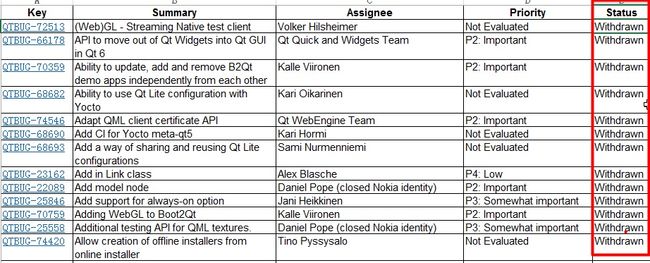
案例故事:有一天测试经理发给我一个Bug列表,
这些Bug都是被开发打回来的无效(WithDrawn)Bug,
就是开发不认为是bug, 测试经理觉得很有必要去分析下,
为什么这么多无效bug,到底是什么原因?
测试经理想知道,是测试提Bug太随意,还是无此需求,还是开发bug流转流程不对,还是其他的什么原因?
肯定是需要看具体Bug的备注,及流转记录的,所以肯定需要批量在浏览器端打开Bug详情网页一个个去看,
那如何批量地在浏览器端打开Bug呢?
准备阶段
- Python的webbrowser 模块,可以轻松地实现打开网页url
- openpyxl是首选的excel解析模块。
Python批处理脚本形式
记住批处理脚本的精髓:批量顺序执行语句
# coding=utf-8
import os
import webbrowser
import openpyxl
# 定义本模块(文件)内的常用变量
excel_file = "Witdrawn_Buglist.xlsx" # excel名称
bugid_col = 1 # Bug ID 列序号
url_prefix = "https://bugreports.qt.io/browse/" # jira url 前缀
# 获取BugID并在浏览器端打开
excel = openpyxl.load_workbook(excel_file) # 读取excel里边的内容
sheet = excel.active
rows = sheet.max_row
for r in range(2, rows + 1): # excel第一行是标题,需要过滤掉
bug_id = sheet.cell(row=r, column=bugid_col).value
webbrowser.open_new_tab("%s%s" % (url_prefix, bug_id)) # 在新窗口打开Jira Bug
os.system("pause")
Python面向过程函数形式
面向过程函数的编程思维应该是这样的:
你需要多少个功能(函数),才能做成这个事。
最好把功能(函数)都尽量封装好,只暴露一些的参数接口即可。
本次代码优化:
考虑到本次bug较多,188条,如果一次性在浏览器端打开,则会导致浏览器崩溃,
或者不容易查看, 所以需要考虑在Python程序执行中,每次只打开10条bug,
然后暂停,再然后按下任意键可继续显示另外的10条bug。
# coding=utf-8
import os
import webbrowser
import openpyxl
def open_url(url):
'''打开指定的url'''
webbrowser.open_new_tab(url)
def get_bug_id(excel_file, col_num):
bug_id_list = []
excel = openpyxl.load_workbook(excel_file) # 读取excel里边的内容
sheet = excel.active
rows = sheet.max_row
for r in range(2, rows + 1): # excel第一行是标题,需要过滤掉
bug_id = sheet.cell(row=r, column=col_num).value
bug_id_list.append(bug_id)
return bug_id_list
count = 0
bug_id_list = get_bug_id("Witdrawn_Buglist.xlsx", 1)
for i in bug_id_list:
open_url("https://bugreports.qt.io/browse/%s" % i)
# 如果能整除10,则暂停一次
count = count + 1
if count % 10 == 0:
os.system("pause")
os.system("pause") # 用于防止脚本运行后直接关闭导致看不到任何执行结果
Python面向对象类形式
面向对象类的编程思维应该是这样的:
如果给你一个空白的世界,在这个世界里你需要哪些种类的事物,
这些种类的事物都具备哪些共有的属性与方法,
这些种类(类)的事物(对象),和其他种类(其他类)的事物(其他对象)有什么关系。
尽量把这些类封装好,只暴露对外的属性(变量)和方法(函数)即可。
# coding=utf-8
import os
import webbrowser
import openpyxl
def open_url(url):
'''打开指定的url'''
webbrowser.open_new_tab(url)
class ExcelParser(object):
'''解析Excel,但是只定义一个函数获取bugID的即可'''
def __init__(self, excel_file):
self.__excel = openpyxl.load_workbook(excel_file) # 读取excel里边的内容, 无需被引用。
def get_bug_id(self, col_num):
bug_id_list = []
sheet = self.__excel.active
rows = sheet.max_row
for r in range(2, rows + 1): # excel第一行是标题,需要过滤掉
bug_id = sheet.cell(row=r, column=col_num).value
bug_id_list.append(bug_id)
return bug_id_list
if __name__ == '__main__':
count = 0
e_obj = ExcelParser("Witdrawn_Buglist.xlsx")
bug_id_list = e_obj.get_bug_id(1)
for i in bug_id_list:
open_url("https://bugreports.qt.io/browse/%s" % i)
# 如果能整除10,则暂停一次
count = count + 1
if count % 10 == 0:
os.system("pause")
os.system("pause") # 用于防止脚本运行后直接关闭导致看不到任何执行结果
运行方式
以上代码的3种实现形式都可以直接运行,比如保存为open_jira_bugs.py并放在桌面,
建议open_jira_bugs.py运行,当然也可以双击运行。
本案例练手素材下载
跳转到官网下载本练手素材
武散人出品,请放心下载!
小提示:WithDrawn 的意思其实和Invalid, Rejected是类似的,表示被开发怼回来的,开发拒绝,不接受这类bug的意思,每个公司的Jira系统所设置的Bug状态稍有不同。
更多更好的原创文章,请访问官方网站:www.zipython.com
自拍教程(自动化测试Python教程,武散人编著)
原文链接:https://www.zipython.com/#/detail?id=071a1e459b6f4174b2b03cf3820e28a2
也可关注“武散人”微信订阅号,随时接受文章推送。