【一点资讯】Google理论背书与百度实践加持:百度Palo数据库宣布开源 www.yidianzixun.com
https://www.yidianzixun.com/article/0H49WjY2?title_sn/0&s=12&appid=yidian&ver=4.5.3.1&utk=047fbokr
策划|Natalie
大数据离不开数据存储,数据库作为大数据业务核心,在整个基础软件栈中是非常重要的一环,正因为如此,业界追求更优的大数据存储引擎和查询引擎的脚步从未停止。目前业界已有的大数据存储、查询引擎有 Druid、Kylin、Impala等开源数据库,还有如 EMCGreenplum、HP Vertica、AWS Redshift等商用数据库。今年 8月 10日刚刚开源的百度Palo项目又是一个什么样的数据库引擎呢?它与现有的这些数据库引擎相比有何不同之处?它的性能表现如何?
今年 8月 10日晚上,百度内部服务于多个项目(包括凤巢、搜索、Feed和金融等应用)的分析型数据库 Palo正式登陆GitHub,成为开源数据库项目大军中的一员。此次开源引起了众多技术人的关注,大家都对 Palo的架构设计、性能以及 Palo与其他数据库引擎有何不同充满了好奇。InfoQ第一时间联系到了百度 Palo项目负责人马如悦,并对他进行了采访,本文整理自采访问答。
Palo是百度开发的面向在线报表和分析的数据仓库系统,可以对标于商业的 MPP数据仓库系统,比如 Greenplum、Vertica、Teradata等。Palo主要基于 C++和 Java开发,集成了GoogleMesa和 Cloudera Impala的技术。
Palo由何而来
开发百度 Palo的团队可以追述到几年前的广告部门的报表系统团队,最初这个团队主要是为百度广告系统开发供广告主查看的在线广告报表系统,由于在线广告报表系统需要满足上百万广告主的大量查询分析需求,这个使用传统MySQL分库分表的系统已经显示出诸多问题,比如运维复杂、性能跟不上、容量占用大等。而商业数据库成本高,且性能也没有想象的那么好,最大的问题是由于商业系统闭源,一旦出了问题,查找问题非常复杂。
鉴于此,当时的团队研发了第一代的 Doris系统,并使用了 2-3年。随着规模和业务需求的增加,他们开始借鉴 Google的思路,研发了百度OlapEngine,Google叫 Stats Server。OlapEngine当前一直服务于百度的凤巢和网盟广告系统,比较稳定。但是由于之前使用的是 MySQL查询层,OlapEngine实际上只是单一的为报表类型服务的存储引擎,而在分布式管理方面还比较弱。加之使用 MySQL查询,查询引擎时常成为性能瓶颈。从 2014年开始,百度开始将OlapEngine改造为分布式存储引擎,自带 sharding和 replication,然后采用 Impala作为分布式查询引擎来替代 MySQL,产品名字也定为 Palo。
开源不仅是个人信仰
从百度云的官网上我们可以找到 Palo的产品信息,也就是说其实 Palo一直是百度云的一款商用产品,那么如今决定开源的原因是什么呢?
马如悦认为,作为任何一个技术人员,开源已经成为了一种信仰,一方面是解决更多人的问题所带来的成就感,另一方面就是社区的广泛参与必定为项目带来更好的活力。
抛开技术人员的个人追求,从商业角度来讲:当前大量底层技术产品都采用开源模式,客户也愿意采用开源产品,所以大环境也会逼着你去开源;另外,在商业市场中存在着 2/8原则,即 80%的收入来自 20%的付费用户,而另外 80%的用户贡献收入并不高,然而前者无论开源与否,都可能付费;而后者则更喜欢开源产品;但是,其中最重要的一条规律是,前面 20%付费用户的选择会参考后面 80%用户的选择。因此从商业上来看,让产品开源,让 80%的用户免费使用你的产品,必然会带来很好的口碑,这直接会影响到那 20%的高付费用户,20%的这群高付费用户更多地关注服务。
