Elasticsearch 性能监控基础
本文的来源是我翻译他人的一篇技术博客,感谢原作者Emily Chang
原文地址
下面让我们一起来学习Elasticsearch
一、Elasticsearch 是什么
Elasticsearch是一款用Java编写的开源分布式文档存储和搜索引擎,可以用于near real-time存储和数据检索。
1、Elasticsearch简要组成
在开始探索性能指标之前,让我们来看看Elasticsearch的工作原理,在elasticsearch中,集群由一个或者更多的节点组成,如下图:
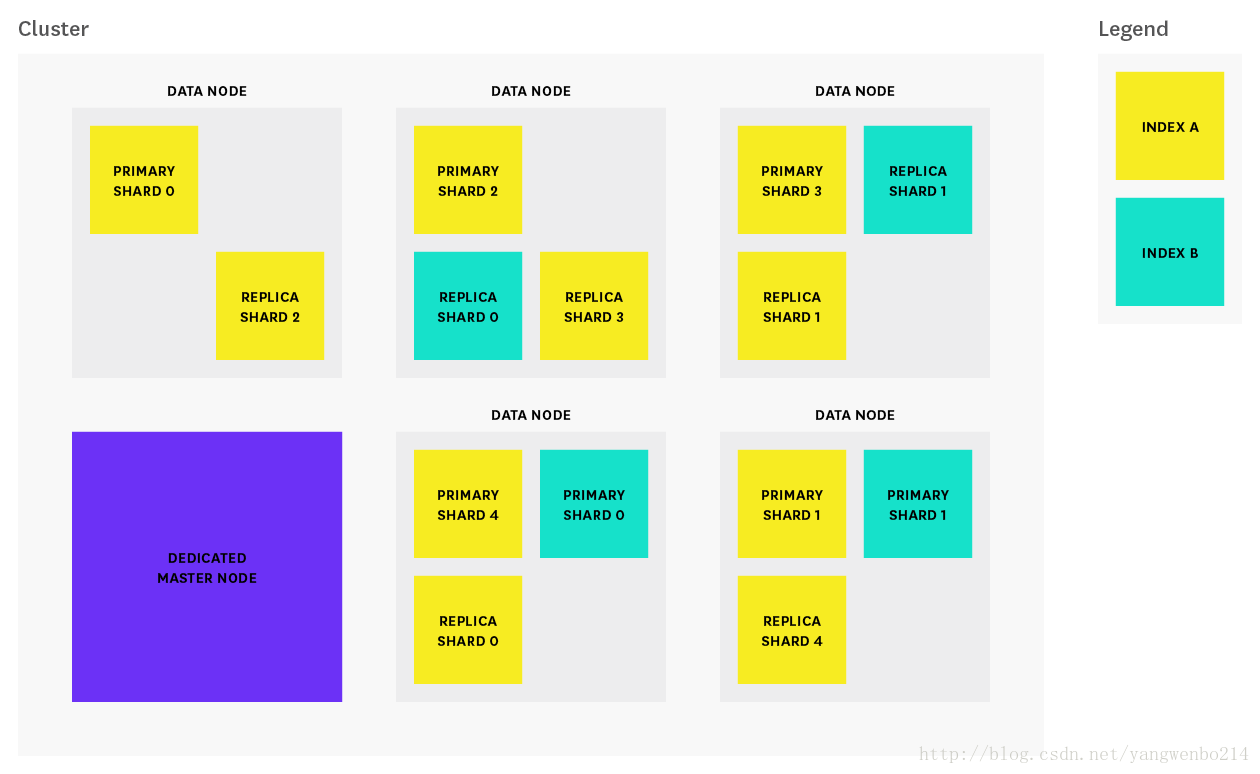
每个节点是Elasticsearch的单个运行实例,其“elasticsearch.yml”配置文件指定其所属的集群(“cluster.name”)以及它可以是什么类型的节点。 配置文件中设置的任何属性(包括集群名称)也可以通过命令行参数指定。 上图中的集群由一个专用主节点和五个数据节点组成。
三种最常见的es几点类型有:
- master备选节点
默认情况下(不动配置),每个节点均为master备选节点。每个集群都会自动从所有master备选节点中选择一个成为master节点。在当前master节点遇到故障(例如停电,硬件故障或内存不足错误)的情况下,重新选举产生新的master节点。master节点负责协调集群任务,比如跨节点的shards分发、创建和删除索引等。
master节点也能同时作为数据节点,但在比较大的集群中,master节点一般不存储数据(通过设置node.data : false 来设置),以提高可靠性。在高可用环境中,节点任务明确、分离可以保证任务单一可靠。(专人干专事) - data节点
默认情况下(不动配置),每个节点都是数据节点,以shards的形式存储数据并执行与索引,搜索和聚合数据相关的操作。
在大集群中,我们可以通过设置node.master : false来设置该节点为专用数据节点。确保这些节点具有足够的资源来处理与数据相关的请求,而不需要承担与集群相关的管理任务类的工作负载。 - client 节点
如果将node.master 和node.data都设置为false。那么该节点就是一个client节点。该client节点被设计为负载均衡器的角色,以帮助路由索引和搜索请求。
client节点有助于承担部分搜索工作量,以便数据和主节点节点可以专注于其核心任务。client节点并不是必须的,因为数据节点能够自己处理请求路由。如果你的search/index workload比较重,可以在集群中配一个client节点。
2、Elasticsearch 如何组织数据
在es中,相关联的数据通常存储在相同的索引中,每个索引包含一组JSON格式的相关联文档。
