NetCAT:来自网络的实用缓存攻击
不断增加的外围设备正在增加现代处理器中内存管理子系统的压力,例如:DRAM的可用吞吐量已经不能满足现代网卡的传输速率。为了达到承诺的传输性能,Intel处理器使IO操作直接在末级缓存(LLC)上进行,而不需要经过DRAM。虽然直接缓存访问替代直接内存访问对提升性能使可行的,但是,忽略了安全性的考虑,因为末级缓存(LLC)是在CPU和所有外围设备之间共享,包括网卡。
DCA,在最近的Intel处理器中,通常被称为直接数据访问IO,本文对其进行逆向工程,并对其进行安全分析。本文中的NetCat,是第一个基于网络的针对远程机器处理器LLC的PRIME+PROBE缓存攻击。NetCAT不仅可以在协作设置中启用攻击,在这种设置中,攻击者可以在网络客户端和沙箱服务器进程(没有网络)之间建立隐蔽通道。更令人担忧的是,在一般的对抗设置中,NetCat可以泄露基于网络延时的敏感信息。
本文展示了对同一服务器上另一个SSH连接的击键延时攻击。
1. 简介
为了提高效率,运行在同一CPU上的不同进程可能会共享微架构中的元器件,比如CPU缓存。注意:这些进程属于不同的安全域,这种共享打破了微架构级别的进程隔离思想。许多已经存在的攻击表明,可以通过监测受害者进程对共享微架构资源状态的操作来获取秘密信息,这些攻击甚至可以通过浏览器的javascript脚本进行。这些攻击的基本假设是,攻击者需要执行代码或利用在目标处理器上运行的受害者进程代码的能力,才能观察到微架构中共享资源状态的修改。本文中,将挑战这两种假设,实验结果显示,在现代Intel处理器模型中,任何外围设备(比如网卡)都能操纵和观察到处理器末级缓存的状态。
之所以可以这样做,是因为处理器使外设能够执行直接缓存访问(DCA)而不是直接存内存访问(DMA),以提高I / O性能。 本文首次探究了这种被广泛采用的机制的安全隐患,结果表明,攻击者可以用它从能被恶意输入的任何外围设备中泄漏敏感信息。为了说明这种威胁,NetCAT可以将连接启用DCA服务器的受害者客户端作为目标,在SSH会话中泄漏该客户端的私钥。
已经存在的微架构攻击:
为了通过微体系结构攻击泄漏敏感信息,攻击者需要能够检测出受害者对微体系结构状态的一部分所做的修改。
例如,在PRIME + PROBE攻击中,攻击者首先 prime 共享资源以使其状态已知。 第二步,攻击者通过再次访问它来 probe 相同的资源集。 如果这次的访问速度变慢,则意味着受害者进程的秘密操作已经访问了该资源。 这些观察结果足以泄漏来自进程或在同一处理器上运行的VM的秘密信息,例如加密密钥。此外,通过执行JavaScript,甚至在与能被攻击的进程进行交互时,通过网络也能进行类似攻击。基于JavaScript的攻击虽然不需要在本机执行代码,增强了其威胁,但可以用沙箱缓解,使得仍然需要受害者执行攻击者的JavaScript代码。
实际上,远程网络攻击通过一个存在漏洞的进程来替代交互,降低了在目标计算机上执行代码(无论是JavaScript还是本机代码)的要求,该进程运行在远程处理器上,包含特定利用代码,或者能与客户端同时运行 。 这些攻击无法直接看到CPU缓存状态,因此它们需要进行大量耗时的网络测量,以及一个存在漏洞的受害者进程,因此,在实践中难以使用。
NetCAT,本文表明,在拥有DDIO功能的Intel平台上,能够在远程处理器上,通过网络来监测一个LLC缓存的“命中”或“未命中”状态。这使得攻击变成可能,是因为数据中心网络已经变得越来越快,以至于它们允许远程进程观察从远程处理器的缓存提供服务的网络数据包与从内存提供的数据包之间的时序差异。NetCaAT,使用prime+probe攻击远程处理器的LLC,可以观察到远程处理器的活动,还有其他和该远程服务器交互的客户端活动。例如,NetCAT可以进行按键时序分析,以恢复与目标服务器的正在进行SSH会话的受害者客户端键入的单词。与本地攻击者相比,NetCAT跨网络的攻击通过对比SSH数据包的到达间隔,只会降低平均11.7%的预测准确性。
面临的挑战:
-
必须逆向工程DDIO(Intel的DCA技术)和LLC的交互过程,因为这部分信息未被公开;
-
为了完成PRIME+PROBE,只能探索性地制作对的网络包序列,从而构建远程驱逐集;
-
为了实现端到端攻击,需要能追踪到远程服务器在什么时候接收到受害者客户端发来的数据包。
本文找到了一个新颖的缓存集跟踪算法,能够恢复NIC环缓存上的状态,这种方法能够用来追踪不同的SSH交互。获得的缓存活动足够分析出受害者客户端从键盘输入的单词。
2. 背景知识
2.1 内存分级
为了加速CPU对内存的访问速度,大多数商用处理器架构都存在多级缓存,这些缓存离CPU越近,访问速度越快,但是由于成本原因,空间就越小。缓存就绪是为了空间利用率和临时数据访问。在三级缓存结构中,每个CPU核心有自己的专用缓存L1和L2,此外,所有处理器核心还共享有1个三级缓存,也就是末级缓存(LLC),LLC有一个特别的区域,用于跨CPU核心数据访问,最近,这个LLC也开始用在PCIe数据交换过程中。抛开速度和尺寸,缓存有两个主要的特性:包含和不包含。举个例子:在以前的Intel服务级处理器中,LLC包含L2,即,L2中的所有缓存行在L3中都有一份,从Skylake X架构开始,LLC不包含LL2,即L2中的缓存行可能不存在LLC中。
2.2缓存攻击
缓存攻击通常分类在微架构攻击中,一般的想法是去泄露CPU上或者周边的共享资源状态。攻击者利用这些共享资源来泄露(窃取)信息。在缓存攻击中,攻击者构建一个基于时序信息的侧信道,时序信息在从不同级别缓存或内存中取数据时获得(缓存命中和未命中时,需要的时间不一样),这些时序信息可以用来获取其它进程中的数据,从而恢复密钥。一个成功的侧信道攻击能够绕过高级别的安全机制,例如:特权分离(操作系统用户态和内核态权限隔离算一种)。
Osvik等人探索了在L1上使用PRIME+PROBE的攻击方法,具体分为3步:
- 构建缓存驱逐集;
- Prime:通过访问驱逐集,让缓存状态成为一种可知的状态;
- Probe:在受害者进行加密操作过程中,再次访问驱逐集,如果访问某个集合需要的时间更长(之前在缓存中的数据数据被覆盖,再次访问驱逐集需要触发缺页机制,从memory中取值),则该集合所在位置被受害者进程访问过。
Ristenpart等人使用PRIME+TRIGGER+PROBE负载测量技术来检测L1和L2缓存上的击键活动,从而使攻击者可以推断出分时共享一个CPU核心的虚拟机(VM)上的活动。Liu等人扩展了PRIME+PROBE,使其适用于LLC,允许攻击者从同一台机器上的VM中提取秘密,而无需共享同一内核。
基于浏览器的缓存攻击:
