第一讲:高性能计算基础知识讲解

回顾过去15年,HPC一直是增长最快的IT市场之一,其增长速度有时甚至超过了在线游戏、平板的年增长率,在云计算、大数据和AI的推动下,HPC的应用类型更加复杂,要求HPC方案必须与时俱进,需要不断匹配新技术来应对应用和业务挑战,这就是笔者推出该专题的背景。
首先,让我们从高性能计算概念开始,逐步深入到技术细节,掌握HPC关键技术和方案选型、设计等综合能力。
什么是高性能计算,涉及哪些技术和知识呢?
高性能计算(High performance computing) 指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境。高性能集群上运行的应用程序一般使用并行算法,把一个大的普通问题根据一定的规则分为许多小的子问题,在集群内的不同节点上进行计算,而这些小问题的处理结果,经过处理可合并为原问题的最终结果。由于这些小问题的计算一般是可以并行完成的,从而可以缩短问题的处理时间。
高性能集群在计算过程中,各节点是协同工作的,它们分别处理大问题的一部分,并在处理中根据需要进行数据交换,各节点的处理结果都是最终结果的一部分。高性能集群的处理能力与集群的规模成正比,是集群内各节点处理能力之和,但这种集群一般没有高可用性。
高性能计算的分类方法很多。这里就拿最传统的分法,从并行任务间的关系角度来对高性能计算分类。
一、高吞吐计算(High-throughput Computing)
有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。因为这种类型应用的一个共同特征是在海量数据上搜索某些特定模式,所以把这类计算称为高吞吐计算。所谓的Internet计算都属于这一类。按照Flynn的分类,高吞吐计算属于SIMDSingle Instruction/Multiple Data,单指令流-多数据流)的范畴。
二、分布计算(Distributed Computing)
另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。按照Flynn的分类,分布式的高性能计算属于MIMD (Multiple Instruction/ Multiple Data,多指令流/ 多数据流)的范畴。
有许多类型的HPC 系统,其范围从标准计算机的大型集群,到高度专用的硬件。大多数基于集群的HPC系统使用高性能网络互连,基本的网络拓扑和组织可以使用一个简单的总线拓扑。HPC系统由计算、存储、网络、集群软件四部分组成。
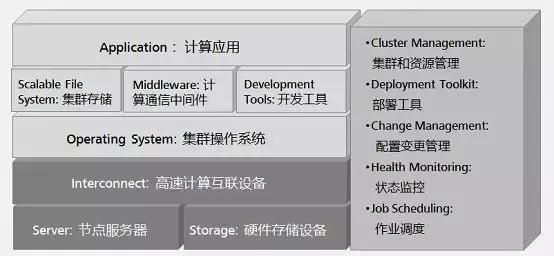
HPC高性能计算具备哪些特性?
在存储通用市场,我们经常听厂商宣传产品NFS性能很高(有些甚至都不支持pFS,NFS v4.1版本),就认为是高性能计算存储产品,事实并非如此。HPC是多并非和带宽要求非常高的计算场景,但除此之外,还需要配合并支持MPI应用集群。个人认为,一个高性能计算存储产品或支持HPC的并行文件系统,必须支持以下特性:
1、首先是pFS(文件系统),不同客户端和连接可以连接到不同存储节点,实现并发访问。
2、支持Posix接口,利用客户端提升性能。
3、支持MPI并行消息接口,对IO访问进行优化。
3、按需可扩展(主要指容量,性能和网络扩展),在方案中往往体现为在线增加存储节点或Building Block。
4、支持IB,OPA(原生RDMA,不是IP over Fabric)网络,降低访问时延。
5、同时支持高带宽(大IO),OPS(小IO)场景, HPC应用随着应用发生变化,不是所有HPC集群应用都是带宽场景,此外,有很多场景都是小IO,OPS场景,如EDA仿真。
HPC高性能计算市场空间有多大?