Elasticsearch的全文搜索秘诀是Lucene的倒排索引。在索引(存入)数据的时候,es会自动为每个字段创建一个倒排索引,倒排索引将索引的词(terms)映射(map)到包含该词的文档(document)中。
index被存储在一个或多个主副shard中,每个shard都是一个完整的Lucenes实例,是一个完整的迷你搜索引擎。
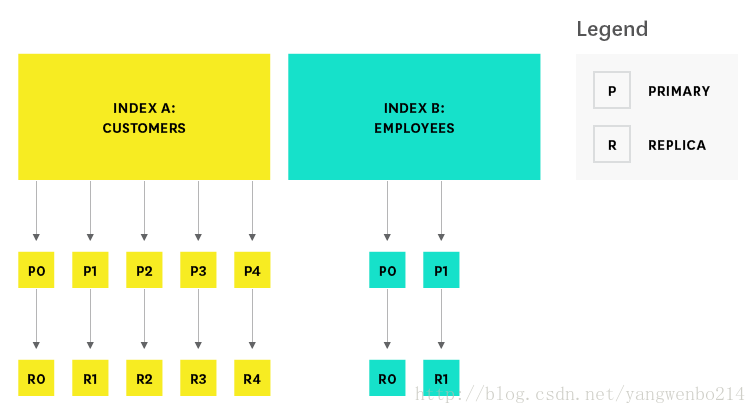
创建索引时,可以指定主分片的数量以及每个主节点的副本数,默认为五个分片和一个副本。索引创建后,分片数不能被修改。如果要修改可能需要reindex。副本数可以在后期被修改。
为了防止数据丢失,主节点的调度机制会确保主副分片不会出现在同一个数据节点上。
二、我们要监控哪些Elasticsearch metric
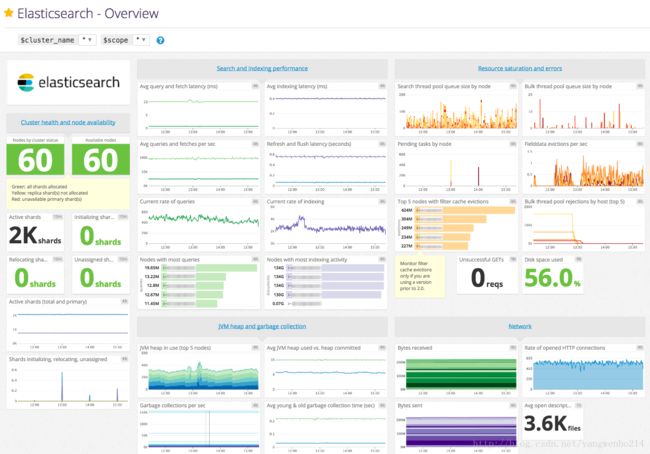
Elasticsearch提供了大量的Metric,可以帮助您检测到问题的迹象,在遇到节点不可用、out-of-memory、long garbage collection times的时候采取相应措施。
一些关键的检测如下:
- Search and indexing performance(搜索、索引性能)
- Memory and garbage collection
- Host-level system and network metrics
- Cluster health and node availability
- Resource saturation(饱和) and errors
这里提供了一个metric搜集和监控的框架 Monitoring 101 series
所有这些指标都可以通过Elasticsearch的API以及Elasticsearch的Marvel和Datadog等通用监控工具访问。
1、搜索性能指标
搜索请求是Elasticsearch中的两个主要请求类型之一,另一个是索引请求。 这些请求有时类似于传统数据库系统中的读写请求。 Elasticsearch提供与搜索过程的两个主要阶段(查询和获取)相对应的度量。 下图显示了从开始到结束的搜索请求的路径。
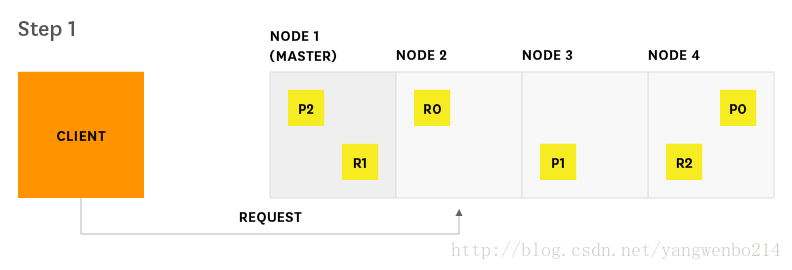
1.客户端向Node 2 发送搜索请求
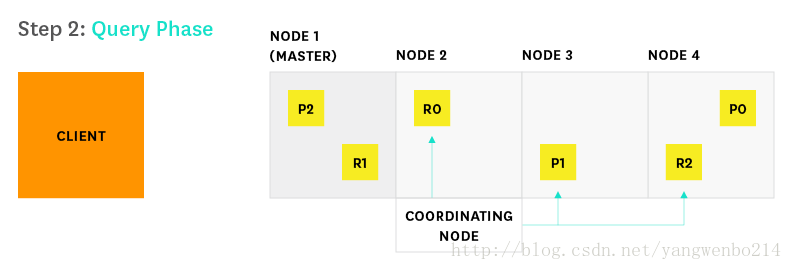
2.Node 2(此时客串协调角色)将查询请求发送到索引中的每一个分片的副本
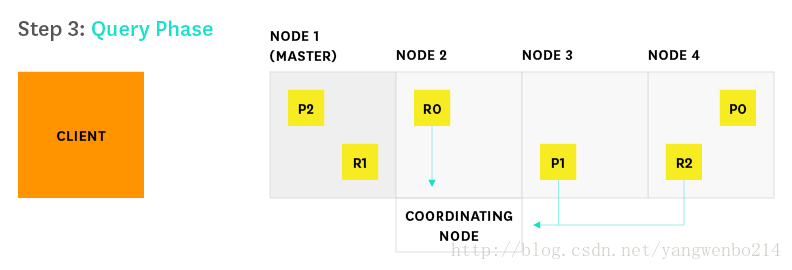
3.每个分片(Lucene实例,迷你搜素引擎)在本地执行查询,然后将结果交给Node 2。Node 2 sorts and compiles them into a global priority queue.
