基于linux平台的Hadoop完全分布式集群搭建
前一段因为课设搭建了基于linux的Hadoop集群,现将搭建过程记录如下,如有错误,望不吝指出。
注:下文从自己的课设报告中直接粘贴下来的,可能有些格式问题。
环境搭建
因为此次课程设计需要用到多台主机,所以选择在虚拟机中完成。三台虚拟机系统均选择Ubuntu16.04。虚拟机分配2G内存,100G硬盘,单个网络适配器,网络连接方式选择nat方式。大致情况如下图所示
|
|

图3. 1 每个虚拟机的概况
系统安装使用Vmware Workstation的简易安装完成。为了使界面友好,安装了中文语言。
|
|

图3. 2 安装中文语言
习惯于使用vim来修改文件,所以还安装了vim。
在安装好了一台虚拟机后,可以使用Vmware Workstation的克隆功能来获得其他两台虚拟机,克隆功能可以百度使用方法,在这里不再展开说明。
|
|

图3. 3 克隆向导
至此,我们已经获得了三台虚拟机,为了接下来的需要以及方便区分,我们将三台虚拟机分别取名为master、node1、node2。
|
|

图3. 4 三台虚拟机
虚拟准备完毕,为了阅读的连贯性,其他环境的准备将放在设计过程(步骤)中介绍。
4 过程(步骤)
4.1 安装JDK
由于系统是新安装的,之前并没有安装过JDK,需要先安装JDK。此次课设安装的JDK版本是jdk1.8.0_191。(下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)。
在下载好之后,可以进入下载的文件夹查看:下载后将它复制到了新建的java文件夹便于查找。
|
|

图4. 1 下载的JDK
将下载后的压缩包解压:
|
|

图4. 2 解压JDK
接下来就是配置环境变量了,我们将环境变量配置在/etc/profile中,这样就可以为所有用户配置JDK环境了。
打开/etc/profile文件:
|
|

图4. 3修改profile文件
在文件的末尾加上环境变量的配置:
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
|
|

图4. 4 末尾加上Java环境变量
使用source /etc/profile来是配置生效。
|
|
图4. 5使配置生效
使用java -version来查看环境变量是否生效。
|
|

图4. 6 查看配置是否生效
这里可能会出现一个错误:将当前的终端关闭后,再次开启终端,发现java命令无效。可以参考后面的“个人遇到的困难”部分的5.1.1。
4.2 配置hosts文件
上面的安装JDK应当算在实验环境搭建里,但是考虑到步骤繁琐,所以将它提到实验步骤里来说明。接下来正式开始搭建Hadoop。
由于虚拟机是由同一台虚拟机克隆来的,所以每一台主机的名称也是一样的。为了区分谁是主节点,谁是从节点,所以需要修改主机名。这里很多资料都是说修改/etc/hostname文件来完成主机名的修改,但是在实际操作后发现,重启主机后,打开终端,如果你想要使用sudo命令会导致报错:主机名XXX无法解析。这时可以参考后面的“个人遇到的困难”部分的5.1.2。
将三台主机分别命名为master、node1、node2。
|
|

图4. 7 重命名主机
在改完主机名后,就需要修改hosts文件来实现三台主机之间互相认识了。我们使用ifconfig来查看主机的ip。
|
|

图4. 8 查看主机IP
查到主机ip后,打开/etc/hosts文件,在顶部添加三台虚拟机的主机名和他的ip地址。其他的都不需要动。
|
|

图4. 9修改hosts文件
在三台主机上都修改好后,就可以实现三台主机可以互相ping通了。
|
|

图4. 10 实现三台主机互相ping通
4.3 建立hadoop运行账号
建立hadoop运行账号就是在三台主机上建立统一的组:Hadoop,在组里加入一个用户hduser,在接下来的所有操作都在这个组的这个用户下操作。
首先建立一个用户组hadoop。
|
|

图4. 11 添加用户组hadoop
新建一个用户hduser,并把它添加到hadoop用户组里。
|
|

图4. 12 在Hadoop组里加入用户hduser
给用户hduser设置密码:
|
|

图4. 13 添加密码
输入两次密码后,用户创建完成,之后就是将sudo权限赋予个用户huuser
|
|

图4. 14授权
接下来的所有操作都在用户hduser下操作:
|
|

图4. 15 切换用户
4.4 SSH免密连接
Hadoop在运行时,要想多Java线程运行就需要在多台主机上跑,所以SSH免密连接是必须要有的一步。
首先确定机器上是否安装了ssh服务:
|
|

图4. 16 查看SSH
上图是安装了ssh的状态,如果没装,可以这样将ssh服务安装上:
|
|
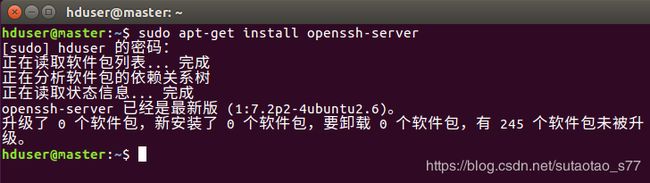
图4. 17 安装SSH
由于撰写课设报告时已经完成了,所以上图中没有更新ssh,没有安装多的话,使用上述命令就可以安装ssh服务了。
安装了ssh后就需要对ssh进行配置了:
首先在master主机上生成一对公钥和密钥:
|
|

