第2章-回归模型(2)-模型诊断
简介
上一节,我们研究了回归模型的线性定义,假设条件,参数估计,以及基于统计学检验的模型评价。但是这并不是意味着我们的回归模型以及可以投入使用,进行决策了。我们还需要在计量经济学的基础上验证模型,当模型出现多重共线性、异方差、序列相关等等问题时,我们需要如何应对与处理。
接下来我们来分别针对不同的情况看进行处理
正文
一,异方差(Heteroscedasticity)
(一) 异方差的介绍
在线性回归模型中,我们假定残差项是同方差的,如果该假定明显背离真实值,则
残差的正态分布假设也将失效。因此通常带来一些问题:
- 参数估计的有效性和渐近线失效
- 参数的显著性检验实效
- 回归方程应用效果极不理想
(二) 异方差的诊断
1,图示法
构建残差图 Y-e
2,假设检验
(1)Halbort White检验
如果存在异方差,说明回归残差项与解释变量X存在某些形式的联系
那么用残差平方对解释变量X,以及解释变量的平方项、交叉乘积项构建辅助回归模型,如果辅助模型显著,则说明存在异方差问题
检验思想
- 假设对于二元回归模型有 y i = β 0 + β 1 x 1 + β 2 x 2 + ϵ i y_i=β_0+β_1x_1+β_2x_2+\epsilon_i yi=β0+β1x1+β2x2+ϵi
- 辅助回归模型 ϵ i 2 = α 0 + α 1 x 1 + α 2 x 2 + α 3 x 1 2 + α 4 x 2 2 + + α 5 x 1 x 2 + v i \epsilon_i^2=α_0+α_1x_1+α_2x_2+α_3x_1^2+α_4x_2^2++α_5x_1x_2+v_i ϵi2=α0+α1x1+α2x2+α3x12+α4x22++α5x1x2+vi
- 根据辅助模型建立方差分析F统计量
- F统计量如果拒绝原假设( H 0 : α 1 = α 2 = . . . = α k = 0 H_0:α_1=α_2=...=α_k=0 H0:α1=α2=...=αk=0),则说明存在异方差
(2)Breush Pagan 检验
检验思想与White检验基本相似,辅助回归模型不同
- 运用OLS估计回归方程 y i = β 0 + β 1 x 1 . . . + + β k x k + ϵ i y_i=β_0+β_1x_1...++β_kx_k+\epsilon_i yi=β0+β1x1...++βkxk+ϵi
- 根据得到的残差项构建辅助回归模型 ϵ i 2 = α 0 + α 1 x 1 . . . + + α k x k + v i \epsilon_i^2=α_0+α_1x_1...++α_kx_k+v_i ϵi2=α0+α1x1...++αkxk+vi
- 根据辅助模型建立方差分析F统计量
- F统计量如果拒绝原假设( H 0 : α 1 = α 2 = . . . = α k = 0 H_0:α_1=α_2=...=α_k=0 H0:α1=α2=...=αk=0),则说明存在异方差
(3)同理,我们可以根据构建不同形式的辅助回归模型,通过其F检验来判断是否存在不同形式的异方差问题
(三) 异方差的处理
加权最小二乘法WLS
我们令 w i = 1 / σ i 2 w_i = 1/\sigma^{2}_{i} wi=1/σi2,构建下面对角矩阵
W = ( w 1 0 … 0 0 w 2 … 0 ⋮ ⋮ ⋱ ⋮ 0 0 … w n ) \textbf{W}=\left( \begin{array}{cccc} w_{1} & 0 & \ldots & 0 \\ 0& w_{2} & \ldots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0& 0 & \ldots & w_{n} \\ \end{array} \right) W=⎝⎜⎜⎜⎛w10⋮00w2⋮0……⋱…00⋮wn⎠⎟⎟⎟⎞
