CNCC day2下午 人工智能与机器学习前沿技术论坛
下午论坛的主题是人工智能与机器学习前沿技术论坛,这应该是本次大会最火爆的一个了,后面一排一排的站着的老师和同学让我庆幸上午走得早才能抢到位子。
知识引导、数据驱动和策略探索之间的相互协调
言归正传,下午首先发言的是zju的吴飞教授。报告的题目是知识引导、数据驱动和策略探索之间的相互协调。这个报告相对来讲是比较泛的。主要是针对当前人工智能虽然依赖于数据驱动模型非常善于预测识别,但是其过程难以理解(神经网络目前还被看做是一个黑箱,没有特别好的办法来理解)。同时数据驱动依赖大量干净的带有标签的数据。
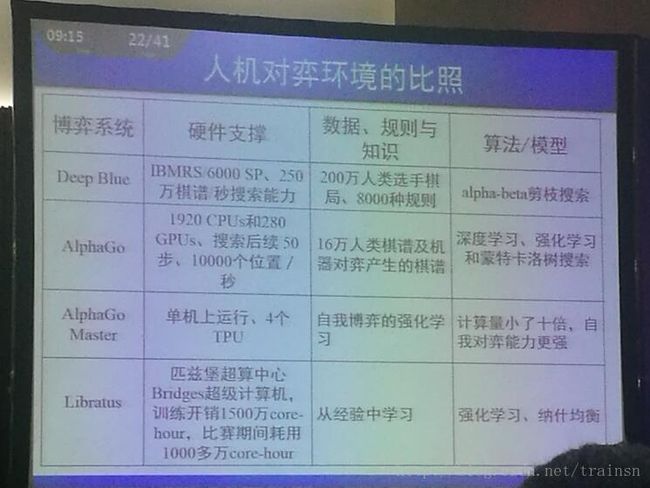
从人机对弈的历史发展来看,计算机经过了人用规则来教计算机(比如深蓝,人类用了200万人类选手棋局,8000种规则来教计算机),计算机通过数据来学习(AlphaGo使用了16万人类棋谱和机器对弈产生的棋谱,用深度学习、强化学习和蒙特卡洛树搜索),计算机通过自我对弈来学习(AlphaGo Master)。从目前的发展现状来看,我们要追求的是一种完全信息下的博弈到非完全信息下的博弈。
对话智能的前沿机器应用思考

接下来做报告的是俞凯老师。这份报告所针对的是对话的处理。首先是对问题进行分类:问答式、任务式、命令式、闲聊式。图中的横纵轴分别是提问的次数和问题的结构化程度和知识的引入程度。举个例子,微软小冰处理的就是一种闲聊式的对话。而此次报告针对的是任务式的对话,也就是相对来说比较结构话的多轮问题。

对对话的处理采用的深度序列学习的技术,如图所示,是一个“编码器-译码器结构”。将输入的序列扔到一个RNN当中,生成词向量,输入到input state当中,得到输入的词向量,然后再扔到ouput RNN里面,得到输出序列。PPT中展现了深度序列学习的优势。
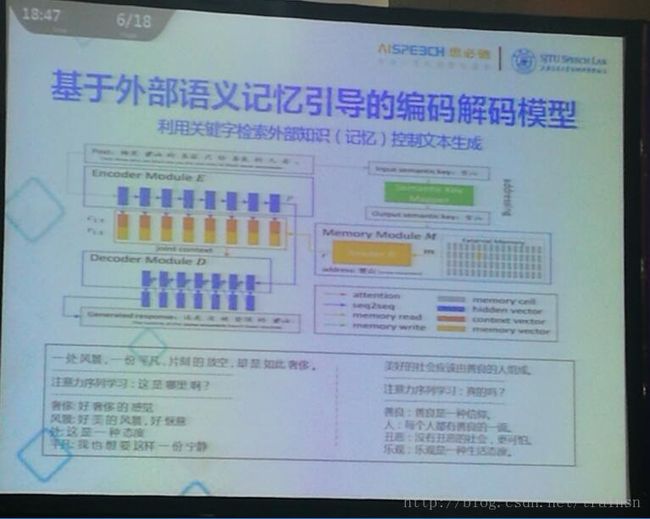
接下来探讨的是基于外部语义引导的编码解码模型。这个是在之前的模型之上加了一个memory module。具体实现的功能是利用关键字检索外部知识(记忆)控制文本生成。距离来说,ppt下面的句子,如果没有关键字索引,得到的回答和有关键字索引得到的回答是有所不同的。针对不同的关键字得到的回答也是不同的。

在处理话数据的时候,存在有标注的对话数据相对较少和标注对话数据难度大的问题。所以单纯的数据驱动可能对问题的处理并非最佳选择。所以采用rule-based+data-driven的方式。其中涉及到强化学习领域的知识,这块实在是没怎么听懂,以后有机会再研究吧。
脑启发的神经网络学习
这份报告主要是对现有的神经网络的一些修改,而修改的思路某种意义上可以和人脑处理信息的方式扯上点关系。

