错误DateTimeParseException could not be parsed at index 0
今天我github下载一个java8-tutoriak时候,偶然发现一个问题
这个是对应连接https://github.com/winterbe/java8-tutorial
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("MMM dd,yyyy - HH:mm");
/**
* Exception in thread "main" java.time.format.DateTimeParseException:
* Text 'Nov 03,2014 - 07:13' could not be parsed at index 0
*/
LocalDateTime parsed = LocalDateTime.parse("Nov 03,2014 - 07:13", formatter);
String string = parsed.format(formatter);
System.out.println(string); // Nov 03, 2014 - 07:13于是我在stackoverflow和bugopenjdk在查找答案
首先在https://bugs.openjdk.java.net/browse/JDK-8031085中发现类似问题如下
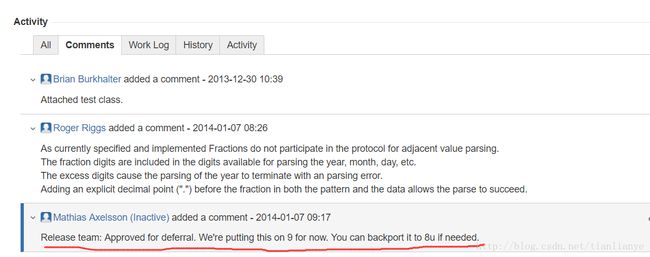
团队给出解释的是,问题会在9版本解决
//我测试过它的情况,如果使用JDK8执行会报错.9则没有问题
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyyMMddHHmmssSSS");
TemporalAccessor parse = dateTimeFormatter.parse("20130812214600025");
System.out.println(parse);
System.out.println(dateTimeFormatter.format(parse));但是我们的问题没有解决:于是我们DEBUG JDK查看数据流向,大家直接看有注释的语句就可以了
//第一步:这里的parse方法为我们的入口parse
LocalDateTime parsed = LocalDateTime.parse("Nov 03,2014 - 07:13", formatter);
//第二步:以下为JDK源码,LocalDateTime的parse方法
public static LocalDateTime parse(CharSequence text, DateTimeFormatter formatter) {
//校验非空
Objects.requireNonNull(formatter, "formatter");
//调用了formatter的parse方法,传入text与一个lamda表达式
return formatter.parse(text, LocalDateTime::from);
//第三步:我们进入到formatter的parse方法
public T parse(CharSequence text, TemporalQuery query) {
//非空校验
Objects.requireNonNull(text, "text");
Objects.requireNonNull(query, "query");
try {
//这里catch了异常,说明出错可能就是这里
//主要是看这里的传的第二个参数是null
return parseResolved0(text, null).query(query);
} catch (DateTimeParseException ex) {
throw ex;
} catch (RuntimeException ex) {
throw createError(text, ex);
}
}
}
//第四步:核心步骤,formatter的parseResolved0方法,请按照数组排序理清思路
//介绍一下ParsePosition参数的意义代表当前解析的位置
private TemporalAccessor parseResolved0(final CharSequence text, final ParsePosition position) {
//1.因为这里position是null,所以可以直接等于ParsePosition pos = new ParsePosition(0))
ParsePosition pos = (position != null ? position : new ParsePosition(0));
//3.此处传入pos进入此方法看看
DateTimeParseContext context = parseUnresolved0(text, pos);
if (context == null || pos.getErrorIndex() >= 0 || (position == null && pos.getIndex() < text.length())) {
String abbr;
if (text.length() > 64) {
abbr = text.subSequence(0, 64).toString() + "...";
} else {
abbr = text.toString();
}
//2.此处可以知道ErrorIndex大于0则会抛出异常,且pos只有在parseUnresolved0方法中被赋值
if (pos.getErrorIndex() >= 0) {
throw new DateTimeParseException("Text '" + abbr + "' could not be parsed at index " +
pos.getErrorIndex(), text, pos.getErrorIndex());
} else {
throw new DateTimeParseException("Text '" + abbr + "' could not be parsed, unparsed text found at index " +
pos.getIndex(), text, pos.getIndex());
}
}
return context.toResolved(resolverStyle, resolverFields);