W Y = W X β + W ϵ \textbf{W}Y=\textbf{W}Xβ+\textbf{W}\epsilon WY=WXβ+Wϵ
Y ∗ = W Y Y^*=\textbf{W}Y Y∗=WY
X ∗ = W X β X^*=\textbf{W}Xβ X∗=WXβ
ϵ ∗ = W ϵ \epsilon^*=\textbf{W}\epsilon ϵ∗=Wϵ
则,WLS结果如下:
β ^ W L S = arg min β ∑ i = 1 n ϵ i ∗ 2 = ( X T WX ) − 1 X T WY \hat{\beta}_{WLS}=\arg\min_{\beta}\sum_{i=1}^{n}\epsilon_{i}^{*2}\\ =(\textbf{X}^{T}\textbf{W}\textbf{X})^{-1}\textbf{X}^{T}\textbf{W}\textbf{Y} β^WLS=argminβ∑i=1nϵi∗2=(XTWX)−1XTWY
二,多重共线性
(一) 多重共线性的介绍
多重共线性有两种
- 基于结构共线性:数学效应引起的,比如解释变量有 X , X 2 , X 3 X,X^2,X^3 X,X2,X3导致的
- 基于数据的共线性:不同变量的数据之间存在隐含的联系导致的
(二) 多重共线性的诊断
1,相关矩阵
2,方差扩大化因子(variance inflation factors ,VIF)
V I F k = 1 1 − R k 2 VIF_k=\frac{1}{1-R_{k}^{2}} VIFk=1−Rk21
VIF>10就认为存在多重共线性
(三) 多重共线性的处理
1,基于数据的共线性:增加样本数据,看是否能减少变量之间的相关性
2,基于结构的共线性:尝试将数据中心化
3,去掉部分变量
4,提取主成分
三,序列相关
(一) 序列相关的介绍
序列相关问题,与时间序列的自回归相似。
一个AR(2)的自回归模型如下:
y t = β 0 + β 1 y t − 1 + β 2 y t − 2 + ϵ t y_{t}=\beta_{0}+\beta_{1}y_{t-1}+\beta_{2}y_{t-2}+\epsilon_{t} yt=β0+β1yt−1+β2yt−2+ϵt
同理如果回归方程中没有被选中的变量是有序列相关的,那么可能导致残差项产生序列相关的问题。
ϵ t = ρ ϵ t − 1 + ω t \epsilon_{t}=\rho\epsilon_{t-1}+\omega_{t} ϵt=ρϵt−1+ωt
如果 ρ \rho ρ显著,则说明存在序列相关的问题
(二) 序列相关的诊断
1,图示法 e t , e t − 1 e_t,e_{t-1} et,et−1
2,回归检验法
如果残差回归的系数显著,则说明存在序列相关的问题
μ i = ρ 1 μ i − 1 + ρ 2 μ i − 2 + . . . + ρ l μ i − l + ϵ i μ_i=\rho_1μ_{i-1}+\rho_2μ_{i-2}+...+\rho_lμ_{i-l}+\epsilon_i μi=ρ1μi−1+ρ2μi−2+...+ρlμi−l+ϵi
3,D-W检验 (Durbin-Watson Test)
针对方程
ϵ t = ρ ϵ t − 1 + ω t \epsilon_{t}=\rho\epsilon_{t-1}+\omega_{t} ϵt=ρϵt−1+ωt
