hadoop集群运行MR程序、mahout程序
hadoop集群运行MR程序
- 1. 启动集群
- 2. 上传程序资源到hdfs
- 3. 修改程序文件路径
- 4. 安装mahout
- 5. 提交程序到集群
本教程在配置完hadoop,可以正常运行的前提下进行
1. 启动集群
# 启动hdfs
sbin/start-dfs.sh
# 启动yarn
sbin/start-yarn.sh
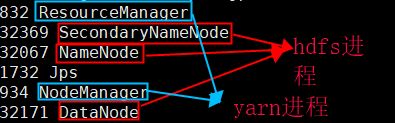
使用jps命令,看到如下图所示,启动成功。
2. 上传程序资源到hdfs
- 第一步:把文件上传到服务器。
- 第二步:把文件上传到hdfs集群。
bin/hadoop dfs -put ../train_data /
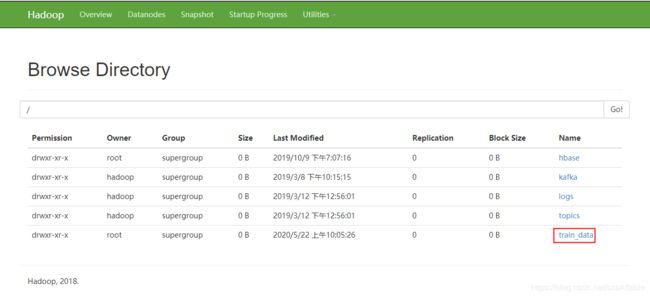
看到如下图所示,上传成功。
3. 修改程序文件路径
把程序读取文件的路径,修改为从参数中获取,本程序需要修改为如下代码:
package com.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.*;
/**
* @author affable
* @description 处理数据
* @date 2020/5/13 10:30
*/
public class DataAnalysis {
/**
* 解析文件,取出userId
*/
static class ParseTxtMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 切分获取每个字段值
String[] fields = value.toString().split(",");
// k -> userId
// v -> workId,action
k.set(fields[0]);
v.set(fields[1] + "," + fields[2]);
context.write(k, v);
}
}
/**
* 按每个userId进行reducer
*/
static class ScoreReducer extends Reducer<Text, Text, Text, Text> {
// 此userId对于所有浏览职位的action
Map<String, Integer> workActions = new HashMap<>();
// 此userId对于所有已投递职位的action
Map<String, Integer> deliveryWorks = new HashMap<>();
// 最大值
double maxWorkAction = 0.0D;
double maxDeliveryWorkAction = 0.0D;
// 这次的userId
String userId;
Text k = new Text();
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
userId = key.toString();
for (Text value : values) {
String[] fields = value.toString().split(",");
if ("2".equals(fields[1])) {
// 如果投递了该职位
// 如果map中没有,则放入1,如果有,则在此基础加1
deliveryWorks.merge(fields[0], 1, Integer::sum);
Integer count = deliveryWorks.get(fields[0]);
maxDeliveryWorkAction = count > maxDeliveryWorkAction ? count : maxDeliveryWorkAction;
} else {
// 只是浏览了职位
workActions.merge(fields[0], 1, Integer::sum);
Integer count = workActions.get(fields[0]);
maxWorkAction = count > maxWorkAction ? count : maxWorkAction;
}
}
// 从浏览职位中去除已投递的
deliveryWorks.forEach((k, v) -> workActions.remove(k));
// 计算分数
// 规则:
// 浏览量/最大浏览量*4 (0, 4]
// 投递量/最大投递量+4 (4, 5]
for (Map.Entry<String, Integer> entry : workActions.entrySet()) {
String workId = entry.getKey();
Integer count = entry.getValue();
k.set(userId + "\t" + workId);
v.set(String.format("%.2f", count / maxWorkAction * 4));
context.write(k, v);
}
for (Map.Entry<String, Integer> entry : deliveryWorks.entrySet()) {
String workId = entry.getKey();
Integer count = entry.getValue();
k.set(userId + "\t" + workId);
v.set(String.format("%.2f", 4.0 + count / maxDeliveryWorkAction));
context.write(k, v);
}
// 清空数据
workActions.clear();
deliveryWorks.clear();
