Elasticsearch品读—第四章:DSL语法(第一节)
上一章:Elasticsearch品读—第三章:ES数据类型
目录
1.DSL语法简介
1.1.上下文
1.2.macth_all
2.全文检索
2.1.match
2.2.match_phrase
2.3.match_phrase_prefix
2.4.multi_match
2.5.common terms
3.术语查询
3.1.term
3.2.terms
3.3.range
3.4.exists
3.5.prefix
3.6.wildcard
3.7.regexp
3.8.fuzzy
3.9.type
3.10.ids
1.DSL语法简介
DSL,全称是 Domain Specific Language,域特定语言。ES将Query DSL视为查询AST(抽象语法树),由两种类型子句组成:
①叶查询子句,查找特定字段中的特定值,例如匹配,术语或范围查询;
②复合查询子句,包装其他叶子或复合查询,用于以逻辑方式组合多个查询
1.1.上下文
query子句的行为取决于它是在查询上下文中还是在过滤器上下文中使用:
①查询上下文中使用的查询子句回答了问题"此文档与此查询子句的匹配程度如何?"除了确定文档是否匹配之外,查询子句还计算一个_score,表示文档相对于其他文档的匹配程度。
②过滤器上下文中使用的查询子句回答问题"此文档是否与此查询子句匹配",答案是简单的是或否,不计算任何分数。 过滤器上下文主要用于过滤结构化数据,例如:
1. 文档的时间戳字段是否属于2018年至2019年的范围?
2. 文档的状态字段是否设置为“已发布”?
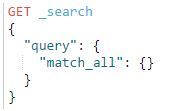
1.2.macth_all
match_all 是最简单的DSL查询语句,用于查询所有的文档,并且查询匹配到的文档的相关度_score默认都为1:
2.全文检索
full text query即全文检索,先建立索引,再对索引进行搜索的过程就叫全文检索
2.1.match
match query,即匹配查询,接受text/numerics/dates查询参数,分析它们并构造查询。匹配查询的类型为boolean,它会分析客户端提供的查询文本,分析过程根据提供的文本构造布尔查询,它的语法为:


额外查询参数:
①operator参数可以设置为其它控制布尔子句(默认为或)
②minimum_should_match参数设置要匹配的可选should子句的最小数量
③analyzer来控制哪个分析仪将对文本执行分析过程。默认为字段显式映射定义或默认搜索分析器
④lenient参数设置为true可以忽略由数据类型不匹配引起的异常,例如尝试使用文本查询字符串查询数字字段默认为false。
例子:

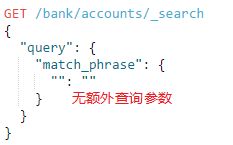
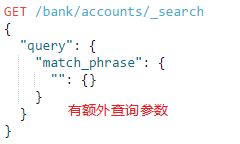
2.2.match_phrase
match phrase query,即匹配短语查询,它其实是在match的基础上将operator改为and的效果,只有文档的字段完全匹配查询文本才会该文档返回。它的语法为:(语法和match很相似)
额外查询参数:
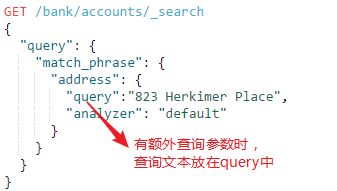
①analyzer:指定分析仪对查询文本进行分析查询
2.3.match_phrase_prefix
match phrase prefix query,即匹配短语前缀查询,它与match_phrase相同,只是它允许文本中最后一个术语的前缀匹配,语法为:

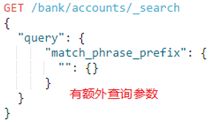
额外查询参数:
①analyzer:设置分析仪对查询文本近分析查询
②max_expansions:设置满足查询前缀的后缀匹配数量,默认是50个。例如有短语"ant"、"area"、"ab"、"ananlyzer",在match_phrase_prefix="a"情况下,设置max_expansions=1,只有ab符合,设置max_expansions=3,ab、ant、area都符合...以此类推,它默认是50个,官方强烈建议要将这个设置成符合业务场景的值,避免无意义的查询

