深度学习面试100题(第1-10题):经典常考点CNN
1、梯度下降算法的正确步骤是什么?
d.用随机值初始化权重和偏差
c.把输入传入网络,得到输出值
a.计算预测值和真实值之间的误差
e.对每一个产生误差的神经元,调整相应的(权重)值以减小误差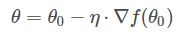
b.重复迭代,直至得到网络权重的最佳值
A.abcde B.edcba C.cbaed D.dcaeb 解析:正确答案D,考查知识点-深度学习
课外点:凸优化,梯度下降这些知识点 属于哪个数学科目 ?? 最优化理论(最优化和运筹学里面都有)
2、已知:
- 大脑是有很多个叫做神经元的东西构成,神经网络是对大脑的简单的数学表达。
- 每一个神经元都有输入、处理函数和输出。
- 神经元组合起来形成了网络,可以拟合任何函数。
- 为了得到最佳的神经网络,我们用梯度下降方法不断更新模型
给定上述关于神经网络的描述,什么情况下神经网络模型被称为深度学习模型?
A.加入更多层,使神经网络的深度增加
B.有维度更高的数据
C.当这是一个图形识别的问题时
D.以上都不正确
解析:正确答案A,更多层意味着网络更深。没有严格的定义多少层的模型才叫深度模型,
目前如果有超过2层的隐层,那么也可以及叫做深度模型。
3、训练CNN时,可以对输入进行旋转、平移、缩放等预处理提高模型泛化能力。这么说是对,还是不对?
A.对 B.不对
解析:对。如寒sir所说,训练CNN时,可以进行这些操作。当然也不一定是必须的,只是data augmentation扩充数据后,模型有更多数据训练,泛化能力可能会变强。
4、下面哪项操作能实现跟神经网络中Dropout的类似效果?
A.Boosting B.Bagging C.Stacking D.Mapping
解析:正确答案B。
Dropout可以认为是一种极端的Bagging,每一个模型都在单独的数据上训练,同时,通过和其他模型对应参数的共享,从而实现模型参数的高度正则化。
5、下列哪一项在神经网络中引入了非线性?
A.随机梯度下降
B.修正线性单元(ReLU)
C.卷积函数
D.以上都不正确
解析:正确答案B。修正线性单元是非线性的激活函数。
激活函数可以参考这几篇:文章一,文章二,文章三
深度学习面试100题(第6-10题)
1.CNN的卷积核是单层的还是多层的?
解析:
一般而言,深度卷积网络是一层又一层的。层的本质是特征图, 存贮输入数据或其中间表示值。一组卷积核则是联系前后两层的网络参数表达体, 训练的目标就是每个卷积核的权重参数组。
描述网络模型中某层的厚度,通常用名词通道channel数或者特征图feature map数。不过人们更习惯把作为数据输入的前层的厚度称之为通道数(比如RGB三色图层称为输入通道数为3),把作为卷积输出的后层的厚度称之为特征图数。
卷积核(filter)一般是3D多层的,除了面积参数, 比如3x3之外, 还有厚度参数H(2D的视为厚度1). 还有一个属性是卷积核的个数N。
卷积核的厚度H, 一般等于前层厚度M(输入通道数或feature map数). 特殊情况M > H。
卷积核的个数N, 一般等于后层厚度(后层feature maps数,因为相等所以也用N表示)。
卷积核通常从属于后层,为后层提供了各种查看前层特征的视角,这个视角是自动形成的。
卷积核厚度等于1时为2D卷积,对应平面点相乘然后把结果加起来,相当于点积运算;
卷积核厚度大于1时为3D卷积,每片分别平面点求卷积,然后把每片结果加起来,作为3D卷积结果;1x1卷积属于3D卷积的一个特例,有厚度无面积, 直接把每片单个点乘以权重再相加。
归纳之,卷积的意思就是把一个区域,不管是一维线段,二维方阵,还是三维长方块,全部按照卷积核的维度形状,对应逐点相乘再求和,浓缩成一个标量值也就是降到零维度,作为下一层的一个feature map的一个点的值!
可以比喻一群渔夫坐一个渔船撒网打鱼,鱼塘是多层水域,每层鱼儿不同。
船每次移位一个stride到一个地方,每个渔夫撒一网,得到收获,然后换一个距离stride再撒,如此重复直到遍历鱼塘。
A渔夫盯着鱼的品种,遍历鱼塘后该渔夫描绘了鱼塘的鱼品种分布;
B渔夫盯着鱼的重量,遍历鱼塘后该渔夫描绘了鱼塘的鱼重量分布;
还有N-2个渔夫,各自兴趣各干各的;
最后得到N个特征图,描述了鱼塘的一切!
