【风控模型】神经网络DNN算法构建信用评分卡模型
【博客地址】:https://blog.csdn.net/sunyaowu315
【博客大纲地址】:https://blog.csdn.net/sunyaowu315/article/details/82905347
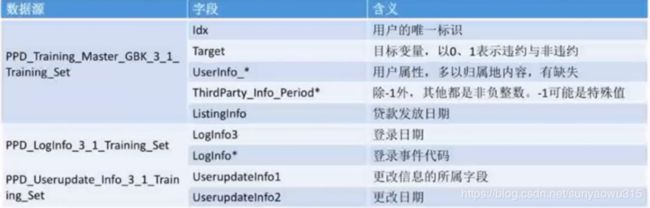
数据集介绍:
本次案例分析所用的数据,是拍拍贷发起的一次与信贷申请审核工作相关的竞赛数据集。其中共有3份文件:
- PPD_Training_Master_GBK_3_1_Training_Set.csv :信贷用户在拍拍贷上的申报信息和部分三方数据信息,以及需要预测的目标变量。
- PPD_LogInfo_3_1_Training_Set : 信贷客户的登录信息
- PPD_Userupdate_Info_3_1_Training_Set :部分客户的信息修改行为
建模工作就是从上述三个文件中对数据进行加工,提取特征并且建立合适的模型,对贷后表现做预测。
关键字段
对数据分析、机器学习、数据科学、金融风控等感兴趣的小伙伴,需要数据集、代码、行业报告等各类学习资料,可关注微信公众号:风控圏子(别打错字,是圏子,不是圈子,算了直接复制吧!)

关注公众号后,可联系圈子助手加入我们的机器学习风控讨论群和反欺诈讨论群。(记得要备注喔!)
相互学习,共同成长。
主程序
import pandas as pd
import datetime
import collections
import numpy as np
import numbers
import random
import sys
_path = r'C:\Users\A3\Desktop\DNN_scorecard'
sys.path.append(_path)
import pickle
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from importlib import reload
from matplotlib import pyplot as plt
import operator
reload(sys)
#sys.setdefaultencoding( "utf-8")
# -*- coding: utf-8 -*-
### 对时间窗口,计算累计产比 ###
def TimeWindowSelection(df, daysCol, time_windows):
'''
:param df: the dataset containg variabel of days
:param daysCol: the column of days
:param time_windows: the list of time window
:return:
'''
freq_tw = {}
for tw in time_windows:
freq = sum(df[daysCol].apply(lambda x: int(x<=tw)))
freq_tw[tw] = freq
return freq_tw
def DeivdedByZero(nominator, denominator):
'''
当分母为0时,返回0;否则返回正常值
'''
if denominator == 0:
return 0
else:
return nominator*1.0/denominator
#对某些统一的字段进行统一
def ChangeContent(x):
y = x.upper()
if y == '_MOBILEPHONE':
y = '_PHONE'
return y
def MissingCategorial(df,x):
missing_vals = df[x].map(lambda x: int(x!=x))
return sum(missing_vals)*1.0/df.shape[0]
def MissingContinuous(df,x):
missing_vals = df[x].map(lambda x: int(np.isnan(x)))
return sum(missing_vals) * 1.0 / df.shape[0]
def MakeupRandom(x, sampledList):
if x==x:
return x
else:
randIndex = random.randint(0, len(sampledList)-1)
return sampledList[randIndex]
def Outlier_Dectection(df,x):
'''
:param df:
:param x:
:return:
'''
p25, p75 = np.percentile(df[x], 25),np.percentile(df[x], 75)
d = p75 - p25
upper, lower = p75 + 1.5*d, p25-1.5*d
truncation = df[x].map(lambda x: max(min(upper, x), lower))
return truncation
############################################################
#Step 0: 数据分析的初始工作, 包括读取数据文件、检查用户Id的一致性等#
############################################################
folderOfData = 'C:/Users/A3/Desktop/DNN_scorecard/'
data1 = pd.read_csv(folderOfData+'PPD_LogInfo_3_1_Training_Set.csv', header = 0)
data2 = pd.read_csv(folderOfData+'PPD_Training_Master_GBK_3_1_Training_Set.csv', header = 0,encoding = 'gbk')
data3 = pd.read_csv(folderOfData+'PPD_Userupdate_Info_3_1_Training_Set.csv', header = 0)
#将数据集分为训练集与测试集
all_ids = data2['Idx']
train_ids, test_ids = train_test_split(all_ids, test_size=0.3)
train_ids = pd.DataFrame(train_ids)
test_ids = pd.DataFrame(test_ids)
data1_train = pd.merge(left=train_ids,right = data1, on='Idx', how='inner')
data2_train = pd.merge(left=train_ids,right = data2, on='Idx', how='inner')
data3_train = pd.merge(left=train_ids,right = data3, on='Idx', how='inner')
data1_test = pd.merge(left=test_ids,right = data1, on='Idx', how='inner')
data2_test = pd.merge(left=test_ids,right = data2, on='Idx', how='inner')
data3_test = pd.merge(left=test_ids,right = data3, on='Idx', how='inner')
#############################################################################################
# Step 1: 从PPD_LogInfo_3_1_Training_Set & PPD_Userupdate_Info_3_1_Training_Set数据中衍生特征#
#############################################################################################
# compare whether the four city variables match
data2_train['city_match'] = data2_train.apply(lambda x: int(x.UserInfo_2 == x.UserInfo_4 == x.UserInfo_8 == x.UserInfo_20),axis = 1)
del data2_train['UserInfo_2']
del data2_train['UserInfo_4']
del data2_train['UserInfo_8']
del data2_train['UserInfo_20']
### 提取申请日期,计算日期差,查看日期差的分布
data1_train['logInfo'] = data1_train['LogInfo3'].map(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))
data1_train['Listinginfo'] = data1_train['Listinginfo1'].map(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))
data1_train['ListingGap'] = data1_train[['logInfo','Listinginfo']].apply(lambda x: (x[1]-x[0]).days,axis = 1)
### 提取申请日期,计算日期差,查看日期差的分布
'''
使用180天作为最大的时间窗口计算新特征
所有可以使用的时间窗口可以有7 days, 30 days, 60 days, 90 days, 120 days, 150 days and 180 days.