maxWorkAction = 0.0D;
maxDeliveryWorkAction = 0.0D;
}
}
public static void main(String[] args) throws Exception {
String inputPath = args[0];
String outputPath = args[1];
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "cal_user_score");
job.setJarByClass(DataAnalysis.class);
job.setMapperClass(ParseTxtMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setNumReduceTasks(1);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
package com.demo;
import org.apache.commons.csv.CSVParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.FastByIDMap;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.GenericDataModel;
import org.apache.mahout.cf.taste.impl.model.GenericPreference;
import org.apache.mahout.cf.taste.impl.model.GenericUserPreferenceArray;
import org.apache.mahout.cf.taste.impl.model.MemoryIDMigrator;
import org.apache.mahout.cf.taste.impl.recommender.svd.ALSWRFactorizer;
import org.apache.mahout.cf.taste.impl.recommender.svd.SVDRecommender;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.Preference;
import org.apache.mahout.cf.taste.model.PreferenceArray;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author affable
* @description 职位推荐
* @date 2020/5/11 10:02
*/
public class WorkRecommend {
private static final int SIZE = 20;
/**
* 获取文件系统
*/
private static FileSystem getFiledSystem() throws IOException {
Configuration configuration = new Configuration();
return FileSystem.get(configuration);
}
/**
* 读取hdfs文件
* @param filePath 文件路径
* @return 返回读取文件流
*/
private static BufferedReader readHDFSFile(String filePath) throws FileNotFoundException {
FSDataInputStream fsDataInputStream = null;
BufferedReader reader = null;
try {
Path path = new Path(filePath);
fsDataInputStream = getFiledSystem().open(path);
reader = new BufferedReader(new InputStreamReader(fsDataInputStream));
} catch (IOException e) {
e.printStackTrace();
}
return reader;
}
public static void main(String[] args) throws TasteException, IOException {
// *******************************处理开始******************************************
// 使用推荐模型之前,对数据的userId和workId映射成long类型
// 防止模型把userId和workId转为long,出现数据异常
// 数据存储路径
String dataPath = args[0];
Map<Long,List<Preference>> preferecesOfUsers = new HashMap<>(16);
// 读取原始数据并处理
BufferedReader reader = readHDFSFile(dataPath);
CSVParser parser = new CSVParser(reader, '\t');
String[] line;
MemoryIDMigrator userIdMigrator = new MemoryIDMigrator();
MemoryIDMigrator workIdMigrator = new MemoryIDMigrator();
while((line = parser.getLine()) != null) {
// string 转 long