报告从微观、介观和宏观三方面来进行阐述。
微观层面首先提到的是兴奋和抑制神经元。当前使用的神经网络没有将神经元进行类型上的区分。而作者采用的是将神经元分为兴奋和抑制性神经元。论文结果如下图所示:
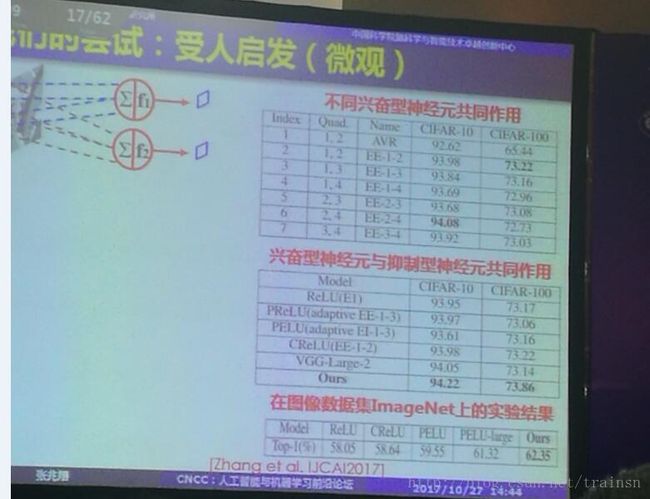
在CIFAR-10、CIFAR-100和ImageNet上均有提高。

微观层面上的第二点是采用了random shifting的方法。文章是Random Shifting for CNN: a Solution to Reduce Information Loss in Down-Sampling Layers。
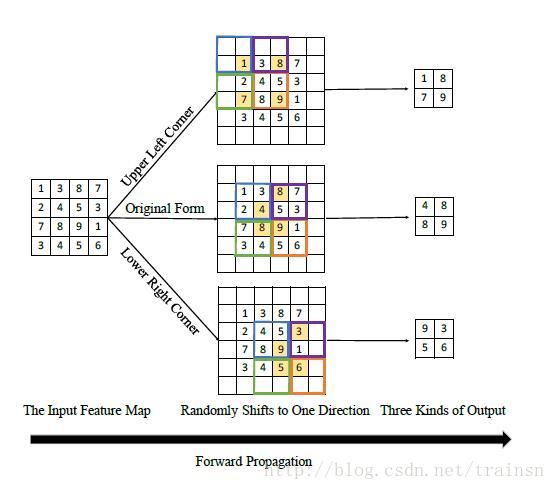
简单的看了一下的论文,论文中提到在dowm-sample的时候,我们可以采用在down-sample的时候随机的将feature map往一个方向做移动。这样可以使得我们产生更加鲁棒的特征。
adjust receptive fields by shifting kernel centers on feature maps in different directions. Thus, it can generate more robust features in networks and further enhance the transformation invariance of downsampling
operators.

论文结果:random shifting的方法使得我们不同的baseline上面都取得了更好的效果。
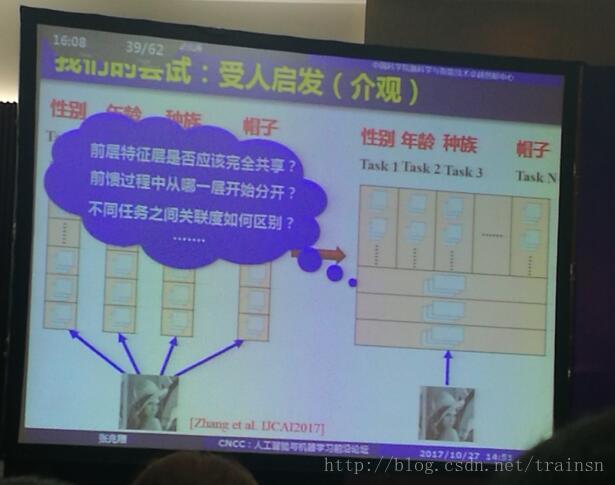
在处理多任务的时候,比如对于一张输入图像,我们要检测得到图中人的性别、年龄、种族……,一般的方法是在底层公用参数,然后在高层分别提取不同的特征。那么问题来了,我们要在哪一层分开网络参数?同时如何体现出任务之间的关联性?报告指出, 我们可以采用一种任务池的方法,将任务处理为动态多任务。

在处理一些比较难的分类问题的时候,比如分“大”和“太”,报告里所采用的是一种第一次伪先验+贝叶斯注意机制的文字分析,通过不断迭代,从而得到最终结果。(具体的还要以后再研究)