图4. 18 生成公钥和密钥
将公钥加入到认证中:
|
|

图4. 19 加入认证
使用ssh localhost就可以登录到自己的主机中了,在从节点也配置好了,就可以连接到其他主机了。可以使用exit退出登录。
|
|

图4. 20 ssh到自己主机
要想主节点能够免密登录到从节点,还需要做如下配置:
将master主机上的id_rsa.pub复制到node1和node2上,并重命名为node1_rsa.pub和node2_rsa.pub。
将密钥加入到认证:
|
|
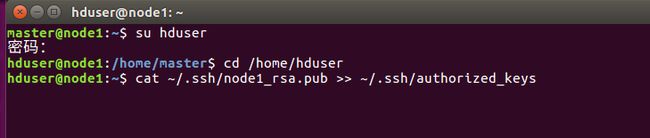
图4. 21 node1加入认证
按照相同的方式,在node2上也把密钥加入认证。这样,在master主机上就能够免密连接到node1和node2了。
|
|
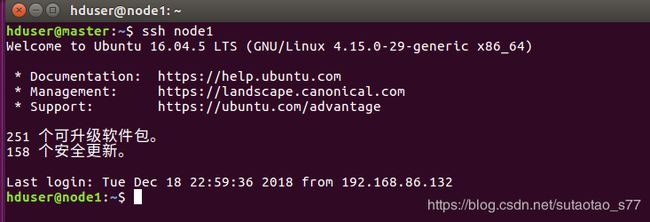
图4. 22master免密连接node1
4.5 安装hadoop
下载hadoop2.6.5,将文件放到/home/hduser目录下。将压缩包解压。如下:
|
|

图4. 23 下载解压Hadoop
4.6 配置hadoop
Hadoop的配置文件都放在hadoop-2.6.5/etc/hadoop目录下,我们要想搭建hadoop集群的话,需要修改如下几个配置文件:
hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、slaves
除此之外我们还需要配置/etc/profile文件来使hadoop生效。接下来逐个修改。注意,在三台虚拟机上都需要做相应修改,可以通过在一台主机上配置好后拷贝到其他主机上。
4.6.1 配置hadoop-env.sh
|
|

图4. 24 修改hadoop-env.sh
打开配置文件后,修改JAVA_HOME路径为之前配置的路径,在开头修改为如下图所示:
|
|

图4. 25 hadoop-env.sh
4.6.2 配置core-site.xml
打开文件:
|
|

图4. 26 打开core-site.xml
打开配置文件后,在末尾修改为下:
|
|

图4. 27 core-site.xml
4.6.3 配置hdfs-site.xml
配置如下:
|
|

图4. 28 hdfs-site.xml
4.6.4 配置mapred-site.xml
|
|

图4. 29 mapred-site.xml
4.6.5 配置slaves
在这里配置你的从节点名称:
|
|

图4. 30 slaves配置
4.6.6 配置/etc/profile
在/etc/profile文件的末尾添加上HADOOP_INSTALL这个环境变量,并把它放入到PATH中。
|
|

图4. 31profile配置
修改后,使它生效
|
|

图4. 32 profile生效
4.6.7 检查配置是否生效
使用hadoop version命令来检查上面的配置是否生效:
|
|

图4. 33 hadoop version
至此完成了所有的hadoop配置。
4.7 格式化namenode并启动集群
|
|

图4. 34 格式化namenode
看到successful就代表格式化namenode成功了。
|
|
图4. 35 格式化成功
启动集群:
|
|

图4. 36 启动集群
使用jps命令来查看master上的服务:
有SecondaryNameNode、 NameNode、ResourceManager、Jps这四个。
|
|

图4. 37查看Hadoop的运行服务
在从节点上使用jps命令,有三个服务:NodeManager、Jps、DataNode
|
|

图4. 38 从节点上的服务进程
还可以在web上使用浏览器来查看和管理集群,http://master:50070
|
|
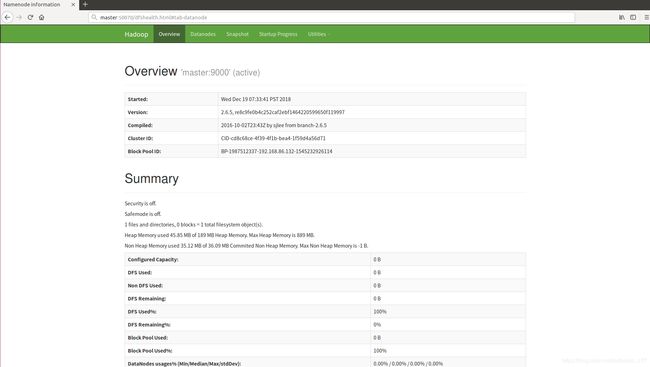
图4. 39 在web上查看集群
也可以查看各个从节点的情况:
|
|

图4. 40 查看从节点状态
启动成功后可以登陆web客户端查看yarn:http://master:8088:
|
|

图4. 41 web 上查看yarn
5个人遇到的困难
5.1 遇到的困难
在整个课程设计中遇到了很多的问题,在这里列出其中遇到的比较典型的问题,并进行总结。同时也是一次记错,以后遇到相似的问题便于参考。
5.1.1 新打开的终端中java -version 命令失效
在给Ubuntu配置JDK后,发现了一个问题,再次打开终端后,输入java -version命令,显式未安装JDK。
经过在网上查阅资料和自己思考,现在总结问题如下:
在安装JDK时,因为权限的原因,是以root用户进行操作的,再次开发终端后,是以普通用户的身份运行。编辑环境变量后,执行source命令,root用户已经配置,但是对普通用户无效。
解决方法:
再次打开终端后,执行 gedit ~/.bashrc,执行 source ~/.bashrc
5.1.2 主机名修改后重启主机导致sudo命令出错
网上的修改主机名的方式在ubuntu16.04TLS上可能会出现问题,在查阅了资料后发现,/etc/hostname文件中存储的确实是主机名,但是仅仅修改这一处是无法达到效果的,还需要将hosts文件也修改为想要的主机名。