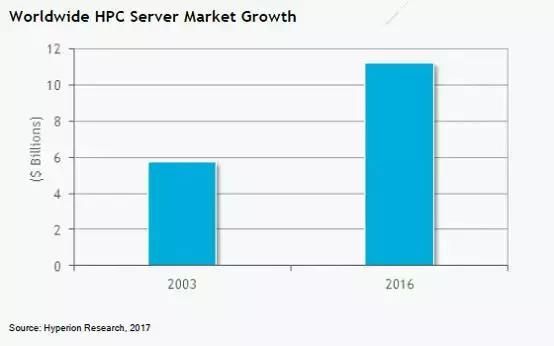
在2016年的全年,我们报告说,HPC服务器市场的全球工厂收入从2015年的107亿美元上升到创纪录的112亿美元,比2003年的57亿美元增长了近两倍。
Intersect360研究将HPC市场定义为应用服务器、集群和Hyperscale 超级计算系统3大类,其中,以任意可伸缩的、面向web的Hyperscale市场增长最快。
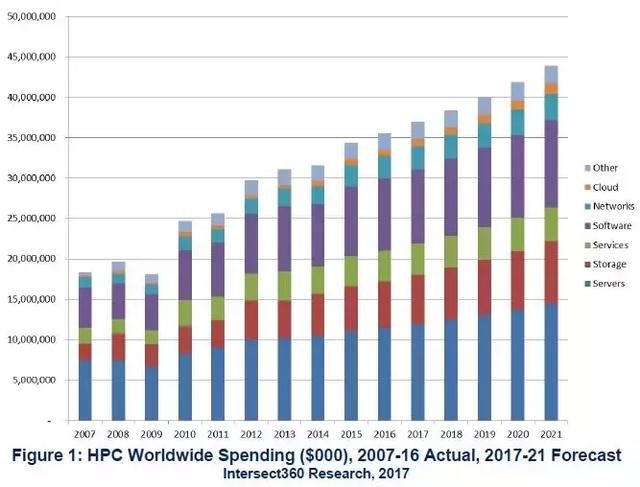
- 1. 2016年全球HPC市场(服务器、存储、软件等)达到356亿美元,较2015年增长3.5%。
- 2. 2016年至2021年,总市场预计2021年将增长到439亿美元,复合年增长率CAGR为4.3%。
- 3. 服务器是最大的组成部分,达到了106亿美元(比2014年增长4.0%),增长率继续下降 (存储、网络和软件将增加)。
- 4. 商业HPC市场推动了经济增长;在接下来的五年里,这种情况还在继续。
- 5. 政府占整个市场的26%。美国政府市场大约占全球的一半。
Intersect360对HPC预算分配研究调查表明: 硬件、软件、设备、人员、服务、云/工具/外购计算等七大项中,最大的预算支出项是硬件,2016年,服务器、存储和网络占所有预算的64% (不包括设施和人员)。
- 1. 第一大预算开支是硬件,HPC硬件(务器、存储和网络)预算从2014年的45%增加到2015年的48%。2016年硬件和服务占所有预算的64% (包括设施和人员,硬件占51%)。
- 2. 第二大的费用人员、员工身上,占HPC预算的20%,主要组成部分包括系统管理、运维和操作等类别。
- 3. 软件是第三大预算费用,在HPC预算中占12%,主要包括软件和对应的工具。
- 4. 实际上,云、工具和外购件在整体HPC支出中,占比仍然是非常小的一部分,每年都有波动,但没有显著的上升或下降变动,约占3%的市场份额。
研究预测,HPC服务器市场将在2021年增长到148亿美元,而整个HPC生态系统的市场在那一年将会超过300亿美元的市场。
高性能计算HPC系统技术特点是什么?
HPC系统目前主流处理器是X86处理器,操作系统是linux 系统(包括Intel、AMD、NEC、Power、PowerPC、Sparc等)、构建方式采用刀片系统,互联网络使用IB和10GE。
高性能计算HPC集群中计算节点一般 分3种: MPI节点、胖节点、GPU加速节点。双路节点称为瘦节点(MPI节点),双路以上称为胖节点;胖节点配置大容量内存;集群中胖节点的数量要根据实际应用需求而定。
GPU英文全称Graphic Processing Unit,中文翻译为图形处理器。 在浮点运算、并行计算等部分计算方面,GPU可以提供数十倍乃至于上百倍于CPU的性能。目前GPU厂家只有三家NVIDIA GPU、AMD GPU和Intel Xeon PHI。可选择的GPU种类比较少。
1、NVIDIA 的GPU卡分图形卡和计算卡,图形卡有NVIDA K2000与K4000,计算卡K20X/K40M/K80 。
2、Intel 的GPU是Intel Xeon Phi 系列,属于计算卡,主要产品有Phi 5110P 、Phi 3210P、Phi 7120P、Phi 31S1P。
3、AMD 的GPU是图形和计算合一,主要产品有W5000、W9100、S7000、S9000、S10000。
高性能计算的性能指标怎样衡量?