在每个时间窗口内,计算总的登录次数,不同的登录方式,以及每种登录方式的平均次数
'''
time_window = [7, 30, 60, 90, 120, 150, 180]
var_list = ['LogInfo1','LogInfo2']
data1GroupbyIdx = pd.DataFrame({'Idx':data1_train['Idx'].drop_duplicates()})
for tw in time_window:
data1_train['TruncatedLogInfo'] = data1_train['Listinginfo'].map(lambda x: x + datetime.timedelta(-tw))
temp = data1_train.loc[data1_train['logInfo'] >= data1_train['TruncatedLogInfo']]
for var in var_list:
#count the frequences of LogInfo1 and LogInfo2
count_stats = temp.groupby(['Idx'])[var].count().to_dict()
data1GroupbyIdx[str(var)+'_'+str(tw)+'_count'] = data1GroupbyIdx['Idx'].map(lambda x: count_stats.get(x,0))
# count the distinct value of LogInfo1 and LogInfo2
Idx_UserupdateInfo1 = temp[['Idx', var]].drop_duplicates()
uniq_stats = Idx_UserupdateInfo1.groupby(['Idx'])[var].count().to_dict()
data1GroupbyIdx[str(var) + '_' + str(tw) + '_unique'] = data1GroupbyIdx['Idx'].map(lambda x: uniq_stats.get(x,0))
# calculate the average count of each value in LogInfo1 and LogInfo2
data1GroupbyIdx[str(var) + '_' + str(tw) + '_avg_count'] = data1GroupbyIdx[[str(var)+'_'+str(tw)+'_count',str(var) + '_' + str(tw) + '_unique']].\
apply(lambda x: DeivdedByZero(x[0],x[1]), axis=1)
data3_train['ListingInfo'] = data3_train['ListingInfo1'].map(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d'))
data3_train['UserupdateInfo'] = data3_train['UserupdateInfo2'].map(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d'))
data3_train['ListingGap'] = data3_train[['UserupdateInfo','ListingInfo']].apply(lambda x: (x[1]-x[0]).days,axis = 1)
collections.Counter(data3_train['ListingGap'])
hist_ListingGap = np.histogram(data3_train['ListingGap'])
hist_ListingGap = pd.DataFrame({'Freq':hist_ListingGap[0],'gap':hist_ListingGap[1][1:]})
hist_ListingGap['CumFreq'] = hist_ListingGap['Freq'].cumsum()
hist_ListingGap['CumPercent'] = hist_ListingGap['CumFreq'].map(lambda x: x*1.0/hist_ListingGap.iloc[-1]['CumFreq'])
'''
对 QQ和qQ, Idnumber和idNumber,MOBILEPHONE和PHONE 进行统一
在时间切片内,计算
(1) 更新的频率
(2) 每种更新对象的种类个数
(3) 对重要信息如IDNUMBER,HASBUYCAR, MARRIAGESTATUSID, PHONE的更新
'''
data3_train['UserupdateInfo1'] = data3_train['UserupdateInfo1'].map(ChangeContent)
data3GroupbyIdx = pd.DataFrame({'Idx':data3_train['Idx'].drop_duplicates()})
time_window = [7, 30, 60, 90, 120, 150, 180]
for tw in time_window:
data3_train['TruncatedLogInfo'] = data3_train['ListingInfo'].map(lambda x: x + datetime.timedelta(-tw))
temp = data3_train.loc[data3_train['UserupdateInfo'] >= data3_train['TruncatedLogInfo']]
#frequency of updating
freq_stats = temp.groupby(['Idx'])['UserupdateInfo1'].count().to_dict()
data3GroupbyIdx['UserupdateInfo_'+str(tw)+'_freq'] = data3GroupbyIdx['Idx'].map(lambda x: freq_stats.get(x,0))
# number of updated types
Idx_UserupdateInfo1 = temp[['Idx','UserupdateInfo1']].drop_duplicates()
uniq_stats = Idx_UserupdateInfo1.groupby(['Idx'])['UserupdateInfo1'].count().to_dict()
data3GroupbyIdx['UserupdateInfo_' + str(tw) + '_unique'] = data3GroupbyIdx['Idx'].map(lambda x: uniq_stats.get(x, x))
#average count of each type
data3GroupbyIdx['UserupdateInfo_' + str(tw) + '_avg_count'] = data3GroupbyIdx[['UserupdateInfo_'+str(tw)+'_freq', 'UserupdateInfo_' + str(tw) + '_unique']]. \
apply(lambda x: x[0] * 1.0 / x[1], axis=1)
#whether the applicant changed items like IDNUMBER,HASBUYCAR, MARRIAGESTATUSID, PHONE
Idx_UserupdateInfo1['UserupdateInfo1'] = Idx_UserupdateInfo1['UserupdateInfo1'].map(lambda x: [x])
Idx_UserupdateInfo1_V2 = Idx_UserupdateInfo1.groupby(['Idx'])['UserupdateInfo1'].sum()
for item in ['_IDNUMBER','_HASBUYCAR','_MARRIAGESTATUSID','_PHONE']:
item_dict = Idx_UserupdateInfo1_V2.map(lambda x: int(item in x)).to_dict()
data3GroupbyIdx['UserupdateInfo_' + str(tw) + str(item)] = data3GroupbyIdx['Idx'].map(lambda x: item_dict.get(x, x))
# Combine the above features with raw features in PPD_Training_Master_GBK_3_1_Training_Set
allData = pd.concat([data2_train.set_index('Idx'), data3GroupbyIdx.set_index('Idx'), data1GroupbyIdx.set_index('Idx')],axis= 1)
allData.to_csv(folderOfData+'allData_0.csv',encoding = 'gbk')
########################################
# Step 2: 对类别型变量和数值型变量进行预处理#
########################################
allData = pd.read_csv(folderOfData+'allData_0.csv',header = 0,encoding = 'gbk')
allFeatures = list(allData.columns)
allFeatures.remove('target')
if 'Idx' in allFeatures:
allFeatures.remove('Idx')
allFeatures.remove('ListingInfo')
#检查是否有常数型变量,并且检查是类别型还是数值型变量