基于浏览器的缓存攻击在JavaScript沙箱环境中执行,增强了本机代码缓存攻击的威胁模型。他们得出了如下结论:JavaScript代码在逻辑上执行沙箱操作(在Javascript环境中执行),但在微体系结构级别并非这样。Oren等人介绍了一种不规范的PRIME+PROBE攻击,该攻击在Javascript中执行,并且不需要直接的物理地址或虚拟地址内存访问。NetCAT在构建驱逐集的时候参考了这个工作。Gras等人使用EVICT+TIME攻击,通过Javascript环境打破了ASLR机制。Lipp等人介绍了一种基于Javascript的击键时序攻击,从而监视用户在浏览器地址栏的输入。Frigo利用针对集成GPU的微架构攻击来逃离安卓环境的Firefox Javascript沙箱。
这些攻击都面临着一些挑战,例如:高精度计时器,以及现代浏览器中存在其他沙箱级缓解措施,并且还要求受害者执行攻击者的JavaScript代码。
2.3 远程缓存攻击
现有的仅利用网络的远程缓存攻击利用了这样一个事实:攻击者可以在将请求发送到Web服务器之后观察其在服务器上的执行时间。针对OpenSSL的远程攻击显示这是可行的。Bernstein从已知的AES明文中恢复了完整的AES key,Neve等人在这基础上作了进一步工作。Schwarz等人描述了一种基于网络的Spectre攻击,该攻击针对远程受害者中的特定代码模式(或代码片段),从而泄露信息。所有这些攻击都是针对特定目标的,并且由于需要对大量网络数据包进行平均以消除网络噪音,因此需要较长时间(数小时至数天)。这两个工作它们都需要包含特定代码片段的易受攻击的(或以其他方式合作的)受害者服务器程序。此类代码片段必须确保依赖输入的操作占整个执行时间的大部分,以泄漏信息。
本文是一个通用的远程缓存侧信道攻击,展示了一份真实的、不完全的实例攻击场景列表,这些场景不需要依赖目标软件。
2.4 直接缓存访问(DCA)
在传统的架构中,NIC使用了一种DMA(直接内存访问)的技术,很快,仅内存延迟就成为10 Gb / s接口上以网络I / O为中心的工作负载的瓶颈。为了环节DRAM的瓶颈,提出了DCA(直接缓存访问)的技术,折中架构中,PCIe设备能够直接访问CPU的LLC(末级缓存)。
DCA缓存区域不是在LLC中专用或保留的,但是分配的写操作静态地限制在LLC的一个区域,以避免由I / O突发或未使用的数据流引起的浪费。
下图展示了DMA(蓝色线)和DCA(橘色线)的区别,LLC中,用于DCA的可用写分配缓存行为橙色,其它缓存行为绿色:
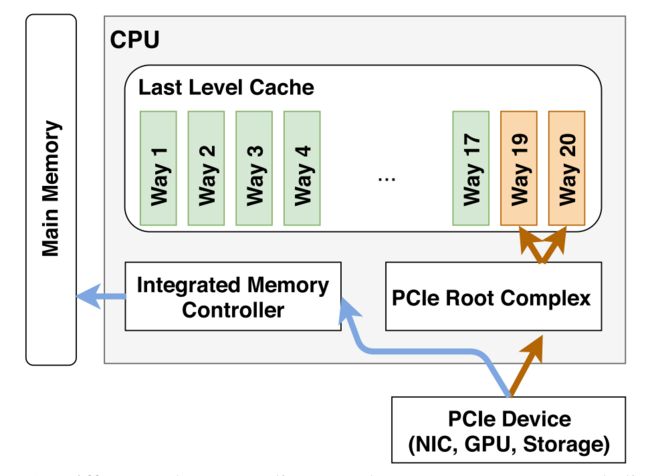
最初,英特尔使用预取提示方法实施DCA,其中,DMA写操作将在到达内存后触发内存预取,将内存的数据预取到LLC,但这需要设备的支持以提示DCA,并且,还需要设备驱动程序支持预取这些DCA提示。
从2011年英特尔至强E5和至强E7 v2处理器家族开始,服务器级CPU以数据直接I / O技术(DDIO)的名称实施DCA,这对软件和硬件完全透明。 借助DDIO,服务器计算机可以在最佳情况下接收和发送数据包,而不会发生任何跳到主内存的情况。 在下一部分中,将进一步描述DDIO并对其行为进行逆向工程。
3 攻击模型
本文的威胁模型针对使用最新配备DDIO的英特尔处理器的服务器,自2012年以来默认情况下在所有英特尔服务器级处理器中透明启用此功能。本文假设攻击者可以与服务器上的目标PCIe设备(例如NIC)进行交互。为了在实际情况下实例化攻击,我们特别假设攻击者与受害者服务器位于同一网络上,并且可以将数据包发送到受害者服务器的NIC,从而与远程服务器的DDIO功能进行交互。
特别地,在本文的示例中,作者通过网络对目标服务器发起了缓存攻击,以从服务器与其他客户端之间的连接中泄漏秘密信息(例如击键)。尽管我们在本文中主要关注客户端到客户端的攻击,但是DDIO也可以在其他环境中使用。第9节介绍了其他威胁模型,在这些模型中,我们的NetCAT可能会应用于目标服务器处理器(而不是其他客户端)以及其他PCIe设备上的应用程序。
本文的示例攻击利用了NIC中的RDMA技术来控制传输的数据包访问的内存位置,并提供当今高速网络提供的低延迟。RDMA现在可在许多主要提供商和许多数据中心(例如Azure,Oracle,华为和阿里巴巴)的云中使用。在虚拟化云设置中,只要NetCAT可以通过虚拟RDMA接口与这些VM之一进行通信,它就可以以目标服务器上的任何VM为目标。此外,如果攻击者的VM(或虚拟服务器)使用SMBDirect 或NFS 之类的协议通过RDMA连接到存储服务器,则NetCAT使攻击者可以监视连接到该存储服务器的其他客户端。类似的,key-value服务和集成RDMA以提高其性能的应用程序,包括大数据,机器学习和数据库,可能会被类似NetCAT的攻击所利用。
4. 攻击概述
我们的目标是利用启用DDIO的应用程序服务器在CPU内核和PCIe设备之间具有共享资源(LLC)这一事实。通过利用LLC,我们可以从应用程序服务器的LLC泄漏敏感信息。存在很多种可能的方法来利用DDIO,例如:对受害者计算机具有物理访问权限的攻击者可以安装恶意PCIe设备来直接访问LLC的DDIO区域。本文的目的是证实:即使对于仅具有对受害机器的远程(非特权)网络访问而无需任何恶意PCIe设备的攻击者,类似的攻击也是可行的。
为此,我们使用了现代NIC中的RDMA,RDMA在数据层面绕过操作系统,从而为远程计算机提供对先前指定的内存区域的直接读写访问,操作系统负责设置和保护此RDMA区域,但是,当启用DDIO时,RDMA读取和写入不仅可以访问固定的内存区域,还可以访问LLC的一部分。Mellanox进一步鼓励使用RDMA来最大程度地减少由于防御最新的推测性执行攻击而导致的性能下降。但是,RDMA使我们更容易执行基于网络的缓存攻击。
下图说明了我们的目标拓扑结构,这在数据中心中很常见:
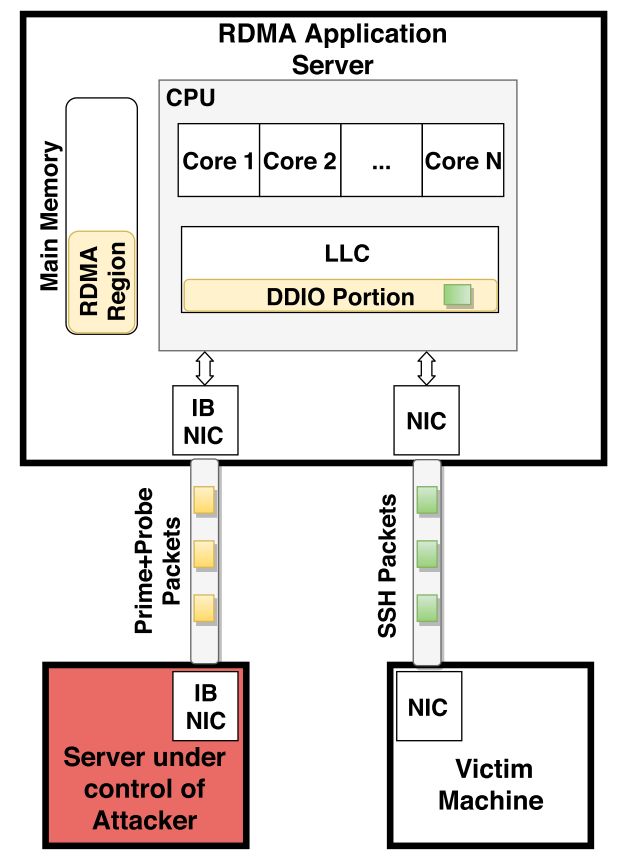
攻击者控制一台计算机,该计算机通过RDMA与支持DDIO并且还为来自另外NIC上的受害者的请求提供服务的应用程序服务器通信。这样,我们可以成功地监视其他PCIe设备。我们也可以不依赖这种分隔(该分隔指:攻击者和受害者不使用同一网卡),即:监视处理PRIME+PROBE数据包的同一PCIe设备。在我们的对抗攻击中,我们将假定受害者客户端通过ssh连接键入敏感信息。攻击者的目的是使用PRIME+PROBE数据包找到受害者客户端键入的内容。
为了实现这个攻击,有三个挑战:
-
弄明白DDIO的内部工作方式
我们的攻击需要对DDIO每种操作的影响有确切的了解,DDIO的分配限制,以及检测缓存命中的可行性。 -
远程PRIME+PROBE
我们的攻击要求我们为PRIME + PROBE攻击远程构建缓存逐出集,而无需了解远程计算机上RDMA内存区域的虚拟或物理地址,从而在测量网络缓存活动方面带来了独特的挑战。
-
端到端攻击
要实施端到端攻击,我们需要对哪些敏感数据可能驻留在LLC的DDIO可访问部分中并可能被泄漏有深入的了解。
