手把手教你用Kaggle开启机器学习之旅(附资源链接)

作者:NITYTESH AGARWAL
翻译:闫晓雨
校对:白静
本文约3200字,建议阅读10分钟。
本文分析了Kaggle利于数据科学领域新手学习的几点特征,并带你学习ML相关知识。

我经常被朋友和大学生问到“如何入门机器学习或数据科学”。
所以,这是我的答案……
前言
早些时候,我不太确定。我会说类似“学这门课”或“读这本教程”或“先学Python(这是我做过的事情)”。但是现在,随着我越来越深入这个领域,我开始意识到我采取的措施的缺点。
所以,事后看来,我认为“入门” 机器学习或数据科学的最佳途径可能是通过Kaggle。
在这篇文章中,我将告诉您为什么我这么认为,以及 如果我的推理令您信服,您将如何做到这一点。
注意:我是一名学生。我不是专业的数据科学家或机器学习工程师。我绝对不是Kaggle的专家。所以,请有保留地采纳我的意见和观点。 :-)
但首先,请允许我介绍一下Kaggle并澄清一些关于它的误解。
你可能听说过Kaggle作为一个网站,为机器学习比赛颁发令人难以置信的现金奖励。

Kaggle举办的比赛获得最高奖金
(是的,这些是百万美元以上的奖金!)
正是这种名气也引起了很多关于平台的误解,让新手们入门比原来更加犹豫不决。
如果你之前从未听说过Kaggle,也不要担心,因此,不要在意下面提到的任何误解。这篇文章仍然完全有道理。对待下一部分就当我向你介绍Kaggle一样。
误解
1. “Kaggle是一个举办机器学习竞赛的网站”
这是对“Kaggle是什么”的不完整描述!我认为竞赛(以及它们丰厚的现金奖励)并不是Kaggle的真谛。看看他们网站的标题——
![]()
竞赛仅仅是Kaggle的一部分
除了举办竞赛,(它目前已经举办过大概300场比赛),Kaggle还主持了3项非常重要的内容:
Datasets
https://www.kaggle.com/datasets
即使是与任何竞赛都无关的那些:与仅仅300个竞赛(在撰写本文时)相比,它包含9500多个数据集。因此,您可以通过选择任何您感兴趣的数据集来提高您的技能。

我觉得最有趣的一些数据集
Kernels:
https://www.kaggle.com/kernels
它们只是Kaggle的Jupyter笔记本版本,反过来,它只是一种非常有效和酷炫的共享代码方式,以及大量的可视化,输出和解释。“内核”选项卡将您带到一个公共内核列表,人们用它来展示一些新工具或分享他们对某些特定数据集的专业知识或见解。
Learn:
https://www.kaggle.com/learn/overview
此选项卡包含免费且实用的实践课程, 这些课程涵盖了快速入门所需的最低前置课程。他们最好的地方是什么?——一切都是使用Kaggle的内核完成的(如上所述)。这意味着您可以互动和学习……通过数小时的学习材料不再被动阅读!

所有这些共同使Kaggle不仅仅是一个举办比赛的网站。现在,它已成为一个完整的基于项目的数据科学学习环境。在本节之后,我将详细讨论Kaggle的这个方面。
2. “只有专家(具有多年经验的博士或经验丰富的机器学习从业者)才能参加并赢得Kaggle比赛”