numerical_var = []
for col in allFeatures:
if len(set(allData[col])) == 1:
print('delete {} from the dataset because it is a constant'.format(col))
del allData[col]
allFeatures.remove(col)
else:
uniq_valid_vals = [i for i in allData[col] if i == i]
uniq_valid_vals = list(set(uniq_valid_vals))
if len(uniq_valid_vals) >= 10 and isinstance(uniq_valid_vals[0], numbers.Real):
numerical_var.append(col)
categorical_var = [i for i in allFeatures if i not in numerical_var]
#检查变量的最多值的占比情况,以及每个变量中占比最大的值
records_count = allData.shape[0]
col_most_values,col_large_value = {},{}
for col in allFeatures:
value_count = allData[col].groupby(allData[col]).count()
col_most_values[col] = max(value_count)/records_count
large_value = value_count[value_count== max(value_count)].index[0]
col_large_value[col] = large_value
col_most_values_df = pd.DataFrame.from_dict(col_most_values, orient = 'index')
col_most_values_df.columns = ['max percent']
col_most_values_df = col_most_values_df.sort_values(by = 'max percent', ascending = False)
pcnt = list(col_most_values_df[:500]['max percent'])
vars = list(col_most_values_df[:500].index)
plt.bar(range(len(pcnt)), height = pcnt)
plt.title('Largest Percentage of Single Value in Each Variable')
#计算多数值占比超过90%的字段中,少数值的坏样本率是否会显著高于多数值
large_percent_cols = list(col_most_values_df[col_most_values_df['max percent']>=0.9].index)
bad_rate_diff = {}
for col in large_percent_cols:
large_value = col_large_value[col]
temp = allData[[col,'target']]
temp[col] = temp.apply(lambda x: int(x[col]==large_value),axis=1)
bad_rate = temp.groupby(col).mean()
if bad_rate.iloc[0]['target'] == 0:
bad_rate_diff[col] = 0
continue
bad_rate_diff[col] = np.log(bad_rate.iloc[0]['target']/bad_rate.iloc[1]['target'])
bad_rate_diff_sorted = sorted(bad_rate_diff.items(),key=lambda x: x[1], reverse=True)
bad_rate_diff_sorted_values = [x[1] for x in bad_rate_diff_sorted]
plt.bar(x = range(len(bad_rate_diff_sorted_values)), height = bad_rate_diff_sorted_values)
#由于所有的少数值的坏样本率并没有显著高于多数值,意味着这些变量可以直接剔除
for col in large_percent_cols:
if col in numerical_var:
numerical_var.remove(col)
else:
categorical_var.remove(col)
del allData[col]
'''
对类别型变量,如果缺失超过80%, 就删除,否则保留。
'''
missing_pcnt_threshould_1 = 0.8
for col in categorical_var:
missingRate = MissingCategorial(allData,col)
print('{0} has missing rate as {1}'.format(col,missingRate))
if missingRate > missing_pcnt_threshould_1:
categorical_var.remove(col)
del allData[col]
allData_bk = allData.copy()
'''
用one-hot对类别型变量进行编码
'''
dummy_map = {}
dummy_columns = []
for raw_col in categorical_var:
dummies = pd.get_dummies(allData.loc[:, raw_col], prefix=raw_col)
col_onehot = pd.concat([allData[raw_col], dummies], axis=1)
col_onehot = col_onehot.drop_duplicates()
allData = pd.concat([allData, dummies], axis=1)
del allData[raw_col]
dummy_map[raw_col] = col_onehot
dummy_columns = dummy_columns + list(dummies)
with open(folderOfData+'dummy_map.pkl',"wb") as f:
f.write(pickle.dumps(dummy_map))
with open(folderOfData+'dummy_columns.pkl',"wb") as f:
f.write(pickle.dumps(dummy_columns))
'''
检查数值型变量
'''
missing_pcnt_threshould_2 = 0.8
deleted_var = []
for col in numerical_var:
missingRate = MissingContinuous(allData, col)
print('{0} has missing rate as {1}'.format(col, missingRate))
if missingRate > missing_pcnt_threshould_2:
deleted_var.append(col)
print('we delete variable {} because of its high missing rate'.format(col))
else:
if missingRate > 0:
not_missing = allData.loc[allData[col] == allData[col]][col]
#makeuped = allData[col].map(lambda x: MakeupRandom(x, list(not_missing)))
missing_position = allData.loc[allData[col] != allData[col]][col].index
not_missing_sample = random.sample(list(not_missing), len(missing_position))
allData.loc[missing_position,col] = not_missing_sample
#del allData[col]
#allData[col] = makeuped
missingRate2 = MissingContinuous(allData, col)
print('missing rate after making up is:{}'.format(str(missingRate2)))
if deleted_var != []:
for col in deleted_var:
numerical_var.remove(col)
del allData[col]
'''
对极端值变量做处理。
'''
max_min_standardized = {}
for col in numerical_var:
truncation = Outlier_Dectection(allData, col)
upper, lower = max(truncation), min(truncation)
d = upper - lower
if d == 0:
print("{} is almost a constant".format(col))
numerical_var.remove(col)
continue
allData[col] = truncation.map(lambda x: (upper - x)/d)
max_min_standardized[col] = [lower, upper]
with open(folderOfData+'max_min_standardized.pkl',"wb") as f:
