【T-Tensorflow框架学习】Tensorflow “计算图”入门理解
#
- Tensorflow 不是一个普通的 Python 库。大多数 Python 库被编写为 Python 的自然扩展形式。当你导入一个库时,你得到的是一组变量、函数和类,它们补充并扩展了你的代码“工具箱”。使用这些库时,你知道它们将产生怎样的结果。
- 我认为谈及 Tensorflow 时应该抛弃这些认识,这些认知从根本上就不符合 Tensorflow 的理念,无法反映 TF 与其它代码交互的方式。pthon 和 Tensorflow 之间的联系,可以类比 Java 和 HTML 之间的关系。Java 是一种全功能的编程语言,可以实现各种出色的效果。HTML 是用于表示某种类型的实用计算抽象(这里指的是可由 Web 浏览器呈现的内容)的框架。Java 在交互式网页中的作用是组装浏览器看到的 HTML 对象,然后在需要时通过将其更新为新的 HTML 来与其交互。
- 与 HTML 类似,Tensorflow 是用于表示某种类型的计算抽象(称为“计算图”)的框架。我们用 Python 操作 Tensorflow 时,我们用 Python 代码做的第一件事是组装计算图。之后我们的第二个任务就是与它进行交互(使用 Tensorflow 的“会话”)。
- 但重要的是,要记住计算图不在变量内部,它处在全局命名空间内
第一个关键抽象:计算图
'''
Creat by HuangDandan
[email protected]
2018-08-25_26
Tensorflow 不是一个普通的 Python 库。
Tensorflow 是用于表示某种类型的计算抽象(称为“计算图”)的框架。
我们用 Python 操作 Tensorflow 时,我们用 Python 代码做的第一件事是组装计算图。
之后我们的第二个任务就是与它进行交互(使用 Tensorflow 的“会话”)。
但重要的是,要记住计算图不在变量内部,它处在全局命名空间内。
'''
'''
第一个关键抽象:计算图
0-仅仅导入 Tensorflow 并不会给我们生成一个有趣的计算图,而只有一个孤独的,空白的全局变量
1-当我们调用tf.constant ,得到了一个节点,它包含常量:
当我们打印这个变量时,我们看到它返回一个 tf.Tensor 对象,它是一个指向我们刚创建的节点的指针。
2-每次我们调用 tf.constant 的时候,我们都会在图中创建一个新节点。
即使节点在功能上与现有节点完全相同,即使我们将节点重新分配给同一个变量,甚至我们根本没有将其分配给变量,结果都一样。
3-相反,如果创建一个新变量并将其设置为与现有节点相等,则只需将该指针复制到该节点,并且不会向该图添加任何内容
4-现在我们来看——这才是我们要的真正的计算图表!
请注意,+ 操作在 Tensorflow 中过载,所以同时添加两个张量会在图中增加一个节点,尽管它看起来不像是 Tensorflow 操作。
two_node 指向包含 2 的节点,three_node 指向包含 3 的节点,
而 sum_node 指向包含... + 的节点?什么情况?它不是应该包含 5 吗?事实证明,没有。计算图只包含计算步骤,不包含结果。至少...... 还没有!
'''
#01
import tensorflow as tf
two_node = tf.constant(2)
print(two_node)
#02
import tensorflow as tf
two_node = tf.constant(2)
another_two_node = tf.constant(2)
two_node = tf.constant(2)
print(tf.constant(3))
#03
import tensorflow as tf
two_node = tf.constant(2)
another_two_node = two_node
two_node = None
print(two_node)
print(another_two_node)
#04
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
print(two_node)
print(sum_node)
输出:
01输出:
Tensor(“Const:0”, shape=(), dtype=int32)
03输出:
None
Tensor(“Const:0”, shape=(), dtype=int32)
04输出:
Tensor(“Const:0”, shape=(), dtype=int32)
Tensor(“add:0”, shape=(), dtype=int32)
第二个关键抽象:会话
'''
第二个关键抽象:会话
会话的作用是处理内存分配和优化,使我们能够实际执行由图形指定的计算。
可以将计算图想象为我们想要执行的计算的“模板”:它列出了所有的步骤。
为了使用这个图表,我们还需要发起一个会话,它使我们能够实际地完成任务。
例如,遍历模板的所有节点来分配一组用于存储计算输出的存储器。
为了使用 Tensorflow 进行各种计算,我们既需要图也需要会话。
会话包含一个指向全局图的指针,该指针通过指向所有节点的指针不断更新。
这意味着在创建节点之前还是之后创建会话都无所谓。
创建会话对象后,可以使用 sess.run(node) 返回节点的值,并且 Tensorflow 将执行确定该值所需的所有计算。
一般来说,sess.run() 调用往往是最大的 TensorFlow 瓶颈之一,所以调用它的次数越少越好。
可以的话在一个 sess.run() 调用中返回多个项目,而不是进行多个调用。
'''
import tensorflow as tf
two_node = tf.constant(2)
three_node = tf.constant(3)
sum_node = two_node + three_node
sess = tf.Session()
print(sess.run(sum_node))输出:
5
占位符和 feed_dict
'''
占位符和 feed_dict
我们迄今为止所做的计算一直很乏味:没有机会获得输入,所以它们总是输出相同的东西。
一个实用的应用可能涉及构建这样一个计算图:它接受输入,以某种(一致)方式处理它,并返回一个输出。
最直接的方法是使用占位符。占位符是一种用于接受外部输入的节点。
占位符被赋予一个值,为了提供一个值,我们使用 sess.run() 的 feed_dict 属性。
直接传递给run()回报错,必须通过 feed_dict方法 传递给session.run(), Tensor.eval(),或者Operation.run()
注意传递给 feed_dict 的数值格式。这些键应该是与图中占位符节点相对应的变量(如前所述,它实际上意味着指向图中占位符节点的指针)。
相应的值是要分配给每个占位符的数据元素——通常是标量或 Numpy 数组
'''
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
sess = tf.Session()
print(sess.run(input_placeholder,feed_dict={input_placeholder: 2}))
第三个关键抽象:计算路径
'''
第三个关键抽象:计算路径
当我们在依赖于图中其他节点的节点上调用 sess.run() 时,我们也需要计算这些节点的值。如果这些节点有依赖关系,
那么我们需要计算这些值(依此类推......),直到达到计算图的“顶端”,也就是所有的节点都没有前置节点的情况
根据图的结构,我们不需要计算所有的节点也可以评估我们想要的节点!
因为我们不需要评估 placeholder_node 来评估 three_node,所以运行 sess.run(three_node) 不会引发异常。
Tensorflow仅通过必需的节点自动路由计算这一事实是它的巨大优势。
如果计算图非常大并且有许多不必要的节点,它就能节约大量运行时间。
它允许我们构建大型的“多用途”图形,这些图形使用单个共享的核心节点集合根据采取的计算路径来做不同的任务。
对于几乎所有应用程序而言,根据所采用的计算路径考虑 sess.run() 的调用方法是很重要的。
'''
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
three_node = tf.constant(3)
sum_node = input_placeholder + three_node
sess = tf.Session()
print(sess.run(three_node))
print(sess.run(input_placeholder,feed_dict={input_placeholder: 2}))
print(sess.run(sum_node))异常:
