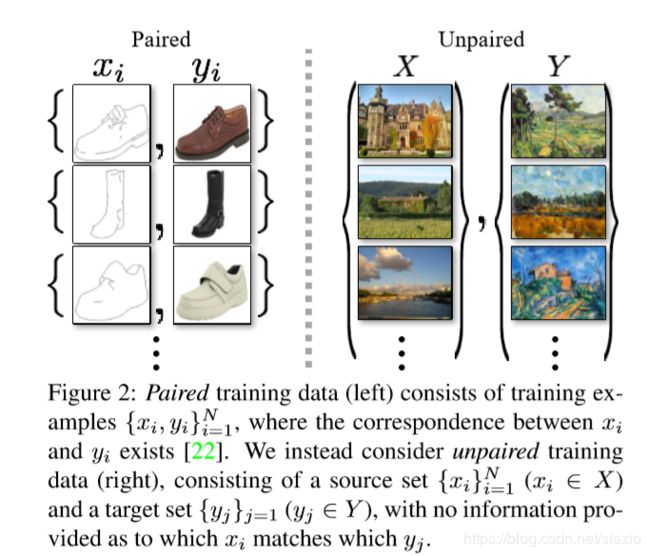
作者提出,该方法基于一个假设,即在多个domains中存在潜在的联系(比如同一个潜在场景的不同翻译),而本方法就是在寻找这种联系。
原始GAN的问题:
作者将原始的gan网络如下概括:
对于两个domains X,Y,定义映射G:X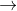 Y输出
Y输出![]() 通过一个adversary网络训练将y和
通过一个adversary网络训练将y和 区分开来。理论上,这将会得到一个与y观测值
区分开来。理论上,这将会得到一个与y观测值![]() 相匹配的分布,最优G将会和Y建立同分布
相匹配的分布,最优G将会和Y建立同分布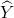 。但是作者提出一个问题,即无法保证每一个x与输出y以一种有意义的方式配对起来,换句话说有无数种映射关系能使得集合X输出与Y相同分布的集合。实际上,作者发现很难对对抗网络进行孤立优化,标准进程经常导致mode collapse,即所有的输入图片输出同样的输出图片,优化过程无法进展。
。但是作者提出一个问题,即无法保证每一个x与输出y以一种有意义的方式配对起来,换句话说有无数种映射关系能使得集合X输出与Y相同分布的集合。实际上,作者发现很难对对抗网络进行孤立优化,标准进程经常导致mode collapse,即所有的输入图片输出同样的输出图片,优化过程无法进展。
在受到“pix2pix”思想(conditional GAN),使用传递性来调整结构化数据的思想,及利用循环一致性监督训练等思想的启发后,作者提出了包含双射映射的cyclegan。
结构图如下(图文参考于https://zhuanlan.zhihu.com/p/32103958):


对于生成器G:XY和它的判别器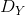 ,定义loss如下:
,定义loss如下:

即完全与原始GAN定义相同。
而对于映射关系F:YX和其判别器![]() ,定义类似loss:
,定义类似loss:
![]()
作者指出,仅仅使用对抗loss不能保证单个的 与期望输出
与期望输出 相匹配,因此利用循环一致性,即定义cycle consistency loss。
相匹配,因此利用循环一致性,即定义cycle consistency loss。
而对于Cycle Consistency Loss文中使用L1范数形式:
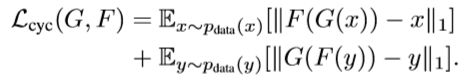
最终loss如下:
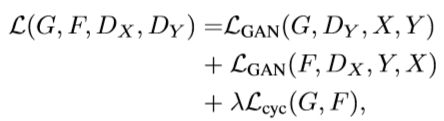
优化目标也仿照原始GAN:
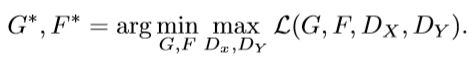 、
、
网络结构方面,生成网络采用的是与Perceptual Losses for Real-Time Style Transfer and Super-Resolution相似的结构(代码来源https://github.com/eriklindernoren/Keras-GAN/blob/master/cyclegan/cyclegan.py):
def build_generator(self):
"""U-Net Generator"""
def conv2d(layer_input, filters, f_size=4):
"""Layers used during downsampling"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
d = InstanceNormalization()(d)
return d
def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
"""Layers used during upsampling"""
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
if dropout_rate:
u = Dropout(dropout_rate)(u)
u = InstanceNormalization()(u)
u = Concatenate()([u, skip_input])
return u
# Image input
d0 = Input(shape=self.img_shape)
# Downsampling
d1 = conv2d(d0, self.gf)
d2 = conv2d(d1, self.gf*2)
d3 = conv2d(d2, self.gf*4)
d4 = conv2d(d3, self.gf*8)
# Upsampling
u1 = deconv2d(d4, d3, self.gf*4)
u2 = deconv2d(u1, d2, self.gf*2)
u3 = deconv2d(u2, d1, self.gf)
u4 = UpSampling2D(size=2)(u3)
output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u4)
return Model(d0, output_img)可以看到借鉴了U-Net的思想:

