ELK--Logstash入门
1.前言
Logstash是一款由ruby编写的开源数据采集工具。其支持对多种不同的数据源进行采集,并进行自定义处理,然后传输到指定位置。为后续的数据分析、可视化等应用提供支持。
1.2版本
近期,ELK版本迭代速度飞快。在本文中采用的版本为5.3.1。
1.3安装与部署
- 下载地址:https://www.elastic.co/downloads/logstash
下载tar.gz格式,直接解压(tar -zxf logstash.tar.gz) - 需要安装JDK 1.8以上的环境
2.Logstash
从数据源到存储端,Logstash的工作共分为三个过程:数据采集、数据处理(可选)、数据输出。对应的三个插件Input、Filter(可选)、Output来完成相应的工作。
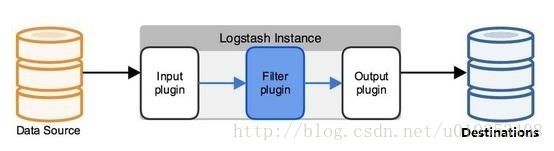
2.1 Input介绍
Input插件能够从多种数据源中采集数据,例如:File、Kafka、Beats、Redis等。
2.1.2 Input应用实例
1.从file中采集数据
input {
file {
path=> [ "/root/example/*.log" ]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
注解:
1. path=> [ "/root/example/*.log" ] 读取指定目录下,所有以.log结尾的文件。
2. start_position => "beginning" 从文件头开始读取数据,默认为从文件结尾开始读取。
3. sincedb_path => "/dev/null" Logstash会将每个文件的读取状态保存到sincedb_path指定的文件中,下次读取的时候会从上次中断的地方开始。这里将sincedb_path指向一个空目录,以便每次读取的时候都能从头开始。
2.从kafka中采集数据
input {
kafka{
bootstrap_servers => "host1:9092,host2:9092"
topics=>'example'
group_id => 'example01'
enable_auto_commit => false
auto_offset_reset => 'earliest'
consumer_threads => 6
codec =>'json'
}
}
注解:
1.enable_auto_commit => false 禁止Logstash自动提交当前topic被消费的offset位置。
2.auto_offset_reset => 'earliest' 从topic最早的offset开始消费。
3.consumer_threads => 9 消费者的数量。
2.2.1 Filter介绍
Filter接受从Input传过来的数据,并对数据进行指定的处理。
2.2.2Filter应用实例
1.Grok正则解析
#从message中,按照如下规则解析出date、p1等字段
filter {
grok{
match=>{"message"=>"%{DATESTAMP:date}|%{DATA:p1}|%{WORD:p2}|%{UUID:p3}|%{DATA:p4}|%{GREEDYDATA:p5}"}
}
}
2.日期处理
#使用日志中date字段中的日期,替换@timestamp的值
filter{
date{
#按照指定格式匹配时间
match => [ "date","yy-MM-dd HH:mm:ss" ]
#将match到的时间赋值给指定字段
target => "@timestamp"
}
}
3.Mutate数据修改
#将timestamp中的时间精度保留到秒级(当前为毫秒级)
filter{
grok{
match=>{"message"=>"%{DATESTAMP:date}|%{DATA:p1}|%{WORD:p2}|%{UUID:p3}|%{DATA:p4}|%{GREEDYDATA:p5}"}
}
mutate{
#在date中,以.为分隔符,进行字符串分割
split=>{"date" => "."}
#添加new_date字段,并用分割后的date[0]进行赋值
add_field => {"new_date" => "%{[date][0]}"}
}
date{
match => [ "new_date","yy-MM-dd HH:mm:ss" ]
target => "@timestamp"
}
mutate{
#删除字段
remove_field => [ "date","path","host"]
}
}
4.Ruby
#将timestamp中的时间精度保留到秒级(当前为毫秒级)
filter{
grok{ match=>{"message"=>"%{DATESTAMP:date}|%{NUMBER:g1}|%{NUMBER:g2}|%{DATA:p1}|%{WORD:p2}|%{UUID:p3}|%{DATA:p4}|%{GREEDYDATA:p5}"}
}
#使用ruby中的时间函数对日志中的时间进行格式处理
ruby{
code => 'event.set("new_time",Time.parse(event.get("date")).strftime("%Y-%m-%d"))'
}
date{
match => [ "new_date","yy-MM-dd" ]
target => "@timestamp"
}
}
2.3.1 Output介绍
Output能够将接受到的数据传输到多种不同的目的地。例如:Kafka、File、ElasticSearch、HDFS等。
2.3.2 Output应用实例
1.输出到Kafka
output{
kafka{
bootstrap_servers => "host1:9092,host2:9092"
topic_id => "example02"
codec => json
}
}
2.输出到File
output{
file{
path=>"/root/output/example/output.txt"
}
}
3.输出到ElasticSearch
output{
elasticsearch{
hosts => ["host1:9200"]
sniffing => true
index => "example-index"
flush_size => 100
pool_max => 2000
pool_max_per_route =>200
}
}
注解:
1.sniffing => true 获取ES所有节点,并将这些节点添加进hosts参数中。将该参数置为true,host=>[]中只填写一个ES的节点地址即可。
2.index => "example-index" 在ES中建立的索引名称。
3.flush_size => 100 Logstash积攒100条event然后发送给ES。
4.pool_max => 2000 Logstash与ES的连接池中,最多可以创建2000个连接,超过这个数量时,会尝试重用连接池的连接。
5.pool_max_per_route 每个Logstash进程能够创建最大的连接数量。
4.输出到HDFS
output {
webhdfs {
host => "host1"
port => 50070
path => "/example/dt=%{+YYYY-MM-dd}/logstash-%{+HH}.log"
user => "example"
compression => "snappy"
flush_size => 10000
idle_flush_time => 2
standby_host => "host2"
standby_port => 50070
}
}