Flink 1.9.0及更高版本支持Python,也就是PyFlink。
在最新版本的Flink 1.10中,PyFlink支持Python用户定义的函数,使您能够在Table API和SQL中注册和使用这些函数。但是,听完所有这些后,您可能仍然想知道PyFlink的架构到底是什么?作为PyFlink的快速指南,本文将回答这些问题。
为什么需要PyFlink?
Python上的Flink和Flink上的Python
那么,PyFlink到底是什么?顾名思义,PyFlink就是Apache Flink与Python的组合,或者说是Python上的Flink。但是Flink on Python是什么意思?首先,两者的结合意味着您可以在Python中使用Flink的所有功能。而且,更重要的是,PyFlink还允许您在Flink上使用Python广泛的生态系统的计算功能,从而可以进一步促进其生态系统的开发。换句话说,这对双方都是双赢。如果您更深入地研究这个主题,您会发现Flink框架和Python语言的集成绝不是巧合。

Python和大数据生态系统
python语言与大数据紧密相连。为了理解这一点,我们可以看一下人们正在使用Python解决的一些实际问题。一项用户调查显示,大多数人都在使用Python进行数据分析和机器学习应用程序。对于此类情况,大数据空间中还解决了一些理想的解决方案。除了扩大大数据产品的受众范围之外,Python和大数据的集成还通过将其独立体系结构扩展到分布式体系结构,极大地增强了Python生态系统的功能。这也解释了在分析大量数据时对Python的强烈需求。

为什么选择Flink和Python?
Python和大数据的集成与其他最近的趋势一致。但是,再次说明一下,为什么Flink现在支持Python,而不是Go或R或另一种语言?而且,为什么大多数用户选择PyFlink而不是PySpark和PyHive?
为了理解原因,让我们首先考虑使用Flink框架的一些优势:
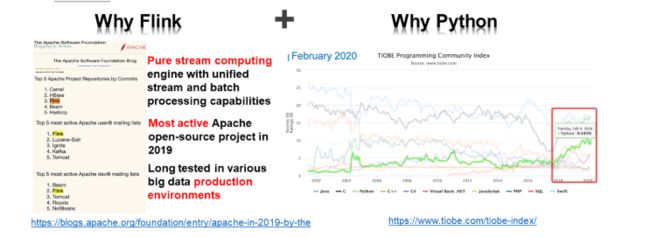
- 有利的体系结构: Flink是具有统一流和批处理功能的纯流计算引擎。
- 新的活力:根据ASF的客观统计,Flink是2019年最活跃的开源项目。
- 高可靠性:作为一个开源项目,Flink经过长期测试,并广泛应用于大数据公司的生产环境中。
接下来,让我们看看为什么Flink支持Python而不是其他语言。统计数据显示,Python是继Java和C之后最受欢迎的语言,并且自2018年以来一直在快速发展。Java和Scala是Flink的默认语言,但是Flink支持Python似乎是合理的。
PyFlink是相关技术发展的必然产物。但是,仅仅了解PyFlink的重要性是不够的,因为我们的最终目标是使Flink和Python用户受益并解决实际问题。因此,我们需要进一步探索如何实现PyFlink。
PyFlink架构
要实现PyFlink,我们需要知道要实现的关键目标和要解决的核心问题。PyFlink的主要目标是什么?简而言之,PyFlink的主要目标如下:
- 使所有Flink功能对Python用户可用。
- 在Flink上运行Python的分析和计算功能,以提高Python解决大数据问题的能力。
在此基础上,让我们分析实现这些目标需要解决的关键问题。

使Flink功能可供Python用户使用
要实现PyFlink,是否需要像现有Java引擎一样在Flink上开发Python引擎?答案是NO。尝试在Flink 1.8版或更早版本中进行,但效果不佳。基本设计原则是以最小的成本实现给定的目标。最简单但最好的方法是提供一层Python API,并重用现有的计算引擎。
那么,我们应该为Flink提供哪些Python API?他们对我们很熟悉:高级表API和SQL,以及有状态的DataStream API。现在,我们越来越接近Flink的内部逻辑,下一步是提供适用于Python的Table API和DataStream API。但是,剩下要解决的关键问题到底是什么呢?

