python scrapy框架使用入门
Scrapy是Python 写的一个爬虫框架
基本流程如下图:
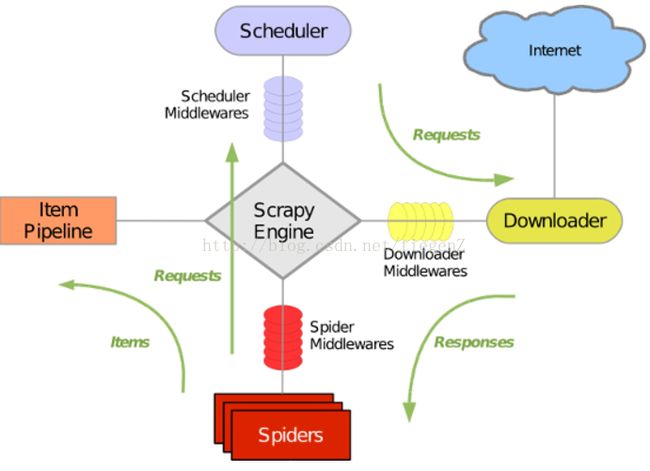
首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载完之后会交给Spider进行分析,Spider 分析出来的结果有两种:
一种是需要进一步抓取的链接,例如“下一页”的链接,这类东西会被回传给 Scheduler
另一种是需要保存的数据,它们则会被送到Item Pipeline那里,再对数据进行后期处理:详细分析、过滤、存储等
使用Scrapy抓取一个网站一共需要四个步骤:
1.创建一个Scrapy项目 Scrapy startproject +项目名
2.定义Item容器 Item是保存爬取到的数据的容器,其使用方法和python字典类似
并提供了额外的保护机制来避免拼写错误导致的未定义字段错误
3.编写爬虫
4.存储内容
---------------------------利用Scrapy爬取csdn我的博客页面 中的文章标题以及链接地址-----------------------------
1.创建一个Scrapy项目
在cmd窗口中执行命令:Scrapy startproject csdnScrapy
csdnScrapy 即项目名

2.定义Item容器
找到项目 csdnScrapy\csdnScrapy文件下的items.py文件
打开后如图

在其中定义 title 以及 link 用于存储标题 以及链接地址
import scrapy
class CsdnscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
3.编写爬虫
在项目 csdnScrapy\csdnScrapy\spiders 文件下新建一个csdn_spider.py文件(一般创建爬虫文件时,以网站域名命名)
csdn_spider.py文件 代码如下
#coding:utf-8
import scrapy
from csdnScrapy.items import CsdnscrapyItem #items文件中的CsdnscrapyItem方法
class CsdnSpider(scrapy.Spider): #必须继承scrapy.Spider
name="csdn" #定义了爬虫的名字,项目启动时需要用到
allowed_domains=['csdn.net'] #规划爬虫爬取范围
start_urls = ['http://blog.csdn.net/tiegenz'] #定义爬虫爬取开始页面
def parse(self,response): # 定义了分析规则通过xpath精确定位我们需要的内容的位置,提取我们需要的部分,再放入item中,再返回item
sel=scrapy.selector.Selector(response)
sites= sel.xpath('//span[@class="link_title"]/a')
items = []
for site in sites :
item = CsdnscrapyItem() #存储内容
item['title'] = site.xpath('text()').extract()
item['link'] = site.xpath('@href').extract()
items.append(item)
return items
启动项目 :
在项目目录下打开cmd窗口执行 命令: scrapy crawl csdn -o csdn.json -t json
注:scrapy crawl 爬虫名 -o 数据存储的文件名 -t 数据存储格式
执行命令后,你会发现在你的项目目录下多了一个 csdn.json 文件
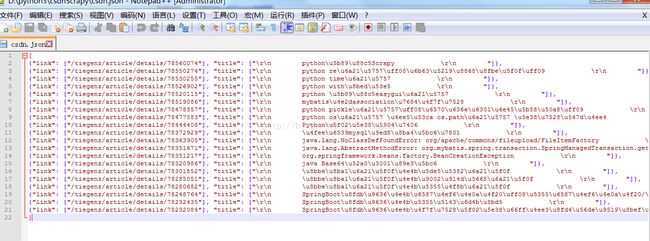
这个文件即保存着爬取到的所有数据 :标题以及链接地址(标题编码问题未处理中文都转成unicode格式了)
数据存储格式常用的有: json 、 csv 、xml
附:该项目中用到命令
# scrapy crawl csdn 运行编写的爬虫
# scrapy shell "爬取的网址"
# response.body
# response.xpath('//标签名') 返回
#response.xpath('//标签名/text()').extract() 以字符串的形式返回标签中的文本
# response.xpath('//span/a') 返回所有span标签下的a标签
#response.xpath('//span/a/text()').extract() 以字符串的方式返回所有span标签下的a标签中的文本
#response.xpath('//span/a/@href').extract() 以字符串的方式返回所有span标签下的a标签中的href属性
#response.xpath('//span[@class="link_title"]/a') 属性class="link_title"的span标签下的a标签
#scrapy crawl csdn -o items.json -t json 设置保存的文件名以及保存的文件格式
-------------------------------------------------- Scrapy Selectors ---------------------------------------------------------
在Scrapy中是使用一种基于XPath和CSS的表达式机制 : Scrapy Selectors
Selector是一个选择器,它有四个基本的方法:
xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
css() : 传入CSS表达式,返回该表达式所对应的所有节点的 selector list列表
extract(): 序列化该节点为unicode字符串并返回list
re():根据传入的正则表达式对数据进行提取,返回 unicode字符串list列表
XPath 是一门在网页中查找特定信息的语言。所以使用XPath筛选数据比正则更简单
-------------------------------------------------------------------------------------------------------------------------------------
Scrapy内部支持更简单的查询语法,帮助我们在html中查询我们需要的标签和标签内容以及标签属性。
下面以span标签为例:
//span 表示查询某个标签的所有span标签
/span 表示查询某个标签的儿子
//span[@class='link_title'] 表示找到所有的属性为class='link_title'的span标签
//span[@class='link_title']/a 表示找到这个span的所有a标签
//span[@class='link_title']//a 表示找在这个span下的所有a标签
//span[@class='link_title']//a/text() 表示找在这个span下的所有a标签并获得所有a标签的内容
//span[@class='link_title']//a/@href 表示找在这个span下的所有a标签并获得所有a标签的href属性