f.write(pickle.dumps(max_min_standardized))
allData.to_csv(folderOfData+'allData_1_DNN.csv', header=True,encoding='gbk', columns = allData.columns, index=False)
allData = pd.read_csv(folderOfData+'allData_1_DNN.csv', header=0,encoding='gbk')
########################################
# Step 3: 构建基于TensorFlow的神经网络模型 #
########################################
allFeatures = list(allData.columns)
allFeatures.remove('target')
with open(folderOfData+'allFeatures.pkl',"wb") as f:
f.write(pickle.dumps(allFeatures))
x_train = np.matrix(allData[allFeatures])
y_train = np.matrix(allData['target']).T
#进一步将训练集拆分成训练集和验证集。在新训练集上进行参数估计,在验证集上决定最优的参数
x_train, x_validation, y_train, y_validation = train_test_split(x_train, y_train,test_size=0.4,random_state=9)
#Example: select the best number of units in the 1-layer hidden layer
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.estimators import SKCompat
no_hidden_units_selection = {}
feature_columns = [tf.contrib.layers.real_valued_column("", dimension = x_train.shape[1])]
for no_hidden_units in range(50,101,10):
print("the current choise of hidden units number is {}".format(no_hidden_units))
clf0 = tf.contrib.learn.DNNClassifier(feature_columns = feature_columns,
hidden_units=[no_hidden_units, no_hidden_units-10,no_hidden_units-20],
n_classes=2,
dropout = 0.5
)
clf = SKCompat(clf0)
clf.fit(x_train, y_train, batch_size=256,steps = 100000)
#monitor the performance of the model using AUC score
clf_pred_proba = clf._estimator.predict_proba(x_validation)
pred_proba = [i[1] for i in clf_pred_proba]
auc_score = roc_auc_score(y_validation.getA(),pred_proba)
no_hidden_units_selection[no_hidden_units] = auc_score
best_hidden_units = max(no_hidden_units_selection.items(), key=operator.itemgetter(1))[0] #80
#Example: check the dropout effect
dropout_selection = {}
feature_columns = [tf.contrib.layers.real_valued_column("", dimension = x_train.shape[1])]
for dropout_prob in np.linspace(0,0.99,20):
print("the current choise of drop out rate is {}".format(dropout_prob))
clf0 = tf.contrib.learn.DNNClassifier(feature_columns = feature_columns,
hidden_units = [best_hidden_units, best_hidden_units-10,best_hidden_units-20],
n_classes=2,
dropout = dropout_prob
)
clf = SKCompat(clf0)
clf.fit(x_train, y_train, batch_size=256,steps = 100000)
#monitor the performance of the model using AUC score
clf_pred_proba = clf._estimator.predict_proba(x_validation)
pred_proba = [i[1] for i in clf_pred_proba]
auc_score = roc_auc_score(y_validation.getA(),pred_proba)
dropout_selection[dropout_prob] = auc_score
best_dropout_prob = max(dropout_selection.items(), key=operator.itemgetter(1))[0] #0.0
#the best model is
clf1 = tf.contrib.learn.DNNClassifier(feature_columns = feature_columns,
hidden_units = [best_hidden_units, best_hidden_units-10,best_hidden_units-20],
n_classes=2,
dropout = best_dropout_prob)
clf1.fit(x_train, y_train, batch_size=256,steps = 100000)
clf_pred_proba = clf1.predict_proba(x_train)
pred_proba = [i[1] for i in clf_pred_proba]
auc_score = roc_auc_score(y_train.getA(),pred_proba) #0.773
功能模块
import numpy as np
import pandas as pd
def SplitData(df, col, numOfSplit, special_attribute=[]):
'''
:param df: 按照col排序后的数据集
:param col: 待分箱的变量
:param numOfSplit: 切分的组别数
:param special_attribute: 在切分数据集的时候,某些特殊值需要排除在外
:return: 在原数据集上增加一列,把原始细粒度的col重新划分成粗粒度的值,便于分箱中的合并处理
'''
df2 = df.copy()
if special_attribute != []:
df2 = df.loc[~df[col].isin(special_attribute)]
N = df2.shape[0]
n = int(N/numOfSplit)
splitPointIndex = [i*n for i in range(1,numOfSplit)]
rawValues = sorted(list(df2[col]))
splitPoint = [rawValues[i] for i in splitPointIndex]
splitPoint = sorted(list(set(splitPoint)))
return splitPoint
def MaximumBinPcnt(df,col):
'''
:return: 数据集df中,变量col的分布占比
'''
N = df.shape[0]
total = df.groupby([col])[col].count()
pcnt = total*1.0/N
return max(pcnt)
def Chi2(df, total_col, bad_col):
'''
:param df: 包含全部样本总计与坏样本总计的数据框
:param total_col: 全部样本的个数
:param bad_col: 坏样本的个数
:return: 卡方值
'''
df2 = df.copy()
# 求出df中,总体的坏样本率和好样本率
badRate = sum(df2[bad_col])*1.0/sum(df2[total_col])
# 当全部样本只有好或者坏样本时,卡方值为0
if badRate in [0,1]:
return 0
df2['good'] = df2.apply(lambda x: x[total_col] - x[bad_col], axis = 1)
goodRate = sum(df2['good']) * 1.0 / sum(df2[total_col])
# 期望坏(好)样本个数=全部样本个数*平均坏(好)样本占比
df2['badExpected'] = df[total_col].apply(lambda x: x*badRate)
df2['goodExpected'] = df[total_col].apply(lambda x: x * goodRate)
badCombined = zip(df2['badExpected'], df2[bad_col])