如果您这么认为,我恳请您阅读下面这篇文章:
高中生自学成为AI大神——如果你深入到人工智能的世界,你肯定知道谷歌云拥有的平台Kaggle:
https://mashable.com/2017/07/28/16-year-old-ai-genius/
觉得文章太长不想看的,可以浏览下面的文章摘要:
一个高中的孩子仅因为好奇并投入比赛就(或者不那么简单,或许?)成为了Kaggle比赛大神。用他自己的话说:
“我不知道算法背后的所有数学原理,但就实际使用算法而言,我认为对其运作方式有一个合理的了解更为重要。”
3. “在参加Kaggle比赛之前,我应该再参加一些课程并学习先进的机器学习概念,这样我的胜算更大”
机器学习中最重要的部分是探索数据分析(或EDA)和特征工程,而不是模型拟合。事实上,许多Kaggle大神认为,新人会很快掉进复杂的模型的坑里,而事实上简单的模型就可以让你走得很远。
爱因斯坦曾经说过:
“任何一个有智力的笨蛋都可以把事情搞得更大,更复杂。往相反的方向前进则需要天分,以及很大的勇气。”
此外,许多挑战都有结构化数据,这意味着所有数据都存在于整齐的行和列中。没有复杂的文本或图像数据。因此,简单的算法(没有花里胡哨的神经网络)通常是这种数据集的获胜算法。在这种情况下,EDA可能是获胜解决方案与其他解决方案的区别所在。
现在,让我们继续讨论为什么你应该使用Kaggle来入门机器学习或数据科学。
你为什么要从Kaggle开始?
理由1:准确了解入门必备内容
关于Kaggle Learn的机器学习课程不会教你机器学习算法背后的理论和数学。相反,它专注于仅教授在分析和建模数据集时绝对必要的事物。类似地,那里的Python课程不会让你成为Python的专家,但它将确保你了解足够知识以进入下一个级别。
关于Kaggle Learn的机器学习课程:
https://www.kaggle.com/learn/machine-learning
Python课程:
https://www.kaggle.com/learn/python
这样可以最大限度地减少您在被动学习中花费的时间,并确保您已准备好尽快应对有趣的挑战。
理由2:体现了注重实践的精神
我相信做项目是最有效的方式,完成一个项目,你就学会了整个过程。我的意思是说,不是在你学到东西之后搜索相关的项目,而是从项目开始并学习使项目变为现实所需的一切可能更好。
正如惠特尼约翰逊在Masters of Scale podcast中所说:
“基本上,你,我,每个人,我们都想学习,跳跃,然后重复。”
Masters of Scale podcast:
https://mastersofscale.com/stacy-brown-philpot-keep-humans-in-the-equation/
我相信学习这种方式更令人兴奋和有效。
几周前我写了一篇关于上述方法的文章。名为——“ 零基础如何(和为什么)开始构建有用的,现实世界的软件 ”。所以,如果你没有看过可以看一下:
https://medium.freecodecamp.org/how-and-why-to-start-building-useful-real-world-software-with-no-experience-46f265eaf38