5. 逆向工程DDIO
为了远程测量缓存活动,我们需要PCIe设备的DDIO功能提供的远程读/写函数。本节讨论如何构建这些必需的函数以发动攻击,同时详细说明DDIO的相关细节。
5.1 访问延迟
实施攻击的第一步是确定我们是否可以通过网络来测量缓存命中与内存读取(未命中)之间的时间差。我们使用了两台运行Ubuntu 18.04.1 LTS的服务器(Intel Xeon Silver 4110),每台服务器都配备了Mellanox ConnectX-4 Infiniband NIC(于2016年生产)。我们将其中一台服务器用作RDMA服务器,将另一台服务器用作客户端。作为基准,ib_read_lat延迟基准测试了两台机器之间的平均延迟1,550 ns,标准偏差为110 ns,第99个百分位数为1,810 ns。为了发送单边的RDMA读取和(在以后的实验中)写入,我们使用libibverbs(RDMA的库)。
在我们的第一个实验中,我们迭代了50,000个内存地址150次。在每次迭代中,我们向相同的内存地址发出两次RDMA读取,并测量了每次结果返回到客户端所花费的时间。结果显示,两次访问之间没有显着差异。仔细检查发现,这是因为通过DDIO读取一个不存在LLC中的地址时,直接从内存中获取数据,而没有在LLC中分配(即,随后对未缓存存储位置的读取仍然未缓存)。
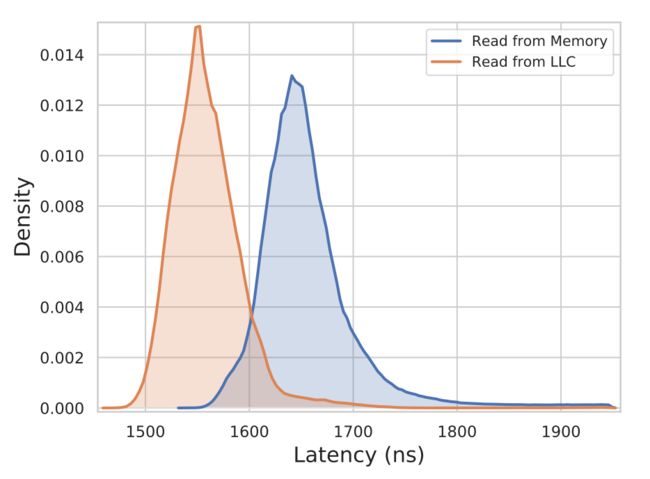
在第二个实验中,我们在每次迭代中做以下操作:Read(x) - Write(x) - Read(x),这样做的考虑是:第一次读取是从内存中进行的,而分配缓存并写入后的读取是从LLC中进行的,这使我们能够测量内存读取和缓存命中之间的时间差异。
下图显示了两种类型读取的结果分布是可区分的。 第6节讨论了进一步区分基于LLC的读取和内存读取的机制。
5.2 DDIO的缓存方式
如前所述,DDIO限制了写分配,以防止PCIe设备造成缓存损坏。由于此限制会影响我们创建逐出集和发起缓存攻击的能力,因此我们研究了该限制的机制。为此,我们构建了一个地址池,这些地址映射到相同的缓存集,并且可以通过RDMA访问。我们通过在RDMA服务器上分配一个较大的缓冲区,然后应用Maurice等人的方法来查找具有相同LLC标记的页面来实现此目的。然后,我们重新映射RDMA缓冲区,以便RDMA客户端可以直接通过DDIO访问这些地址,从而使我们能够远程创建驱逐集,而无需知道在一般情况下实现此目的所需的确切算法。借助这个被标记的RDMA缓冲区,我们能够探索LLC中DDIO方式的布局。
更具体地说,我们的实验重复写入被标记缓冲区(位于同一缓存集内)中的n个地址,然后读取这些相同的地址,从而测量是否从缓存中提供的这些读取。我们从n = 0开始,每轮之后增加n,期望这将使我们能够通过找到高速缓存命中数变为恒定的n来确定DDIO写分配限制。
我们在两台装有运行CentOS 7.4的英特尔至强E5-2630 v3处理器的计算机上执行此实验,每台计算机均配备Mellanox ConnectX-3 Infiniband NIC(2014年生产)。每台机器的LLC大小为20 MB,并根据规范进行20路关联。如下图所示,从n = 2(写0-1)开始,我们看到一个恒定的模式,即从缓存中提供两个地址,其余地址从主存储器中提供。
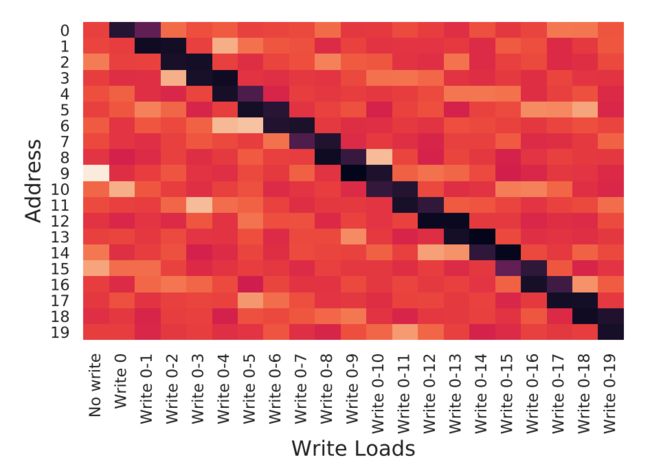
对于低延迟,存储图较暗,对于高延迟,存储图较浅。该实验提供了有力的证据,证明我们的测试机上有两种DDIO方式。原始的英特尔文档也支持这一点,该文档指出写分配限制为LLC的10%(即,总共20路中的2路为LLC的10%)。
上图还提供了对LLC中DDIO区域使用的缓存替换策略的见解。 如我们所见,最后两个被写的值由LLC提供。 我们对随机读写操作的进一步实验表明,替换策略最有可能驱逐DDIO区域中使用最少的(LRU)高速缓存行。
在Intel Xeon Silver 4110上,我们的实验同样揭示了两种DDIO方式,考虑到该模型使用11 MB和11路集的关联LLC,这意味着DDIO写分配限制大约是LLC的18.2%,如下表所示:

6. 远程PRIME+PROBE
为了发起成功的远程PRIME+PROBE攻击,我们需要在远程计算机的内存区域上进行读写操作。如第5节所述,RDMA在LLC上为我们提供了这些功能。
6.1 创建远程驱逐集
PRIME+PROBE的第一步是构建缓存驱逐集。本文中,在DDIO的写分配限制下,我们不为LLC中的所有缓存集构建驱逐集,而仅为DDIO可访问的有限数量的缓存路构建驱逐集。构建驱逐集并随后使用其泄漏数据依赖于基本RDMA操作,因此,使用单边RDMA并允许RDMA客户端写入数据的任何应用程序都可以用于NetCAT攻击。以RDMA-memcached(具有RDMA支持的键值存储)为例,RDMA-Memcached实现GET和SET操作,将内存分配分为1MB大小的块。为了分配足够大的内存区域来构建驱逐集,我们分配了多个1MB大小的键值项。这些内存区域一旦被分配,我们可以使用基本的单边RDMA操作以任意偏移量访问它们。构建驱逐集的一个挑战是,我们不了解远程计算机上RDMA内存区域的虚拟或物理地址。但是,我们可以通过相对于基准的偏移量来控制访问,并结合分配的内存块是页面对齐的知识。Oren等人通过JavaScript攻击LLC时,针对类似问题设计了非规范的PRIME + PROBE。我们以他们的算法为基础,但必须解决由于在网络上运行算法而带来的挑战。这些挑战包括抵御网络差异引起的时间偏移的弹性,以及第二台机器参与测量过程。而且,通过网络进行的读写操作要比本地运行慢几个数量级。该算法的更广泛的想法是使用一组与页面对齐的地址 S(与页面起始位置具有相同的偏移量)的页面对齐地址,以及一个候选地址x。该集合最初非常大,因此自然会形成地址x的逐出集合,然后,该算法通过迭代删除地址并检查该集合是否仍构成逐出集合来减少该集合。使用此向后选择策略,该算法将创建一个最小驱逐集,其大小等于高速缓存路的数量。在为页面中的给定偏移量找到一个逐出集之后,该算法可以为其余偏移量建立逐出集。页面大小为4KB,高速缓存行大小为64B时,将产生另外63个逐出集。我们的第一种朴素方法是使用多个回合来测量集合S是否仍构成逐出集合,以解决网络上的测量噪声。但是,这使算法相当慢,尤其是在分析所有可用的缓存集时(需要数小时)。 因此,我们引入了许多优化。
- 优化1:作为第一个优化,我们介绍了一种前向选择算法,该算法创建了一个可能的较小集合S,该集合S逐出地址x。我们从一个空集S开始,在每次迭代中,我们向S添加一个地址,直到测量出逐出为止。该选择过程平均将S中的地址数从数千减少到数百。 该优化效果很好,因为DDIO缓存路是所有缓存路的子集,例如在Intel Xeon E5-2630 v3 CPU上,我们只需要在构成地址x逐出的二十个潜在地址中找到两个即可。 然后,该减少的集合S是向后选择算法的输入。 前向选择算法在附录A中有详细说明。