关键问题
显然,关键问题在于在Python虚拟机(PyVM)和Java虚拟机(JVM)之间建立握手,这对于Flink支持多种语言至关重要。要解决此问题,我们必须选择适当的通信技术。

选择虚拟机通信技术
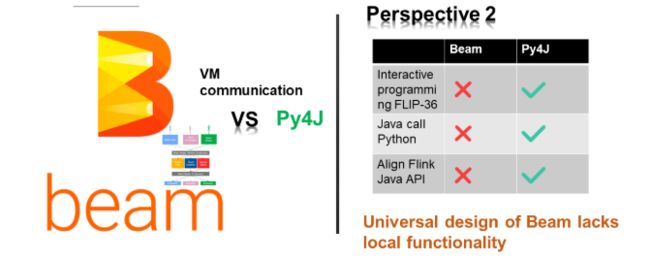
当前,有两种解决方案可用于实现PyVM和JVM之间的通信,它们是Beam和Py4J。前者是一个著名的项目,具有多语言和多引擎支持,而后者是用于PyVM和JVM之间通信的专用解决方案。我们可以从几个不同的角度比较和对比Apache Beam和Py4J,以了解它们之间的区别。首先,考虑一个比喻:要越过一堵墙,Py4J会像痣一样在其中挖一个洞,而Apache Beam会像大熊一样把整堵墙推倒。从这个角度来看,使用Apache Beam来实现VM通信有点复杂。简而言之,这是因为Apache Beam专注于通用性,在极端情况下缺乏灵活性。

除此之外,Flink还需要交互式编程。此外,为了使Flink正常工作,我们还需要确保其API设计中的语义一致性,尤其是在其多语言支持方面。Apache Beam的现有体系结构无法满足这些要求,因此答案很明显,Py4J是支持PyVM和JVM之间通信的最佳选择。
技术架构
在PyVM和JVM之间建立通信之后,我们已经实现了向Python用户提供Flink功能的第一个目标。我们已经在Flink 1.9版中实现了这一点。现在,让我们看一下Flink 1.9版中PyFlink API的体系结构:
Flink 1.9版使用Py4J来实现虚拟机通信。我们为PyVM启用了网关,为JVM启用了网关服务器以接收Python请求。此外,我们还提供了Python API中的TableENV和Table之类的对象,这些对象与Java API中提供的对象相同。因此,编写Python API的本质是关于如何调用Java API。Flink 1.9版还解决了作业部署问题。它使您可以通过各种方式提交作业,例如运行Python命令以及使用Python Shell和CLI。

但是,此体系结构提供了哪些优势?首先,该体系结构很简单,并且可以确保Python API和Java API之间的语义一致性。其次,它还提供了与Java作业相当的出色Python作业处理性能。
在Flink上运行Python的分析和计算功能
上一节介绍了如何使Flink功能可供Python用户使用。本节说明如何在Flink上运行Python函数。通常,我们可以通过以下两种方式之一在Flink上运行Python函数:
- 选择一个典型的Python类库,并将其API添加到PyFlink。该方法花费很长时间,因为Python包含太多的类库。在合并任何API之前,我们需要简化Python执行。
- 基于现有的Flink Table API和Python类库的特征,我们可以将所有现有的Python类库函数视为用户定义的函数,并将其集成到Flink中。Flink 1.10及更高版本中支持此功能。功能集成的关键问题是什么?同样,它取决于Python用户定义函数的执行。
接下来,让我们为这个关键问题选择一种技术。

选择执行用户定义功能的技术
实际上,执行Python用户定义的函数非常复杂。它不仅涉及虚拟机之间的通信,还涉及以下所有方面:管理Python执行环境,解析Java和Python之间交换的业务数据,将Flink中的状态后端传递给Python以及监视执行状态。鉴于所有这些复杂性,现在是Apache Beam发挥作用的时候了。作为支持多种引擎和多种语言的大熊,Apache Beam可以在解决这种情况方面做很多工作,所以让我们看看Apache Beam如何处理执行Python用户定义的函数。
下面显示了可移植性框架,该框架是Apache Beam的高度抽象的体系结构,旨在支持多种语言和引擎。当前,Apache Beam支持几种不同的语言,包括Java,Go和Python。
用户定义的功能架构
UDF体系结构不仅需要实现PyVM与JVM之间的通信,还需要在编译和运行阶段满足不同的要求。在下面的PyLink用户定义功能架构图中,JVM中的行为以绿色表示,而PyVM中的行为以蓝色表示。让我们看看编译期间的局部设计。本地设计依赖于纯API映射调用。Py4J用于VM通信。
现在,让我们看看Python API和Java API在此架构中的工作方式。在Java方面,JobMaster将作业分配给TaskManager,就像处理普通Java作业一样,并且TaskManager执行任务,这涉及到操作员在JVM和PyVM中的执行。在Python用户定义的函数运算符中,我们将设计各种gRPC服务,用于JVM和PyVM之间的通信。例如,用于业务数据通信的DataService和用于Python UDF的StateService来调用Java State后端。还将提供许多其他服务,例如日志记录和指标。
我们如何使用PyFlink?
了解了PyFlink的体系结构及其背后的思想之后,我们来看一下PyFlink的特定应用场景,以更好地了解其背后的方式和原因。
PyFlink的应用场景
PyFlink支持哪些业务方案?我们可以从两个角度分析其应用场景:Python和Java。请记住,PyFlink也适用于Java可以应用的所有情况。
- 事件驱动的方案,例如实时数据监控。
- 数据分析,例如库存管理和数据可视化。
- 数据管道,也称为ETL方案,例如日志解析。
- 机器学习,例如有针对性的建议。
您可以在所有这些情况下使用PyFlink。PyFlink也适用于特定于Python的方案,例如科学计算。在如此众多的应用场景中,您可能想知道现在可以使用哪些特定的PyFlink API。因此,现在我们也来研究这个问题。