2D卷积表示渔夫的网就是带一圈浮标的渔网,只打上面一层水体的鱼;
3D卷积表示渔夫的网是多层嵌套的渔网,上中下层水体的鱼儿都跑不掉;
1x1卷积可以视为每次移位stride,甩钩钓鱼代替了撒网;
下面解释一下特殊情况的 M > H:
实际上,除了输入数据的通道数比较少之外,中间层的feature map数很多,这样中间层算卷积会累死计算机(鱼塘太深,每层鱼都打,需要的鱼网太重了)。所以很多深度卷积网络把全部通道/特征图划分一下,每个卷积核只看其中一部分(渔夫A的渔网只打捞深水段,渔夫B的渔网只打捞浅水段)。这样整个深度网络架构是横向开始分道扬镳了,到最后才又融合。这样看来,很多网络模型的架构不完全是突发奇想,而是是被参数计算量逼得。特别是现在需要在移动设备上进行AI应用计算(也叫推断), 模型参数规模必须更小, 所以出现很多减少握手规模的卷积形式, 现在主流网络架构大都如此。
2.什么是卷积?
解析:
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。
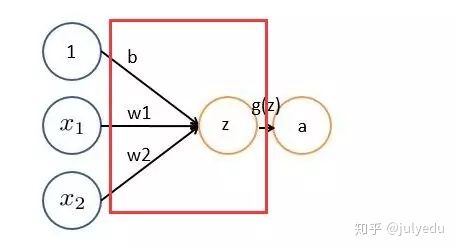
OK,举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
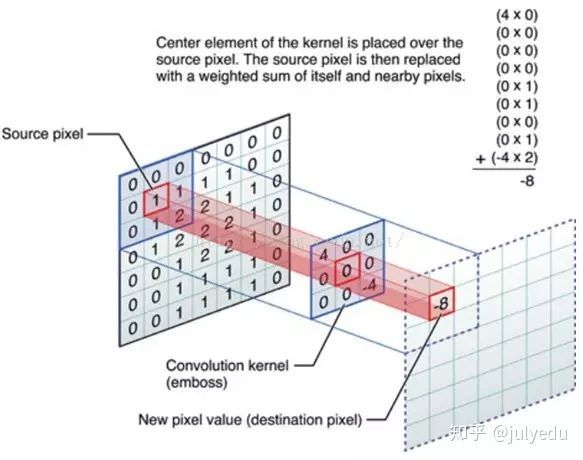

中间滤波器filter与数据窗口做内积,其具体计算过程则是:4*0 + 0*0 + 0*0 + 0*0 + 0*1 + 0*1 + 0*0 + 0*1 + -4*2 = -8
3.什么是CNN的池化pool层?
解析:
池化,简言之,即取区域平均或最大,如下图所示(图引自cs231n)
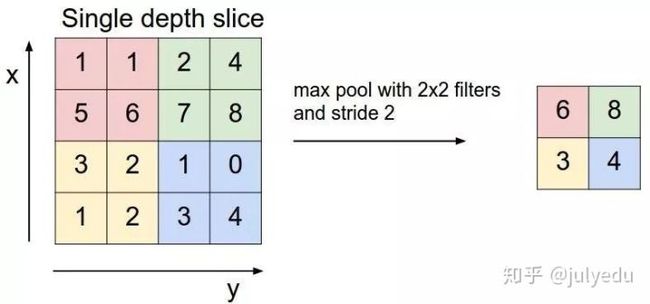
上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。
4.简述下什么是生成对抗网络。
解析:
GAN之所以是对抗的,是因为GAN的内部是竞争关系,一方叫generator,它的主要工作是生成图片,并且尽量使得其看上去是来自于训练样本的。另一方是discriminator,其目标是判断输入图片是否属于真实训练样本。
更直白的讲,将generator想象成假币制造商,而discriminator是警察。generator目的是尽可能把假币造的跟真的一样,从而能够骗过discriminator,即生成样本并使它看上去好像来自于真实训练样本一样。

如下图中的左右两个场景:
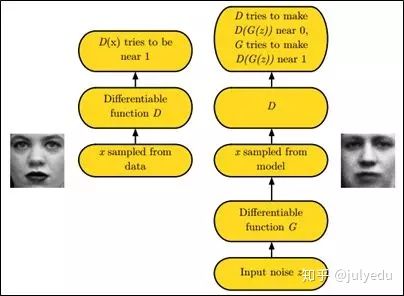
更多请参见此课程:《生成对抗网络班》(链接:https://www.julyedu.com/course/getDetail/83)
5.学梵高作画的原理是什么?
解析:
这里有篇如何做梵高风格画的实验教程《教你从头到尾利用DL学梵高作画:GTX 1070 cuda 8.0 tensorflow gpu版》(链接:http://blog.csdn.net/v_july_v/article/details/52658965),至于其原理请看这个视频:NeuralStyle艺术化图片(学梵高作画背后的原理)(链接:http://www.julyedu.com/video/play/42/523)。