影视评论动辄好几万,小小的词云已不能很全面的展示用户的整体想法。那么在工作和学习中我们面对海量文章时,有没有什么神器呢?当然。比如:文本关键词和主题抽取 本文使用python对500条文本做主题抽取,一步步带你体会和学习非监督学习LDA的魅力。
准备工作
- 安装所用库文件:
jieba、pyldavis、sklearn、pandas - pyldavis 简介
- 官方文档:http://pyldavis.readthedocs.io/en/latest/modules/API.html
开始干活
- 处理表格数据,使用数据框工具pandas
import pandas as pd
# 以csv方式读入文件
df = pd.read_csv()
# 查看数据框前几行,确认文件是否正确
df.head()
# 查看数据相信信息,是否符合预期
df.info()
- 中文分词
因为我们需要提取每条评论的关键词,而中文并不是以空格划分各个词语,所以我们需要进行分词处理,此处我们采用结巴分词工具。import jieba
我们此次需要处理的,并不是单一的文本文件,而是多条文本数据,因此我们需要将该工作并行化处理。并借助更为高效的apply函数
def chinese_cutt(content):
words =" ".join( [word for word in jieba.cut(content,cut_all=False) if len(word)>2] )
return words
df['cutted'] = df.comment_infos.apply(chinese_cutt)
# 查看结果是否正常
df.cutted.head()
文本中文分词已经完成,接下来我们来开始文本向量化,关于文本向量化可参考文本向量化。
文本向量化只是将文本中的关键字转化为一个个的特征值以便计算机识别。
提取特征关键词
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
# 关键词提取和向量转化
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features = 1000,
max_df = 0.5,
min_df = 10
)
tf = tf_vectorizer.fit_transform(df.cutted)
设定主题数量,吓的本汪掐之一算,这可能是个坑。不用担心,就猜一把呗,LDA方法指定主题数是必须的,当然我们可以15个起步,小步迭代,一步步来么。
lda = LatentDirichletAllocation(n_topics = 15,
max_iter =50,
learning_method = 'online',
learning_offset = 50,
random_state = 0)
lda.fit(tf)
一直在运行,啥时候结束啊,我也很无奈呢,让我们把每个主题的关键词表输出来喵一眼
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
输出看一眼,也不咋的啊,为啥?不够直观。借助pyDAvis让文字动起来看看
import pyLDAvis
import pyLDAvis.sklearn
# pyLDAvis.enable_notebook()
data = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
pyLDAvis.show(data)
接下来,你会看到如下一张图,并且还一闪一闪的
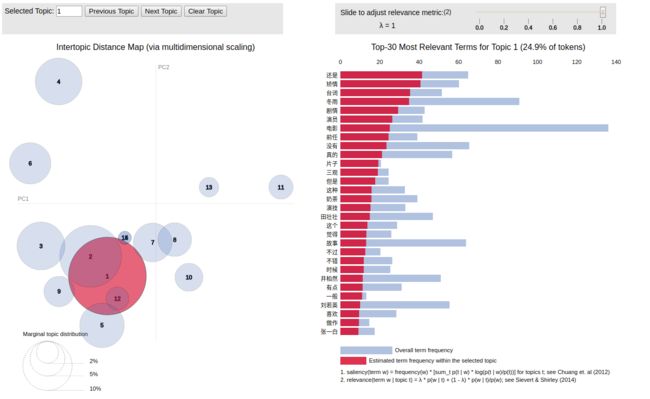
影视评论主题抽取
本文问题说明
- 未做停用词处理
- 各方法以默认参数为主
相关阅读 请移步
影视评论分析(三)-- 情感分析
初步学习有很多不足之处,希望大家多多指教