所以,对于未来的技术产品,开源可能成为必须,这个必须不一定损害商业模式,反而会促进商业上的成功。
Palo的架构设计
在介绍 Palo架构之前首先说一下 Palo和百度云上 Palo产品的区别。Palo Cloud版本不仅包含 Palo这个 Core,还会为云端的按需部署进行产品化功能补充,所以可以粗略的认为 Palo Cloud是 Palo云化的一个产品,开源的 Palo可以认为是 Palo Cloud里面的 Palo Core。下面 2张图分别给出了 Palo的架构和 Palo云化产品的总体产品架构。
Palo的架构包括前端进程和后端进程。前端负责元数据管理、集群管理、查询接收、查询规划和执行协调;后端负责管理存储和查询执行。
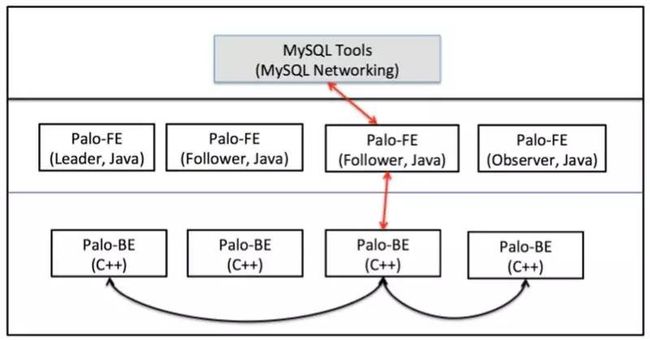
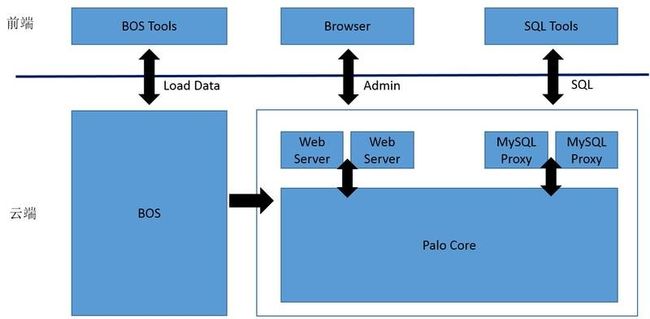
Palo的详细架构设计可以参考 https://github.com/baidu/palo。
当前开源版本的 Palo版本高于百度云上的 Palo Cloud版本内的 Palo Core,这个 Palo开源版本直接 fork了百度内部的 Palo开发分支,所以比较新,但是 Bug也可能会多一些。
另外,在百度云网站对 Palo的介绍中,小编发现了“Palo云端产品目前只支持从百度的 BOS系统导入数据,用户需要使用 BOS相关工具,将自己的数据上传到 BOS系统再导入 Palo”这样的描述。难道对于 Palo开源项目的使用者,一定要借助 BOS才能向 Palo中导入数据吗?这是否会给用户带来不便呢?
对于这个疑问,马如悦也给出了解答:Palo当前支持通过 http的 mini-batch的 push导入方式,也支持从 BOS、HDFS等进行拉取的 batch导入,还支持将很多计算 offload到hadoop上的 bulk-batch的大批量导入。当前开源版本还不能支持 bulk-batch的大批量导入,未来代码整理好后会开源出来。
Palo的应用场景
在百度,数据分析典型会分为两层系统来完成,底层是由 Hadoop、Spark构成的离线数据分析系统,这些系统提供对数据的批量和流式处理;上层系统主要由 Palo这种数据仓库系统来提供在线的数据服务。底层的离线系统完成类似 ETL的数据处理后,按照业务需求,将处理后的聚合数据灌入上层的 Palo系统供在线用。Palo最擅长报表、多维分析,而离线系统对 ad-hoc的分析是比较有优势的。
在 Palo之前,百度的各类分析主要是两种形式。
一个是写 MR程序,例行的在 Hadoop上计算,然后将计算的结果用邮件或者网页的形式呈现给用户。这种报表的问题是,很多报表基本都是从头计算,中间有大量的重复计算。另外,如果用户有新的需求,也需要 RD配合写程序来完成,交付较慢。与此同时,很多报表用户是不会每次都看的,于是有很多报表的计算就浪费掉了。对于那些在线实时访问的报表需求,MR计算这种方式更是支持不了。
另一个分析的形式是使用 MR计算后,将中间结果写入 MySQL,然后上层的应用从 MySQL中查询分析,但是受限于 MySQL的处理能力,一般存储的都是要查询的最终结果,无法满足新的报表需求,也无法满足稍微耗计算的很多多维分析需求。
Palo的出现就解决了上面两种形式的问题。根据在线可能对数据的需求,比如利用 Hadoop这种离线系统,先将接近 TB级别的原始数据处理成 GB级别的中间数据,然后将这些中间数据写入 Palo,这之后上层业务就可以灵活地使用这些中间数据来按需查询,得出自己需要的结果。
Palo的主要应用场景就是那些进行在线聚合分析的各类报表和多维分析,同时也支持分钟级别的数据小批量导入。Palo专注于小批量导入,废弃了实时导入,主要是为了解决导入原子性和一致性的需求,比如同时导入两张表,可以做到要么全部导入成功,要么都导入不成功。同时小批量导入大大增强了系统的导入性能。除此之外,Palo能够满足互联网这种在线系统的需求,即无论是查询前端节点,还是后端存储执行节点,还是元数据节点,全部都是高可用的,并且查询节点和存储节点都可以按需扩展。这一点是离线系统和很多商业数据库难以达到的。
大家对百度统计这个产品可能有所了解,它类似于Google Analytics系统。百度统计系统的后端数据库系统使用的就是 Palo,只用了大约 60多台 SATA的硬盘机器,就支撑了近几百 TB的存储,和峰值 2000qps的查询,这都得益于 Palo的列式存储带来的高效压缩和高查询性能。
性能不该是唯一关注点
对于众多大数据人高度关注的 Palo的性能测试数据,非常遗憾,由于 Palo性能测试数据目前还在整理中,今天的文章里暂时无法给出详细的测试数据了。但数据整理完很快会放到 GitHub上,相信不会让大家久等。为了不让大家失望,马如悦也和我们分享一些粗略的数字。
Palo使用了Mesa的存储模型,所以如果你的存储是可以按照维度聚合的,建议根据业务需求建立不同的 rollup表,比如天表、月表,也可以按照其他维度建立相应的 rollup,并且建议根据日期为表建立两层分区。如果按照这种方式建表,对于大部分的查询,Palo比很多大家已知的数据库可能会有 5到 10倍的性能提升。
大家如此好奇 Palo的性能,马如悦对此也有话要说。
小米的雷军卖手机时曾在 PPT上打出了“不服跑个分”的豪言壮语,苹果和小米手机的高低之分难道仅仅是那个性能跑分吗?
马如悦认为系统性能固然重要,但不该是选型和使用的唯一关注点。他提到了两点:第一,很多系统大家可能因为不了解,所以感觉系统性能很差。数据库产品需要大家认真去了解其擅长之处后,去努力用好,基本上这一领域还不能达到傻瓜式的使用方式。他所在的团队曾经接触过一个政府部门,向他们进行数据库咨询,其不断抱怨 Oracle性能太差,结果检查后发现竟然一个 Index都没有建立,根据业务需求帮其建立了 Index后性能提升了上百倍;第二,Palo从产品设计之初就不是为了追求高性能去做的,这一点在GitHub页面的 Overview里也有体现。Palo更多的是追求系统的设计简单和使用简单,当然前提是能满足性能的要求。当前刻意追求系统的高性能,很多时候造成了系统的功能缺失或者过度复杂。对于在线系统,易用易部署易维护更加重要。百度内部也有很多用户用过 Impala+HBase+HDFS,还有 Kylin(依赖 HBase和 Hive),这些系统的性能暂且不提,主要是依赖很多其它系统,部署维护都很成问题,尤其对于在线系统。所以这些用户最后都转向了 Palo,原因就是 Palo不管是部署还是维护用起来都太简单了。总得来说,一个好用的系统,不能仅仅是性能好,而是其他方面也优秀。
Palo的不同之处?
如今业界已经有了这么多大数据分析和搜索引擎,如 Druid、Kylin、Impala等,还有同样采用 MPP架构的实时查询系统 EMCGreenplum、HP Vertica和 Google Dremel,Palo与这些数据库引擎或系统相比有何不同?Palo的优势在哪里?