- 优化2:第二个优化是向后选择算法。 在原始算法中,集S首先被完全写入,然后再次写入,同时在每次迭代中都留下一个地址s, 根据S \ s是否仍为逐出集,将x的缓存未命中时间与x的未命中/命中时间进行比较。 在我们的方法中,我们首先通过写入和读取x来测量x上的缓存命中,然后将访问时间与S \ s进行比较。 之所以可行,是因为S在成功进行性能分析运行时总是将x逐出,同时在此步骤中将写操作的次数减少了两倍。
- 优化3:作为第三种优化,我们实现了动态调整算法,该算法不只从反向选择过程中仅从集合S中删除一个地址s,而可以同时从S中删除多个地址。 在前一次的迭代成功减少S后,该算法将要删除的地址数量增加了十。相反,如果前一次迭代未减少S,则该算法将要删除的地址数量减少了一个。要删除的地址数量最多限制为S大小的一半。当S的大小较小时,将禁用动态调整算法,因为进行调整可能会对运行时间产生负面影响,并需要额外的迭代。 我们在附录B中概述了更新的向后选择算法。在最近的研究中,Vila等人提供了一种优化算法,可将逐出集减少为最小逐出集。 应用新算法可以进一步提高后向选择的性能。
- 优化4:我们的最后一个优化引入了清理步骤。在为一个缓存集成功构建一个逐出集之后,我们遍历整个地址池以查找其他地址,这些地址也映射到同一缓存集。 它们要么不是S的一部分,要么在S中是多余的,可以将其从最小驱逐集中删除。 此清理步骤有助于缩小由子缓存集的前向选择算法(以及流水线的其余部分)产生的地址池。
适应能力:
我们的实验采用多种策略来应对网络噪声,网络排队以及测量机本身的副作用。 首先,我们使用多个测量回合并进行中值延迟测量。 这种简单而有效的方法显着提高了建立驱逐集的稳定性。 轮次是性能和可靠性之间的折衷,可以根据不同环境中的噪声因素进行调整。 但是,请注意,只有在控制要测量的操作时,才能使用此方法。 构建驱逐集时就是这种情况,但是正如我们稍后将要看到的那样,击键检测不是这种情况。
其次,如第5节所示,如果DDIO读取是由主内存提供的,则不会导致缓存分配。 因此,我们已经知道DDIO读取不会更改LLC的状态。所以,我们可以利用这一特点,通过连续读取同一地址多次并记录每次读取的延迟时间,取这些时间的中值。在不能单独测试每次的读取时间时,这种方法很有用。
最后,三个不同的阶段(正向选择,向后选择和清除)具有多个内置的完整性检查。 如果测试失败,则管道要么返回到上一阶段,要么完全重新启动此缓存集的性能分析。
6.2 评估
我们在DAS-5群集上评估了远程驱逐集构建算法。 这使我们能够使用具有不同等待时间的机器对来测试该算法,具体取决于它们在数据中心的位置以及交换机跳数的不同。 所有机器都具有相同的处理器(Intel Xeon E5-2630 v3)和机器配置。 此外,我们在另一个Intel Xeon Silver 4110群集上评估了该算法,以显示攻击的一般性。 我们使用了5,000个页面对齐地址的初始池来构建逐出集。 我们分析了总共16,384个缓存集(256种标记,4KB页面大小)。
如下图所示,总分析时间在3分钟到19秒之间,以及5分钟到52秒之间:
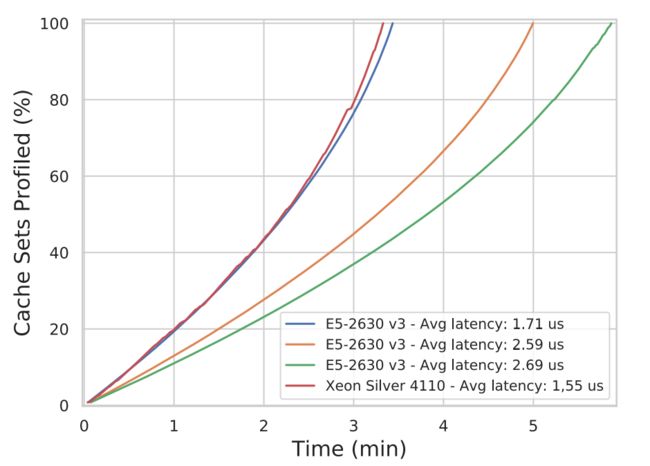
我们可以看到,网络延迟对配置整个LLC所需的时间有直接影响。此外,当池中的地址较少时,算法的性能也会提高。该加速归因于清理步骤,在该步骤中,从池中删除了属于同一缓存集的地址,从而随着时间的流逝减少了算法的搜索空间。图中显示的延迟是由ib_read_lat延迟基准报告的。三种集群机器组合的延迟标准偏差在0.08µs至0.10µs之间。 Intel Xeon Silver 4110群集的延迟标准偏差为0.11µs。在至强Silver的记录中,我们还可以观察到完整性检查在第三分钟左右失败,这时算法将通过重新启动当前的配置回合而恢复。为了验证驱逐集的正确性,我们实现了一个验证程序,以针对映射到同一缓存集的其他地址测试每个驱逐集,以检查它们是否被驱逐。此外,我们对逐出集进行测试以验证其唯一性。
总而言之,我们表明可以在6分钟内为数据中心拓扑中的DDIO高速缓存行创建一个驱逐集。
7. 隐藏信道
在本节中,我们介绍两种基于DDIO的协作攻击。 在第一种情况下,我们在两个不在同一网络上但可以将数据包发送到共享服务器的客户端之间建立一个隐蔽通道。 在第二种情况下,我们在客户端和服务器上的沙盒进程之间建立一个秘密通道。 我们使用Lui等人的高带宽隐蔽信道协议,该协议最初用于在同一物理机上运行的两个虚拟机之间发送数据。 与我们的隐藏信道类似,Maurice等描述了进程之间的跨CPU核隐藏信道,Oren等人描述了用JavaScript构建的隐藏渠道。 此外,莫里斯等人开发了一种健壮且无错误的隐藏信道协议,该协议用于在两个虚拟机之间传输SSH连接。 在第8节中,我们介绍了一种基于网络的对抗击键计时攻击。
7.1 网络客户端之间的隐藏信道
在第一种情况下,两个客户端将RDMA数据包发送到目标服务器,但是它们不共享公共RDMA内存区域(即,无法直接通信),此外,客户端不能直接通过网络彼此通信,可以通过两个不同的物理网络或网络之间的逻辑隔离来强制实现这种情况。 从第六节,我们知道我们可以测量LLC整个DDIO部分的缓存活动。 这意味着我们还可以测量LLC中网络上另一个客户端的活动。
因此,在协作环境中,两个客户端可以通过将数据包发送到其各自RDMA缓冲区中的不同偏移量进行通信,而另一个客户端检测到哪个偏移量是由另一个客户端的数据包激活的。 在我们的单向隐蔽通道中,建立通信的第一步是就哪些高速缓存集将用于传输达成一致。 发送方选择页面对齐的内存位置,然后使用覆盖该位置的缓存集进行通信。 为了进行同步,发送方然后对页面中所有连续的缓存集进行迭代,并在很长一段时间内以不同的模式将数据包发送(使用RDMA写入)到这些缓存集。
接收者遍历所有被分析的缓存集以检测模式。 这样,接收方就可以找到64个缓存集(即一个页面),这些缓存集覆盖了与发送者页面标记相同的页面。 双方现在已经就服务器上的64个共享缓存集达成了一致。 因此,在每一轮中,发送方可以通过激活或不激活64个高速缓存集的每一个来发送64位。 为了宽松地同步测量,我们使用Lui等人的方法,发送方在预定义的时间内多次发送当前信息,接收方在相同的时间内测量缓存活动,因此知道传输回合何时完成。 接收者需要PRIME+PROBE 64个缓存集的时间是每一轮的最小时间窗口。
结果:隐蔽通道的合适时间窗口取决于接收器可以启动至少一个PRIME + PROBE迭代的时间。 在我们的测试网络中,可靠地允许接收器在该窗口内完成其操作的最小时间窗口为0.44 ms,这意味着峰值带宽为145.45 Kb / s。 在这种情况下,我们的错误率为9.43%。 我们评估了多个时间窗口,保守选择为4 ms(16 Kb / s)。 在更长的窗口中,接收器可以启动多个PRIME + PROBE迭代。 因此,接收器获得更多的数据点,从而导致较低的错误率。 在4 ms的窗口内,我们测得的错误率为0.20%。 下图说明了在不同时间窗口大小下的实验:
