基于的BERT的一些改进模型及思路
基于的BERT的一些改进模型及思路
- 被遗弃的NSP
- Underfitted的BERT
- 数据和批大小的作用
- Drop掉dropout
- 减少参数的技术
- 嵌入层的参数化方法-- 矩阵分解
- 层间共享参数
- 改头换面的MLM
- 动态掩码
- 判别器的优势
- 总结
BERT的成功主要在于几大因素:超大模型+超大语料;利用Transformer;新的Loss即MLM(Masked Language Model)+NSP(Next Sentence Prediction)。其后有很多的研究在BERT的基础上进行了各种修正和改良,甚至对原Loss(比如NSP)提出了不同的看法和尝试。这里做一个简单的总结。主要涉及到的论文:RoBERTa,
ALBERT,ELECTRA。
被遗弃的NSP
BERT的loss由两部分组成(MLM+NSP)。MLM在各种研究中得到了越来越多的认可,相信LM会让位给MLM或者新的形态的LM(比如XLNet提出的PLM)。但是NSP自问世以来一直受到各种诟病和质疑。
NSP(Next Sentence Prediction)给定一个句子对,判断在原文中第二个句子是否紧接第一个句子。正例来自于原文中相邻的句子;负例来自于不同文章的句子。RoBERTa,ALBERT,XLNet都做过实验表明NSP没有必要。它们都摒弃了NSP而取得了更好的效果,ALBERT提出了更好的替代品SOP(Sentence Order Prediction)并从理论上解释了SOP之余NSP的优越性。
ALBERT的作者认为,NSP作为一项任务,和MLM相比,没有什么难度。它把主题预测和一致性预测混淆在了一起,而主题预测比一致性预测要容易。具体而言,由于正例来自于同样一篇文章,而负例来自于不同的文章,很可能判别正负例仅仅需要判别两个句子的主题是否一致,而这些信息已经在MLM中学习过了。
作为NSP的替代,SOP显然更有挑战性。它使用同一篇文章的相邻的两个句子作为正例,把句子的位置互换作为负例。任务是判断句序是否正确。而这仅属于一致性预测,大大提高了预测的难度。实验也表明SOP能较好的解决NSP任务,而NSP对SOP任务没有任何助益。在下游的多句子编码类任务中,SOP的效果得到了很好的体现。
具体实验如图:
 NSP在解决SOP问题时精度仅为52%,而SOP在NSP任务上的精度是78.9%
NSP在解决SOP问题时精度仅为52%,而SOP在NSP任务上的精度是78.9%
SOP在几乎所有的下游任务中(除了SST-2)都相比NSP有提升。我个人的看法是NSP很快会被无情抛弃,仅使用MLM或者使用MLM加上一个更强的句子对任务会成为预训练的主流。
Underfitted的BERT
BERT其实并没有被overfit,后来的工作比如XLNet就尝试用了10倍于BERT的预训练数据。
既然如此,数据大小,训练方法,参数化方法都可以是针对underfit的改革的方向。
数据和批大小的作用
RoBERTa的作者认为BERT忽视了预训练数据大小及预训练时长的影响。实验表明更大的数据会带来更好的精度提升。
 表中RoBERTa用到了10倍于BERT的预训练数据和32倍的批大小。在精度带来提高的同时,也观察到模型最终仍然未被overfitting。在"+pretrain evern longer"一栏中精度仍在上升。
表中RoBERTa用到了10倍于BERT的预训练数据和32倍的批大小。在精度带来提高的同时,也观察到模型最终仍然未被overfitting。在"+pretrain evern longer"一栏中精度仍在上升。
Drop掉dropout
ALBERT不仅观察到了更多数据的好处,还发现去掉dropout也有助于下游任务精度提升。这算是首个发现dropout对Transformer-based模型有害的工作。


减少参数的技术
减参,即把模型变小可以提高训练速度。ALBERT在不影响精度的前提下大幅度减少了参数(ALBERT的large版本参数仅为BERT large的1/18)
嵌入层的参数化方法-- 矩阵分解
ALBERT的作者提出了一个很漂亮的解构嵌入层的方法。在BERT和XLNet中,embedding size E和hidden size H大小一样。从模型的角度来看,嵌入层是用来学习独立于环境的表征(context-independent representations),而隐藏层的embeddings是用来学习与环境有关(想一想Transformer的attention module)的表征(context-independent representations)。这二者没有必要保持embedding大小一致,完全可以解耦。
从实用的角度来看,嵌入层的vocabulary size V一般都是10K的量级。为了模型的精度,H一般很大。如果E=H,则嵌入层的参数大小V × \times ×H。这很容易就导致模型有超多参数。
矩阵分解的做法是,把原来的嵌入层矩阵(大小V × \times ×H)投影到一个低维的空间(维度为E, E<
当H远大于E时,这种参数化方法效果显著。
层间共享参数
层间的参数共享有很多方式,比如仅前向层共享,仅attention参数共享。ALBERT的缺省模式是全参数共享。
这些方法对参数大小的改变有多大?
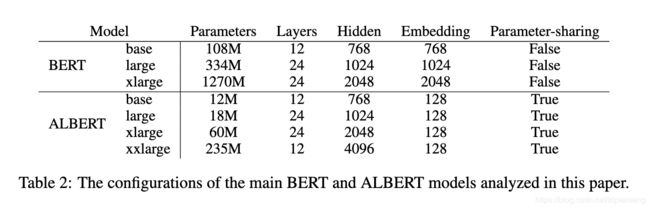 模型在下游任务中的表现:
模型在下游任务中的表现:
 在dev set上,ALBERT xxlarge以BERT large约70%的参数量,取得更好的下游任务表现。比如RACE +8.5%,SQuAD v2.0 +4.2%, SST-2 +3.0%等等。
在dev set上,ALBERT xxlarge以BERT large约70%的参数量,取得更好的下游任务表现。比如RACE +8.5%,SQuAD v2.0 +4.2%, SST-2 +3.0%等等。
改头换面的MLM
MLM提供了真正的双向语言模型。虽然在BERT提出MLM之后,GPT-2仍然坚持使用LM,XLNet改良了LM(PLM),但是大的方向上看,MLM势不可挡。很多后续的工作对MLM作了微调也观察到了更好的效果。
动态掩码
BERT在预训练中随机遮掩tokens,然后保持这些被遮掩的tokens不变。这被称为静态掩码。 RoBERTa提出了动态掩码,具体是每一次都对同样的sentence产生不同的掩码。在对更大的数据进行更长时间的预训练时,动态掩码比静态掩码效果更好。
判别器的优势
动态掩码只算是一个小的改进。从本质上说这些方法都利用模型generate对masked token的预测。但是ELECTRA巧妙的把这个利用generator的预测问题,改装成了利用discriminator的分类问题。
ELECTRA用一个generator(通常是一个小型的MLM)产生在masked token上的预测值分布,经过sample以后作为输入传给discriminator来判断每个位置上的token是否被置换过。如下图:
 注意判别器discriminator部分并不仅仅对masked tokens做判别,而是对所有的输入做判断。这样做的好处是模型的discriminator部分可以利用到所有的输入tokens,具有很高的学习效率。作为对比,MLM只能对一小部分tokens进行学习。
注意判别器discriminator部分并不仅仅对masked tokens做判别,而是对所有的输入做判断。这样做的好处是模型的discriminator部分可以利用到所有的输入tokens,具有很高的学习效率。作为对比,MLM只能对一小部分tokens进行学习。
(注意BERT和ELECTRA之间的关系,类似于skip-thought和Quick thougts的关系。)
下图是和经典算法包括MLM系算法(BERT,RoBERTa)对比,同等量级的ELECTRA碾压BERT并趋近于RoBERTa
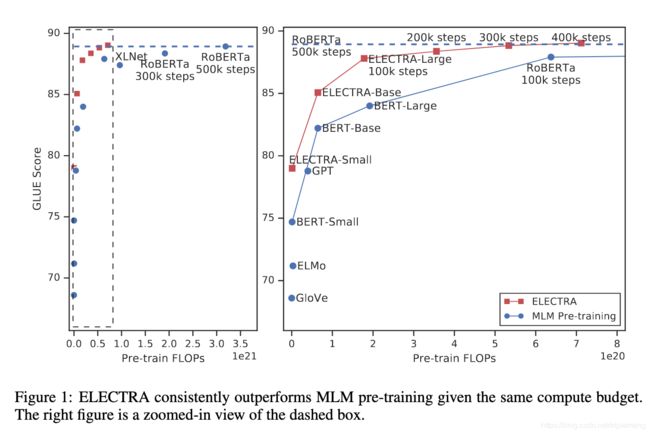 ELECTRA以少很多的参数,更少的预训练时间达到更好的效果。
ELECTRA以少很多的参数,更少的预训练时间达到更好的效果。

总结
文章只是简单介绍几个基于BERT的非常优秀的拓展工作,中间省略了大量丰富的原始细节(比如ELECTRA对GAN在NLP中的思考和尝试,ALBERT用到的LAMP优化方法)。从大的趋势来看,NSP很可能会被抛弃,MLM及其变种会展现出更大的活力。ELECTRA的MLM based generator + 判别器令人印象深刻。模型的训练会趋向于利用更大数据和更大batch。同时在保证精度的前提下,人们会寻求更少参数的模型(比如ALBERT的嵌入层参数分解)。
关注公众号《没啥深度》有关自然语言处理的深度学习应用