我花了一番时间才承认只读一本书不是学习而是娱乐,我相信课程和教程也是如此
但是当你没有一个项目可以实践一波时,这个想法完全没用。做一个有趣的项目很难,因为:
a. 很难找到一个有趣的想法
由于需要有合适的数据集,因此实现数据科学项目的想法似乎更加困难。
b. 我不知道该怎么处理我的知识中的漏洞
有时当我开始某个项目时,感觉就像有很多东西我仍然不知道。我觉得我甚至不知道学习前置课程去构建这个东西的先决条件。我触及到知识盲区了吗?我如何去学习我不知道的东西?
那就是所有的动力开始消失的时候。
c. 我经常被“卡住”
似乎在构建过程中我在消除一个又一个路障。如果能有一群人一起学并知道如何解决这个问题,那就太好了。
以下是Kaggle如何为所有问题提供解决方案:
解决方案a:Datasets和Competitions :
https://www.kaggle.com/datasets
https://www.kaggle.com/competitions
大约有300个竞赛挑战,全部附带公共数据集,总共9500多个数据集(并且不断增加)这个地方就像是数据科学/机器学习项目的创意宝库。
解决方案b:Kernels和Learn :
https://www.kaggle.com/kernels
https://www.kaggle.com/learn/overview
让我告诉你Kernels是如何使用的。
所有数据集都有一个公共的Kernels选项卡,人们可以在这里发布他们的分析,以造福整个社区。因此,只要您不知道下一步该做什么,您就可以通过查看这些Kernels帖子来获得一些想法。此外,很多Kernels帖都是专为帮助初学者而编写的。
解决方案c:Kernels和Discussion :
https://www.kaggle.com/kernels
https://www.kaggle.com/discussion
除了我刚才描述的公共的Kernel之外,每个竞赛和每个数据集也都有自己的讨论论坛。所以,你总能找个一个提问的地方。
除此之外,在比赛期间,许多参与者撰写了有趣的问题,凸显了数据集的特征和怪癖,一些参与者甚至在论坛上发布了代码性能良好的基准。比赛结束后,获奖者分享他们的获奖方案是很常见的。
就像下面这篇文章写的“向最好的学习”:
http://blog.kaggle.com/2014/08/01/learning-from-the-best/
理由3:解决真实问题的真实数据=>真正的动机
Kaggle上的挑战是由为解决现实问题的公司举办的。他们提供的数据集是真实的。所有奖金都是真实的。这意味着您可以通过解决实际问题来学习数据科学/机器学习并练习您的技能。
如果您以前尝试过竞争性编程,那么当我说这些网站上承载的问题有时太不现实时,您可能会与我联系。我的意思是为什么我要编写一个程序来找出数组中毕达哥拉斯三元组的数量?那要实现什么!?
我并不想断言这些问题很容易;我发现它们非常困难。我也没想要降低托管此类问题的网站的重要性;它们是测试和改进数据结构和算法知识的好方法。
我只是说这对我来说太虚无缥缈了。当您尝试解决的问题是真实的时,您将始终希望努力改进您的解决方案。这将提供学习和成长的动力。这就是参加Kaggle挑战所能获得的。
争论的另一面:“机器学习不是Kaggle竞赛”
我将不再提及本次辩论的另一面,它认为机器学习不是Kaggle比赛,而且Kaggle比赛只代表了实际数据科学工作的“旅游观光”。
好吧,也许这是真的。也许真正的数据科学工作与Kaggle竞赛中的方法不同。我没有以专业的身份工作,所以我不知道如何评论。
但我所做的,很多时候,是使用教程和课程来学习一些东西。每一次,我觉得教程/课程与学习动机之间存在脱节。我会学到一些东西,因为它在教程/课程中存在,并希望它可以在一些遥远的,神秘的未来中使用。
另一方面,当我正在进行Kaggle挑战时,我确实需要不断学习。曾经有一个阶段,我会立即应用我学到的东西,看看它的效果。这给了我学习所有知识的动力和凝聚力。
如何开始?
Kaggle拥有所有那些有野心的现实世界的问题有一个缺点,它可能是初学者进入的一个令人生畏的地方。我理解这种感觉,因为我最近开始在Kaggle上入门。但是,一旦我克服了最初的障碍,我对它的社区以及它给我的学习机会感到非常景仰。
所以,在这里我试着说明如何开始:
第1步:掌握必要的基础知识
选择一种语言:Python或R语言。
完成后,请前往Kaggle Learn快速了解该语言的基础知识,机器学习和数据可视化技术。
Kaggle Learn:
https://www.kaggle.com/learn/overview
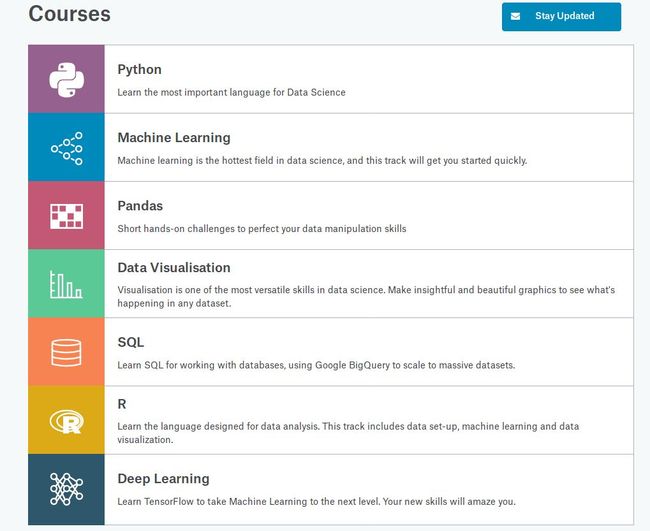
关于Kaggle Learn的课程
第2步:找到一个有趣的挑战/数据集
我建议您在开始时选择一个playground比赛或一个比较受欢迎的比赛。通过这种方式,您可以确保找到至少一些旨在帮助新手的公共Kernel帖子。
记住你的目标不是赢得比赛。它是学习和提高您的数据科学/机器学习的知识。
 如果您仍不确定,请任选其中一个
如果您仍不确定,请任选其中一个
第3步:探索公共内核
它们将帮助您了解该领域的一般工作流程以及其他人为此竞赛所采取的特定方法。
通常,这些内核会告诉您机器学习/数据科学中您不知道的内容。当你遇到一个不熟悉的术语时,不要感到沮丧。
了解您需要知道的是知识的第一步。
它们只是您需要学习以帮助您成长的东西。但在你这样做之前……
第4步:开发自己的Kernel
继续自己的分析工作。利用您当前的知识尽可能多地构建。将你在先前步骤中学到的所有内容应用到你自己的Kernel中。
第5步:了解您的需求并返回第4步
现在,你学习了。有时,它只是一篇短文,而在其他时候它可能是一个干货满满的教程/课程。请记住,您需要回到第3步并使用您在Kernel中学到的知识。这样您就可以创建所需的循环——“学习,跨越和重复”!
第6步:返回第3步以完善分析
一旦构建了完整的预测模型,就可以实现此步骤。所以,祝贺你!
现在您可能希望完善分析。要做到这一点,你可以回到第3步,看看其他人做了什么。这可以为您提供有关改进模型的想法。或者,如果你觉得你已经尝试了所有东西,但碰壁了,那么在论坛上寻求帮助可能会有所帮助。