2.4.multi_match
multi match query,即多重匹配查询,在match的基础上允许多个字段查询,multi_match默认带有2个属性:query 和 fields,query设置搜索文档,fields用于指定匹配字段,它的语法为:
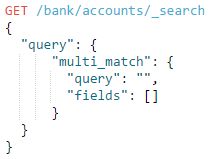
fields可以: ①模糊匹配,如:"fields": ["title", "*_name"]
②重要字段,如:"fields" : [ "subject^3", "message" ] (表示subject字段是message字段的三倍重要)
额外参数:
type:设置multi_match在内部查询的执行方式,它有5个取值:
①best_fields:默认值,它可以查询与任何字段匹配的文档,但使用最佳字段的_score作为返回结果的_score(相关度)
②most_fields:查找与任何字段匹配的文档,并组合每个字段的_score
③cross_fields:使用相同的分析器处理每个字段
④phrase:在每个字段上运行match_phrase查询,并组合每个字段的_score
⑤phrase_prefix:在每个字段上运行match_phrase_prefix查询,并组合每个字段的_score
2.5.common terms
common terms query,即常用术语查询,ES旧版本为了防止像"the"、"a"等高频词影响查询性能和效果,忽略高频率的术语,通过将高频词视为一个停用词,直接将高频词过滤。常用术语查询就是替代停用词的新技术。常用术语查询将查询术语划分为两组:更重要(即低频术语)和不太重要(即以前曾是停用词的高频术语)它的查询步骤为:
①先查询匹配低频术语(重要性大)的文档。这些术语出现在较少的文档中,对相关性有较大影响
②基于第①步查到的结果上,对高频词(不太重要)的术语执行第二次查询,这些术语经常出现并且对相关性的影响很小
语法:

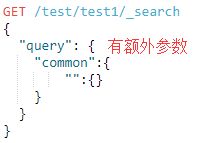
额外属性:
①cutoff_frequency:将术语分配给高频或低频组,cutoff_frequency可以指定为绝对频率(> = 1)或相对频率(0.0 ... 1.0),文档频率是按照每个分片级别计算的
②low_freq_operator:设置低频词的操作符(默认是 or )
③high_freq_operator:设置高频词的操作符(默认是 or )
④minimum_should_match:指定若没有特殊指明,则表示必须存在的低频项的最小数量或百分比:"minimum_should_match":2 表示低频术语占2个;若指明为高频和低频占比,则分别表示:
"minimum_should_match": {
"low_freq" : 2, // 低频术语占2个
"high_freq" : 3 // 高频术语占1个
}例子:


3.术语查询
term-level queries,术语级查询,将根据存储在反向索引中的确切术语进行操作,通常用于结构化数据,如数字,日期和枚举,而不是全文字段。所有属于term level query的API的查询术语,都是给什么就认什么,不会再分析查询术语(明显区别与full text query)
3.1.term
term query查找指定字段的倒排索引中指定的确切术语的文档。它对大小写敏感且不会对查询参数分析,所以常用在对关键字、数字、日期字段查找值。其实,当字段的数据类型是"text",最好不要使用term查询,为啥?ES索引"text"类型的数据,会先将它们分析,例如原句"Quick Foxes! "经过分析器后得到结果"quick"和"foxes",最后ES是将"quick"和"foxes"保存到倒排索引。对比下使用match和term查询就可以知道:match: "Quick Foxes!",ES分析后得到quick和foxes去匹配倒排索引,那肯定匹配的到term: "Quick Foxes!",ES不会对term query进行分析,所以直接用QuickFoxes!去匹配倒排索引,肯定匹配不到(倒排索引只有"quick"和"foxes",根本没有Quick Foxes!)
语法:


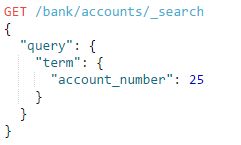
例如:
查询 account_number=25的文档:
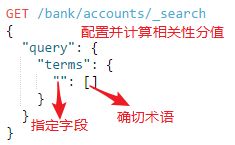
3.2.terms
terms query用于查找包含指定字段中指定的任何确切术语的文档,它是term的"复数形式",term只能从指定字段中的匹配一个确切术语,terms可以从指定字段中匹配多个确切术语。
语法:
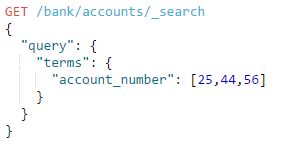
例如:
查询account_number值为25或44或56的文档
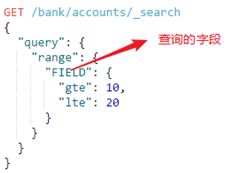
3.3.range
range query查找指定字段包含指定范围内的值(日期,数字或字符串)的文档。range接受以下参数:gte 、gt、lte、lt和boost(表示匹配分值),
语法:
特别地,当range用在date类型上的字段时,可以使用date Math指定范围。它会将日期舍入到最近的日期,月份,小时等,舍入日期取决是要"大于"还是"大于等于",这一点很重要,不清楚的话会多出或少掉临界点的日期。
舍入规则:
向上舍入移动到舍入范围的最后一毫秒,并向下舍入到舍入范围的第一毫秒
①gt: 大于日期的四舍五入:2014-11-18 || / M成为2014-11-30T23:59:59.999,即不包括整月
②gte: 大于或等于日期向下舍入:2014-11-18 || / M成为2014-11-01,即包括整个月
③lt: 低于日期向下舍入:2014-11-18 || / M成为2014-11-01,即不包括整个月
④lte: 小于或等于向上舍入的日期:2014-11-18 || / M成为2014-11-30T23:59:59.999,即包括整个月
默认ES储存日期的格式为严格模式,"yyyy/MM/dd HH:mm:ss"不足两位数一定要补0,例如不能写"2018/1/11"而是要写"2018/01/11"。
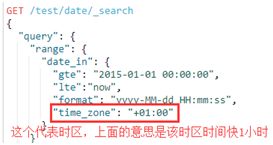
例子:
1、参数"format"指定日期格式