goodCombined = zip(df2['goodExpected'], df2['good'])
badChi = [(i[0]-i[1])**2/i[0] for i in badCombined]
goodChi = [(i[0] - i[1]) ** 2 / i[0] for i in goodCombined]
chi2 = sum(badChi) + sum(goodChi)
return chi2
def BinBadRate(df, col, target, grantRateIndicator=0):
'''
:param df: 需要计算好坏比率的数据集
:param col: 需要计算好坏比率的特征
:param target: 好坏标签
:param grantRateIndicator: 1返回总体的坏样本率,0不返回
:return: 每箱的坏样本率,以及总体的坏样本率(当grantRateIndicator==1时)
'''
total = df.groupby([col])[target].count()
total = pd.DataFrame({'total': total})
bad = df.groupby([col])[target].sum()
bad = pd.DataFrame({'bad': bad})
regroup = total.merge(bad, left_index=True, right_index=True, how='left')
regroup.reset_index(level=0, inplace=True)
regroup['bad_rate'] = regroup.apply(lambda x: x.bad * 1.0 / x.total, axis=1)
dicts = dict(zip(regroup[col],regroup['bad_rate']))
if grantRateIndicator==0:
return (dicts, regroup)
N = sum(regroup['total'])
B = sum(regroup['bad'])
overallRate = B * 1.0 / N
return (dicts, regroup, overallRate)
def AssignGroup(x, bin):
'''
:return: 数值x在区间映射下的结果。例如,x=2,bin=[0,3,5], 由于0
N = len(bin)
if x<=min(bin):
return min(bin)
elif x>max(bin):
return 10e10
else:
for i in range(N-1):
if bin[i] < x <= bin[i+1]:
return bin[i+1]
def ChiMerge(df, col, target, max_interval=5,special_attribute=[],minBinPcnt=0):
'''
:param df: 包含目标变量与分箱属性的数据框
:param col: 需要分箱的属性
:param target: 目标变量,取值0或1
:param max_interval: 最大分箱数。如果原始属性的取值个数低于该参数,不执行这段函数
:param special_attribute: 不参与分箱的属性取值
:param minBinPcnt:最小箱的占比,默认为0
:return: 分箱结果
'''
colLevels = sorted(list(set(df[col])))
N_distinct = len(colLevels)
if N_distinct <= max_interval: #如果原始属性的取值个数低于max_interval,不执行这段函数
print("The number of original levels for {} is less than or equal to max intervals".format(col))
return colLevels[:-1]
else:
if len(special_attribute)>=1:
df1 = df.loc[df[col].isin(special_attribute)]
df2 = df.loc[~df[col].isin(special_attribute)]
else:
df2 = df.copy()
N_distinct = len(list(set(df2[col])))
# 步骤一: 通过col对数据集进行分组,求出每组的总样本数与坏样本数
if N_distinct > 100:
split_x = SplitData(df2, col, 100)
df2['temp'] = df2[col].map(lambda x: AssignGroup(x, split_x))
else:
df2['temp'] = df2[col]
# 总体bad rate将被用来计算expected bad count
(binBadRate, regroup, overallRate) = BinBadRate(df2, 'temp', target, grantRateIndicator=1)
# 首先,每个单独的属性值将被分为单独的一组
# 对属性值进行排序,然后两两组别进行合并
colLevels = sorted(list(set(df2['temp'])))
groupIntervals = [[i] for i in colLevels]
# 步骤二:建立循环,不断合并最优的相邻两个组别,直到:
# 1,最终分裂出来的分箱数<=预设的最大分箱数
# 2,每箱的占比不低于预设值(可选)
# 3,每箱同时包含好坏样本
# 如果有特殊属性,那么最终分裂出来的分箱数=预设的最大分箱数-特殊属性的个数
split_intervals = max_interval - len(special_attribute)
while (len(groupIntervals) > split_intervals): # 终止条件: 当前分箱数=预设的分箱数
# 每次循环时, 计算合并相邻组别后的卡方值。具有最小卡方值的合并方案,是最优方案
chisqList = []
for k in range(len(groupIntervals)-1):
temp_group = groupIntervals[k] + groupIntervals[k+1]
df2b = regroup.loc[regroup['temp'].isin(temp_group)]
chisq = Chi2(df2b, 'total', 'bad')
chisqList.append(chisq)
best_comnbined = chisqList.index(min(chisqList))
groupIntervals[best_comnbined] = groupIntervals[best_comnbined] + groupIntervals[best_comnbined+1]
# 当将最优的相邻的两个变量合并在一起后,需要从原来的列表中将其移除。例如,将[3,4,5] 与[6,7]合并成[3,4,5,6,7]后,需要将[3,4,5] 与[6,7]移除,保留[3,4,5,6,7]
groupIntervals.remove(groupIntervals[best_comnbined+1])
groupIntervals = [sorted(i) for i in groupIntervals]
cutOffPoints = [max(i) for i in groupIntervals[:-1]]
# 检查是否有箱没有好或者坏样本。如果有,需要跟相邻的箱进行合并,直到每箱同时包含好坏样本
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
(binBadRate,regroup) = BinBadRate(df2, 'temp_Bin', target)
[minBadRate, maxBadRate] = [min(binBadRate.values()),max(binBadRate.values())]
while minBadRate ==0 or maxBadRate == 1:
# 找出全部为好/坏样本的箱
indexForBad01 = regroup[regroup['bad_rate'].isin([0,1])].temp_Bin.tolist()
bin=indexForBad01[0]
# 如果是最后一箱,则需要和上一个箱进行合并,也就意味着分裂点cutOffPoints中的最后一个需要移除
if bin == max(regroup.temp_Bin):
cutOffPoints = cutOffPoints[:-1]
# 如果是第一箱,则需要和下一个箱进行合并,也就意味着分裂点cutOffPoints中的第一个需要移除
elif bin == min(regroup.temp_Bin):
cutOffPoints = cutOffPoints[1:]
# 如果是中间的某一箱,则需要和前后中的一个箱进行合并,依据是较小的卡方值
else:
# 和前一箱进行合并,并且计算卡方值
currentIndex = list(regroup.temp_Bin).index(bin)
prevIndex = list(regroup.temp_Bin)[currentIndex - 1]
df3 = df2.loc[df2['temp_Bin'].isin([prevIndex, bin])]
(binBadRate, df2b) = BinBadRate(df3, 'temp_Bin', target)
chisq1 = Chi2(df2b, 'total', 'bad')
# 和后一箱进行合并,并且计算卡方值
laterIndex = list(regroup.temp_Bin)[currentIndex + 1]
df3b = df2.loc[df2['temp_Bin'].isin([laterIndex, bin])]
(binBadRate, df2b) = BinBadRate(df3b, 'temp_Bin', target)
chisq2 = Chi2(df2b, 'total', 'bad')