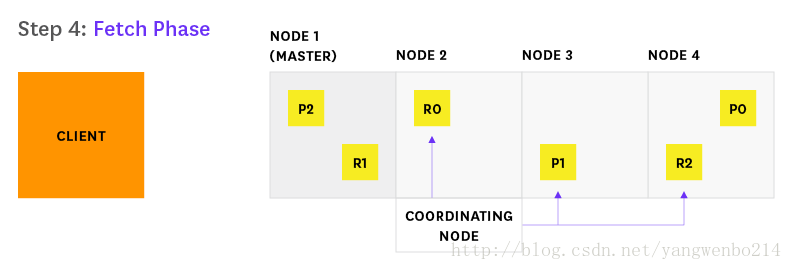
4.Node 2发现需要获取哪些文档,并向相关的分片发送多个GET请求。
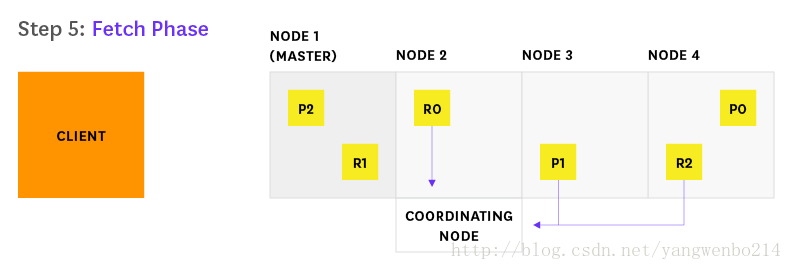
5.每个分片loads documents然后将他们返回给Node 2
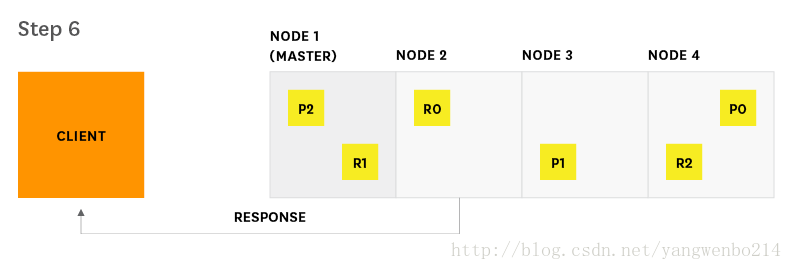
6.Node 2将搜索结果交付给客户端
节点处理,由谁分发,就由谁交付
如果您使用Elasticsearch主要用于搜索,或者如果搜索是面向客户的功能。您应该监视查询延迟和设定阈值。 监控关于查询和提取的相关指标很重要,可以帮助您确定搜索随时间的变化。 例如,您可能希望跟踪查询请求的尖峰和长期增长,以便您可以做好准备。
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Total number of queries | indices.search.query_total |
Work: Throughput |
| Total time spent on queries | indices.search.query_time_in_millis |
Work: Performance |
| Number of queries currently in progress | indices.search.query_current |
Work: Throughput |
| Total number of fetches | indices.search.fetch_total |
Work: Throughput |
| Total time spent on fetches | indices.search.fetch_time_in_millis |
Work: Performance |
| Number of fetches currently in progress | indices.search.fetch_current |
Work: Throughput |
搜索性能指标的要点:
- Query load:监控当前正在进行的查询数量可以让您了解群集在任何特定时刻处理的请求数量。您可能还想监视搜索线程池队列的大小,稍后我们将在本文中进一步解释链接。
- Query latency: 虽然Elasticsearch没有明确提供此度量标准,但监控工具可以帮助您使用可用的指标来计算平均查询延迟,方法是以定期查询总查询次数和总经过时间。 如果延迟超过阈值,则设置警报,如果触发,请查找潜在的资源瓶颈,或调查是否需要优化查询。
- Fetch latency: 搜索过程的第二部分,即提取阶段通常比查询阶段要少得多的时间。 如果您注意到这一指标不断增加,可能是磁盘性能不好、highlighting影响、requesting too many results的原因。
2、索引性能指标
索引请求类似于传统数据库系统中的写入请求,如果es的写入工作量很重,那么监控和分析您能够如何有效地使用新数据更新索引非常重要。在了解指标之前,让我们来探索Elasticsearch更新索引的过程,在新数据被添加进索引、更新或删除已有数据,索引中的每个shard都有两个过程:refresh 和 flush
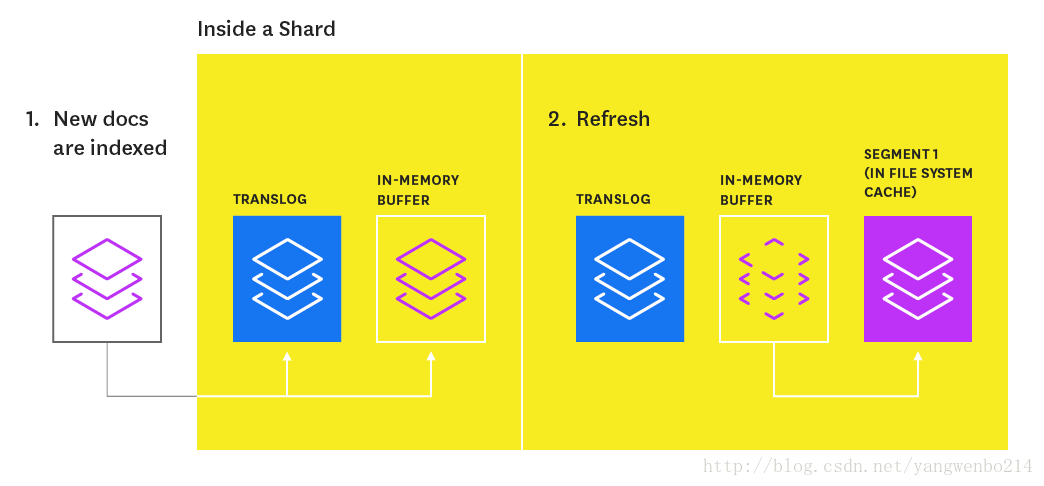
Index fresh
新索引的文档不能立马被搜索的。
首先,它们被写入一个内存中的缓冲区(in-memory buffer),等待下一次索引刷新,默认情况下每秒一次。刷新是以in-memory buffer为基础创建in-memory segment的过程(The refresh process creates a new in-memory segment from the contents of the in-memory buffer )。这样索引进的文档才能是可被搜索的,创建完segment后,清空buffer
如下图:
A special segment on segments
索引由shards构成,shard又由很多segments组成,The core data structure from Lucene, a segment is essentially a change set for the index. 这些segments在每次刷新的时候被创建,随后会在后台进行合并,以确保资源的高效利用(每个segment都要占file handles、memory、CPU)
segments 是mini的倒排索引,这些倒排索引映射了terms到documents。每当搜索索引的时候,每个主副shards都必须被遍历。更深一步说shards上的每个segment会被依次搜索。
segment是不可变的,因此updating a document 意味着如下:
- writing the information to a new segment during the refresh process
- marking the old information as deleted