2、由于"time_zone"存在,所以gte指定的日期实际为"2014-12-31 23:00:00",而"now"不受time_zone影响
3.4.exists
查找指定字段包含至少包含一个非空值的文档
语法:
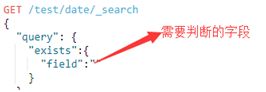
例子:
查询user字段不为空的文档:

1、会被匹配到的文档:

2、不会匹配到的文档:
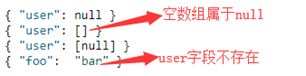
注意点:
①若字段的_mapping中包含null_value设置,则使用指定的null_value替换显式空值。例如,如果user字段映射如下

显式空值(null)将被索引成字符串"_null_",以下文档将匹配存在:
![]()
但是,这些文档因为没有显式空值(null),在user字段中仍然没有值,因此与exists过滤器不匹配:
![]()
3.5.prefix
匹配包含具有指定前缀(未分析)术语的字段的文档。前缀查询映射到Lucene PrefixQuery,请注意"prefix"也是属于确切属于行列,与term一样,只不过term给出全部术语,而prefix只给出前缀术语:
语法:
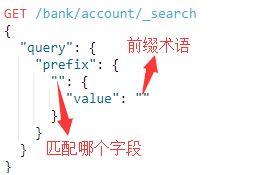
例子:
查询address字段中带有"put"前缀的文档,注意prefix与term一样,它不会分析查询参数,"put"和"Put"是两个不同的查询参数,它也是从字段的倒排索引中匹配是否有put前缀的术语。
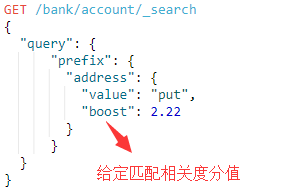
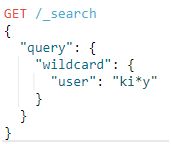
3.6.wildcard
匹配具有与通配符表达式匹配的字段(未分析)的文档。支持的通配符是:①"*",它匹配任何字符序列(包括空字符序列)②"?",它匹配任何单个字符。此查询可能很慢,因为它需要迭代多个术语。为了防止极慢的通配符查询,查询术语不应该以通配符*或?之一开头。通配符查询映射到Lucene WildcardQuery。
语法:

例子:
查询user字段匹配" ki*y "通配符的文档
3.7.regexp
查找指定字段包含与指定正则表达式匹配的术语的文档,正则表达式查询的性能在很大程度上取决于所选的正则表达式,像" .*?+ "这样的通配符匹配器会降低性能。ES不会解释正则表达式,而只是解释支持的运算符。


额外参数:
①boost:设置匹配相关度分值
②flags:Lucecne的特殊标志,详见Lucene API文档
③max_determinized_states:提高此参数可以允许执行更复杂的正则表达式,默认为10000

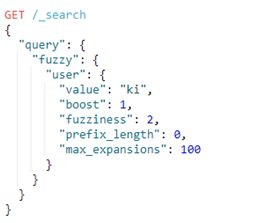
3.8.fuzzy
fuzzy query,模糊查询,使用基于Levenshtein编辑距离的相似性。它查询所有可能的匹配项,这些匹配项处于查询参数指定的最大编辑距离内,然后检查术语词典以找出索引中实际存在哪些生成的术语。

额外参数:
①fuzziness:最大编辑距离。默认为AUTO
②boost:匹配相关度
③prefix_length:不会“模糊化”的初始字符数。这有助于减少必须检查的术语数量。默认为0
④max_expansions:模糊查询将扩展到的最大术语数。默认为50
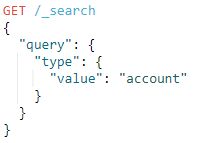
3.9.type
type query,查询与提供的文档/映射类型匹配的文档
语法:

例子:
查询类型为account的文档:
3.10.ids
ids query,查询包含提供的ID的文档。请注意,此查询使用_uid字段。类型是可选的,可以省略,也可以接受值数组。如果未指定类型,则尝试在索引映射中定义的所有类型。
语法:

例子:
