python模拟登陆淘宝(更新版)
python模拟登录淘宝,获取cookies,含sign参数破解(新)
-
旧版方法总结
- 流程繁琐
- 需要操作外部工具fildder,方便性差
- 理解略显困难
- 成功率不足
-
新版两种方法
1 扫码登陆:操作简便,结果可直接使用
主要思路:使用selenium打开淘宝登录网址,切换至二维码,然后扫码登录。
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: sweep_QuickMark_login.py
Description :
Author : tao
date: 2019/8/10
-------------------------------------------------
Change Activity:
-------------------------------------------------
"""
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
class SessionException(Exception):
def __init__(self, message):
super().__init__(self)
self.message = message
def __str__(self):
return self.message
class login():
def __init__(self):
self.browser = None
self.wait = WebDriverWait(self.browser, 10)
def start(self):
self.__init__browser()
self.browser.get(setting.TB_LOGIN_URL)
self.browser.implicitly_wait(10) # 智能等待,直到网页加载完毕,
print('Please scan the qr code!')
# 等待扫描二维码
while True:
qr_code = self.__is_element_exist('#J_QRCodeImg') # 二维码是否存在
login_button = self.__is_element_exist('.J_Submit') # 登陆按钮是否存在
serach_button = self.__is_element_exist('.btn-search.tb-bg') # 登陆后搜索商品按钮是否存在
# 二维码存在,登录按钮存在,登陆后的搜索商品按钮不存在,判定为扫码未完成,继续等待扫码
if qr_code and login_button and not serach_button:
continue
else:
break
time.sleep(1) # 每隔1s检测一次是否扫描二维码
cookie = self.browser.get_cookies()
return cookie
def __init__browser(self):
"""初始化浏览器"""
options = Options()
# options.add_argument("--headless")
prefs = {"profile.managed_default_content_settings.images": 1}
options.add_experimental_option("prefs", prefs)
# options.add_argument('--proxy-server=http://127.0.0.1:9000')
options.add_argument('disable-infobars')
options.add_argument('--no-sandbox')
self.browser = webdriver.Chrome(executable_path=setting.CHROME_DRIVER_PATH, options=options)
self.browser.implicitly_wait(3)
self.browser.maximize_window()
def __is_element_exist(self, selector):
"""检查是否存在指定元素"""
try:
self.browser.find_element_by_css_selector(selector)
return True
except NoSuchElementException:
return False
if __name__ == '__main__':
cookie = login().start()
2 例用mitmdump登录,并破解sign参数
主要思路
(1)mitmdump拦截登录请求,获取cookies信息
①编写mitmdump拦截函数:
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: login.py
Description :
Author : tao
date: 2019/8/10
-------------------------------------------------
Change Activity:
-------------------------------------------------
"""
import json
def response(flow):
"""
instruction:
1.at current directory and open terminal and input command
mitmdump -s login.py
2.open url and login
https://login.m.taobao.com/login.htm?_input_charset=utf-8
"""
url = 'https://login.m.taobao.com/login.htm?_input_charset=utf-8'
if url in flow.request.url:
cookie = flow.request.headers
# 将登陆后的请求头信息存入request_headers.json
with open('request_headers.json', 'w') as f:
f.write(json.dumps(dict(cookie)))
f.flush()
②使用命令mitmdump -s login.py,运行程序
③配置谷歌浏览器代理,是mitmdump可以在本地抓包,具体配置如下两张图:
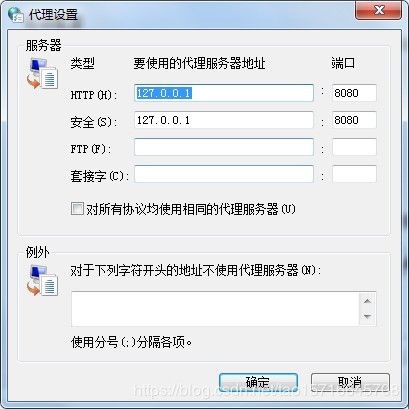
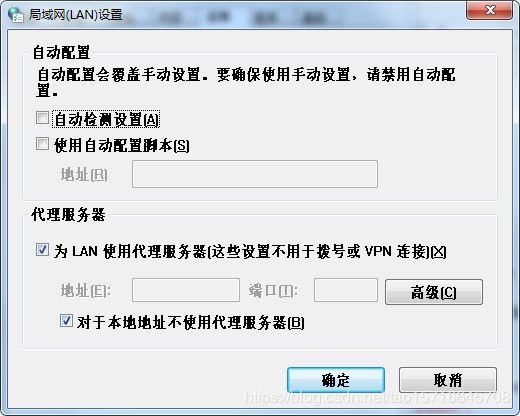
④打开网址https://login.m.taobao.com/login.htm?_input_charset=utf-8,登陆即可。
(2)从已获取的cookies信息中提取相应元素,构造淘宝sign参数
sign的生成公式为md5Hex(token&t&时间戳&appKey&data),因此构造token,appKey,data,时间戳四个参数即可。(以爬取该店铺第一页商品为例:https://skin79.tmall.com/shop/view_shop.htm)
data参数
data = """{"m":"shopitemsearch","vm":"nw","sversion":"4.6","shopId":"135330822","sellerId":"2395131222","style":"wf","page":1,"sort":"_coefp","catmap":"","wirelessShopCategoryList":""}"""
token参数
import re
def _m_h5_tk_cookie(self):
# 读取前文提到所获取到的cookies文件,提取token
with open('request_headers.json', 'r') as f:
json_obj = json.loads(f.read())
cookie = json_obj['cookie']
# print(cookie)
__m_h5_tk = [_m for _m in cookie.split(';') if '_m_h5_tk=' in _m][0]
_m_h5_tk = re.findall(r'_m_h5_tk=(.*?)_', __m_h5_tk)[0]
return _m_h5_tk
appKey参数
"""
通过抓包,拿到get所需的参数,此参数含appKey
"""
params= {
'jsv': '2.3.16',
'appKey': '12574478', # appKey就在此处
't': str(int(time.time() * 1000)),
'api': 'mtop.taobao.wsearch.h5search',
'v': '1.0',
'H5Request': 'true',
'ecode': '1',
'AntiCreep': 'true',
'AntiFlool': 'true',
'type': 'jsonp',
'dataType': 'jsonp',
'callback': 'mtopjsonp1',
'data': data,
}
时间戳参数
import time
timestamp = str(int(time.time()*1000))
生成sign
import hashlib
sign_str = '%s&%s&%s&%s'%(token, timestamp , appKey, data)
def sign(self, sign_str):
"""
整合得到的四个参数,生成sign参数(通过分析得知sign是md5加密)
:return sign
"""
md5_obj = hashlib.md5()
md5_obj.update(sign_str.encode("utf-8"))
return md5_obj.hexdigest()
发起requests请求,获取数据
import json
import requests
import fake_useragent
params = params.update({'sign': sign})
url = "https://h5api.m.taobao.com/h5/mtop.taobao.wsearch.appsearch/1.0/"
data_obj = json.loads(data)
headers = {
'User-Agent': fake_useragent.UserAgent().random, # 随机请求头
'Accept': '*/*',
'Connection': 'keep-alive',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Referer': 'https://market.m.taobao.com/app/tb-source-app/shop-auction/pages/auction?_w&sellerId=%s&shopId=%s&disablePromotionTips=false&shop_navi=allitems&displayShopHeader=true'%(data_obj ['sellerId'], data_obj ['shopId']),
}
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
response = requests.get(url, headers=headers, params=params, verify=False, timeout=5)
text = response.text