当多个outdated segment合并后才会被删除。(意思是不单个删除,合并后一起删)。
Index flush
在新索引的document添加到in-memory buffer的同时,它们也会被附加到分片的translog(a persistent, write-ahead transaction log of operations)中。
每隔30分钟,或者每当translog达到最大大小(默认情况下为512MB)时,将触发flush 。在flush 期间,在in-memory buffer上的documents会被refreshed(存到新的segments上),所有内存中的segments都提交到磁盘,并且translog被清空。
translog有助于防止节点发生故障时的数据丢失。 It is designed to help a shard recover operations that may otherwise have been lost between flushes. 这个translog每5秒将操作信息(索引,删除,更新或批量请求(以先到者为准))固化到磁盘上。
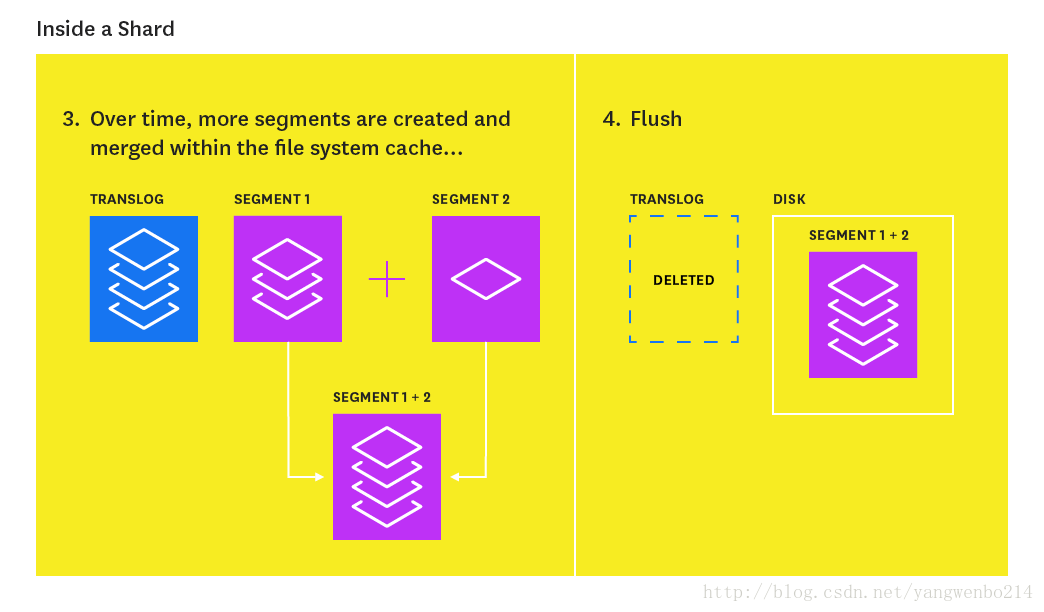
Elasticsearch提供了许多指标,可用于评估索引性能并优化更新索引的方式。
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Total number of documents indexed | indices.indexing.index_total |
Work: Throughput |
| Total time spent indexing documents | indices.indexing.index_time_in_millis |
Work: Performance |
| Number of documents currently being indexed | indices.indexing.index_current |
Work: Throughput |
| Total number of index refreshes | indices.refresh.total |
Work: Throughput |
| Total time spent refreshing indices | indices.refresh.total_time_in_millis |
Work: Performance |
| Total number of index flushes to disk | indices.flush.total |
Work: Throughput |
| Total time spent on flushing indices to disk | indices.flush.total_time_in_millis |
Work: Performance |
索引性能指标的要点:
Indexing latency: Elasticsearch不会直接公开此特定指标,但是监控工具可以帮助您从可用的index_total和index_time_in_millis指标计算平均索引延迟。 如果您注意到延迟增加,您可能会一次尝试索引太多的文档(Elasticsearch的文档建议从5到15兆字节的批量索引大小开始,并缓慢增加)。
如果您计划索引大量文档,并且不需要立即可用于搜索。则可以通过减少刷新频率来优化。索引设置API使您能够暂时禁用刷新间隔:curl -XPUT:9200/ /_settings -d '{ "index" : { "refresh_interval" : "-1" } }' - 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
完成索引后,您可以恢复为默认值“1s”
Flush latency: 在flush完成之前,数据不会被固化到磁盘中。因此追踪flush latency很有用。比如我们看到这个指标稳步增长,表明磁盘性能不好。这个问题将最终导致无法向索引添加新的数据。
可以尝试降低index.translog.flush_threshold_size。这个设置决定translog的最大值(在flush被触发前)
3、内存使用和GC指标
在运行Elasticsearch时,内存是您要密切监控的关键资源之一。 Elasticsearch和Lucene以两种方式利用节点上的所有可用RAM:JVM heap和文件系统缓存。 Elasticsearch运行在Java虚拟机(JVM)中,这意味着JVM垃圾回收的持续时间和频率将成为其他重要的监控领域。
JVM heap: A Goldilocks tale
Elasticsearch强调了JVM堆大小的重要性,这是“正确的” - 不要将其设置太大或太小,原因如下所述。 一般来说,Elasticsearch的经验法则是将少于50%的可用RAM分配给JVM堆,而不会超过32 GB。