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor ‘Placeholder’ with dtype int32
[[Node: Placeholder = Placeholder[dtype=DT_INT32, shape=, _device=”/job:localhost/replica:0/task:0/device:C
问题在于计算sum_node结点,必须要通过占位符,占位符运行的时候才会赋值,而且需要用feed_dict传入参数给run()函数,将上面的程序修改如下:
import tensorflow as tf
input_placeholder = tf.placeholder(tf.int32)
three_node = tf.constant(3)
sum_node = input_placeholder + three_node
sess = tf.Session()
print(sess.run(input_placeholder, feed_dict={input_placeholder: 2}))
print(sess.run(three_node))
print(sess.run(sum_node,feed_dict={input_placeholder: 10}))输出:
2
3
13
变量和副作用
- tensorflow中的三个节点:两种类型的“无祖先”节点:
- tf.constant(每次运行都一样)
- tf.placeholder(每次运行都不一样)。
- 还有第三种节点:通常情况下具有相同的值,但也可以更新成新值。这个时候就要用到变量。
- 了解变量对于使用 Tensorflow 进行深度学习来说至关重要,因为模型的参数就是变量。在训练期间,通过梯度下降在每个步骤更新参数,但在计算过程中,希望保持参数不变,并将大量不同的测试输入集传入到模型中。模型所有的可训练参数很有可能都是变量。
创建变量
- tf.get_variable()
tf.get_variable() 的前两个参数是必需的,其余可选的。
tf.get_variable(name,shape)。name 是一个唯一标识这个变量对象的字符串。它在全局图中必须是唯一的,所以要确保不会出现重复的名称。shape 是一个与张量形状相对应的整数数组,它的语法很直观——每个维度对应一个整数,并按照排列。
例如,一个 3×8 的矩阵可能具有形状 [3,8]。要创建标量,请使用空列表作为形状:[]。
#tf.assign()初始化
import tensorflow as tf
count_variable = tf.get_variable('count',[])
sess = tf.Session()
print(sess.run(count_variable))异常:
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value count
[[Node: _retval_count_0_0 = _RetvalT=DT_FLOAT, index=0, _device=”/job:localhost/replica:0/task:0/device:CPU:0”]]
- 问题在于:一个变量节点在首次创建时,它的值基本上就是“null”,任何尝试对它进行计算的操作都会抛出这个异常。我们只能先给一个变量赋值后才能用它做计算。有两种主要方法可以用于给变量赋值:初始化器和
tf.assign()。
两种方法创建变量:
- tf.assign()
- 初始化器
#tf.assign()初始化
import tensorflow as tf
count_variable = tf.get_variable('count',[])
zero_node = tf.constant(0.)
assign_node = tf.assign(count_variable,zero_node)
sess = tf.Session()
sess.run(assign_node)
print(sess.run(count_variable))输出:
0.0
与我们迄今为止看到的节点相比,tf.assign(target,value) 有一些独特的属性:
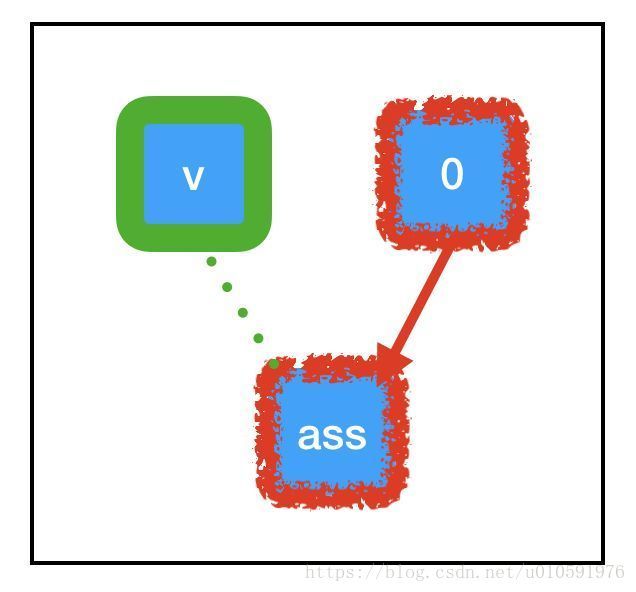
- 标识操作。tf.assign(target,value) 不做任何计算,它总是与 value 相等。
- 副作用。当计算“流经”assign_node 时,就会给图中的其他节点带来副作用。在这种情况下,副作用就是用保存在 zero_node 中的值替换 count_variable 的值。
- 非依赖边。即使 count_variable 节点和 assign_node 在图中是相连的,两者都不依赖于其他节点。这意味着在计算任一节点时,计算不会通过该边回流。不过,assign_node 依赖 zero_node,它需要知道要分配什么。
“副作用”节点充斥在大部分 Tensorflow 深度学习工作流中。当我们调用 sess.run(assign_node) 时,计算路径将经过 assign_node 和 zero_node。
当计算流经图中的任何节点时,它还会让该节点控制的副作用(绿色所示)起效。由于 tf.assign 的特殊副作用,与 count_variable(之前为“null”)关联的内存现在被永久设置为 0。这意味着,当我们下一次调用 sess.run(count_variable) 时,不会抛出任何异常。相反,我们将得到 0。
初始化器初始化变量
#初始化器
import tensorflow as tf
const_init_node = tf.constant_initializer(0.)