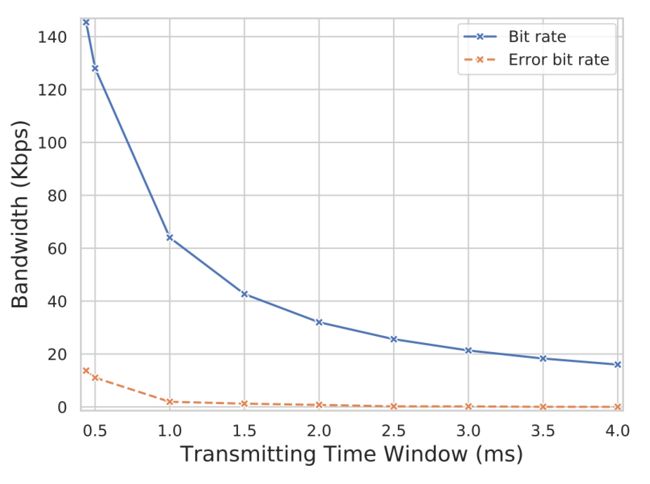
注意,这种简单的隐藏通道协议没有内置的可靠性。 如果需要更高的可靠性(即冗余),则隐蔽通道的带宽将成比例地减小。
7.2 到沙箱程序隐藏信道
在这种情况下,我们在服务器上具有无法访问任何网络功能的沙盒进程。但是,沙盒过程仍可以写入LLC。为了建立一个隐藏信道,我们观察到此场景与前一个场景相似,不同的是沙盒进程是发送方,客户端是接收方。与两个网络客户端之间的隐藏信道的区别在于,沙盒进程进行的内存访问并不必会溢出到专用于DDIO的接收方可见的LLC部分。
在我们的设置中,LLC的DDIO区域由两条高速缓存行(LLC中的2路)组成。因此,为了确保成功传输,沙盒进程必须在n路集联LLC中写入n-1个高速缓存行,以确保该写入在DDIO区域中可见。在非包含LLC中,该过程还必须考虑L2缓存,因为必须在将数据写入LLC之前填充L2。无论LLC是否包含在内,沙箱进程都必须先按照先前的工作策略创建一个LLC驱逐集。一旦找到了针对64个不同缓存集的逐出集,便可以类似于使用两个网络客户端的情况来构建隐藏信道,主要区别在于,沙盒进程必须针对每个目标缓存集写入整个逐出集,而不是每个缓存集写入一次。然后,接收器可以使用PRIME+PROBE监视来自网络的驱逐。
结果:类似于我们在网络客户端之间的隐藏信道,传输回合与预定义的时间窗口松散地同步。 同样,隐藏信道的带宽受到接收客户端检查64个缓存集的速度的限制。 因此,即使发送方必须比以前的隐藏信道发出更多的写操作,这些操作还是在本地CPU上完成的,这比接收方基于网络的操作要快得多。 因此,沙盒过程隐蔽通道的带宽与网络到网络隐藏信道的带宽相同。
8. 基于网络的击键攻击
在本节中,我们展示了对抗环境中的结果。 我们测量来自受害者的SSH连接上的击键时间,以重建敏感(类型化)数据。 我们的目标不是要改进现有关于击键攻击的文献,而是要证明我们的缓存测量值足够准确,可以实施实际的对抗性的时间延迟攻击。
在较高级别,我们的攻击如下:攻击者控制了具有RDMA链接到应用程序服务器的计算机。攻击者使用远程PRIME + PROBE来检测LLC中的网络活动。 然后,用户从另一台计算机打开到应用程序服务器的交互式SSH会话。 在交互式SSH会话中,每个击键都以单独的数据包发送。 攻击者可以使用环形缓冲区位置从缓存中恢复数据包间的时间,并将其映射到对应击键。如本节所示,可以通过单次跟踪敏感数据来发起此类攻击。 启动远程PRIME + PROBE以测量LLC活动后,成功的攻击需要执行以下步骤:
- 找到RX队列的网络环形缓冲区;
- 跟踪RX包头以恢复传入的数据包时间;
- 使用机器学习将时间映射到按键。
8.1 定位LLC中的循环缓冲区
环形缓冲区是一种循环数据结构,可促进进程异步读取和写入数据。 在联网的情况下,环形缓冲区用作NIC和操作系统之间的队列。 环形缓冲区不直接保存数据包数据,而是指向实际数据包数据结构的指针(套接字内核缓冲区)。 现代操作系统通常具有用于接收(RX)和发送(TX)数据包的不同队列(环形缓冲区)。 网络环形缓冲区通常分配在多个不同标记的页面上,这应防止环形缓冲区从缓存中自动退出。 我们的实验表明,环形缓冲区的访问在内存图中留下了非常不同的模式。 具体来说,两个连续的传入数据包激活相同的驱逐集,接下来的两个数据包然后激活下一个驱逐集,依此类推。 因此,对于多个连续的数据包,在内存图中可以看到阶梯状图案,如下图所示:
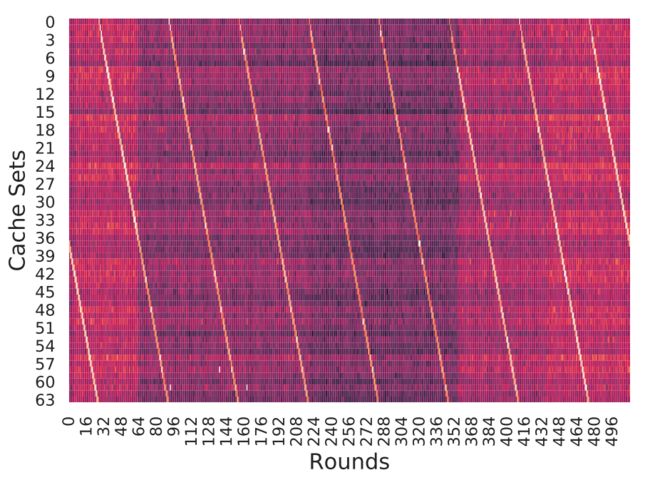
(使用远程PRIME + PROBE的环形缓冲区实验的内存图。 较深的颜色表示较快的颜色,较浅的颜色表示较慢的访问时间。 在每一轮中,我们发送两个网络数据包。 我们可以看到环形缓冲区在每个回合中都向前移动。)
要在远程LLC中找到环形缓冲区,我们首先按照第6节中的说明构建远程驱逐集。 接下来,我们启动一个PRIME + PROBE变体,在该变体中,我们在每次prime后向服务器发送两个网络数据包,然后立即通过probe步骤测量延迟。 对于256种标记的每一种,我们执行PRIME + PROBE 512次,每种标记总共1024个数据包。 完成所有回合后,我们在其中一页中找到了独特的楼梯图案。 在RX队列长度为128的情况下,该模式重复八次,如上图所示。
由于大多数现代操作系统的默认网络环形缓冲区大小为512–4096个记录,因此仍会出现阶梯模式,但会覆盖多个页面。由于模式是循环的,因此攻击者可以重建环形缓冲区的所有可能位置,并预测下一次缓存活动的预期位置。
现代NIC和操作系统通常支持多个RX和TX队列,并根据数据包数据的哈希值,使用诸如接收方缩放(RSS)之类的机制在接收方的不同队列上分发数据包。具体而言,哈希函数通常是在源IP地址,源端口,目标IP地址,目标端口和协议上的五元组输入哈希。通过更改源端口和协议,攻击者可以使用上述概要分析方法映射所有不同的队列。为简单起见,但又不失一般性,我们说明了对启用了一个RX队列和一个驻留在一页(即128个条目)内的环形缓冲区的系统的攻击。
8.2 追踪环形缓冲区
一旦确定了包含环形缓冲区的页面,便要跟踪环形缓冲区的确切活动以泄漏传入的数据包间时间。 一个挑战是,当我们看到某个缓存集已激活时,我们无法确定这是由于环形缓冲区还是由于其他缓存活动。 此外,由于两个后续数据包都激活相同的缓存集,因此观察到的环形缓冲区活动可能意味着接收到一个或两个数据包。 最后,与协作攻击不同,我们不能使用多个测量回合,因为环形缓冲区的位置可能在两次测量之间发生变化。
为了克服这些挑战,我们设计了一个两阶段流水线来提取分组间时间。online tracker 负责在测量期间跟踪以太网NIC环形缓冲区,并发送以太网probe数据包以连续确认其在缓存中的位置,该位置由发送RDMA缓存PRIME + PROBE数据包确定。offline extractor 获取跟踪器生成的数据,并使用它来计算最可能出现的客户端以太网网络数据包(非探测数据包,更具体地说是客户端SSH数据包)。 以下两段详细介绍了这两种算法的设计方式。
online tracker:重复检查所有64个逐出集太慢,无法测量未同步的网络数据包。因此,我们通过形成测量窗口w并根据环形缓冲区指针的当前位置移动w来减少同时测量的逐出集的数量。这种方法的挑战之一是确定何时移动窗口以跟随环形缓冲区的头部。为了解决这一挑战,我们在测量回合之间从攻击者计算机发送数据包。这些数据包可确保环形缓冲区前进和相应的高速缓存未命中。如果在线跟踪器没有观察到这一点,我们知道必须调整窗口w的位置。在较高级别,在线跟踪算法的工作原理如下:首先,我们必须确定环形缓冲区的当前位置pos。我们通过在初始PRIME + PROBE阶段发送许多网络数据包来做到这一点。一旦我们的算法检测到正确的当前环形缓冲区位置,便停止。