从宏观上来说,互联网公司对分析型数据库的需求远高于传统企业对分析型数据库的需求,这其中包括性价比、高可用、高扩展、高稳定性。Palo是在百度内部大量使用的系统,在功能取舍上都是为了满足实际业务问题去解决和优化,并且 Palo系统由百度自己运维,团队了解其在一线急需的需求。马如悦认为,很多研发这些系统的公司,自己并不是其用户或典型用户,所以很难拿到最直接的用户需求,这是 Palo的优势之一。
从其他方面来说,Palo的优势还有以下几点。
易用性。从百度团队了解到的当前用户的很多需求,易用性已经排在了选择产品的第一要求下。而很多开源产品,部署使用都非常复杂,很多商用产品也不便于使用。而 Palo本身不依赖任何第三方系统,只有 2个进程,使用MySQL协议,所以易用性非常好。
高可用。Palo为了满足在线系统的需求,考虑到了 24*7的高可用需求,全系统无任何单点设计。这个在很多商用系统上并不是第一考虑,因此很多系统都存在单点。
易扩展。很多系统,尤其商业系统,后端系统虽然可以扩展,但是查询节点是单点,而越来越高的并发查询需求是原来传统商业数据库未曾考虑到的,毕竟很多传统商业数据仓库是为了满足内部数据报表和分析的需求,而没有考虑到当今大量报表的时效性和面向大量外部用户的需求。大家可以考虑一下,为什么像电信或者银行很多系统都不让你查超过半年或者一年以前的详单或者账单,这些系统很多都使用了商用数据库,而这些数据库应对这种数据规模时就会捉襟见肘。百度统计每年花费 50万人民币的成本,可以让上百万网站主实时查询 10年的网站统计数据。
对于 Palo系统的扩展性,马如悦进行了补充说明。根据当前硬件节点的配置,对于绝大部分公司,100节点基本是上限,已经可以支持到 1PB的存储,部署 5到 10个 FE节点,即可达到 10w-20wqps,对于绝大部分业务够用了。工商银行使用了Teradata,也就 100节点左右,百度内部的 Palo单一业务还未到达 100节点。所以 Palo当前可以扩展到 100节点,10w-20wqps, 1PB存储是设计的目标,并且经过实际测试和验证。更高的扩展还没有测试过,但马如悦认为扩展到 200或者 300不成问题。
最新技术的使用。Palo使用了当前很多最新的技术,比如 Nvme SSD,两层存储介质;LLVM和向量化执行;最新的列式存储技术;Hyperlog、bloomfilter;Cgroup等资源隔离技术。面对计算新技术 (GPU,FPGA)、存储新技术(Nvme SSD)、网络新技术 (RDMA),百度一直在不断改进 Palo,以便吸收这些新技术。而很多传统商业数据库对这些新技术的跟进速度太慢。
与开源数据库对比。Druid没有原生 SQL查询支持;Kylin需要大量预计算,存储会暴增,而没有预计算的可能无法查询;Impala只是查询引擎,而没有存储引擎。同时这些系统都存在前面提到的重大问题,就是依赖复杂、部署复杂。
随着各种硬件技术的进步,产生了越来越多的系统依赖,很多用户现在迫切需要的是尽量用一套系统完成更多的工作,而不是为了完成很多近似的需求而去部署多套系统。Google在今年年中发布的 Spanner论文就提到,未来 OLAP和 OLTP一定会逐渐融合。马如悦说到:“很多人还是很期待‘LAMP’走遍天下的感觉,现在的各种系统太多了,优秀的太少。在这方面,不管 Spark未来能走多远,但是 Spark那种追求尽量在一套系统解决大部分数据分析问题的志向,我还是为其点赞。在 OLTP领域,NewSQL已经进行的如火如荼,我自己是这个领域的极大推动者,在百度我们已经投入了大量人力去开发 NewSQL,NewSQL系统的出现和成熟未来会取代 OldSQL和 NoSQL的绝大部分使用场景,这是个高维对低维的战争,要么不成功,要是成功,对老系统是摧枯拉朽的替代。”
未来展望
当然 Palo也并不完美,目前 Palo较大的缺点是产品化比较差,周边工具、文档等较少,还不如商业产品那样完善。
从技术上来说,Palo下一步要支持实时导入、支持更多索引,也会融合 Elasticsearch的一部分功能进来;从更长远的角度来看,包括GPU、FPGA的加速支持也在调研之中。很多使用Palo的用户对上层的可视化系统也有较大的需求,所以百度也投入了很多人力去开发新一代的可视化分析系统。马如悦透露,这个新的可视化分析系统将不同于大家现在见到的 Tableau和 Qlik等系统,会有一些新的创新理念。
作者介绍
马如悦,百度开源技术委员会成员,百度大数据主任架构师。百度分布式计算和存储团队的创始人,曾领导Hadoop团队、在线数据库团队,当前是百度大数据架构技术及产品的研发负责人。其团队负责百度所有大数据相关技术和产品的研发,同时也支持百度云大数据相关产品的研发。