CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes2018—论文笔记
本论文来自CVPR2018, 读于20190409。
Abstract
我们提出的Congested Scene Recognition(CSRNet)包含了两个部分,一个是获得二维特征的前端,一个是使用膨胀CNN(dilated CNN)的后端。
我们在最常用的那四个数据集((ShanghaiTech dataset, the UCF CC 50 dataset, the WorldEXPO’10 dataset, and the UCSD dataset)都比之前的方法表现都好,而且用在TRANCOS这个数据集去识别车辆的数量,表现也优于之前的算法。
1 Introduction
之前关于拥堵场景的人群计算一般都是基于multi-scale architecture,例如CVPR16年的一篇论文《Single-Image Crowd Counting via Multi-Column Convolutional Neural Network》(MCNN)。
16年到17年的论文基本上都是基于MCNN的。本文将MCNN和一个简单的深度CNN作对比,发现一个单独的deeper CNN甚至比MCNN效果更好,如表1所示:

选择MCNN这个算法的主要原因是可以根据不同的尺寸灵活改变receptive fields,在不同尺寸下得到的特征不一样。但是通过separated colunmns(分为large、medium和small receptive fields)去学习不同的特征,发现学习到的特征是相似的。如图2所示。所以其实是没有达到提出MCNN这个算法的初衷的。

采用MCNN存在以下四个问题:
- MCNN比较难训练,要花费一定的时间;
- 如表1所示,MCNN引入了冗余的网络结构;
- 需要密度分类器(density level classifier),提高了计算量;
- 网络很大一部分的参数都是来自密度分类器(density level classifier),而用于估计density map的参数只占所有参数很小的一部分。
在我们的论文中,我们设计了一个深度的网络称为CSRNet。为了限制网络的复杂度,我们在所有层都使用最小尺寸的卷积过滤器(3x3)。我们利用VGG16的前十层作为我们的前端,利用膨胀卷积层(dilated convolution layers)作为后端来扩大receptive fields和在不丢失分辨率的情况下提取更深的特征(因为没有用池化层)。
3. Proposed Solution
有效的利用deeper CNN通过larger receptive fields捕获high-level特征,也不通过提高网络的复杂度来得到高质量的密度图。
3.1. CSRNet architecture
参考了三篇论文(其中17年的两篇论我看过了),我们选择VGG16作为CSRNet的前端(front-end)是不仅因为VGG16强大的迁移学习能力,还可以很灵活的与后端(back-end)连起来,从而得到density map。但是《Crowdnet: a deep convolutional network for dense crowd counting》这篇论文对VGG16修改之后的效果微乎其微,《Switching convolutional neural network for crowd counting》和《Generating highquality crowd density maps using contextual pyramid CNNs》这两篇论文用VGG16都是为了分类,对生成density map只是起一个辅助的作用,并没有很大程度提高最终的准确度。
输出的尺寸如果很小会很难得到high-quality density map。所以我们使用VGG16删掉了全连接网络层之后的所有层,后面也没有添加新的卷积层和池化层。
3.1.1 Dilated convolution
我们的设计中最关键的部分就是膨胀卷积层(dilated convolution layer)。

x(m,n)是输入图片,w(i,j)是过滤器,r是膨胀率(dilation rate)。当r=1时,dilated convolution就是一个普通的卷积运算。
膨胀卷积层(dilated convolutional layers)能够提高图像分割的准确性,也能很好的替代池化层。
池化层的主要两个优点:
- 保持不变性;
- 有效抑制过拟合。
池化层的主要缺点:
- 减少空间分辨率;
- 会丢失一些空间特征信息。
而去卷积层(deconvolutional layers)虽然能够减少信息的丢失,但是却提高了复杂度。
综上,膨胀卷积层是最好的选择,使用稀疏核(sparse kernels)来代替池化层和卷积层。这样可以在不断增加参数的数量和计算量的情况下,增大receptive field(例如,增加卷积层虽然能增大receptive field,但是会提高计算量)。
原始大小为kxk的过滤器,若膨胀步长为r,得到的过滤器的边长被扩大为k+(k-1)(r-1),如图3所示。所以当保持相同分辨率的情形下,能够更加灵活地收集一些multi-scale contextual information。
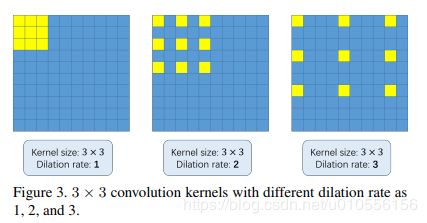
图4展示了两种方法的对比:
上面一排使用的方法是:先通过池化层降采样,然后过一个3x3 sobel kernel的卷积层,最后过一个deconvolutional layer(用的双线性插入)上采样,将图片恢复到和原始图片相同的尺寸;
下面一排使用的方法是:通过一个dilation rate为2,尺寸为3x3的sobel kernel的dilated convolution。
通过对比,使用dilated convolution保留了更多的细节信息。