接下来,在线跟踪程序使用已知的pos在大小为w的窗口中prime pos周围的驱逐集。在我们的测试中,为了在测量速度和可靠性之间取得良好的平衡,我们选择w=10。现在我们进行prome(探测),直到算法在窗口w中检测到缓存激活为止,这时我们保存测量并开始另一轮prime。在启动缓存后,我们通过发送数据包来定期进行同步。每次同步后,该算法都会发送一个网络数据包,以确认我们已按预期注册了缓存激活。对于这些实验,我们需要时延阈值以区分导致缓存命中的数据包与导致缓存未命中的数据包。我们发现我们需要动态地维持此阈值,因为它可能会由于未说明的原因(可能是由于电源管理)而在受害机器上稍微浮动。除了我们对环形缓冲区活动的测量之外,我们还保存了所有已确认和丢失的同步点,以帮助进行下面描述的离线分析阶段。我们在附录C中提供了详细描述在线跟踪器行为的伪代码。
Offline extraction:脱机提取器阶段的目标是计算受害机器在哪个时间步接收到不是攻击者发送的probe数据包。为此,脱机提取器接收缓存行等待时间测量值,以及每个测量点的在线跟踪器状态。在线跟踪器仅在估计在测量中的任何地方都观察到高速缓存行未命中时才记录时间步长,而无论它是否是由probe引起的。
离线提取器检查高速缓存行等待时间测量并重建环形缓冲区访问。提取器可以依赖于探测数据包的已知时间,该时间作为提取器的基准。我们计算该到达模式产生的相应的环形缓冲区进程。我们通过对所有测量延迟求和来对这一猜测进行评分,根据该进展,这些测量延迟应该是缓存未命中。我们将延迟限制在10%之下和99%之上,以限制异常值的影响。
我们尝试通过从0开始在任何时间步大量地插入一个额外到达的数据包来增强最基本的猜测。如果这些插入中的任何一个比当前的结果更好地得分猜测,我们将采用这种新的数据包到达模式。 如果在步骤N中插入了新数据包,则我们尝试插入另一个从N开始的数据包(非0),并且仅在有改进的情况下才采用新的猜测,然后重复此过程,直到无法进一步改善猜测为止。 提取器的输出是其他客户端发送的可能数据包时间戳的列表。
在最后一步,我们过滤最有可能是SSH数据包的网络数据包。 此步骤是通过启发式方法完成的,因为我们没有任何头数据包信息来将SSH数据包与其他网络数据包区分开。 启发式的想法是,在发送击键后,客户端将发送一个ACK数据包。 此启发式方法在空闲网络上工作。 但是,这也是基于网络的攻击的固有局限性。 如果有更多网络流量,即数据包靠近在一起,则我们的算法无法将其与SSH数据包区分开。
8.3 击键预测
在上一节中,我们描述了攻击者如何测量与环形缓冲区相关的缓存活动,然后提取可能的SSH数据包。下一步是根据提取的分组间时间来预测击键。 Song等人率先从交互式SSH会话中恢复了击键。在他们的工作中,他们展示了在网络分路器上捕获SSH数据包时进行这种攻击的可行性。为此,他们使用了双字母组和隐马尔可夫模型(HMM)来猜测输入的密码。密码数据集的挑战在于从用户那里收集真实密码是不道德的。这将留下让用户键入预定密码集的选项,但是,真实的密码键入频率是唯一的,当不训练用户频繁且长时间地不输入这些密码时,很难估算出这种频率。此外,这样的数据集将需要数百个不同的密码才能进行公平评估。与该领域的最新工作类似,我们决定使用单词猜测来表明攻击者可以根据缓存的测量结果成功执行击键预测。
为了促进可重复性和可比性,我们使用了公开可用的数据集。 数据集由二十个主题输入自由和转录的文本组成。 我们从自由输入会话中提取的单词仅包含小写字符。 过滤后的数据集总共包含4,574个独特词,每个主题平均228.7个独特词。 我们为每个用户在训练和测试集中划分数据集。 对于多次键入的每个单词,我们在训练集和测试集之间以2:1的比例划分数据集。 我们确保测试集中的单词键入在训练集中至少具有同一单词的其他键入。 此外,我们还将单词键入保留在训练集中仅出现一次。 平均而言,训练集由376.25个单词键入和每个用户121个键入的测试集组成。 正如我们将在后面显示的那样,评估具有足够大的单词语料库的数据集至关重要。
为了预测单词,我们使用了k最近邻算法(k-NN),与最近有关微体系结构攻击的工作类似。 k-NN算法通过使用距离法来查看k个最近的邻居,从而对看不见的样本进行分类。 在我们的实验中,我们使用k = 15和均匀权重。 这种简单的方法非常适合对击键序列进行分类,因为我们希望用户每次都以类似的方式键入单词。 但是,用户的键入仍存在一定程度的差异,这使按键定时恢复变得困难。 先前的击键计时攻击也已经尝试了更复杂的方法,例如HMM,支持向量机制和神经网络,以将击键映射到字符,单词或用户。 我们在这里只关注简单的k-NN基线,并希望通过应用更复杂的方法,可以进一步提高我们的预测准确性。
8.4 评估
我们在具有3台计算机的Intel Xeon Silver 4110群集上评估了NetCAT,攻击者可以将数据包发送到受害计算机所连接到的NIC。如前所述,这使攻击者可以发送同步数据包。受害者开始与应用程序服务器的SSH连接,然后开始输入测试集中的单词。我们使用 expect(它是一个与交互程序进行交互的可编程接口),通过使用数据集中的 key-down-to-key-down 时间来恢复SSH会话中的单词。这种方法使我们可以使用不同的设置和环境因素来重复实验。在线跟踪器会在7秒内测量缓存活动。expect 程序开始在此次捕获窗口中恢复单词。请注意,确切的开始时间不会输入到跟踪或提取算法中。除了测量缓存活动之外,我们还使用tcpdump捕获应用程序服务器上的传入网络流量。尽管tcpdump基线获得一个强大的攻击者模型,该模型需要对服务器的物理访问(即,网络窃听),但这些跟踪信息使我们能够对 key-down-to-key-down 的分类器进行并排比较实际的网络数据包到达时间(通过tcpdump)以及从缓存活动中恢复的数据。
我们总共有2,420个测试字迹。训练数据的总捕获需要大约6h。这段时间包括在7秒钟内测量每个单词的缓存,以及一些时间来设置tcpdump。重要的是要注意,我们只追踪单词一次,并在分类中使用结果数据。
SSH包恢复的评估:我们在二十个主题的整个测试集中评估了联机跟踪器和脱机提取器的工作情况。如果该数据包在SSH按键数据包的间隔I内,则将其定义为True Positive(TP)。如果在SSH击键的时间间隔I内没有预测的数据包,则注册为 False Negative。如果信号提取预测的数据包多于发出的数据包,则将这些计数计为误报(FP)。同样,如果仅针对一个按键预测了多个数据包,则一个将导致TP,而其余将成为FP。我们在三个不同的时间间隔I上评估了提取。下表给出了我们的结果:
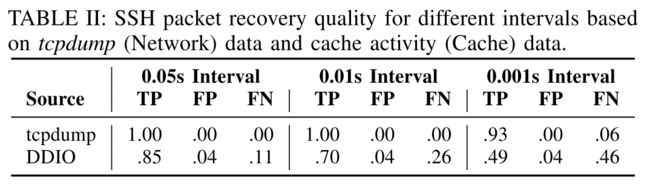