long userIdLong = userIdMigrator.toLongID(line[0]);
long workIdLong = workIdMigrator.toLongID(line[1]);
userIdMigrator.storeMapping(userIdLong, line[0]);
workIdMigrator.storeMapping(workIdLong, line[1]);
List<Preference> userPrefList;
if((userPrefList = preferecesOfUsers.get(userIdLong)) == null) {
userPrefList = new ArrayList<>();
preferecesOfUsers.put(userIdLong, userPrefList);
}
userPrefList.add(new GenericPreference(userIdLong, workIdLong, Float.parseFloat(line[2])));
}
FastByIDMap<PreferenceArray> preferecesOfUsersFastMap = new FastByIDMap<>();
for(Map.Entry<Long, List<Preference>> entry : preferecesOfUsers.entrySet()) {
preferecesOfUsersFastMap.put(entry.getKey(), new GenericUserPreferenceArray(entry.getValue()));
}
// ***********************************处理完成**************************************
// 读取数据
DataModel dataModel = new GenericDataModel(preferecesOfUsersFastMap);
// 使用als求损失函数
ALSWRFactorizer factorizer = new ALSWRFactorizer(dataModel, 5, 0.2, 200);
// 使用SVD算法进行推荐
Recommender recommender = new SVDRecommender(dataModel, factorizer);
// 推荐测试
LongPrimitiveIterator userIdIterator = dataModel.getUserIDs();
int i = 0;
while (userIdIterator.hasNext()) {
long userIdLong = userIdIterator.nextLong();
String userId = userIdMigrator.toStringID(userIdLong);
List<RecommendedItem> recommendedItems = recommender.recommend(userIdLong, SIZE);
for (RecommendedItem item : recommendedItems) {
// 写出到mysql
// MysqlUtils.insert(userId, workIdMigrator.toStringID(item.getItemID()), item.getValue());
System.out.println(String.format("userId: %s, itemId: %s, score: %.2f",
userId, workIdMigrator.toStringID(item.getItemID()), item.getValue()));
i++;
}
}
System.out.println(i);
// 释放资源
// MysqlUtils.release();
reader.close();
}
}
4. 安装mahout
- 下载安装包。
- 上传到服务器,并解压。
- 修改环境变量,在/etc/profile中做如下修改,并重新加载profile文件。

source /etc/profile
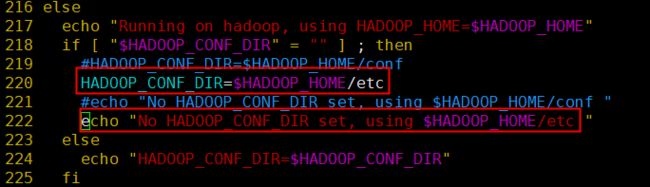
- 修改mahout配置(或者添加HADOOP_CONF_DIR环境变量也可以)
vim bin/mahout
6. 在命令行输入 mahout,测试是否可以正常运行。
5. 提交程序到集群
- 本地使用以下命令对程序打包,并上传到服务器。
最好把后缀为-with-dependencies.jar的包上传到服务器,防止hadoop集群没有对应的依赖包
# maven程序打包
mvn clean package
- 运行数据分析处理程序。
# 最后两个参数为:待处理数据路径,处理后结果的保存路径
bin/hadoop jar ../work-recommend-1.0.0-Release-jar-with-dependencies.jar com.demo.DataAnalysis /train_data/user_action.csv /work_out/user_score
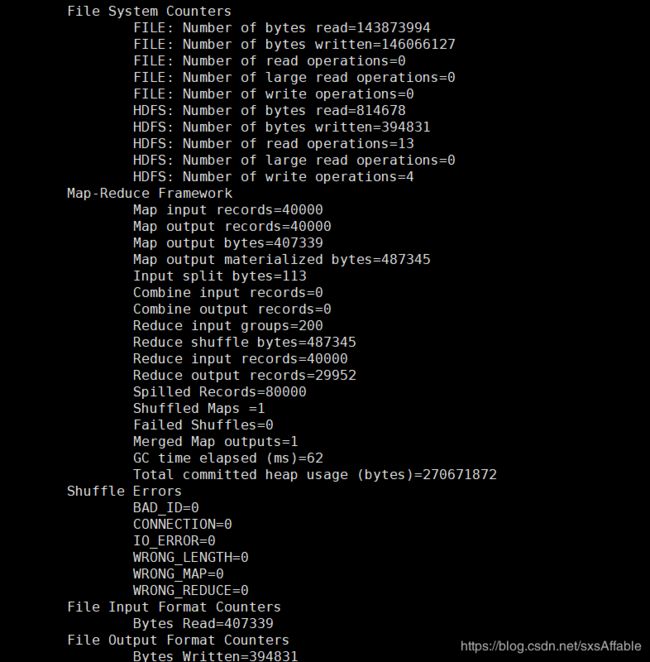
如下图所示,运行成功。
3. 运行预测程序。
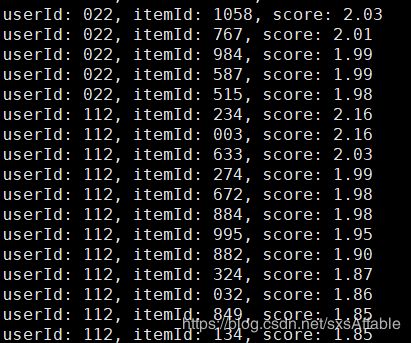
mahout hadoop jar ../work-recommend-1.0.0-Release-jar-with-dependencies.jar com.demo.WorkRecommend hdfs://localhost:9000/work_out/user_score/part-r-00000
执行结果如下