ELK 分布式日志收集分析系统记录
ELK = elasticsreach + logstash + kibana + beats
也称为 : ELK Stack, 是因为加入了 beats.

elasticsreach : 分布式全文检索引擎。

logstash: 日志的收集,过滤, 分析。
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中

kibana: 可视化界面操作工具。

beats: 组件包


首先需要装好 es + kibana环境
这是我前一篇文章搭建es+kibana.
https://blog.csdn.net/tang_jian_dong/article/details/104446526
ELK 原理图:

下载 logstash: 对应es版本。 或者直接yum安装, 或者docker安装在官网都有说明的。
https://www.elastic.co/cn/downloads/past-releases/logstash-7-6-0
下载 beats:
nohup ./filebeat -e -c filebeat.yml -d "publish" > filebeat.log &
https://www.elastic.co/cn/downloads/beats
上传至目录后解压: tar -zxvf logstash-7.6.0.tar.gz
上传至目录后解压: tar -zxvf filebeat-7.7.0-linux-x86_64.tar.gz

1: 先配置filebeat, 可以读取单个日志文件, 也可以读取目录
input: 日志文件或目录路径

output: 输出到 elasticsearch 或者 logstash, 我是输出到logstash

启动: filebeat , 将日志输入到 filebeat.log中
nohup ./filebeat -e -c filebeat.yml -d "publish" > filebeat.log &
2: 配置 logstash
/software/es/logstash-7.6.0/config
新增: first-pipeline.conf, 加入如下内容
input {
beats {
#数据来自 filebeat
port => "5044"
codec => "json"
id => "filebeat"
}
}
filter {
#grok过滤器插件,可以将非结构化日志数据解析为结构化和可查询的内容
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
#geoip插件查找IP地址,从地址中获取地理位置信息,然后将该位置信息添加到日志中
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
#数据输出到es保存
elasticsearch {
hosts => [ "IP:9200" ]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
启动:进入 logstash 的bin目录 : /software/es/logstash-7.6.0/bin
执行如下命令启动:
nohup ./logstash -f ../config/first-pipeline.conf > logstash.log &
启动成功: successfully

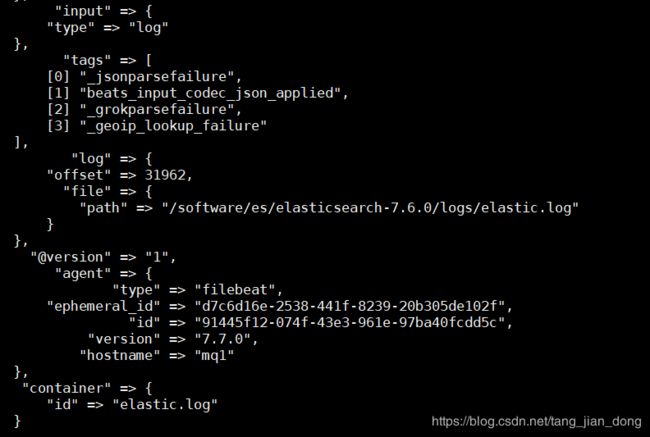
logstash 显示读取的日志:
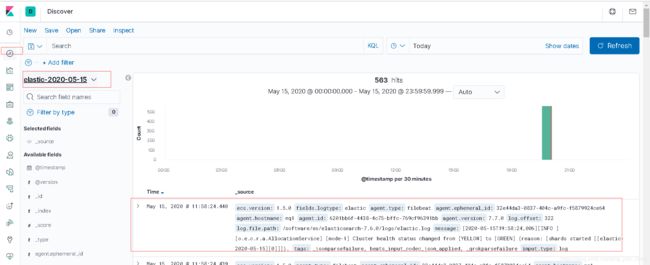
kibana 查看logstash传输的数据: