网易云音乐“王牌冤家”用户评论:评论爬虫及情感分析(SnowNLP)
李荣浩上周发的《耳朵》专辑,你萌听了吗?小编真的超级喜欢“王牌冤家”这首歌,在新说唱听了李老师的那几句就一直念念不忘,这一周可是一直单曲循环中。恰好前两天看了SnowNLP的一点东西,所以,这一次基于这首歌的评论,来做个非常easy的情感分析。文本信息是选取的网易云音乐下的评论,所以本文是爬虫+分析。
爬虫
在网易云音乐上万首hiphop歌曲解析rapper们的最爱(爬虫篇)一文中,我们基于selenium爬取了歌单,歌曲和歌词的信息,本来在评论的爬取也可以选择selenium的方式,但是,小编上网一搜,就找到评论的API,这可就非常简单了。
Step 1:在网页打开需要爬取歌曲的界面:

这个歌曲ID非常重要,而,目前,我们仅需要这一个信息就OK了。
Step 2:上API:
http://music.163.com/api/v1/resource/comments/R_SO_4_862129612?limit=20&offset=0
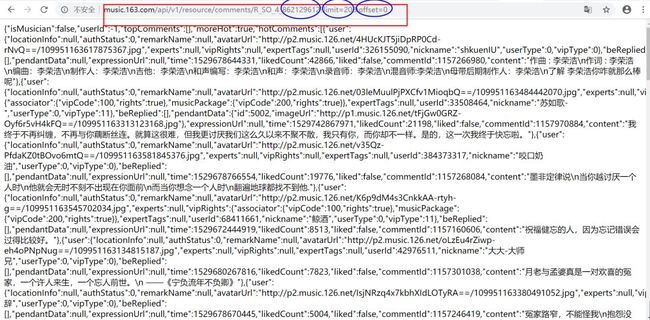
API其实是
http://music.163.com/api/v1/resource/comments/R_SO_4_歌曲ID?limit=每页展示评论数量&offset=(页数-1)*20.
是不是对于API下的代码有点看不懂,没关系,你可以把这些代码粘贴到一个json解码网站,比如说
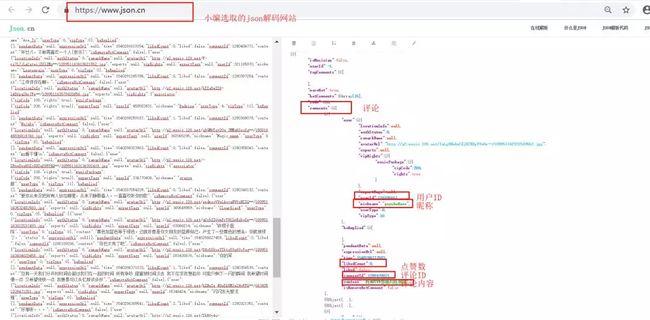
这么是不是自己想要爬取的信息更直观了。
Step 3:上代码
import requests
import json
import time
import random
import pandas as pd
#下载第一页数据
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200: #页面正常响应
return response.text # 返回页面源代码
return None
commentId=[]
nickname=[]
userId=[]
content=[]
likedCount=[]
#解析第一页数据
def parse_ono_page(html):
data = json.loads(html)['comments'] #评论以json形式存储,故以json形式截取
for item in data:
commentId.append(item['commentId']),#评论id
nickname.append(item['user']['nickname']),#评论用户的昵称
userId.append(item['user']['userId']),#评论用户的id
content.append(item['content']),#评论内容
likedCount.append(item['likedCount'])#点赞数
#保存数据到文本文档
def save_to_txt():
for i in range(1, 755):
url='http://music.163.com/api/v1/resource/comments/R_SO_4_862129612?limit=20&offset=' + str(20*(i-1))
html = get_one_page(url)
print('正在保存第%d页.'% i)
parse_ono_page(html)
time.sleep(5 + float(random.randint(1,100)) /20)
if __name__ =='__main__':
save_to_txt()
wangpai = {'commentId': commentId, 'nickname': nickname, 'userId': userId, 'content': content, 'likedCount':likedCount}
wangpai = pd.DataFrame(wangpai, columns=['commentId', 'nickname', 'userId', 'content','likedCount'])
wangpai.to_csv("wangpaiyuanjia.csv",encoding="utf_8_sig",index = False) 爬虫部分,done!
分析
这里小编用到了SnowNLP,官方介绍是:SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。简单的说,SnowNLP就是可以中文自然语言处理库,可以完成中文分析,词性标注,情感分析,等等功能。
在本文,我们仅借助其对评论进行情感分析,举一个简单的例子:
s1 = '我喜欢,作曲作词我都好喜欢'
s2 = '一般般'
s3 = '感觉水平下降了好多,不好听'
print('s1: ',SnowNLP(s1).sentiments)
print('s2: ',SnowNLP(s2).sentiments)
print('s3: ',SnowNLP(s3).sentiments)
#s1: 0.9574420076803888
#s2: 0.5033557046979866
#s3: 0.183861270052044 给出的情感评分在[0,1]之间,越接近1,情感表现越积极,越接近0,情感表现越消极。所以,我们将所有的评论都计算了情感得分,并将大于0.5的归于正向情感,反之则为负向情感。代码如下:
from snownlp import SnowNLP
data = pd.read_csv("wangpaiyuanjia.csv",lineterminator='\n')
data["semiscore"] = data['content'].apply(lambda x: SnowNLP(x).sentiments)
data['semilabel'] = data["semiscore"].apply(lambda x: 1 if x>0.5 else -1)
import numpy as np
import matplotlib.pyplot as plt
plt.hist(data["semiscore"], bins = np.arange(0, 1.01, 0.01),label="semisocre", color="#ff9999")
plt.xlabel("semiscore")
plt.ylabel("number")
plt.title("The semi-score of comment")
plt.show()
semilabel = data["semilabel"].value_counts()
plt.bar(semilabel.index,semilabel.values,tick_label=semilabel.index,color='#90EE90')
plt.xlabel("semislabel")
plt.ylabel("number")
plt.title("The semi-label of comment")
plt.show()基于情感的得分,我们得到下图:

非常直观,大家对“王牌冤家”这首歌喜欢的人居多,和我一样,非常喜欢的人数也是相当可观的。那么以0.5为界限进行划分后呢:
![]()
正向情感的人数是负向情感人数的两倍多。作为粉丝,非常欣慰啊。
这里,再对这些评论做一个简单的词云图吧,词云图主要是jieba分词,因为SnowNLP分词的效果不如jieba。如下:
import jieba
comment=''.join(data['content'])
wordlist = jieba.cut(comment, cut_all=False)
stopwords_chinese = [line.strip() for line in open('stopwords_chinese.txt',encoding='UTF-8').readlines()]
#过滤点单个字
word_list=[]
for seg in wordlist:
if seg not in stopwords_chinese:
word_list.append(seg)
word_list=pd.DataFrame({'comment':word_list})
word_rank = word_list["comment"].value_counts()
from pyecharts import WordCloud
wordcloud_chinese = WordCloud(width=1500, height=820)
wordcloud_chinese.add("", word_rank.index[0:100], word_rank.values[0:100], word_size_range=[20, 200], is_more_utils=True)
wordcloud_chinese.render("comment.html")
关于停用词,可以参考网易云音乐上万首hiphop歌曲解析rapper们的最爱(可视化篇)。
结语
结合之前写的关于rap歌词的三篇文章,好像把网易云音乐相关能爬的信息都爬了, 。网页爬虫,小编写了很多了,之后,小编给大家带来一些不一样的爬虫吧。
。网页爬虫,小编写了很多了,之后,小编给大家带来一些不一样的爬虫吧。
更多内容,关注:经管人学数据分析