这是一个讨论的例子
https://www.kaggle.com/c/amazon-employee-access-challenge/discussion/4838
棒!
现在去做更多挑战,分析更多数据集,学习更新的东西!
与其他资源的链接
1. 学习Python
Python已经变得非常受欢迎。这意味着有大量优秀的指南和教程可以帮助您开始使用该语言。这是我第一次学习Python时使用的两种资源:
Python3教程
https://www.python-course.eu/python3_interactive.php
从O'Reilly学习Python
http://shop.oreilly.com/product/0636920028154.do
显然,这些并没有为学习Python提供明确的资源列表,但这些是我入门时最适合我的资源。
2. 机器学习文章
在深入了解某个领域之前,您可能想知道它是什么。所以,这里有一些文章对机器学习进行了有趣的介绍:
EliteDataScience上的“如何学习机器学习之自学入门”一篇写得很好的文章,在介绍机器学习方面做得很好,甚至还开设了自学课程!
https://elitedatascience.com/learn-machine-learning
Vishal Maini的“人类学习机器学习指南”本指南旨在供任何人使用。将讨论概率、统计、编程、线性代数和微积分的基本概念,从本系列获得干货无需预备知识。”
https://medium.com/machine-learning-for-humans/why-machine-learning-matters-6164faf1df12
Vishal Maini的“最佳机器学习资源”本文是上述系列的一部分。我单独提到它是因为它有一套与机器学习相关的非常好非常全面的链接。
https://medium.com/machine-learning-for-humans/how-to-learn-machine-learning-24d53bb64aa1
Adam Geitgey的“机器学习很有趣”阅读本系列文章,了解机器学习的优点。虽然这篇比较高深,但它可以作为了解该领域的更多动力。
https://medium.com/@ageitgey
3. 数据科学博客
以下是一些与数据科学相关的好博客,您可以查看:
方差解释
http://varianceexplained.org/
成为一名数据科学家
https://www.becomingadatascientist.com
Mark Meloon
https://www.markmeloon.com/
Julia Silge
https://juliasilge.com/blog/
好吧那么。谢谢你的阅读。我希望这对你有所帮助。
我真的相信通过做项目来学习是一种非常有益的体验,但这很难。Kaggle让你轻松自如。Kaggle竞赛负责提出任务,为您获取数据,将其清理成一些可用的形式,并有一个预先定义的指标来优化。
但正如其他人所指出的那样,这是数据科学家80%的工作。所以,虽然Kaggle是一个开始你旅程的好工具,但仅仅把你带到最后是不够的。您需要在数据科学产品组合中展示其他内容。
如何构建数据科学产品组合:
https://towardsdatascience.com/how-to-build-a-data-science-portfolio-5f566517c79c
因此,我正在尝试创建一个社区——Build to Learn。在这里,人们可以分享他们的项目想法(欢迎稀奇古怪的想法!)或对工具的渴望,并在其他成员的帮助下构建它们。它是由Web开发人员,移动应用程序开发人员和机器学习工程师组成的社区。因此,无论您的想法或问题属于哪个领域,您都可以期待与其他成员一起获得至少一些帮助。
如果你想做一些有趣的辅助项目,但似乎无法得到一个有趣的想法,或者你有一个想法,但不知道从哪里开始,或者你只是被困在当前项目的某个地方,这种社区可能正是你所需要的。如果您觉得这很有趣,可以点击下方链接加入Slack。
Slack:
https://join.slack.com/t/build-to-learn/shared_invite/enQtMzg3MzYyNTA5MjAzLWU4M2RkOGY3OWE1OTE5NTIzMGQ5MzZhMmZmOWQyZDVhNWVkMmRjODc3ZWM5ZDA5MDM3YzRiZDM4YTczYTNmMDk
请在下面的评论部分告诉我您的想法。您也可以在Twitter或LinkedIn上与我联系。你可以给我发一封电子邮[email protected]。另外,你可以在Twitter上关注我;我不会发垃圾消息哒;-)
Twitter:
https://twitter.com/nityeshaga
LinkedIn:
https://www.linkedin.com/in/nityeshaga/
最初发表在Zeolearn博客上:
https://www.zeolearn.com/magazine/using-kaggle-to-guide-your-learning-why-and-how-should-you-start
原文标题:
Use Kaggle to start (and guide) your ML/ Data Science journey—Why and How
原文链接:
https://towardsdatascience.com/use-kaggle-to-start-and-guide-your-ml-data-science-journey-f09154baba35
译者简介

闫晓雨,本科毕业于北京林业大学,即将就读于南加州大学应用生物统计与流行病硕士项目。继续在生统道路上摸爬滚打,热爱数据,期待未来。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织