if chisq1 < chisq2:
cutOffPoints.remove(cutOffPoints[currentIndex - 1])
else:
cutOffPoints.remove(cutOffPoints[currentIndex])
# 完成合并之后,需要再次计算新的分箱准则下,每箱是否同时包含好坏样本
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
(binBadRate, regroup) = BinBadRate(df2, 'temp_Bin', target)
[minBadRate, maxBadRate] = [min(binBadRate.values()), max(binBadRate.values())]
# 需要检查分箱后的最小占比
if minBinPcnt > 0:
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
valueCounts = groupedvalues.value_counts().to_frame()
N = sum(valueCounts['temp'])
valueCounts['pcnt'] = valueCounts['temp'].apply(lambda x: x * 1.0 / N)
valueCounts = valueCounts.sort_index()
minPcnt = min(valueCounts['pcnt'])
while minPcnt < minBinPcnt and len(cutOffPoints) > 2:
# 找出占比最小的箱
indexForMinPcnt = valueCounts[valueCounts['pcnt'] == minPcnt].index.tolist()[0]
# 如果占比最小的箱是最后一箱,则需要和上一个箱进行合并,也就意味着分裂点cutOffPoints中的最后一个需要移除
if indexForMinPcnt == max(valueCounts.index):
cutOffPoints = cutOffPoints[:-1]
# 如果占比最小的箱是第一箱,则需要和下一个箱进行合并,也就意味着分裂点cutOffPoints中的第一个需要移除
elif indexForMinPcnt == min(valueCounts.index):
cutOffPoints = cutOffPoints[1:]
# 如果占比最小的箱是中间的某一箱,则需要和前后中的一个箱进行合并,依据是较小的卡方值
else:
# 和前一箱进行合并,并且计算卡方值
currentIndex = list(valueCounts.index).index(indexForMinPcnt)
prevIndex = list(valueCounts.index)[currentIndex - 1]
df3 = df2.loc[df2['temp_Bin'].isin([prevIndex, indexForMinPcnt])]
(binBadRate, df2b) = BinBadRate(df3, 'temp_Bin', target)
chisq1 = Chi2(df2b, 'total', 'bad')
# 和后一箱进行合并,并且计算卡方值
laterIndex = list(valueCounts.index)[currentIndex + 1]
df3b = df2.loc[df2['temp_Bin'].isin([laterIndex, indexForMinPcnt])]
(binBadRate, df2b) = BinBadRate(df3b, 'temp_Bin', target)
chisq2 = Chi2(df2b, 'total', 'bad')
if chisq1 < chisq2:
cutOffPoints.remove(cutOffPoints[currentIndex - 1])
else:
cutOffPoints.remove(cutOffPoints[currentIndex])
groupedvalues = df2['temp'].apply(lambda x: AssignBin(x, cutOffPoints))
df2['temp_Bin'] = groupedvalues
valueCounts = groupedvalues.value_counts().to_frame()
valueCounts['pcnt'] = valueCounts['temp'].apply(lambda x: x * 1.0 / N)
valueCounts = valueCounts.sort_index()
minPcnt = min(valueCounts['pcnt'])
cutOffPoints = special_attribute + cutOffPoints
return cutOffPoints
def BadRateEncoding(df, col, target):
'''
:return: 在数据集df中,用坏样本率给col进行编码。target表示坏样本标签
'''
regroup = BinBadRate(df, col, target, grantRateIndicator=0)[1]
br_dict = regroup[[col,'bad_rate']].set_index([col]).to_dict(orient='index')
for k, v in br_dict.items():
br_dict[k] = v['bad_rate']
badRateEnconding = df[col].map(lambda x: br_dict[x])
return {'encoding':badRateEnconding, 'bad_rate':br_dict}
def AssignBin(x, cutOffPoints,special_attribute=[]):
'''
:param x: 某个变量的某个取值
:param cutOffPoints: 上述变量的分箱结果,用切分点表示
:param special_attribute: 不参与分箱的特殊取值
:return: 分箱后的对应的第几个箱,从0开始
例如, cutOffPoints = [10,20,30], 对于 x = 7, 返回 Bin 0;对于x=23,返回Bin 2; 对于x = 35, return Bin 3。
对于特殊值,返回的序列数前加"-"
'''
cutOffPoints2 = [i for i in cutOffPoints if i not in special_attribute]
numBin = len(cutOffPoints2)
if x in special_attribute:
i = special_attribute.index(x)+1
return 'Bin {}'.format(0-i)
if x<=cutOffPoints2[0]:
return 'Bin 0'
elif x > cutOffPoints2[-1]:
return 'Bin {}'.format(numBin)
else:
for i in range(0,numBin):
if cutOffPoints2[i] < x <= cutOffPoints2[i+1]:
return 'Bin {}'.format(i+1)
def CalcWOE(df, col, target):
'''
:param df: 包含需要计算WOE的变量和目标变量
:param col: 需要计算WOE、IV的变量,必须是分箱后的变量,或者不需要分箱的类别型变量
:param target: 目标变量,0、1表示好、坏
:return: 返回WOE和IV
'''
total = df.groupby([col])[target].count()
total = pd.DataFrame({'total': total})
bad = df.groupby([col])[target].sum()
bad = pd.DataFrame({'bad': bad})
regroup = total.merge(bad, left_index=True, right_index=True, how='left')
regroup.reset_index(level=0, inplace=True)
N = sum(regroup['total'])
B = sum(regroup['bad'])
regroup['good'] = regroup['total'] - regroup['bad']
G = N - B
regroup['bad_pcnt'] = regroup['bad'].map(lambda x: x*1.0/B)
regroup['good_pcnt'] = regroup['good'].map(lambda x: x * 1.0 / G)
regroup['WOE'] = regroup.apply(lambda x: np.log(x.good_pcnt*1.0/x.bad_pcnt),axis = 1)
WOE_dict = regroup[[col,'WOE']].set_index(col).to_dict(orient='index')
for k, v in WOE_dict.items():
WOE_dict[k] = v['WOE']
IV = regroup.apply(lambda x: (x.good_pcnt-x.bad_pcnt)*np.log(x.good_pcnt*1.0/x.bad_pcnt),axis = 1)
IV = sum(IV)
return {"WOE": WOE_dict, 'IV':IV}
def FeatureMonotone(x):
'''
:return: 返回序列x中有几个元素不满足单调性,以及这些元素的位置。
例如,x=[1,3,2,5], 元素3比前后两个元素都大,不满足单调性;元素2比前后两个元素都小,也不满足单调性。
故返回的不满足单调性的元素个数为2,位置为1和2.