假设检验
H 0 : ρ = 0 H A : ρ ≠ 0 H_{0}: \rho=0 \\ H_{A}: \rho\neq 0 H0:ρ=0HA:ρ̸=0
构造统计量
D = ∑ t = 2 n ( e t − e t − 1 ) 2 ∑ t = 1 n e t 2 D=\frac{\sum_{t=2}^{n}(e_{t}-e_{t-1})^{2}}{\sum_{t=1}^{n}e_{t}^{2}} D=∑t=1net2∑t=2n(et−et−1)2
D的统计值在0-4之间
| D | 0 | 2 | 4 |
|---|---|---|---|
| P | 1 | 0 | -1 |
只适合于一阶情形
不适用于同时存在异方差和序列相关模型
2,Ljung-Box Q Test
H 0 : k 个 滞 后 期 的 自 相 关 系 数 都 是 0 H_0: k个滞后期的自相关系数都是0 H0:k个滞后期的自相关系数都是0
H 1 : k 个 滞 后 期 的 自 相 关 系 数 不 都 是 0 H_1: k个滞后期的自相关系数不都是0 H1:k个滞后期的自相关系数不都是0
Q k = n ( n + 2 ) ∑ j = 1 k r j 2 n − j Q_{k}=n(n+2)\sum_{j=1}^{k}\frac{{r}^{2}_{j}}{n-j} Qk=n(n+2)∑j=1kn−jrj2
Q k 服 从 χ k 2 分 布 Q_{k}服从\chi^{2}_{k}分布 Qk服从χk2分布
(三) 序列相关的处理
1,广义差分
如果残差存在一阶序列相关,则可以把数据进行一阶差分,然后再进行OLS估计
当然可以推广到广义差分:
如果原模型存在
μ i = ρ 1 μ i − 1 + ρ 2 μ i − 2 + . . . + ρ l μ i − l + ϵ i μ_i=\rho_1μ_{i-1}+\rho_2μ_{i-2}+...+\rho_lμ_{i-l}+\epsilon_i μi=ρ1μi−1+ρ2μi−2+...+ρlμi−l+ϵi
则广义差分回归模型为:
y i − ρ 1 y i − 1 − ρ 2 y i − 2 − . . . − ρ l y i − l = β 0 ( 1 − ρ 1 − ρ 2 − . . . − ρ l ) + β 1 ( X 1 − ρ 1 X 1 − ρ 2 X 2 − . . . − ρ l X l ) + . . + ϵ i y_i-\rho_1y_{i-1}-\rho_2y_{i-2}-...-\rho_ly_{i-l}=β_0(1-\rho_1-\rho_2-...-\rho_l)+β_1(X_1-\rho_1X_1-\rho_2X_2-...-\rho_lX_l)+..+\epsilon_i yi−ρ1yi−1−ρ2yi−2−...−ρlyi−l=β0(1−ρ1−ρ2−...−ρl)+β1(X1−ρ1X1−ρ2X2−...−ρlXl)+..+ϵi
根据广义差分模型估计得到的参数,可以解决所有类型的自相关问题。
备注:广义差分需要得到具体的 ρ i \rho_i ρi值
2,Cochrane-Orcutt迭代法
(1)先估计出回归模型的参数 Y = β X + μ Y=βX+μ Y=βX+μ
(2)再估计出 μ i = ρ 1 μ i − 1 + ρ 2 μ i − 2 + . . . + ρ l μ i − l + ϵ i μ_i=\rho_1μ_{i-1}+\rho_2μ_{i-2}+...+\rho_lμ_{i-l}+\epsilon_i μi=ρ1μi−1+ρ2μi−2+...+ρlμi−l+ϵi的参数 ρ i \rho_i ρi
(3)代入广义差分模型