您分配给Elasticsearch的堆内存越少,Lucene就可以使用更多的RAM,这很大程度上依赖于文件系统缓存来快速提供请求。 但是,您也不想将堆大小设置得太小,因为应用程序面临来自频繁GC的不间断暂停,可能会遇到内存不足错误或吞吐量降低的问题
Elasticsearch的默认安装设置了1 GB的JVM heap大小,对于大多数用例来说,太小了。 您可以将所需的heap大小导出为环境变量并重新启动Elasticsearch:
export ES_HEAP_SIZE=10g
如上我们设置了es heap大小为10G,通过如下命令进行校验:
curl -XGET http://:9200/_cat/nodes?h=heap.max
Garbage collection
Elasticsearch依靠垃圾收集过程来释放heap memory。因为垃圾收集使用资源(为了释放资源!),您应该注意其频率和持续时间,以查看是否需要调整heap大小。设置过大的heap会导致GC时间过长,这些长时间的停顿会让集群错误的认为该节点已经脱离。
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Total count of young-generation garbage collections | jvm.gc.collectors.young.collection_count (jvm.gc.collectors.ParNew.collection_count prior to vers. 0.90.10) |
Other |
| Total time spent on young-generation garbage collections | jvm.gc.collectors.young.collection_time_in_millis (jvm.gc.collectors.ParNew.collection_time_in_millis prior to vers. 0.90.10) |
Other |
| Total count of old-generation garbage collections | jvm.gc.collectors.old.collection_count (jvm.gc.collectors.ConcurrentMarkSweep.collection_count prior to vers. 0.90.10) |
Other |
| Total time spent on old-generation garbage collections | jvm.gc.collectors.old.collection_time_in_millis (jvm.gc.collectors.ConcurrentMarkSweep.collection_time_in_millis for versions prior to 0.90.10) |
Other |
| Percent of JVM heap currently in use | jvm.mem.heap_used_percent |
Resource: Utilization |
| Amount of JVM heap committed | jvm.mem.heap_committed_in_bytes |
Resource: Utilization |
JVM指标的要点:
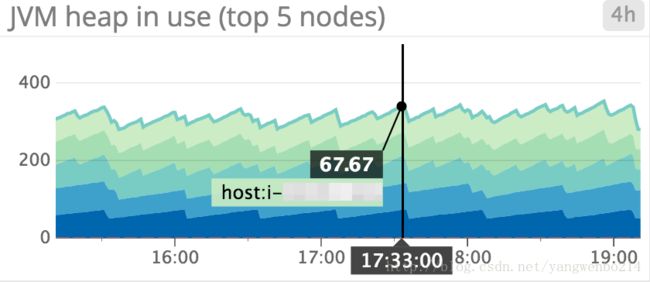
JVM heap in use: 当JVM heap 使用率达到75%时,es启动GC。如上图所示,可以监控node的JVM heap,并且设置一个警报,确认哪个节点是否一直超过%85。如果一直超过,则表明垃圾的收集已经跟不上垃圾的产生。此时可以通过增加heap(需要满足建议法则不超过32G),或者通过增加节点来扩展集群,分散压力。
JVM heap used vs. JVM heap committed: 与commit的内存(保证可用的数量)相比,了解当前正在使用多少JVM heap的情况可能会有所帮助。heap memory的图一般是个锯齿图,在垃圾收集的时候heap上升,当收集完成后heap下降。如果这个锯齿图向上偏移,说明垃圾的收集速度低于rate of object creation,这可能会导致GC时间放缓,最终OutOfMemoryErrors。
Garbage collection duration and frequency: Both young- and old-generation garbage collectors undergo “stop the world” phases, as the JVM halts execution of the program to collect dead objects。在此期间节点cannot complete any task。主节点每30秒会去检查其他节点的状态,如果任何节点的垃圾回收时间超过30秒,则会导致主节点任务该节点脱离集群。
Memory usage: 如上所述,es非常会利用除了分配给JVM heap的任何RAM。像Kafka一样,es被设计为依赖操作系统的文件系统缓存来快速可靠地提供请求。