CPU的性能计算公式: 单节点性能=处理器主频*核数*单节点CPU数量*单周期指令数。单周期指令数=8(E5-2600/E5-2600 v2/E7-4800 v2)或16(E5-2600 v3);节点数量=峰值浮点性能需求/单节点性能。
时延(响应时间)
内存和磁盘访问延时是计算的另一个性能衡量指标,在HPC系统中,一般时延要求如下:

容量计量单位
是一种容量计量单位,通常在标示内存等具有一般容量的储存媒介之储存容量时使用。一般指磁盘空间、文档大小时使用。

速率单位
指在一个数据传送系统中,单位时间内通过设备比特、字符、块等的平均量。一般在描述传输速率或带宽时使用。如果是比特/秒,就用bit/s (kbit/s, Mbit/s) ,如果是字节/秒,就用B/s (kB/s、 MB/s、 KB/s), 小写的k代表1000, 大写的K代表1024。
计算单位和峰值
每秒浮点运算次数(亦称每秒峰值速度)是每秒所执行的浮点运算次数(Floating point Operations Per Second)的简称,被用来估算电脑效能,尤其是在使用到大量浮点运算的科学计算领域中。

HPC高性能计算网络
交换:完成信号由设备入口到出口的转发。只要是和符合该定义的所有设备都可被称为交换设备。
二层交换机工作在数据链路层。二层交换机就是普通的交换,把数据以帧的形式发送出去。三层交换机工作在网络层。三层交换机既可以作交换机又可以做路由器。
路由:是把信息从源穿过网络传递到目的地的行为,在路上,至少遇到一个中间节点。它们的主要区别在于桥接发生在OSI参考协议的第二层(链接层),而路由发生在第三层(网络层)。这一区别使二者在传递信息的过程中使用不同的信息,从而以不同的方式来完成其任务。
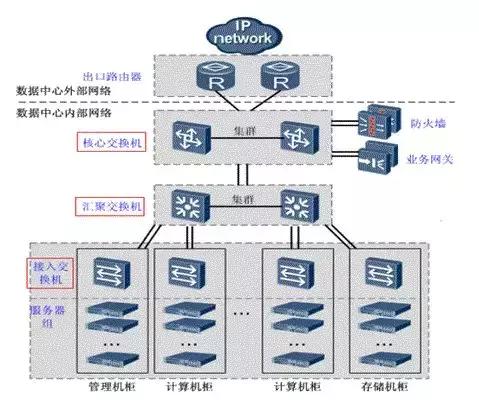
- 接入交换机:一般用于直接连接电脑。通常将网络中直接面向用户连接或访问网络的部分称为接入层。负责连接机柜内部的服务器。
- 汇聚交换机:汇聚相当于一个局部或重要的中转站,将位于接入层和核心层之间的部分称为分布层或汇聚层。完成接入层交换机流量的汇聚,并与核心层交换机连接。
- 核心交换机:相当于一个出口或总汇总。完成数据报文的高速转发,并提供对外的网络接口。
堆叠和级联
级联和堆叠是多台交换机或集线器连接在一起的两种方式。它们的主要目的是增加端口密度,主要区别:
级联是上下关系(总线型、树型或星型的级联),堆叠是平等关系(堆叠中多台交换机作为一个整体对外体现为一台逻辑设备)。
- 级联可以连接不同类型或厂家的交换机,而堆叠只有在同系列的交换机之间。
- 交换机间的级联在理论上没有级联数的限制。叠堆有最大限制,堆叠中多台交换机作为一个整体对外体现为一台逻辑设备。
堆叠组建时会选举出一台交换机做为主交换机(Master),剩下的交换机称为从交换机(Slave)。主交换机是整个堆叠系统中的控制中心。堆叠中每一台交换机都同时具备成为主交换机或者从交换机的能力。
测试工具—Linpack HPC是什么?