对于I = 0.05s,我们可以提取TP率为84.72%(FN率为11%)的SSH击键数据包。当减小间隔I时,FN的数量增加。当I = 0.001s时,TP率仍接近50%。张等人建立了I = 0.001s的标准数字,足以成功实现击键共计。为了进行比较,该表还显示了从tcpdump提取SSH数据包及其时间的结果。这些(理想的)结果用作网络上延迟的数据包的基线,因此不再位于间隔I之内。
下图显示了SSH击键发出时间与所有I = 0.001内正确预测的SSH数据包之间的绝对差值:
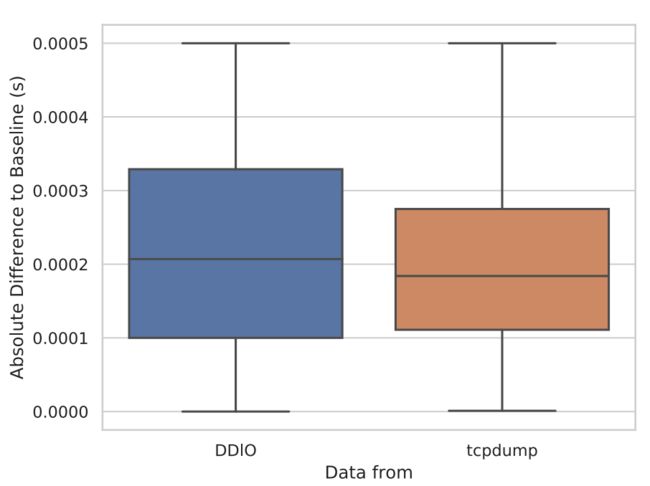
我们可以看到,与tcpdump捕获的数据包相比,来自缓存的正确分类的数据包具有更高的内部四分位数范围。 总的来说,这表明与基线和tcpdump相比,我们仅需很小的时间差异即可提取输入数据包时间。 然而,挑战在于首先要从缓存测量中正确提取数据包。 为了直观地了解SSH数据包的恢复成功,我们在下图中显示了“because”一词的踪迹:
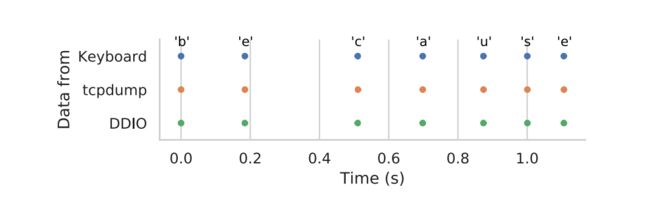
在这种情况下,恢复的SSH数据包几乎与原始击键完全吻合。 这种对齐方式在低延迟网络中是可能的。 否则,网络和缓存数据将根据传输时间移动。 由于我们分割1.2秒(以0.2秒为一个单位)来显示数据点,因此无法看到测量的微小扰动。
端到端评估:为了执行端到端的准确性评估,我们现在从缓存活动中获取预测的数据包,并将其输入到在键盘训练数据上训练的k-NN模型中。 我们选择此设置是因为攻击者可能有权访问击键数据集,但无法在目标网络拓扑上恢复它们。 为了使分类器的评估结果更直观,我们在下图中总结了键盘数据,从tcpdump提取的数据以及来自缓存测量的数据的准确性和Top-10准确性:
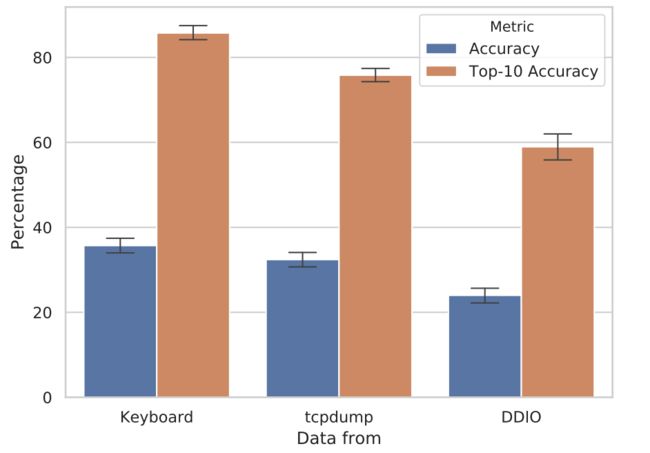
我们可以看到,即使是 击键数据,k-NN模型的准确性也低于40%,这告诉我们准确预测此数据集中的真实单词具有挑战性。 因此,我们使用常用的Top-10准确性度量标准,结果表明:在有限的猜测数(10)中预测正确的单词可以准确地达到85.75%。
将前10准确率的网络数据与原始击键数据进行比较时,我们可以看到准确性显着下降。将这些结果与表II中以0.001s为间隔的93.48%准确率进行比较,我们可以看到,即使在相交的时间中出现轻微扰动,也可能误导对原始键盘数据进行训练的分类器。与缓存测量一样,这对于不完美的SSH数据包恢复来说,预测正确的单词更具挑战性。但是,在所有用户中,分类器平均会在58.95%的单词的前十个猜测(前10个准确度)内预测正确的单词。令人鼓舞的是,这仅比tcpdump分类的性能低约15%。对于50%的单词,攻击者能够以7.85个猜测(中值距离)猜测单词。平均而言,所有用户和所有单词的猜测距离为20.89。平均每个用户我们有228.7个单词。因此,随机猜测者的平均距离为114.35个字。我们得出的结论是,缓存测量的信号足够强大,可以通过远程PRIME + PROBE发起成功的按键时延攻击。每个测试数据源和主题的完整测试分数可在附录D中找到。
为了分析词库对分类器的影响,我们更改了用于训练和测试的唯一词的数量。在每一轮中,我们从用户特定的语料库中随机选择x个单词,然后在下一轮中将x增加十。唯一的单词不必增加十个,因为我们每个主题的单词语料库大小不同。如下图所示,与原始数据集中唯一词的总数相比,使用较少唯一词的分类器具有更高的准确性:
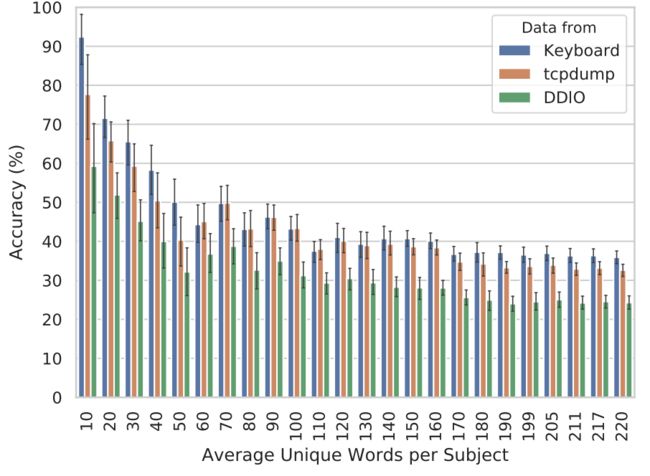
此外,准确性的差异在字数较少的情况下非常显着,并且每个实验在大约170个唯一单词的时候变平。可以对所有三个不同的测试数据源进行这些观察。使用大量唯一词的一个缺点是我们的训练数据集相对较小,即训练集中的大多数词只有一条用户的记录。一个每个单词具有许多重复,足够大的单词语料库和足够数量的测试对象的数据集自然会提高预测的准确性。
9. 推论
现在,我们讨论在未来的工作中,如何将类似于NetCAT的攻击推广到我们的概念验证场景之外。
PCIe到CPU的攻击:
如前所述,DDIO的写分配限制阻止了攻击者为整个LLC构建驱逐集,这使得直接从主机CPU泄漏信息成为挑战。为了完成此类信息泄漏,我们相信我们可以利用在受害者身上运行的服务器软件。例如,AnC攻击可能会通过网络发动。给定具有任意偏移量的读取原语(如Redis会给出的那样),攻击者可能会生成访问模式,该访问模式将刷新TLB集和反向缓存的转换缓存,正如[“Trans- lation Leak-aside Buffer: Defeating Cache Side-channel Protections with TLB Attacks” 和 “RevAnC: A framework for reverse engineering hardware page table caches”]两篇论文提到的逆向工程。然后,攻击者将取消引用目标虚拟地址,从而保证生成具有依赖于虚拟地址的偏移量的页表遍历。如果以相同的偏移量(模数页面大小)重复执行此实验的次数足够多,则逐出最终将达到DDIO级别,并且NetCAT可以观察到该信号。同样,我们期望当某些Spectre小工具以相同的偏移量(页面大小模数)重复取消引用时,它们将导致DDIO级别的可见驱逐,并允许秘密泄露,就像本地Spectre攻击一样。
另一个挑战是解决时间,通过该时间我们可以衡量缓存中的更改。 DDIO上下文中一个缓存集的逐出集包含两个地址。 因此,连续探测一个高速缓存集需要两次单边RDMA读取。 ib_read_lat延迟基准测试了我们的Intel Xeon Silver 4110集群之间单次读取的平均延迟,为1,550 ns。 在我们的实验中,我们将两个读取操作同时计时,与单次计时操作相比,其开销较小。 平均而言,我们可以在Intel Xeon Silver 4110集群(第99个百分位数:3066 ns,SD:115 ns)上描述一个总时间为2892 ns的逐出集。 解析时间受网络往返时间的限制,并且会因设置而异。 与本地缓存定时攻击相比,基于网络的攻击减少了解析时间,这意味着对于加密密钥恢复,可能需要更多的测量。 这是进一步研究的有趣途径。
将其它PCIe设备作为目标:
尽管本文重点介绍通过DDIO监视NIC活动,但通常我们可以在其他PCIe设备上进行监听。 例如,USB键盘可以通过DDIO将用户按键事件发送到LLC。 这为JavaScript攻击提供了可能性,这些攻击可以测量LLC的活动并可以获取敏感的击键数据或网络活动,如先前的攻击所示[“The Spy in the Sandbox: Practical Cache Attacks in JavaScript and their Implications”,“Practical Keystroke Timing Attacks in Sandboxed JavaScript”]。 与以前的攻击不同,通过DDIO进行的攻击将能够监视缓存访问模式并辨别特定于硬件的行为,如本文在NIC接收缓冲区访问模式中所展示的那样。 这有可能使启用DDIO的攻击达到更高的精度。