'''
monotone = [x[i]<x[i+1] and x[i] < x[i-1] or x[i]>x[i+1] and x[i] > x[i-1] for i in range(1,len(x)-1)]
index_of_nonmonotone = [i+1 for i in range(len(monotone)) if monotone[i]]
return {'count_of_nonmonotone':monotone.count(True), 'index_of_nonmonotone':index_of_nonmonotone}
## 判断某变量的坏样本率是否单调
def BadRateMonotone(df, sortByVar, target,special_attribute = []):
'''
:param df: 包含检验坏样本率的变量,和目标变量
:param sortByVar: 需要检验坏样本率的变量
:param target: 目标变量,0、1表示好、坏
:param special_attribute: 不参与检验的特殊值
:return: 坏样本率单调与否
'''
df2 = df.loc[~df[sortByVar].isin(special_attribute)]
if len(set(df2[sortByVar])) <= 2:
return True
regroup = BinBadRate(df2, sortByVar, target)[1]
combined = zip(regroup['total'],regroup['bad'])
badRate = [x[1]*1.0/x[0] for x in combined]
badRateNotMonotone = FeatureMonotone(badRate)['count_of_nonmonotone']
if badRateNotMonotone > 0:
return False
else:
return True
def MergeBad0(df,col,target, direction='bad'):
'''
:param df: 包含检验0%或者100%坏样本率
:param col: 分箱后的变量或者类别型变量。检验其中是否有一组或者多组没有坏样本或者没有好样本。如果是,则需要进行合并
:param target: 目标变量,0、1表示好、坏
:return: 合并方案,使得每个组里同时包含好坏样本
'''
regroup = BinBadRate(df, col, target)[1]
if direction == 'bad':
# 如果是合并0坏样本率的组,则跟最小的非0坏样本率的组进行合并
regroup = regroup.sort_values(by = 'bad_rate')
else:
# 如果是合并0好样本率的组,则跟最小的非0好样本率的组进行合并
regroup = regroup.sort_values(by='bad_rate',ascending=False)
regroup.index = range(regroup.shape[0])
col_regroup = [[i] for i in regroup[col]]
del_index = []
for i in range(regroup.shape[0]-1):
col_regroup[i+1] = col_regroup[i] + col_regroup[i+1]
del_index.append(i)
if direction == 'bad':
if regroup['bad_rate'][i+1] > 0:
break
else:
if regroup['bad_rate'][i+1] < 1:
break
col_regroup2 = [col_regroup[i] for i in range(len(col_regroup)) if i not in del_index]
newGroup = {}
for i in range(len(col_regroup2)):
for g2 in col_regroup2[i]:
newGroup[g2] = 'Bin '+str(i)
return newGroup
def Monotone_Merge(df, target, col):
'''
:return:将数据集df中,不满足坏样本率单调性的变量col进行合并,使得合并后的新的变量中,坏样本率单调,输出合并方案。
例如,col=[Bin 0, Bin 1, Bin 2, Bin 3, Bin 4]是不满足坏样本率单调性的。合并后的col是:
[Bin 0&Bin 1, Bin 2, Bin 3, Bin 4].