Linpack HPC 是性能测试工具。LINPACK是线性系统软件包(Linear system package) 的缩写, 主要开始于 1974 年 4 月, 美国Argonne 国家实验室应用数学所主任 Jim Pool, 在一系列非正式的讨论会中评估,建立一套专门解线性系统问题之数学软件的可能性。
业界还有其他多种测试基准,有的是基于实际的应用种类如TPC-C,有的是测试系统的某一部分的性能,如测试硬盘吞吐能力的IOmeter,测试内存带宽的stream。
至目前为止, Linpack 还是广泛地应用于解各种数学和工程问题。也由于它高效率的运算, 使得其它几种数学软件例如IMSL、MatLab纷纷加以引用来处理矩阵问题,所以足见其在科学计算上有举足轻重的地位。
Linpack现在在国际上已经成为最流行的用于测试高性能计算机系统浮点性能的Benchmark。通过利用高性能计算机,用高斯消元法求解N元一次稠密线性代数方程组的测试,评价高性能计算机的浮点性能。
双列直插式内存(DIMM)有几种类型?
双列直插式内存(DIMM)包括UDIMM内存、RDIMM内存和LRDIMM内存三种DIMM内存可用类型。
- 在处理较大型工作负载时,无缓冲DIMM( UDIMM )速度快、廉价但不稳定。
- 寄存器式DIMM( RDIMM )内存稳定、扩展性好、昂贵,而且对内存控制器的电气压力小。它们同样在许多传统服务器上使用。
- 降载 DIMM( LRDIMM )内存是寄存器式内存( RDIMM )的替代品,它们能提供高内存速度,降低服务器内存总线的负载,而且功耗更低。LRDIMM内存成本比 RDIMM内存高非常多,但在高性能计算架构中十分常见。
非易失双列直插式内存NVDIMM是什么?
NVDIMM由BBU(Battery Backed Up) DIMM演变而来。BBU采用后备电池以维持普通挥发性内存中的内容几小时之久。但是,电池含有重金属,废弃处置和对环境的污染,不符合绿色能源的要求。由超级电容作为动力源的NVDIMM应运而生。并且NVDIMM使用非挥发性的Flash存储介质来保存数据,数据能够保存的时间更长。
主流高性能计算网络类型有哪些?
InfiniBand架构是一种支持多并发链接的“转换线缆”技术,InfiniBand技术不是用于一般网络连接的,它的主要设计目的是针对服务器端的连接问题的。因此,InfiniBand技术将会被应用于服务器与服务器(比如复制,分布式工作等),服务器和存储设备(比如SAN和直接存储附件)以及服务器和网络之间(比如LAN,WANs和互联网)的通信。高性能计算HPC系统为什么要使用IB互联?主要原因是IB协议栈简单,处理效率高,管理简单,对RDMA支持好,功耗低,时延低。
目前只有Mexllaon、Intel、Qlogic提供IB产品,Mexllaon是主要玩家,处于主导地位, IB目前支持FDR和QDR、EDR。
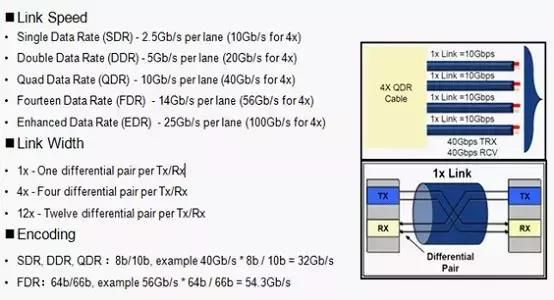
Host Channel Adapters (HCA)是IB连接的设备终结点,提供传输功能和Verb接口;Target Channel Adapters (TCA)是HCA的子集,基本上用于存储。
RDMA(Remote Direct Memory Access)技术全称远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把数据直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,实现Zero Copy。
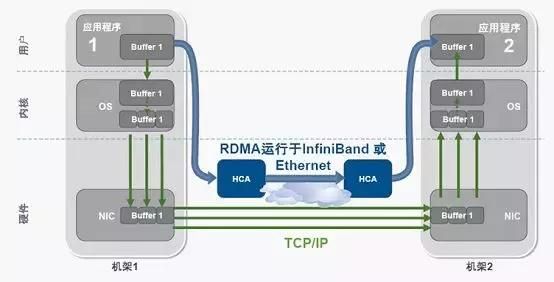
高性能计算的灵魂—并行文件系统