}
//第五步
private DateTimeParseContext parseUnresolved0(CharSequence text, ParsePosition position) {
Objects.requireNonNull(text, "text");
Objects.requireNonNull(position, "position");
DateTimeParseContext context = new DateTimeParseContext(this);
int pos = position.getIndex();//这里的值是0
//此处赋值pos,进入此方法
pos = printerParser.parse(context, text, pos);
if (pos < 0) {
position.setErrorIndex(~pos); //按位取反
return null;
}
position.setIndex(pos); // errorIndex not updated from input
return context;
}
//最后一步:
@Override
public int parse(DateTimeParseContext context, CharSequence text, int position) {
if (optional) {
context.startOptional();
int pos = position;
for (DateTimePrinterParser pp : printerParsers) {
//循环解析,流程调制图后下一处代码
pos = pp.parse(context, text, pos);
if (pos < 0) {
context.endOptional(false);
return position; // return original position
}
}
context.endOptional(true);
return pos;
} else {//走的else,printerParsers是一个DateTimePrinterParser[]数组,它的信息在注图1:
for (DateTimePrinterParser pp : printerParsers) {
position = pp.parse(context, text, position);
if (position < 0) {
break;
}
}
return position;
}
} 注图1:
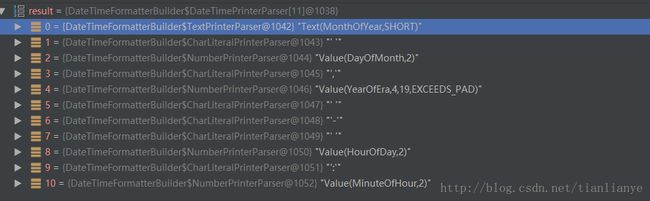
我们可以在知道printerParsers的组成
[0]—>一年中的哪一个月
[1]—>空格
[2]—>本月的哪一天
[3]—>逗号
[4]—>年
[5]—>空格
[6]—>短话线
[7]—>空格
[8]—>小时
[9]—>:
[10]—>分钟
public int parse(DateTimeParseContext context, CharSequence parseText, int position) {
int length = parseText.length();//Nov 03,2014 - 07:13有19个长度
if (position < 0 || position > length) {
throw new IndexOutOfBoundsException();
}
//获取text类型
TextStyle style = (context.isStrict() ? textStyle : null);
//ISO
Chronology chrono = context.getEffectiveChronology();
Iterator> it;
if (chrono == null || chrono == IsoChronology.INSTANCE) {
it = provider.getTextIterator(field, style, context.getLocale());
} else {
it = provider.getTextIterator(chrono, field, style, context.getLocale());
}
//it里面存的是1月~12月
if (it != null) {
while (it.hasNext()) {
Entry entry = it.next();
String itText = entry.getKey();
//这里应该return的,当是11月的时候,我们进入此方法观察
if (context.subSequenceEquals(itText, 0, parseText, position, itText.length())) {
return context.setParsedField(field, entry.getValue(), position, position + itText.length());
}
}
if (field == ERA && !context.isStrict()) {
// parse the possible era name from era.toString()
List eras = chrono.eras();
for (Era era : eras) {
String name = era.toString();
if (context.subSequenceEquals(name, 0, parseText, position, name.length())) {
return context.setParsedField(field, era.getValue(), position, position + name.length());
}
}
}
if (context.isStrict()) {
return ~position;
}
}
return numberPrinterParser().parse(context, parseText, position);
} 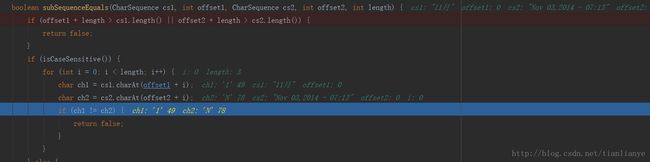
这里我们发现他是将Nov与11月进行字符串对比,这个肯定返回false的
结论:最后发现自己真的愚蠢,Nov是按照英系来计算的,在formatter的时候,JVM会自动加载出自己的时区,并按照此时区进行字符串对比,所以将最开始的Nov换成11月就可以了,也当长个教训吧