合并只能在相邻的箱中进行。
迭代地寻找最优合并方案。每一步迭代时,都尝试将所有非单调的箱进行合并,每一次尝试的合并都是跟前后箱进行合并再做比较
'''
def MergeMatrix(m, i,j,k):
'''
:param m: 需要合并行的矩阵
:param i,j: 合并第i和j行
:param k: 删除第k行
:return: 合并后的矩阵
'''
m[i, :] = m[i, :] + m[j, :]
m = np.delete(m, k, axis=0)
return m
def Merge_adjacent_Rows(i, bad_by_bin_current, bins_list_current, not_monotone_count_current):
'''
:param i: 需要将第i行与前、后的行分别进行合并,比较哪种合并方案最佳。判断准则是,合并后非单调性程度减轻,且更加均匀
:param bad_by_bin_current:合并前的分箱矩阵,包括每一箱的样本个数、坏样本个数和坏样本率
:param bins_list_current: 合并前的分箱方案
:param not_monotone_count_current:合并前的非单调性元素个数
:return:分箱后的分箱矩阵、分箱方案、非单调性元素个数和衡量均匀性的指标balance
'''
i_prev = i - 1
i_next = i + 1
bins_list = bins_list_current.copy()
bad_by_bin = bad_by_bin_current.copy()
not_monotone_count = not_monotone_count_current
#合并方案a:将第i箱与前一箱进行合并
bad_by_bin2a = MergeMatrix(bad_by_bin.copy(), i_prev, i, i)
bad_by_bin2a[i_prev, -1] = bad_by_bin2a[i_prev, -2] / bad_by_bin2a[i_prev, -3]
not_monotone_count2a = FeatureMonotone(bad_by_bin2a[:, -1])['count_of_nonmonotone']
# 合并方案b:将第i行与后一行进行合并
bad_by_bin2b = MergeMatrix(bad_by_bin.copy(), i, i_next, i_next)
bad_by_bin2b[i, -1] = bad_by_bin2b[i, -2] / bad_by_bin2b[i, -3]
not_monotone_count2b = FeatureMonotone(bad_by_bin2b[:, -1])['count_of_nonmonotone']
balance = ((bad_by_bin[:, 1] / N).T * (bad_by_bin[:, 1] / N))[0, 0]
balance_a = ((bad_by_bin2a[:, 1] / N).T * (bad_by_bin2a[:, 1] / N))[0, 0]
balance_b = ((bad_by_bin2b[:, 1] / N).T * (bad_by_bin2b[:, 1] / N))[0, 0]
#满足下述2种情况时返回方案a:(1)方案a能减轻非单调性而方案b不能;(2)方案a和b都能减轻非单调性,但是方案a的样本均匀性优于方案b
if not_monotone_count2a < not_monotone_count_current and not_monotone_count2b >= not_monotone_count_current or \
not_monotone_count2a < not_monotone_count_current and not_monotone_count2b < not_monotone_count_current and balance_a < balance_b:
bins_list[i_prev] = bins_list[i_prev] + bins_list[i]
bins_list.remove(bins_list[i])
bad_by_bin = bad_by_bin2a
not_monotone_count = not_monotone_count2a
balance = balance_a
# 同样地,满足下述2种情况时返回方案b:(1)方案b能减轻非单调性而方案a不能;(2)方案a和b都能减轻非单调性,但是方案b的样本均匀性优于方案a
elif not_monotone_count2a >= not_monotone_count_current and not_monotone_count2b < not_monotone_count_current or \
not_monotone_count2a < not_monotone_count_current and not_monotone_count2b < not_monotone_count_current and balance_a > balance_b:
bins_list[i] = bins_list[i] + bins_list[i_next]
bins_list.remove(bins_list[i_next])
bad_by_bin = bad_by_bin2b
not_monotone_count = not_monotone_count2b
balance = balance_b
#如果方案a和b都不能减轻非单调性,返回均匀性更优的合并方案
else:
if balance_a< balance_b:
bins_list[i] = bins_list[i] + bins_list[i_next]
bins_list.remove(bins_list[i_next])
bad_by_bin = bad_by_bin2b
not_monotone_count = not_monotone_count2b
balance = balance_b
else:
bins_list[i] = bins_list[i] + bins_list[i_next]
bins_list.remove(bins_list[i_next])
bad_by_bin = bad_by_bin2b
not_monotone_count = not_monotone_count2b
balance = balance_b
return {'bins_list': bins_list, 'bad_by_bin': bad_by_bin, 'not_monotone_count': not_monotone_count,
'balance': balance}
N = df.shape[0]
[badrate_bin, bad_by_bin] = BinBadRate(df, col, target)
bins = list(bad_by_bin[col])
bins_list = [[i] for i in bins]
badRate = sorted(badrate_bin.items(), key=lambda x: x[0])
badRate = [i[1] for i in badRate]
not_monotone_count, not_monotone_position = FeatureMonotone(badRate)['count_of_nonmonotone'], FeatureMonotone(badRate)['index_of_nonmonotone']
#迭代地寻找最优合并方案,终止条件是:当前的坏样本率已经单调,或者当前只有2箱
while (not_monotone_count > 0 and len(bins_list)>2):
#当非单调的箱的个数超过1个时,每一次迭代中都尝试每一个箱的最优合并方案
all_possible_merging = []
for i in not_monotone_position:
merge_adjacent_rows = Merge_adjacent_Rows(i, np.mat(bad_by_bin), bins_list, not_monotone_count)
all_possible_merging.append(merge_adjacent_rows)
balance_list = [i['balance'] for i in all_possible_merging]
not_monotone_count_new = [i['not_monotone_count'] for i in all_possible_merging]
#如果所有的合并方案都不能减轻当前的非单调性,就选择更加均匀的合并方案
if min(not_monotone_count_new) >= not_monotone_count:
best_merging_position = balance_list.index(min(balance_list))
#如果有多个合并方案都能减轻当前的非单调性,也选择更加均匀的合并方案
else:
better_merging_index = [i for i in range(len(not_monotone_count_new)) if not_monotone_count_new[i] < not_monotone_count]
better_balance = [balance_list[i] for i in better_merging_index]
best_balance_index = better_balance.index(min(better_balance))
best_merging_position = better_merging_index[best_balance_index]
bins_list = all_possible_merging[best_merging_position]['bins_list']
bad_by_bin = all_possible_merging[best_merging_position]['bad_by_bin']
not_monotone_count = all_possible_merging[best_merging_position]['not_monotone_count']
not_monotone_position = FeatureMonotone(bad_by_bin[:, 3])['index_of_nonmonotone']
return bins_list
def Prob2Score(prob, basePoint, PDO):
#将概率转化成分数且为正整数
y = np.log(prob/(1-prob))
return (basePoint+PDO/np.log(2)*(-y)).map(lambda x: int(x))
### 计算KS值
def KS(df, score, target):
'''
:param df: 包含目标变量与预测值的数据集
:param score: 得分或者概率
:param target: 目标变量
:return: KS值
'''
total = df.groupby([score])[target].count()
bad = df.groupby([score])[target].sum()
all = pd.DataFrame({'total':total, 'bad':bad})
all['good'] = all['total'] - all['bad']
all[score] = all.index
all = all.sort_values(by=score,ascending=False)
all.index = range(len(all))
all['badCumRate'] = all['bad'].cumsum() / all['bad'].sum()
all['goodCumRate'] = all['good'].cumsum() / all['good'].sum()
KS = all.apply(lambda x: x.badCumRate - x.goodCumRate, axis=1)
return max(KS)