许多变量决定了Elasticsearch是否成功读取文件系统缓存,如果segment file最近由es写入到磁盘,它已经in the cache。然而如果节点被关闭并重新启动,首次查询某个segment的时候,数据很可能是必须从磁盘中读取,这是确保您的群集保持稳定并且节点不会崩溃的重要原因之一。
总的来说,监控节点上的内存使用情况非常重要,并且尽可能多给es分配RAM,so it can leverage the speed of the file system cache without running out of space。
4、es主机的网络和系统
| Name | [Metric type][monitoring-101-blog] |
|---|---|
| Available disk space | Resource: Utilization |
| I/O utilization | Resource: Utilization |
| CPU usage | Resource: Utilization |
| Network bytes sent/received | Resource: Utilization |
| Open file descriptors | Resource: Utilization |
虽然Elasticsearch通过API提供了许多特定于应用程序的指标,但您也应该从每个节点收集和监视几个主机级别的指标。
Host指标要点:
Disk space: 如果数据很多,这个指标很关键。如果disk space 过小,讲不能插入或更新任何内容,并且节点会挂掉。可以使用Curator这样的工具来删除特定的索引以保持disk的可用性。
如果不让删除索引,另外的办法是添加磁盘、添加节点。请记住analyzed field占用磁盘的空间远远高于non-analyzed fields。I/O utilization: 由于创建,查询和合并segment,Elasticsearch会对磁盘进行大量写入和读取,于具有不断遇到大量I / O活动的节点的写入繁重的集群,Elasticsearch建议使用SSD来提升性能。
CPU utilization: 在每个节点类型的热图(如上所示)中可视化CPU使用情况可能会有所帮助。 例如,您可以创建三个不同的图表来表示集群中的每组节点(例如,数据节点,主节点,客户端节点), 如果看到CPU使用率的增加,这通常是由于搜索量大或索引工作负载引起的。 如果需要,可以添加更多节点来重新分配负载。
Network bytes sent/received: 节点之间的通讯是集群平衡的关键。因此需要监控network来确保集群的health以及对集群的需求(例如,segment在节点之间进行复制或重新平衡)。 Elasticsearch提供有关集群通信的指标,但也可以查看发送和接收的字节数,以查看network接收的流量。
Open file descriptors: 文件描述符用于节点到节点的通信,客户端连接和文件操作。如果这个number达到了系统的最大值,则只有在旧的连接和文件操作关闭之后才能进行新的连接和文件操作。 如果超过80%的可用文件描述符被使用,您可能需要增加系统的最大文件描述符数量。大多数Linux系统每个进程只允许1024个文件描述符。 在生产中使用Elasticsearch时,您应该将操作系统文件描述符计数重新设置为更大,如64,000。
HTTP connections:
Metric description Name [Metric type][monitoring-101-blog] Number of HTTP connections currently open http.current_openResource: Utilization Total number of HTTP connections opened over time http.total_openedResource: Utilization 可以用任何语言发送请求,但Java将使用RESTful API通过HTTP与Elasticsearch进行通信。 如果打开的HTTP连接总数不断增加,可能表示您的HTTP客户端没有正确建立持久连接。 重新建立连接会在您的请求响应时间内添加额外的毫秒甚至秒。 确保您的客户端配置正确,以避免对性能造成负面影响,或使用已正确配置HTTP连接的官方Elasticsearch客户端。
5、集群健康和节点可用性
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Cluster status (green, yellow, red) | cluster.health.status |
Other |
| Number of nodes | cluster.health.number_of_nodes |
Resource: Availability |
| Number of initializing shards | cluster.health.initializing_shards |
Resource: Availability |