TOP500 HPC系统中存储主要使用分布式文件系统,分布式文件系统(Distributed File System)可以有效解决数据的存储和管理难题: 将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。
分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。当前主流的分布式文件系统包括: Lustre、GPFS、BeeGFS、Hadoop、MogileFS、FreeNAS、FastDFS、NFS、OpenAFS、MooseFS、pNFS、以及GoogleFS等。 Lustre、GPFS、BeeGFS分布式并行文件系统将在后续章节详细讲解,文件系统分析,在此跳过。
文件系统从来都没成为IT领域中最闪光的那部分,这或许可以解释在大型变革和新进入该领域的人,为什么没有注意到它。但在HPC领域,情况可能有所不同(在本专栏中,将分多个章节分析主流HPC并行文件系统)。
HPC供应商主要基于GPFS或Lustre的产品提供HPC解决方案,而且企业和HPC组织已经接受了这些产品。然而,近年来IT环境的变化已经说服一些公司和供应商重新考虑文件系统。诸如大规模分析和机器学习的兴起,HPC向主流企业应用的扩张以及云存储的发展等都给文件服务器带来了新的挑战,使得这些文件服务器变得日益复杂和难以管理。
并行文件系统的业务环境变化也更加关注GPFS和Lustre。特别是英特尔在2017年4月停止了销售Lustre企业版本的维护和发行,这样一个备受瞩目的Lustre支持者的决定引发了大众对Lustre未来的质疑。
与此同时,又有一个平行文件系统BeeGFS兴起,其目标就是HPC领域。2005年,德国Fraunhofer高性能计算中心在该机构的一个计算机集群内部开始实施,该技术开始迅速攀升,2007年第一个测试版发布,一年后正式版首次发布。并在2009年商业化。在2014年,Fraunhofer拆出一家新公司ThinkParQ,以扩大其在HPC商业市场的覆盖面。最初被称为FhGFS的文件系统被命名为BeeGFS。
ThinkParQ的目标是为各种规模的组织提供开放源代码和免费软件Bee GFS,并提供从支持、咨询到系统集成商的合作伙伴关系等服务,开发包括BeeGFS在内的解决方案。并行文件系统软件的大部分开发仍在Fraunhofer中进行开发。
在2017年,ThinkParQ和BeeGFS开发人员在多个领域取得了进展,包括与集群管理软件制造商Bright Computing,HPC解决方案提供商Penguin Computing以及硬件制造商Ace Computers和QuantaCloud Computing等公司扩大合作关系,扩展到欧洲以外的俄罗斯和日本等地区,并在SC17超级计算展会上发布的BeeGFS v7.0版本,包括新的存储池设计,SSD和HDD混合磁盘支持,数据存放策略控制。
在日本,富士通宣布其即将推出的人工智能桥接云基础架构(ABCI)超级计算机将使用BeeGFS onDemand(BeeOND)实现加速,类似于HewlettPackard Enterprise上线的Tsubame3.0系统。据ThinkParQ称,该系统在计算节点采用1PB NVMe高速缓冲BeeOND,可实现1TB/s性能。
根据ThinkParQ首席执行官和BeeGFS首席执行官Sven Bruener的介绍,该公司对BeeGFS的兴趣有所增加,其中主要原因是BeeGFS对市场需求满足以及对Lustre及其未来发展的担忧。BeeGFS帮助公司在一个市场中获得竞争力,而这些市场竞争来源于提供经过市场考验的并行文件系统产品的知名供应商。