count_variable = tf.get_variable('count',[], initializer = const_init_node)
sess = tf.Session()
print(sess.run(count_variable))异常:
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value count
[[Node: _retval_count_0_0 = _Retval[T=DT_FLOAT, index=0, _device=”/job:localhost/replica:0/task:0/device:CPU:0”](cou
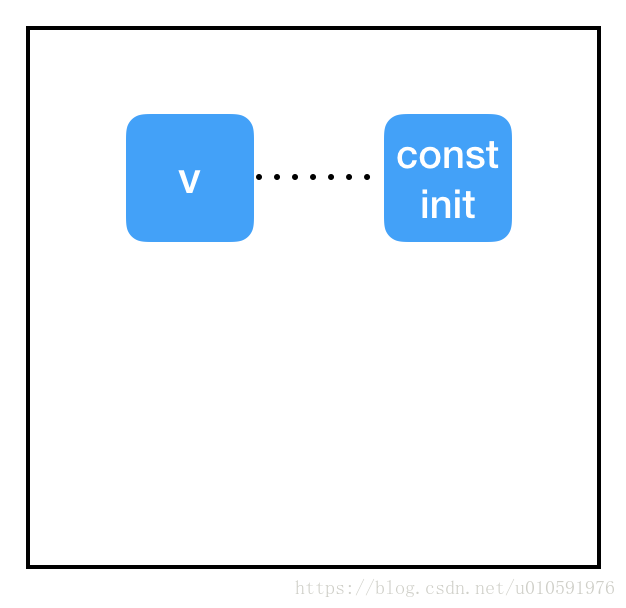
初始化器不起作用
问题在于会话和图之间的分隔。我们已经将 get_variable 的 initializer 属性指向 const_init_node,但它只是在图中的节点之间添加了一个新的连接。我们还没有做任何与导致异常有关的事情:与变量节点(保存在会话中,而不是图中)相关联的内存仍然为“null”。我们需要通过会话让 const_init_node 更新变量
#初始化器
import tensorflow as tf
const_init_node = tf.constant_initializer(0.)
count_variable = tf.get_variable('count',[], initializer = const_init_node)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print(sess.run(count_variable))
输出:
0.0
为此,我们添加了另一个特殊节点:init = tf.global_variables_initializer()。与 tf.assign() 类似,这是一个带有副作用的节点。与 tf.assign() 不一样的是,我们实际上并不需要指定它的输入!tf.global_variables_initializer() 将在其创建时查看全局图,自动将依赖关系添加到图中的每个 tf.initializer 上。当我们调用 sess.run(init) 时,它会告诉每个初始化器完成它们的任务,初始化变量,这样在调用 sess.run(count_variable) 时就不会出错。
变量共享
你可能会碰到带有变量共享的 Tensorflow 代码,代码有它们的作用域,并设置“reuse=True”。强烈建议不要在代码中使用变量共享。如果你想在多个地方使用单个变量,只需要使用指向该变量节点的指针,并在需要时使用它。换句话说,对于打算保存在内存中的每个参数,应该只调用一次 tf.get_variable()。
在深度学习中,典型的“内循环”训练如下:
获取输入和 true_output
根据输入和参数计算出一个“猜测”
根据猜测和 true_output 之间的差异计算出一个“损失”
根据损失的梯度更新参数
参考文章:
http://www.sohu.com/a/238210167_473283
https://blog.csdn.net/tz_zs/article/details/80847165