(4)重复上面的步骤直到第二步的 ρ i \rho_i ρi不在显著或相邻两次迭代的数值差异小于某个精度时,终止循环
(5)一般迭代两次即可,所以又叫Cochrane-Orcutt两步法
四,异常数据
(一) 异常数据的介绍
1,对于异常数据,有下面三种情况:
| 分类 | 定义 | 说明 |
|---|---|---|
| 异常点(outliers) | 对于正常的X来说,Y值偏离总体趋势 | Y极端值 |
| 高杠杆点(leverage points) | 不仅Y,X也偏离总体,要么很大要么很小 | X极端值 |
| 强影响点(influential observations) | 凡是能够影响到模型推断、斜率等回归分析中各阶段的影响点 | 其他极端的情况 |
2,异常点示例
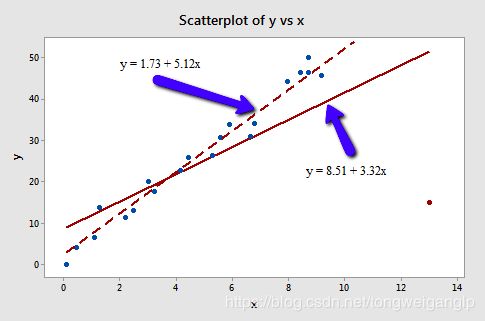
下图,红色的点,明显脱离总体趋势,所以可以被认为是异常点,但是因为x值并不异常,所以不是高杠杆点。
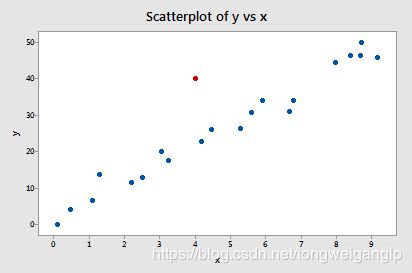
但是,红色的点是强影响点嘛?我们对比包含和剔除异常点后的回归线,以及回归模型的结果进行判断。
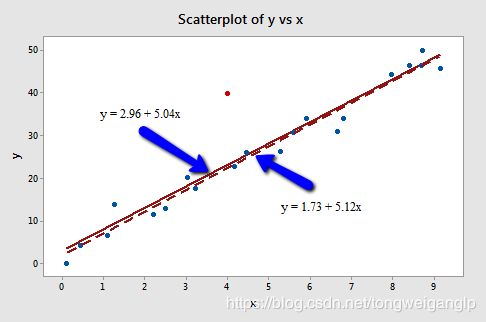
包含红色样本点

不包含红色样本点

由于,仅拟合优度提升了估计量的标准差变好了,但是斜率参数变化不大,且均显著;所以,该样本点不是强影响点。
3,高杠杆点示例
下图中的红色样本点,虽然,y保持了总体的趋势,但是x是个异常值,所以是个高杠杆点。
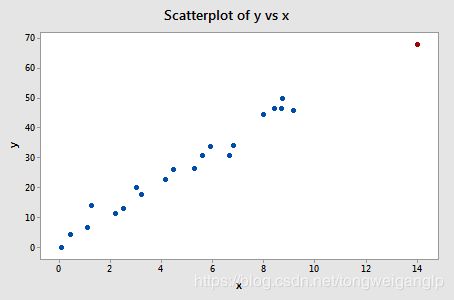
同理我们依然可以通过对比有无高杠杆点的回归线,以及回归模型的结果进行判断。

回归方程结果-略
可以判断,该点不是强影响点。
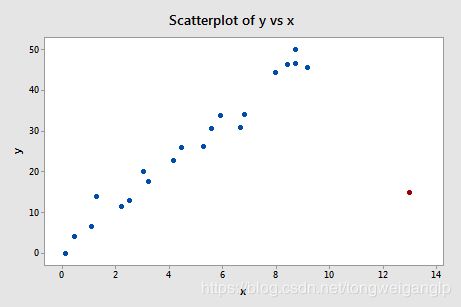
4,强影响点示例
同理,我们可以推断,下图中的红点,不仅仅是异常点、高杠杆点,而且还是强影响点,因为使得斜率发生了较大的偏离,拟合优度以及显著性推断的值也发生了较大的变化。
(二) 异常数据的诊断
1,x极端值的判断-高杠杆点
通过线性代数的角度求解线性回归模型的过程:
Y = X β + μ Y=Xβ+μ Y=Xβ+μ
β = ( X ′ X ) − 1 X ′ Y β=(X'X)^{-1}X'Y β=(X′X)−1X′Y
Y ^ = X β \hat Y=Xβ Y^=Xβ
Y ^ = X ( X ′ X ) − 1 X ′ Y \hat Y=X(X'X)^{-1}X'Y Y^=X(X′X)−1X′Y
令 H = X ( X ′ X ) − 1 X ′ H=X(X'X)^{-1}X' H=X(X′X)−1X′,则
Y ^ = H Y \hat Y=HY Y^=HY
改写成方程的形式:
y ^ i = h i 1 y 1 + h i 2 y 2 + . . . + h i n y n \hat y_i = h_{i1}y_1 +h_{i2}y_2+...+h_{in}y_n y^i=hi1y1+hi2y2+...+hinyn , for i = 1,…,n
杠杆参数 y ^ i \hat y_i y^i
一般当 h i j > 3 ( ∑ h i j n ) = 3 ( p n ) h_{ij} > 3 (\frac{\sum h_{ij}}{n})=3 (\frac{p}{n}) hij>3(n∑hij)=3(np)时,认为可能出现高杠杆点的情况。
其中,p表示参数的个数,包括截距项。
2,y极端值的判断-异常值
通过学生化的残差值,进行判断