Intel放弃其Lustre商业化努力的决定导致合作伙伴将BeeGFS用于Lustre替代计划,因为与Lustre不同,BeeGFS起源于HPC世界。当大家使用BeeGFS时,他们得到的东西并非依靠Intel针对大量功能进行了优化,而主要是针对性能,这对许多用户而言非常重要。
由于性能问题和底层体系结构,各种组织倾向于使用BeeGFS替代GPFS和Lustre系统的,他们注意到从一开始,他们的文件系统表现相当好,但过了一段时间其表现就不再那么好了。BeeGFS更易于使用并且需要更少的维护。大多数用户实际上是从Lustre和GPFS等其他系统切换出来的,因为他们遇到了各方面的问题,然后他们开始尝试其他系统,然而在尝试的过程中,他们对BeeGFS开箱即用设置的容易程度和性能感到惊讶。
根据ThinkParQ全球销售咨询总监的说法,可扩展性也是BeeGFS一个差异化因素,BeeGFS的灵活性很好,以至于真的可以从两台服务器开始即时添加组件扩展。它可以与Panasas的PanFS文件系统进行比较,就连IBM这样的供应商也认可BeeGFS的市场表现。
IBM认为他们可以通过添加BeeGFS来销售更多的服务器硬件和存储控制器,因为GPFS相对来说非常复杂并且可能更昂贵。对于解决方案来,BeeGFS在各种环境下的体现出很好的灵活性。通过BeeGFS,可以使用较少的组件构建小规模系统,但如果系统需要增长,则只需按容量或性能要求添加组件即可(BeeGFS可以扩展到ExaByte规模),没有技术限制。
虽然BeeGFS用户主要集中在欧洲,但ThinkParQ在其他地区如俄罗斯、美国和日本也在迅速增长,像Oak Ridge这样的国家实验室大约有二十个多个。ThinkParQ拥有部署容量约在10PB范围的客户也遍布多个行业,包括生物信息学领域,维也纳大学等,拥有数千个部署节点。
当BeeGFS出现时,其他大型厂商正在支持其他老牌文件系统(如Lustre、GPFS、StorNext等),一些开发自己的文件系统的公司正在努力增长,实际上,BeeGFS可以满足不断变化的市场需求。
纵观历史,GPFS将在25年前就已经出现,并更关注于数据管理。而Lustre在17年前作为一个试验性项目开发出来。15年前,固态硬盘尚不存在,他们也不知道未来的存储环境会有什么样的需求。如今,BeeGFS开发人员了解了这些限制,他们也看到了市场的动向和市场的需求,他们的客户确实需要独立于硬件的软件解决方案,从而充分利用组件的全部优势,通过易用性简化运维管理,无需专业人员。
BeeGFS系统背后的魔力在于它坐落在本地文件系统之上的Linux系统的用户空间中,这使得它非常非常灵活,因为通常如果您要设置HPC环境,需要一个专用的元数据服务器、存储服务器组件。然而BeeGFS具有很好的灵活性,可以将BeeGFS组件安装连接到存储节点,也可以设置文件系统实例。HPC非常流行的BurstBuffer技术,在BeeGFS称之为BeeGFS on Demand,它有效缓解现有HPC环境中令人讨厌的浪涌IO模式,通过闪存介质保障系统在任何时候的性能要求。
实际上,Bright Computing已经与BeeGFS合作了几年了,努力如何简单在Bright集群之上部署这个BeeGFS,并在健康检查BeeGFS和监测BeeGFS方面做出更多努力。实际上,Bright是可以集成GPFS和Lustre并行文件系统使用,在Bright Computing看来,他们对GPFS,Lustre和BeeGFS都有丰富经验,但发现BeeGFS是最轻量的,即使没有与BeeGFS集成,也不像Lustre和GPFS那么难以安装部署。
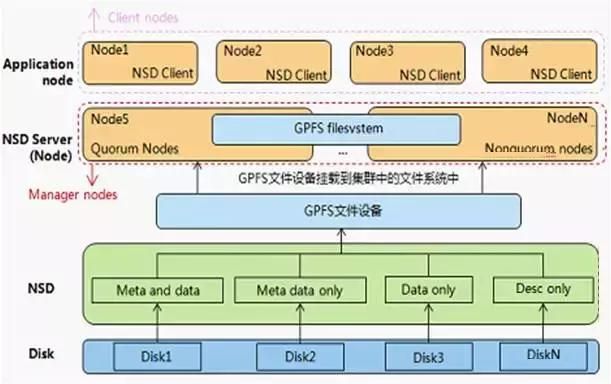