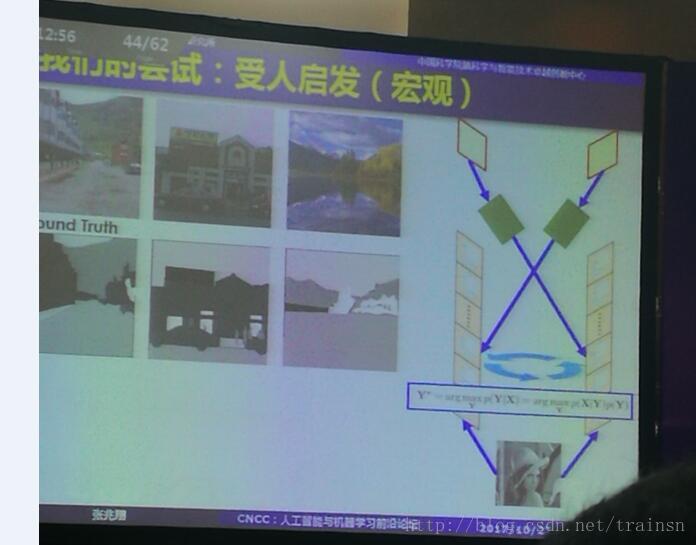
在处理多模态的时候, 比如视觉输入+听觉输入,是否要采用分别提取特征的方法?报告指出,我们可以采用震荡的方法。这样,即使在模态缺失的情况下,从另一个模态当中我们也可以得出信息。
半监督生成模型
这份报告是由清华的朱军老师做的,深度生成模型是一类从复杂数据中提取隐含结构并且进行“从上到下”生成样本的方法。


本篇报告介绍了一些用于半监督的模型与算法。

比如在二维空间内,有标记的数据只有红点和蓝点,这个时候,如果单用监督学习的方法,分类线很可能就是中间切一刀。但是有了这些没有标记的数据和半监督学习的算法,我们可以获得图中的分类方法。
不巧的是,这个时候手机没电了,所以很多PPT都没有拍到。记了一些关键词Triplet-GAN
generator 隐含欧式空间插值
最后朱军教授介绍了支持快速编程实现的“珠算”计算平台,这是一个基于TensorFlow的库,已经在github上开源了。
thu-ml/zhusuan
面向大规模图像视频检索的深度哈希学习
王瑞平研究院主要讲的是面向图像视频检索的深度哈希学习研究方面取得的进展,包括面向传统图像类别检索的深度监督哈希、面向图像类别与属性联合检索的哈希。
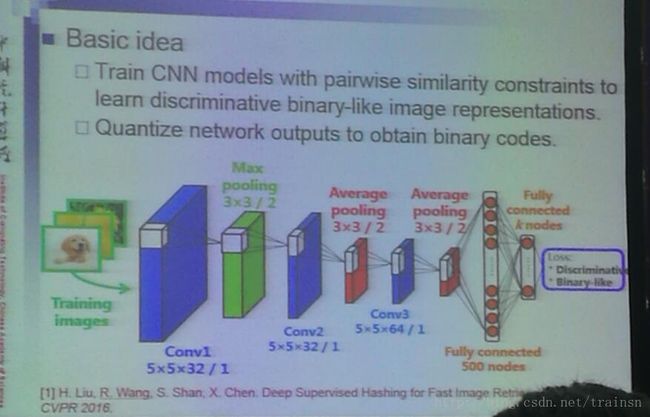
深度哈希学习在原有的方法的基础上是我们不再使用传统的方法提取的特征,而是使用神经网络提取出的特征来做后续的处理。
网络最后的loss是首先将特征向量转化为binary code, 然后用异或的方法来计算loss(计算效率高)。

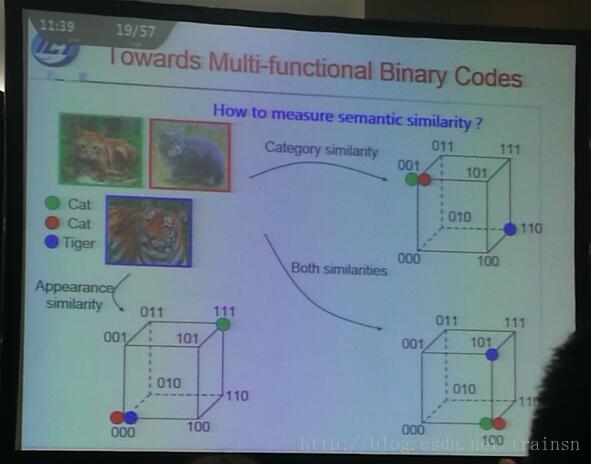
为了解决面向图像属性类别与属性联合检索的多功能哈希,当特征向量被转化到了二值空间之后,可以从不同角度来度量图片的相似程度。比如类别的判断可以高层的向量,属性、纹理等的判断可以从中层的向量……
在处理视频的二值编码的时候,采用时域融合的方法……