PyFlink安装
在使用任何API之前,您需要安装PyFlink。当前,要安装PyFlink,请运行命令:pip install apache-Flink
PyFlink API
PyFlink API与Java Table API完全一致,以支持各种关系和窗口操作。某些易于使用的PyFlink API比SQL API更为强大,例如特定于列操作的API。除了API,PyFlink还提供了多种定义Python UDF的方法。

PyFlink中用户定义的函数定义
可以扩展ScalarFunction(例如,通过添加指标)以提供更多辅助功能。另外,PyFlink用户功能函数支持Python支持的所有方法定义,例如lambda,命名函数和可调用函数。
定义完这些方法后,我们可以使用PyFlink Decorators进行标记,并描述输入和输出数据类型。我们还可以基于Python的类型提示功能进一步简化更高版本,以进行类型派生。以下示例将帮助您更好地了解如何定义用户定义的函数。

定义Python用户定义函数的一种情况
在本例中,我们将两个数字相加。首先,为此,导入必要的类,然后定义前面提到的函数。这非常简单,因此让我们进行一个实际案例。

PyFlink的未来前景如何?
通常,使用PyFlink进行业务开发很简单。您可以通过SQL或Table API轻松描述业务逻辑,而无需了解基础实现。让我们看一下PyFlink的整体前景。
目标驱动路线图
PyFlink的开发始终受到目标的推动,这些目标是使Flink功能可供Python用户使用并将Python函数集成到Flink中。根据下面显示的PyFlink路线图,我们首先在PyVM和JVM之间建立了通信。然后,在Flink 1.9中,我们提供了Python Table API,向Python用户开放了现有的Flink Table API功能。在Flink 1.10中,我们准备通过以下操作将Python函数集成到Flink:集成Apache Beam,设置Python用户定义的函数执行环境,管理Python对其他类库的依赖关系以及为用户定义用户定义的函数API,以便支持Python用户定义函数。
为了扩展分布式Python的功能,PyFlink提供了对Pandas Series和DataFrame支持,以便用户可以在PyFlink中直接使用Pandas用户定义的函数。此外,将来会在SQL客户端上启用Python用户定义函数,以使PyFlink易于使用。PyFlink还将提供Python ML管道API,以使Python用户能够在机器学习中使用PyFlink。监视Python用户定义的函数执行对实际生产和业务至关重要。因此,PyFlink将进一步为Python用户定义函数提供度量管理。这些功能将包含在Flink 1.11中。
但是,这些只是PyFlink未来发展计划的一部分。还有更多工作要做,例如优化PyFlink的性能,提供图形计算API以及为Flink上的Pandas支持Pandas的本机API。我们将继续向Python用户提供Flink的现有功能,并将Python的强大功能集成到Flink中,以实现扩展Python生态系统的最初目标。

PyFlink的前景如何?您可能知道,PyFlink是Apache Flink的一部分,它涉及运行时和API层。
PyFlink在这两层将如何发展?在运行时方面,PyFlink将构建用于JVM和PyVM之间通信的gRPC常规服务(例如控件,数据和状态)。在此框架中,将抽象化Java Python用户定义函数运算符,并构建Python执行容器以支持Python的多种执行方式。例如,PyFlink可以在Docker容器中甚至在外部服务集群中作为进程运行。特别是在外部服务群集中运行时,将以套接字的形式启用无限扩展功能。这一切在后续的Python集成中都起着至关重要的作用。
在API方面,我们将在Flink中启用基于Python的API,以实现我们的使命。这也依赖于Py4J VM通信框架。PyFlink将逐渐支持更多的API,包括Flink中的Java API(例如Python Table API,UDX,ML Pipeline,DataStream,CEP,Gelly和State API)以及在Python用户中最受欢迎的Pandas API。基于这些API,PyFlink将继续与其他生态系统集成以便于开发;例如Notebook,Zeppelin,Jupyter和Alink,这是阿里巴巴的Flink开源版本。到目前为止,PyAlink已完全整合了PyFlink的功能。PyFlink也将与现有的AI系统平台集成,例如著名的TensorFlow。
为此,PyFlink将一直保持活力。同样,PyFlink的任务是使Flink功能可供Python用户使用,并在Flink上运行Python分析和计算功能。
更多实时数据分析相关博文与科技资讯,欢迎关注 “实时流式计算”
关注 “实时流式计算” 回复 “电子书” 获取Flink 300页实战电子书