GPFS(General Parallel FileSystem)是一个分布式、共享、并行集群文件系统,支持从多个节点同时对单一文件系统或一组文件系统的访问。GPFS可以在AIX、Linux和windows操作系统和IBM Power、Intel/AMD x86架构下使用,被全世界HPC用户广泛使用。GPFS集群中每一个节点都由管理命令集、GPFS内核扩展、多线程守护进程三个组件构成。
GPFS管理命令集,是用来控制GPFS操作和配置的脚本集合,默认情况下GPFS命令可以在集群中任何一个节点执行,GPFS集群会自动处理并把请求的操作重定向到合适的节点执行。可以定义为在所有GPFS节点同步,还是在一个子网内的节点间同步请求。
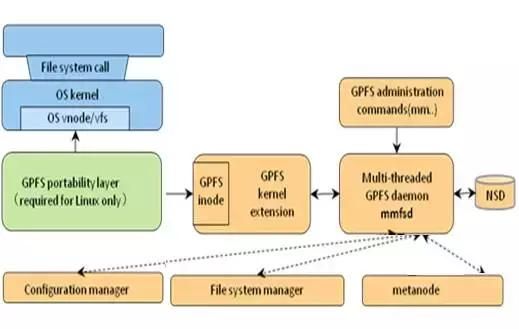
GPFS内核扩展提供了一个接口和操作系统的vNode、VFS层交互模块,并注册GPFS作为一个Native文件系统,GPFS在操作系统中以一个标准的处理应用下发给操作系统的请求。
GPFS守护进程处理所有I/O操作和Buffer管理,包括对于顺序读进行Read-ahead,对于非同步的所有写进行Write-behind操作,I/O操作被GPFS的Token管理保护,以确认数据分布在集群中所有节点的一致性。GPFS守护进程会和其他节点的守护进程共同工作,进行文件系统的配置变更、修复、并行更新元数据状态。
GPFS NSD组件对运行在节点上的应用,提供一种在集群中相对于直接访问普通硬盘的集群访问,集群中NSD可能会物理的连接到所有的节点或者服务器上,数据通过NSD server对外提供一个虚拟连接,最多可以为每个NSD指定8个NSD Server,如果其中一个服务器宕机了,列表中的下一个服务器将会接管宕机的节点工作。
当启动GPFS和一个文件系统挂载的时候,GPFS通过守护进程确认哪些NSD可以通过物理或者虚拟的方式访问,即NSD的发现过程,NSD的默认发现顺序是优先本地的块设备接口,例如SAN、SCSI和IDE,其次是NSD Server。
对GPFS文件系统集群中的组件和其关系进行总结。Node在GPFS文件系统中独立的OS实例,NSD则是对GPFS集群可见用于创建文件系统的存储设备,NSD server提供对特定NSD访问的I/O服务器,通过一组NSD创建的文件系统称为GPFS文件系统。运行应用程序并通过挂载文件系统访问文件系统节点称为Application Node。
GPFS支持配置一些节点直接连接到磁盘上而其他的一些节点通过这些节点访问磁盘,这种配置组网通常在一些较大的HPC集群中使用,提供一种低成本高性能的组网方式。当GPFS节点为其他节点提供访问磁盘的服务时,这个节点称之为NSD Server,GPFS节点通过NSD Server访问数据时称之为GPFS客户端。服务器通常都会复用,以来降低成本,服务器的许可可以作为客户端使用,但是有客户端许可的服务器不能做服务器角色使用。
每个GPFS集群有一个集群管理服务器,从设置为Quorum的节点中选举得来,并且可以通过命令更改,主要负责监视磁盘状态,检测节点故障,执行节点恢复,确定仲裁节点是否满足启动GPFS daemon管理与远程集群的通信,选择文件系统管理节点。
每个文件服务器都会有一个文件系统管理服务器,文件管理服务器通过集群管理进行选择。文件系统管理服务器通常分布在管理服务器中,文件管理服务器不可以跨节点,但是可以在一台服务器上运行多个文件系统的文件管理服务器,文件管理服务器通常有以下功能。
- 文件系统配置(添加磁盘,改变磁盘可达性,修复文件系统,挂载、解挂载文件系统)
- 磁盘空间分配(控制磁盘的那个段的空间分配给哪个节点)
- 令牌管理(令牌管理服务器通过授权令牌协调访问共享磁盘上的文件传达到读或写一个文件的数据或元数据的权利)。
- Quota管理(在启用了配额的文件系统中GPFS文件系统管理节点自动承担配额管理的职责)
