BiLSTM-CRF中CRF层解析-1
最近,使用BiLstm-CRF模型,但是对CRF层的算法实现不是很理解,在网上找了很多资料也没解答我心中的疑问,后边看到了英文版的解析,很清晰,因此,将其进行翻译。
原英文链接:https://www.cnblogs.com/createMoMo/p/7529885.html
概要
此系列博文将会包含以下内容:
- 引言-命名实体识别任务中,Bilstm-CRF模型中CRF层的基本概念和思想;
- 示例-解释CRF层是如何一步一步工作的小例子;
- 实现-CRF层的链式实现算法。
文章读者
读者目标:学习NLP的新手或者AI相关的人员,我希望您能从该博文中学到您想学的知识。
先验知识
在阅读本博文之前,您唯一需要了解的就是什么是命名实体识别。如果您不了解神经网络、CRF或者其他相关概念,请不要担心,我会尽可能地将这些讲的通俗易懂。
1.引言
对于命名实体识别来讲,目前比较流行的方法是基于神经网络,例如,论文[1]提出了基于BiLSTM-CRF的命名实体识别模型,该模型采用word embedding和character embedding(在英文中,word embedding对应于单词嵌入式表达,character embedding对应于字母嵌入式表达;在中文中,word embedding对应于词嵌入式表达,character embedding对应于字嵌入式表达;接下来的示例中我们都假设是英文的场景),我将用该模型作为示例来解释CRF层的工作原理。
1.1 参数定义
假设,我们的数据集中有两种实体类型:人名和机构名,因此,在我们的数据集中有5种实体标签:
- B-Person
- I- Person
- B-Organization
- I-Organization
- O
假设 x x x是一个句子,该句子由5个单词组成: w 0 , w 1 , w 2 , w 3 , w 4 w_0,w_1,w_2,w_3,w_4 w0,w1,w2,w3,w4,而且在句子 x x x中, [ w 0 , w 1 ] [w_0,w_1] [w0,w1]组成一个人名, [ w 3 ] [w_3] [w3]为一个机构名,其他单词标签都是"O"。
1.2 BiLSTM-CRF模型
接下来,简明介绍一下该模型。
示意图如下所示:
- 首先,句子 x x x中的每个单词表达成一个向量,该向量包含了上述的word embedding和character embedding,其中character embedding随机初始化,word embedding通常采用预训练模型初始化。所有的embeddings 将在训练过程中进行微调。
- 其次,BiLSTM-CRF模型的的输入是上述的embeddings,输出是该句子 x x x中每个单词的预测标签。
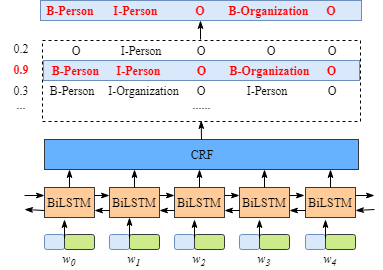
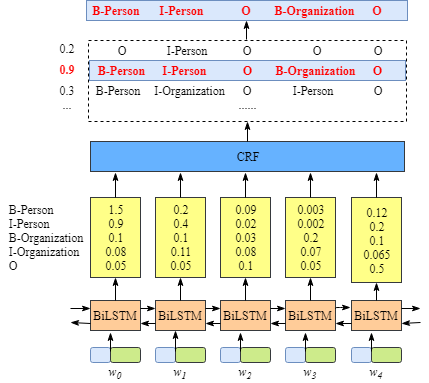
从上图可以看出,BiLSTM层的输出是每个标签的得分,如单词 w 0 w_0 w0,BiLSTM的输出为1.5(B-Person),0.9(I-Person),0.1(B-Organization), 0.08 (I-Organization) and 0.05 (O),这些得分就是CRF层的输入。
将BiLSTM层预测的得分喂进CRF层,具有最高得分的标签序列将是模型预测的最好结果。
如果没有CRF层将如何
根据上文,能够发现,如果没有CRF层,即我们用下图所示训练BiLSTM命名实体识别模型:
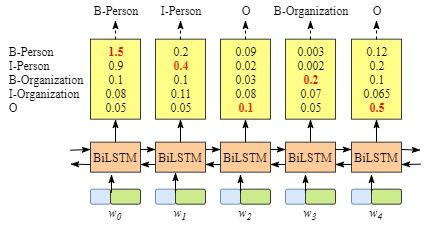
因为BiLSTM针对每个单词的输出是标签得分,对于每个单词,我们可以选择最高得分的标签作为预测结果。
例如,对于 w 0 w_0 w0,“B-Person"得分最高(1.5),因此我们可以选择“B-Person”最为其预测标签;同样的, w 1 w_1 w1的标签为"I-Person”, w 2 w_2 w2的为"O", w 3 w_3 w3的标签为"B-Organization", w 4 w_4 w4的标签为"O"。
按照上述方法,对于 x x x虽然我们得到了正确的标签,但是大多数情况下是不能获得正确标签的,例如下图的例子:

显然,输出标签“I-Organization I-Person” 和 “B-Organization I-Person”是不对的。
1.4 CRF能够从训练数据中学习到约束条件
CRF层可以对最终的约束标签添加一些约束条件,从而保证预测标签的有效性。而这些约束条件是CRF层自动从训练数据中学到。
约束可能是:
- 一句话中第一个单词的标签应该是“B-“ or “O”,而不能是"I-";
- “B-label1 I-label2 I-label3 I-…”中,label1, label2, label3 …应该是相同的命名实体标签。如“B-Person I-Person”是有效的,而“B-Person I-Organization” 是无效的;
- “O I-label” 是无效的。一个命名实体的第一个标签应该以 “B-“ 开头,而不能以“I-“开头,换句话说, 应该是“O B-label”这种模式;
- …
有了这些约束条件,无效的预测标签序列将急剧减少。
下篇博客
在下篇博客中,将会分析CRF的损失函数,从而解释CRF层是如何从训练数据中学习到上述约束条件的。
参考文献
[1] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. and Dyer, C., 2016. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360.
https://arxiv.org/abs/1603.01360