通过残差值 e i = y i − y ^ i e_i=y_i-\hat{y}_i ei=yi−y^i
我们做如下变换
r i = e i s ( e i ) = e i M S E ( 1 − h i i ) r_{i}=\frac{e_{i}}{s(e_{i})}=\frac{e_{i}}{\sqrt{MSE(1-h_{ii})}} ri=s(ei)ei=MSE(1−hii)ei
r i r_{i} ri超过3的被认为是异常点
待改进:当异常点对模型产生了很大的影响,甚至将回归曲线“拉向自己”的时候,则上述这种“internally studentized residual”内部的学生化误差就起不到判断的作用了。
我们建立外部的学生化误差“externally studentized residuals”:
定义
d i = y i − y ^ ( i ) d_i=y_i-\hat{y}_{(i)} di=yi−y^(i)
其中,
y i y_i yi对应的依旧是第i个样本观测值
y ^ ( i ) \hat{y}_{(i)} y^(i)则代表,剔除第i个观测点后建立的回归模型,再代入第i个点解释变量值得到的预测结果
举例

去除第四个点的(i=4)回归模型,得到的第四个点( x 4 = 10 , y = 2.1 x_4=10,y=2.1 x4=10,y=2.1)的预测值,如下
y ^ ( 4 ) = 0.6 + 1.55 x = 0.6 + 1.55 ∗ 10 = 16.1 \hat{y}_{(4)}=0.6+1.55x=0.6+1.55*10=16.1 y^(4)=0.6+1.55x=0.6+1.55∗10=16.1
则 d 4 = y 4 − y ^ ( 4 ) = 2.1 − 16.1 = − 14 d_4=y_4-\hat{y}_{(4)}=2.1-16.1=-14 d4=y4−y^(4)=2.1−16.1=−14
外部的学生化误差记为:
t i = d i s ( d i ) = e i M S E ( i ) ( 1 − h i i ) t_i=\frac{d_i}{s(d_i)}=\frac{e_i}{\sqrt{MSE_{(i)}(1-h_{ii})}} ti=s(di)di=MSE(i)(1−hii)ei
结果依旧是与3相比较, t i > 3 t_i>3 ti>3的认为是异常点。
3,强影响点的判断
定义Cook’s distance
D i = ( y i − y ^ i ) 2 p × M S E [ h i i ( 1 − h i i ) 2 ] D_i=\frac{(y_i-\hat{y}_i)^2}{p \times MSE}\left[ \frac{h_{ii}}{(1-h_{ii})^2}\right] Di=p×MSE(yi−y^i)2[(1−hii)2hii]
其中,
y i y_i yi对应的依旧是第i个样本观测值
y ^ ( i ) \hat{y}_{(i)} y^(i)则代表,剔除第i个观测点后建立的回归模型,再代入第i个点解释变量值得到的预测结果
p 表示参数的个数,包括截距项
判断:
当 D i D_i Di值大于0.5,则仅仅有可能是
当 D i D_i Di值大于1,则非常有可能是
当 D i D_i Di与其他值比非常抢眼,则基本可以确定就是
(三) 异常数据的处理
如果是录入错误或收集错误,则改正
如果其他原因,基本都是直接删除
上一节:第2章-回归模型(1)-线性回归模型与估计
下一节:第2章-回归模型(3)-模型筛选
参考
1,https://newonlinecourses.science.psu.edu/stat501/node/337/