3.1.2 Network Configuration
根据论文《Very deep convolutional networks for large-scale image recognition》,在receptive field是相同尺寸的情况下,层数多(kernel的尺寸小)会比层数少(kernel尺寸大)更有效。
我们提出了四种CSRNet网络的配置,具体如表3所示。前端的配置相同,而后端的dilated convolution有四种不同dilation rate。前端采用VGG16的前十层,对参数和结构进行了一些微调,其中只使用3x3的核,并且使用三层池化层来代替掉原来的五层。

CSRNet输出的density map只有原始图片1/8的大小,所以最后会使用一个双线性插入来使density map扩展到原始图片相同的大小。
3.2. Training method
3.2.1 Ground truth generation
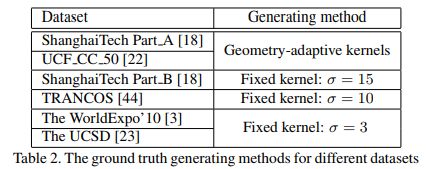
根据论文《Single-Image Crowd Counting via Multi-Column Convolutional Neural Network》。为了生成density maps,我们使用了geometry-adaptive kernels来处理拥挤的场景(highly congested scenes)。使用Gaussian kernel处理稀疏人群(sparse crowd)。
geometry-adaptive kernels公式如下:

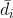 表示k个相邻人头的平均距离;
表示k个相邻人头的平均距离; 表示标准偏差;
表示标准偏差; 表示人头位置的像素点;
表示人头位置的像素点;- 取

Gaussian kernel针对不同的数据集设置的参数不一样,详细如表2所示。
3.2.2 Data augmentation
我们从原图剪切9张只有原图1/4大小的patches。其中4张就是将原图无重叠的分割成4份剩下5张随机剪裁。然后我们再做一次镜像的操作,一共得到18张patches。
3.2.3 Training details
前十层卷积层使用VGG16已经训练好了的参数进行微调。Gaussian kernel的标准偏差初始化为0.01、随机梯度下降(stochastic gradient descent)的学习率固定为1e-6。损失函数采用Euclidean距离,损失函数的公式如下:

- N表示the size of training batch;
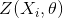 表示CSRNet的输出;
表示CSRNet的输出; 表示CSRNet网络的所有参数;
表示CSRNet网络的所有参数; 表示输入的图片;
表示输入的图片;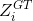 表示the ground truth。
表示the ground truth。
4 Experiments
4.1. Evaluation metrics

4.2. Ablations on ShanghaiTech Part A

4.3. Evaluation and comparison
4.3.1 ShanghaiTech dataset


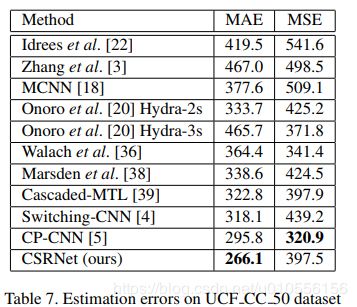
4.3.2 UCF CC 50 dataset
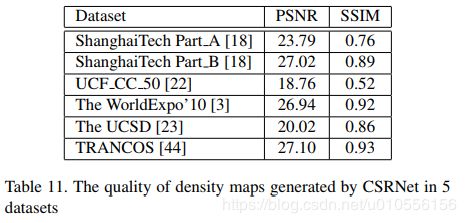
4.3.3 The WorldExpo’10 dataset

4.3.4 The UCSD dataset

4.3.5 TRANCOS dataset


5 Conclusion
CSRNet can expand the receptive field without losing resolution
代码
- https://github.com/leeyeehoo/CSRNet-pytorch
- https://github.com/wkcn/CSRNet-mx
- https://github.com/tlokeshkumar/CSRNet-tf
- https://github.com/Neerajj9/CSRNet-keras