- 配置管理(在每个GPFS集群中配置管理服务器通常有主备两台相互协同工作,当主不可用备机接替工作,配置管理服务器通常有Manager Node来充当)
文件系统在执行元数据的写操作时,为了保证数据的一致需要对数据进行加锁,也就会产生锁冲突,为了解决写冲突GPFS引入Meta node,通过Meta node去收集和合并其他节点的元数据的状态更新,维护元数据的完整性。
Meta node节点是在每个文件打开时动态选择的,在每个文件关闭时动态删除,一个文件的读写可以由所有节点操作,一个文件的所有元数据操作都通过Meta node执行(主要包括权限和属性),也只可以通过Meta node执行。通常情况下打开文件操作时间持续最长的会被选举为Meta node。
GPFS在系统架构设计十分灵活,丰富的功能延伸出了多种组网方式,而每种组网方式适配不同的应用模式,常见组网方式包括SAN、NSD、SNC、Remote Cluster和混合组网方式(该内容将在后续章节详解介绍)。
GPFS文件系统解决方案的BuildingBlock如何设计呢?如上文所述GPFS的架构、组网相比Lustre和NAS等来说要较为复杂,如何可以简化存储设计以匹配性能和容量需求,如何让GPFS易于规划、交付和调优,如何让GPFS以近线性的方式进行扩容呢?这里基于最佳项目实践讨论下BuildingBlock设计(Building Block即一个最小的可通过模块叠加实现性能和容量线性扩展的服务器和存储组合)。
Building Block类型一般分为性能和容量2大类型,Capacity Building Block以获取最大容量为目的的BuildingBlock,实际使用中可通过Building Blcok的叠加实现容量和性能的近线性增长;Performance Building Block以获取最大性能为目的的BuildingBlock,实际使用中可通过Building Block的叠加实现性能和容量的近线性增长。
Building Block可选配置选项非常灵活,如计算网络组网方式,存储磁盘选项,仲裁节点数和数据副本等等。
计算网络组网方式默认Infiniband组网,适用于带宽要求较高,时延敏感的应用。通过提供了可选的10GE组网,适用于带宽较低,延时不敏感的应用,如每个BuildingBlock的带宽要求高时,需要通过端口绑定汇聚端口带宽。
数据存储磁盘选项包括磁盘类型、磁盘框类型(2.5寸2U硬盘框、3.5寸4U高密框)等,可靠性选项需要考虑数据份数(默认值元数据2份),仲裁节点数、磁盘仲裁。仲裁节点数默认值6~8台NSD Server采用3个仲裁节点,10台NSD Server时5个仲裁节点,10台NSD Server以上使用7个仲裁节。磁盘仲裁默认值2~4台NSD Server时,用3个仲裁盘。
Building Block扩展性设计主要考虑2种典型场景,即初次新建交付Building Block和已存在GPFS通过Building Block扩容。
在初次新建交付多个Building Block场景下,由于GPFS实行宽条带策略,性能存在木桶效应,所以建议每个Building Block配置一致。同时在交付多个Building Block时考虑后续的扩容,即扩容以之前交付的Building Block作为一个扩展模块,保持配置均衡。
在已存在GPFS通过Building Block扩容场景下,当对现有GPFS文件系统进行扩容时,推荐使用GPFS集群中已有的BuildingBlock模式进行配置,保持GPFS文件系统的配置均衡。当对现有GPFS文件系统进行扩容时,需要将新增Building Block的节点在线加入到集群中,新增BuildingBlock中的LUN在线添加为新的NSD,在线添加过程不会中断现有业务。