10. 修复
本节讨论了针对来自PCIe设备的最后一级缓存侧通道攻击的潜在缓解措施,例如本文提出的攻击。
禁用DDIO:针对基于DDIO的攻击(例如我们的攻击),最明显、最直接的缓解措施是禁用DDIO。 这可以通过调整集成I / O(IIO)配置寄存器来完成。 有两种可能,即全局更改(Disable_All_Allocating_Flows位)或每个根PCIe端口(NoSnoopOpWrEn和Use_Allocating_Flow_Wr位)进行更改。 通过在英特尔至强E5群集上设置这些位,我们成功地缓解了NetCAT。 对于Intel Xeon Silver 4110,尚未公开记录这些位的偏移量。 尽管这种方法通过阻止我们构建缓存逐出集来减轻攻击,但它的性能成本很高。 例如,即使对于10 GB / s的NIC,禁用DDIO也会带来性能瓶颈。 对延迟敏感的应用程序可能会使延迟增加11%至18%。 此外,每个两端口NIC的功耗可能会增加7瓦。
LLC隔离:另一个可能的防御方法是使用CAT在硬件或软件中对LLC进行分区,以将逐出限制为每个集合一定数量缓存路。但是请注意,由于所有启用DDIO的设备仍共享相同的缓存路,因此无法解决设备间DDIO侦听的问题。可以通过页面标记在软件中实现此防御,这可以通过隔离页面来隔离安全域。内核通过按标记组织物理内存(每种标记都是LLC中的一个分区),并确保独立的安全域永远不会共享一种标记。不幸的是,由于域经常共享设备,因此这种防御措施在实践中可能很难应用。在[“A software approach to defeating side channels in last-level caches”]中详细探讨了基于软件的LLC分区。现有的另一种软件缓存防御是基于TSX的。但是,此防御措施无助于抵抗我们的攻击,因为TSX仅保护CPU生成的缓存活动,而不保护设备。其他软件防御措施同样无法解决设备间监听的可能性。使用CAT也会产生负面影响,因为它可能被滥用来加速rowhammer(行翻转)攻击。
升级DDIO:原则上最替代的方法是更改DDIO的当前设计。 在理想的设计中,每个用户(例如,网络客户端)将接收他们自己的缓存部分。 通过缓存路进行分区似乎很有吸引力,但由于LLC中的缓存路数量有限,因此无法扩展。 最终,我们认为最佳的解决方案是灵活的硬件机制,该机制允许系统软件(例如OS)有选择地将LLC的区域列入白名单,以供支持DDIO的设备使用。
11. 相关工作
11.1 本地微架构攻击
在信息泄漏和破坏的背景下,已经对局部微体系结构攻击进行了广泛研究。 这些攻击通常监视受害进程或位于同一位置的VM。
Osvik等人在L1缓存上开拓了PRIME + PROBE攻击,而Ristenpart等人开发了PRIME + TRIGGER + PROBE来测量共享内核的VM上的L1和L2活动。 Liu等人在假定存在大内存页面的情况下将PRIME + PROBE扩展到了LLC,从而使攻击者可以从共同托管的VM中提取秘密。 后来的工作将威胁模型扩展到JavaScript,从而允许从Web服务器传递攻击代码。
我们的远程PRIME + PROBE基于Oren等人的方法来构建非规范的驱逐集。 而且,我们的攻击根本不需要在受害者计算机上执行攻击代码。
11.2 网络侧信道和微架构攻击
基于网络的旁通道攻击通常会在受害机器上触发代码执行,然后观察执行时间以泄漏信息。 例如,伯恩斯坦通过监视Web服务器中对已知明文消息进行加密的请求时间来恢复AES密钥。 本地计算机是受害者Web服务器的克隆,它支持监视。Cock等人利用OpenSSL漏洞利用MAC检查的非恒定执行时间对Datagram TLS发起了明显的攻击。Schwarz等人远程利用了包含通过网络触发的Spectre v1小工具的Web服务器。
Kim等人表明,Rowhammer漏洞可以由软件触发,后来发现可以通过越来越复杂的手段加以利用,所有这些手段都是本地的。 最近的工作表明,Rowhammer也可以从网络触发。 塔塔尔(Tatar)等人展示了如何利用RDMA在数据中心设置中构建端到端Rowhammer漏洞。 Lipp等人表明,在某些缓存受限的条件下,Rowhammer也可以在以太网中触发。
许多基于网络的攻击都需要重复操作以过滤掉诸如网络方差之类的噪声因素。 相比之下,我们的攻击仅通过单次操作即可泄露敏感信息。 之所以可行,是因为我们可以通过精确地确定要测量的缓存集来精确地测量缓存活动,从而为我们提供比以前的工作更准确的活动度量。 而且,NetCAT甚至可以监视其他PCIe外围设备(而不仅仅是CPU),这使NetCAT成为同类中第一个基于网络的攻击。
11.3 击键攻击
先前的击键恢复攻击针对的是进程、音频、CPU调度、Wi-Fi信号、中断和图形渲染。 Song等人是第一个使用SSH网络数据包来利用交织时间进行密码恢复的人,它使用了隐马尔可夫模型(HMM)对字符对进行建模。 Hogye等人认为,网络时序变化会掩盖现实网络中的这种交错时间。 Lipp等人使用JavaScript来监视输入到浏览器地址栏中的URL,使用的是封闭世界字典,并使用k最近邻居(k-NN)将其信号映射到URL。我们使用相同的基本技术来演示攻击的信号强度。但是,我们使用可公开获取的数据集,该数据集提供了大量的单词和主题,以表明我们的击键攻击在现实环境中是可行的。如第8节所述,大的单词语料库是验证分类器结果的关键。
在我们的原型设置中,我们能够以10kHz至20kHz的轮询频率检索缓存行信息。这样,我们的离线提取逻辑就足够可靠了,因此与从原始键盘数据预测单词相比,单词预测准确性平均仅降低11.7%。
12. 总结
在过去的十年中,不断提高的外围设备性能迫使英特尔将LLC置于其处理器的快速I / O路径上。本文探讨了此设计选择的安全隐患,并表明现代Intel CPU上的DDIO功能使系统可以通过网络缓存攻击。我们的概念证明利用NetCAT可以通过计时网络请求的持续时间来泄漏目标OpenSSH服务器的受害客户端的秘密击键。 NetCAT的实现要求我们对Intel处理器上DDIO技术的细节进行逆向工程,以便分别测量从LLC或内存提供的数据包之间的时序差异。仅使用此基本定时元操作,NetCAT就能构建逐出集并将其用作基于网络的LLC PRIME + PROBE攻击的第一阶段,最终导致我们的按键定时攻击。尽管有一些假设,NetCAT仍然具有强大的功能。我们只是为基于网络的缓存攻击打下了基础,并且我们预计将来还会有基于NetCAT的类似攻击。我们希望我们的努力能警告处理器供应商不要将微体系结构元素暴露给外围设备,而不进行全面的安全设计以防止被利用。