提交的应用程序
Spark的bin目录中的Spark -submit脚本用于在集群上启动应用程序。它可以通过一个统一的接口使用所有Spark支持的集群管理器,这样您就不必为每一个都配置您的应用程序。
绑定应用程序的依赖关系
如果您的代码依赖于其他项目,您将需要将它们与应用程序一起打包,以便将代码分发到Spark集群中。为此,创建一个包含代码及其依赖项的编译jar(或“uber”jar)。sbt和Maven都有编译插件。在创建编译jar时,按提供的依赖项列出Spark和Hadoop;这些不需要绑定,因为它们是由集群管理器在运行时提供的。一旦您有了一个编译好的jar,您就可以调用bin/spark提交脚本,如这里所示,同时传递您的jar。
对于Python,您可以使用spark-submit的——py-files参数来添加.py、.zip或.egg文件,以便与应用程序一起分发。如果您依赖于多个Python文件,我们建议将它们打包成.zip或.egg。
启动应用程序与spark-submit
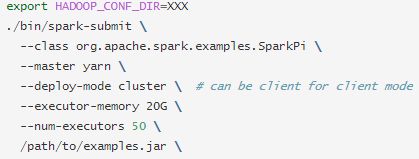
一旦绑定了用户应用程序,就可以使用bin/spark提交脚本启动它。这个脚本负责设置带有Spark及其依赖项的类路径,并可以支持不同的集群管理器和Spark支持的部署模式:

(由于对于某些标签不识别 只能用图片了)
常用的选择:
--class: 应用程序的入口点(例如org.apache.spark.examples.SparkPi,自己程序的入口)
--master: 集群的主URL(例如spark://23.195.26.187:7077,一般用yarn管理,所以直接用yarn即可)
--conf: 任意Spark 配置属性用 键=值 格式表示。对于包含空格的值,将“key=value”用引号括起来
application-jar:包含应用程序和所有依赖项的打包jar的路径。URL必须在集群内部全局可见,例如,所有节点上都有hdfs://路径或文件://路径。
application-arguments: 传递给主类的主方法的参数
提交方式:
一种常见的部署策略是从物理上与工作机器共存的网关机器(例如,独立EC2集群中的主节点)提交应用程序。在这种设置中,client mode是合适的。在client mode下,驱动程序直接在spark-submit过程中启动,该过程充当集群的客户机。应用程序的输入和输出附加到控制台。因此,这种模式特别适用于涉及REPL(如Spark shell)的应用程序。
或者,如果您的应用程序是从远离工作机器的机器(例如本地的笔记本电脑上)提交的,那么通常使用集群模式来最小化驱动程序和执行程序之间的网络延迟。目前,standalone mode不支持Python应用程序的集群模式。
有一些特定于正在使用的集群管理器的可用选项。例如,使用带有集群部署模式的Spark独立集群,您还可以指定—supervision以确保如果驱动程序在非零退出代码的情况下失败,它将自动重新启动。要枚举用于spark-submit的所有此类选项,请使用—help运行它。下面是一些常见选项的例子:





Master URLs
传递给Spark的主URL可以是以下格式之一
Master URL->Meaning
local->使用一个工作线程在本地运行Spark(即根本没有并行性)
local[K]->使用K个工作线程在本地运行Spark(理想情况下,将其设置为机器上的内核数)。
local[*]->在计算机上运行Spark,工作线程数量与逻辑核心数量相同。
spark://HOST:PORT->连接到给定的Spark独立集群主服务器。端口必须是您的主配置要使用的端口,默认为7077。
mesos://HOST:PORT->连接到给定的Mesos集群。端口必须是配置为使用的端口,默认为5050。或者,便集群使用管理员,使用便:/ / zk:/ / ....要使用——deployment -mode集群提交,应该将主机:端口配置为连接到MesosClusterDispatcher。
yarn->根据-deploy-mode的值,以客户机或集群模式连接到yarn集群。集群位置将基于hadoop op_conf_dir或YARN_CONF_DIR变量找到
从文件加载配置
Spark -submit脚本可以从属性文件加载默认的Spark配置值,并将其传递给应用程序。默认情况下,它将从conf/spark-defaults中读取选项。conf在Spark目录中。
以这种方式加载默认的Spark配置可以避免某些标志需要spark-submit。例如,如果 spark.master已设置,您可以安全地从spark-submit中省略 --master标志。通常,在SparkConf上显式设置的配置值具有最高的优先级,然后将标记传递给spark-submit,然后是默认文件中的值
如果您一直不清楚配置选项来自哪里,那么可以通过使用—verbose选项运行spark-submit来打印细粒度调试信息。
先进的依赖管理
在使用spark-submit时,应用程序jar以及—jars选项中包含的任何jar都将自动转移到集群中。jar之后提供的url必须用逗号分隔。该列表包含在驱动程序和执行程序类路径中。目录扩展不适用于--jars。
Spark使用以下URL模式来允许不同的策略来传递jars:
file:-绝对路径和文件:/ uri由驱动程序的HTTP文件服务器提供,每个执行程序都从驱动程序HTTP服务器提取文件。
hdfs:, http:, https:, ftp:-这些按预期从URI中拉下文件和jar
local: 一个以local:/开头的URI应该以本地文件的形式存在于每个工作节点上。这意味着不会产生网络IO,对于推送到每个工作者的或通过NFS、GlusterFS等共享的大型文件/ jar也可以很好地工作。
注意,jar和文件被复制到执行器节点上的每个SparkContext的工作目录中。随着时间的推移,这会占用大量的空间,需要清理。对于YARN,清理是自动处理的,而对于Spark独立的,可以设置spark.worker.cleanup.appDataTtl参数进行自动清理
用户还可以通过使用-packages提供以逗号分隔的maven坐标列表来包含任何其他依赖项。使用此命令时将处理所有传递依赖项。其他存储库(或SBT中的解析器)可以以逗号分隔的方式与标志存储库一起添加。(注意,有密码保护的凭证存储库可以提供在某些情况下在存储库中URI,比如https://user password@host / ....以这种方式提供凭证时要小心。这些命令可以与pyspark、Spark -shell和Spark -submit一起使用,以包含Spark Packages.
spark-submit 详细参数说明
参数名->参数说明
--master-> master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local
--deploy-mode-> 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
--class-> 应用程序的主类,仅针对 java 或 scala 应用
--name-> 应用程序的名称
--jars ->用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下
--packages ->包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标
--exclude-packages ->为了避免冲突 而指定不包含的 package
--repositories-> 远程 repository
--conf PROP=VALUE ->指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m"
--properties-file-> 加载的配置文件,默认为 conf/spark-defaults.conf
--driver-memory ->Driver内存,默认 1G
--driver-java-options-> 传给 driver 的额外的 Java 选项
--driver-library-path-> 传给 driver 的额外的库路径
--driver-class-path ->传给 driver 的额外的类路径
--driver-cores ->Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
--executor-memory ->每个 executor 的内存,默认是1G
--total-executor-cores ->所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用
--num-executors ->启动的 executor 数量。默认为2。在 yarn 下使用
--executor-core-> 每个 executor 的核数。在yarn或者standalone下使用
PS:此文是我的学习笔记,来源官网,在工具翻译的基础上进行了修改 仅供参考