| Number of unassigned shards | cluster.health.unassigned_shards |
Resource: Availability |
指标要点:
Cluster status: 如果集群状态为黄色,则至少有一个副本分片未分配或丢失。 搜索结果仍将完成,但如果更多的分片消失,您可能会丢失数据。
红色的群集状态表示至少有一个主分片丢失,并且您缺少数据,这意味着搜索将返回部分结果。 您也将被阻止索引到该分片。 Consider setting up an alert to trigger if status has been yellow for more than 5 min or if the status has been red for the past minute.Initializing and unassigned shards: 当首次创建索引或者重启节点,其分片将在转换到“started”或“unassigned”状态之前暂时处于“initializing”状态,此时主节点正在尝试将分片分配到集群中的数据节点。 如果您看到分片仍处于初始化或未分配状态太长时间,则可能是您的集群不稳定的警告信号。
6、资源saturation and errors
es节点使用线程池来管理线程如何消耗内存和CPU。 由于线程池设置是根据处理器数量自动配置的,所以调整它们通常没有意义。However, it’s a good idea to keep an eye on queues and rejections to find out if your nodes aren’t able to keep up; 如果无法跟上,您可能需要添加更多节点来处理所有并发请求。Fielddata和过滤器缓存使用是另一个要监视的地方,as evictions may point to inefficient queries or signs of memory pressure.
Thread pool queues and rejections
每个节点维护许多类型的线程池; 您要监视的确切位置将取决于您对es的具体用途,一般来说,监控的最重要的是搜索,索引,merge和bulk,它们与请求类型(搜索,索引,合并和批量操作)相对应。
线程池队列的大小反应了当前等待的请求数。 队列允许节点跟踪并最终服务这些请求,而不是丢弃它们。 一旦超过线程池的maximum queue size,Thread pool rejections就会发生。
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Number of queued threads in a thread pool | thread_pool.bulk.queuethread_pool.index.queuethread_pool.search.queuethread_pool.merge.queue |
Resource: Saturation |
| Number of rejected threads a thread pool | thread_pool.bulk.rejectedthread_pool.index.rejectedthread_pool.search.rejectedthread_pool.merge.rejected |
Resource: Error |
指标要点:
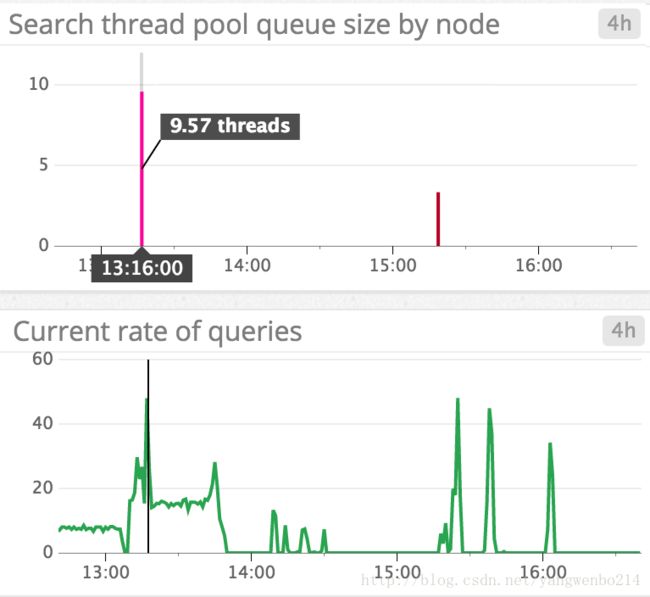
Thread pool queues: 大队列不理想,因为它们耗尽资源,并且如果节点关闭,还会增加丢失请求的风险。如果你看到线程池rejected稳步增加,你可能希望尝试减慢请求速率(如果可能),增加节点上的处理器数量或增加群集中的节点数量。 如下面的截图所示,查询负载峰值与搜索线程池队列大小的峰值相关,as the node attempts to keep up with rate of query requests。
Bulk rejections and bulk queues: 批量操作是一次发送许多请求的更有效的方式。 通常,如果要执行许多操作(创建索引或添加,更新或删除文档),则应尝试以批量操作发送请求,而不是发送许多单独的请求。
bulk rejections 通常与在一个批量请求中尝试索引太多文档有关。根据Elasticsearch的文档,批量rejections并不是很需要担心的事。However, you should try implementing a linear or exponential backoff strategy to efficiently deal with bulk rejections。Cache usage metrics: 每个查询请求都会发送到索引中的每个分片的每个segment中,Elasticsearch caches queries on a per-segment basis to speed up response time。另一方面,如果您的缓存过多地堆积了这些heap,那么它们可能会减慢速度,而不是加快速度!