而判别器则使用了70*70的PatchGANs(Image-to-Image Translation with Conditional Adversarial Networks):
def build_discriminator(self):
def d_layer(layer_input, filters, f_size=4, normalization=True):
"""Discriminator layer"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if normalization:
d = InstanceNormalization()(d)
return d
img = Input(shape=self.img_shape)
d1 = d_layer(img, self.df, normalization=False)
d2 = d_layer(d1, self.df*2)
d3 = d_layer(d2, self.df*4)
d4 = d_layer(d3, self.df*8)
validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
return Model(img, validity)对于PatchGAN的解释引用来自https://www.leiphone.com/news/201706/feaYeOeyO7ZVvbuZ.html的一段话:
PatchGAN的思想是,既然GAN只负责处理低频成分,那么判别器就没必要以一整张图作为输入,只需要对NxN的一个图像patch去进行判别就可以了。这也是为什么叫Markovian discriminator,因为在patch以外的部分认为和本patch互相独立。
作者提出,使用patchGAN是因为参数更少并且对图片尺寸的适应性更强。
加粗部分暂时不能理解,先记录在此。
训练细节
具体实现时,对于GAN loss,![]() 采用最小二乘loss来替代log形式的loss,即
采用最小二乘loss来替代log形式的loss,即
训练G最小化![]()
训练D最小化![]() 与
与![]() 之和
之和
其次为了减小模型震荡,采用了来自 Learning from simulated and unsupervised images through adversarial training的方法,即采用一段时间之前生成器生成的图片而不是最近生成的图片。具体实现是采用了长度为50的缓冲区存储生成的图片。
对于总loss采用![]() ,学习率为0.0002并在100-200epoch线性衰减至0。
,学习率为0.0002并在100-200epoch线性衰减至0。
具体使用FCN score对一个生成图片预测label map,然后将这个label map与输入的ground truth使用标准的语义分割标准进行比较。语义分割标准采用Cityscapes benchmark体系,包括per-pixel accuracy, per-class accuracy,和mean class IOU。
作者将一些其他论文中提出的baseline进行实验,与CycleGAN进行对比结果如下:

作者给出在AMT上做的实验(欺骗率):

在Cityscapes数据集上结果:

而对总loss进行拆分后效果如下:
在匹配的数据集上效果如下(本文称生成图片质量已经接近了pix2pix方法但是本方法是在没有匹配监督的情况下学习到的映射关系):
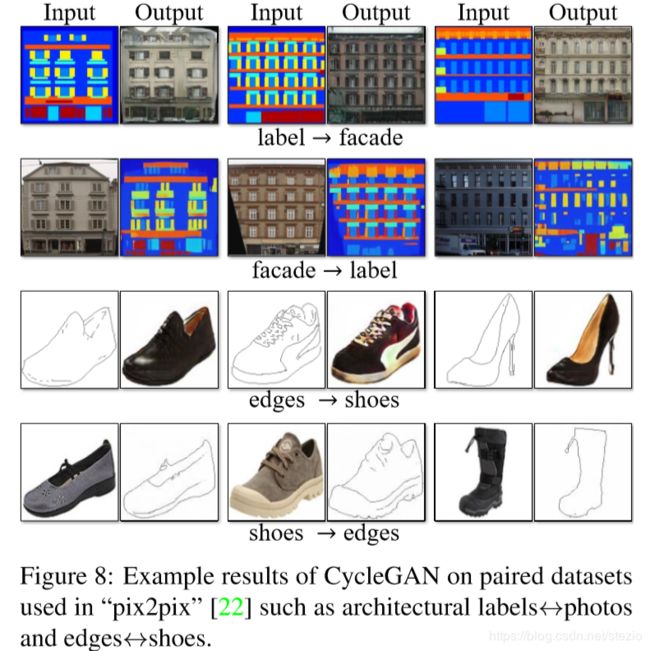
具体的应用作者列出许多,见原文。
作者自己也指出了本方法目前存在的一些问题:
1.当需求输出存在几何学的改变效果会很差,比如想把狗转变成猫或相反

2.一些失败是由训练及分布特征导致的,比如训练野马和斑马转换时,并没有考虑到马上可能骑着一个人

3.在匹配的数据集上训练和不匹配的数据集上训练仍然会有差距,作者提出要解决这种问题需要融合一些弱语义监督,这样仍然只会带来比全监督系统低得多的标注成本。