在es中,文档中的每个字段可以以两种形式存储:exact value 和 full text。
例如,假设你有一个索引,它包含一个名为location的type。每个type的文档有个字段叫city。which is stored as an analyzed string。你索引了两个文档,一个的city字段为“St. Louis”,另一个的city字段为“St. Paul”。在倒排索引中存储时将变成小写并忽略掉标点符号,如下表Term Doc1 Doc2 st x x louis x paul x
分词的好处是你可以搜索st。结果会搜到两个。如果将city字段保存为exact value,那只能搜“St. Louis”, 或者 “St. Paul”。
Elasticsearch使用两种主要类型的缓存来更快地响应搜索请求:fielddata和filter。
Fielddata cache: fielddata cache 在字段排序或者聚合时使用。 a process that basically has to uninvert the inverted index to create an array of every field value per field, in document order. For example, if we wanted to find a list of unique terms in any document that contained the term “st” from the example above, we would:
1.扫描倒排索引查看哪些文档(documents)包含这个term(在本例中为Doc1和Doc2)
2.对1中的每个步骤,通过索引中的每个term 从文档中来收集tokens,创建如下结构:
| Doc | Terms |
|---|---|
| Doc1 | st, louis |
| Doc2 | st, paul |
3.现在反向索引被再反向,从doc中compile 独立的tokens(st, louis, and paul)。compile这样的fielddata可能会消耗大量堆内存。特别是大量的documents和terms的情况下。 所有字段值都将加载到内存中。
对于1.3之前的版本,fielddata缓存大小是无限制的。 从1.3版开始,Elasticsearch添加了一个fielddata断路器,如果查询尝试加载需要超过60%的堆的fielddata,则会触发。
Filter cache: 过滤缓存也使用JVM堆。 在2.0之前的版本中,Elasticsearch自动缓存过滤的查询,最大值为堆的10%,并且将最近最少使用的数据逐出。 从版本2.0开始,Elasticsearch会根据频率和段大小自动开始优化其过滤器缓存(缓存仅发生在索引中少于10,000个文档的段或小于总文档的3%)。 因此,过滤器缓存指标仅适用于使用2.0之前版本的Elasticsearch用户。
例如,过滤器查询可以仅返回年份字段中的值在2000-2005范围内的文档。 在首次执行过滤器查询时,Elasticsearch将创建一个与其相匹配的文档的位组(如果文档匹配则为1,否则为0)。 使用相同过滤器后续执行查询将重用此信息。 无论何时添加或更新新的文档,也会更新bitset。 如果您在2.0之前使用的是Elasticsearch版本,那么您应该关注过滤器缓存以及驱逐指标(更多关于以下内容)。
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Size of the fielddata cache (bytes) | indices.fielddata.memory_size_in_bytes |
Resource: Utilization |
| Number of evictions from the fielddata cache | indices.fielddata.evictions |
Resource: Saturation |
| Size of the filter cache (bytes) (only pre-version 2.x) | indices.filter_cache.memory_size_in_bytes |
Resource: Utilization |
| Number of evictions from the filter cache (only pre-version 2.x) | indices.filter_cache.evictions |
Resource: Saturation |
Fielddata cache evictions: 理想情况下,我们需要限制fielddata evictions的数量,因为他们很吃I/O。如果你看到很多evictions并且你又不能增加内存。es建议限制fielddata cache的大小为20%的heap size。这些是可以在elasticsearch.yml中进行配置的。当fielddata cache达到20%的heap size时,es将驱逐最近最少使用的fielddata,然后允许您将新的fielddata加载到缓存中。
es还建议使用doc values,因为它们与fielddata的用途相同。由于它们存储在磁盘上,它们不依赖于JVM heap。尽管doc values不能被用来分析字符串, they do save fielddata usage when aggregating or sorting on other types of fields。在2.0版本后,doc values会在文档被index的时候自动创建,which has reduced fielddata/heap usage for many users。
Filter cache evictions: 如前所述,filter cache eviction 指标只有在es2.0之前的版本可用。每个segment都维护自己的filter cache eviction。因为eviction在大的segment上操作成本较高,没有的明确的方法来评估eviction。但是如果你发现eviction很频繁,表明你并没有很好地利用filter,此时你需要重新创建filter,即使放弃原有的缓存,你也可能需要调整查询方式(用bool query 而不是 and/or/not filter)。
Pending tasks:
| Metric description | Name | [Metric type][monitoring-101-blog] |
|---|---|---|
| Number of pending tasks | pending_task_total |
Resource: Saturation |
| Number of urgent pending tasks | pending_tasks_priority_urgent |
Resource: Saturation |
| Number of high-priority pending tasks | pending_tasks_priority_high |
Resource: Saturation |
pending task只能由主节点来进行处理,这些任务包括创建索引并将shards分配给节点。任务分优先次序。如果任务的产生比处理速度更快,将会产生堆积。待处理任务的数量是您的群集运行平稳的良好指标,如果您的主节点非常忙,并且未完成的任务数量不会减少,我们需要仔细检查原因。
Unsuccessful GET requests: GET请求比正常的搜索请求更简单 - 它根据其ID来检索文档。 get-by-ID请求不成功意味着找不到文档ID
(function () { ('pre.prettyprint code').each(function () {
var lines = (this).text().split(′\n′).length;var numbering = $('
(this).addClass(′has−numbering′).parent().append( numbering);
for (i = 1; i <= lines; i++) {
numbering.append( (' ').text(i));
};
$numbering.fadeIn(1700);
});
});