Tensorflow实现YOLOv2(亲测有效!)
一、全部代码如下:
代码部分tf函数见下面第二部分。
yolo2的预测过程大致分为以下3部分。
1、model_darknet19.py:yolo2网络模型——darknet19。
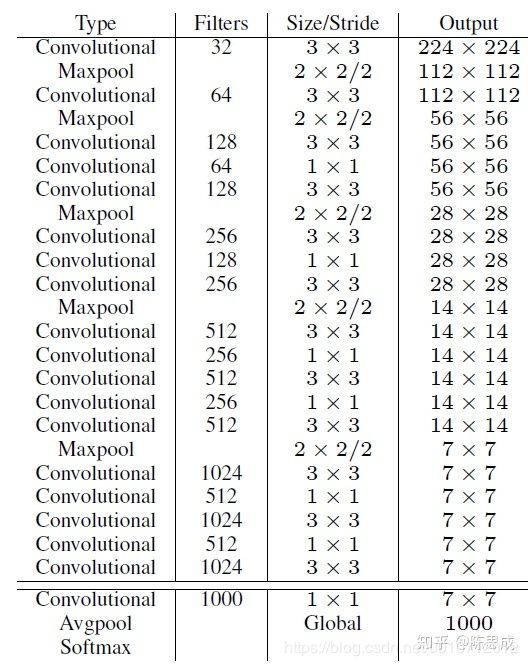
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如下图。Darknet-19与VGG16模型设计原则是一致的,主要采用3 * 3卷积,采用2 * 2的maxpooling层之后,特征图维度降低2倍,而同时将特征图的channles增加两倍。
主要特点有:
(1)去掉了全连接层fc
·这样大大减少了网络的参数,个人理解这是yolo2可以增加每个cell产生边界框以及每个边界框能够单独的对应一组类别概率的原因。
·并且,网络下采样是32倍,这样也使得网络可以接收任意尺寸的图片,所以yolo2有了Multi-Scale Training多尺度训练的改进:输入图片resize到不同的尺寸(论文中选用320,352…,608十个尺寸,下采样32倍对应10 * 10~19 * 19的特征图)。每训练10个epoch,将图片resize到另一个不同的尺寸再训练。这样一个模型可以适应不同的输入图片尺寸,输入图像大(608608)精度高速度稍慢、输入图片小(320320)精度稍低速度快,增加了模型对不同尺寸图片输入的鲁棒性。
(2)在每个卷积层后面都加入一个BN层并不再使用dropout
·这样提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。
(3)采用跨层连接Fine-Grained Features
·YOLOv2的输入图片大小为416 * 416,经过5次maxpooling(下采样32倍)之后得到13 * 13大小的特征图,并以此特征图采用卷积做预测。这样会导致小的目标物体经过5层maxpooling之后特征基本没有了。所以yolo2引入passthrough层:前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个22的局部区域,然后将其转化为channel维度,对于26 * 26 * 512的特征图,经passthrough层处理之后就变成了13 * 13 * 2048的新特征图,这样就可以与后面的13 * 13 * 1024特征图连接在一起形成13 * 13 * 3072大小的特征图,然后在此特征图基础上卷积做预测。作者在后期的实现中借鉴了ResNet网络,不是直接对高分辨特征图处理,而是增加了一个中间卷积层,先采用64个11卷积核进行卷积,然后再进行passthrough处理,这样26 * 26 * 512的特征图得到13 * 13 * 256的特征图。这算是实现上的一个小细节。
代码:
import os
import tensorflow as tf
import numpy as np
################# 基础层:conv/pool/reorg(带passthrough的重组层) #############################################
# 激活函数
def leaky_relu(x):
return tf.nn.leaky_relu(x,alpha=0.1,name='leaky_relu') # 或者tf.maximum(0.1*x,x)
# Conv+BN:yolo2中每个卷积层后面都有一个BN层
def conv2d(x,filters_num,filters_size,pad_size=0,stride=1,batch_normalize=True,
activation=leaky_relu,use_bias=False,name='conv2d'):
# padding,注意: 不用padding="SAME",否则可能会导致坐标计算错误
if pad_size > 0:
x = tf.pad(x,[[0,0],[pad_size,pad_size],[pad_size,pad_size],[0,0]])
# 有BN层,所以后面有BN层的conv就不用偏置bias,并先不经过激活函数activation
out = tf.layers.conv2d(x,filters=filters_num,kernel_size=filters_size,strides=stride,
padding='VALID',activation=None,use_bias=use_bias,name=name)
# BN,如果有,应该在卷积层conv和激活函数activation之间
if batch_normalize:
out = tf.layers.batch_normalization(out,axis=-1,momentum=0.9,training=False,name=name+'_bn')
if activation:
out = activation(out)
return out
# max_pool
def maxpool(x,size=2,stride=2,name='maxpool'):
return tf.layers.max_pooling2d(x,pool_size=size,strides=stride)
# reorg layer(带passthrough的重组层)
def reorg(x,stride):
return tf.space_to_depth(x,block_size=stride)
# 或者return tf.extract_image_patches(x,ksizes=[1,stride,stride,1],strides=[1,stride,stride,1],
# rates=[1,1,1,1],padding='VALID')
#########################################################################################################
################################### Darknet19 ###########################################################
# 默认是coco数据集,最后一层维度是anchor_num*(class_num+5)=5*(80+5)=425
def darknet(images,n_last_channels=425):
net = conv2d(images, filters_num=32, filters_size=3, pad_size=1, name='conv1')
net = maxpool(net, size=2, stride=2, name='pool1')
net = conv2d(net, 64, 3, 1, name='conv2')
net = maxpool(net, 2, 2, name='pool2')
net = conv2d(net, 128, 3, 1, name='conv3_1')
net = conv2d(net, 64, 1, 0, name='conv3_2')
net = conv2d(net, 128, 3, 1, name='conv3_3')
net = maxpool(net, 2, 2, name='pool3')
net = conv2d(net, 256, 3, 1, name='conv4_1')
net = conv2d(net, 128, 1, 0, name='conv4_2')
net = conv2d(net, 256, 3, 1, name='conv4_3')
net = maxpool(net, 2, 2, name='pool4')
net = conv2d(net, 512, 3, 1, name='conv5_1')
net = conv2d(net, 256, 1, 0,name='conv5_2')
net = conv2d(net,512, 3, 1, name='conv5_3')
net = conv2d(net, 256, 1, 0, name='conv5_4')
net = conv2d(net, 512, 3, 1, name='conv5_5')
shortcut = net # 存储这一层特征图,以便后面passthrough层
net = maxpool(net, 2, 2, name='pool5')
net = conv2d(net, 1024, 3, 1, name='conv6_1')
net = conv2d(net, 512, 1, 0, name='conv6_2')
net = conv2d(net, 1024, 3, 1, name='conv6_3')
net = conv2d(net, 512, 1, 0, name='conv6_4')
net = conv2d(net, 1024, 3, 1, name='conv6_5')
net = conv2d(net, 1024, 3, 1, name='conv7_1')
net = conv2d(net, 1024, 3, 1, name='conv7_2')
# shortcut增加了一个中间卷积层,先采用64个1*1卷积核进行卷积,然后再进行passthrough处理
# 这样26*26*512 -> 26*26*64 -> 13*13*256的特征图
shortcut = conv2d(shortcut, 64, 1, 0, name='conv_shortcut')
shortcut = reorg(shortcut, 2)
net = tf.concat([shortcut, net], axis=-1) # channel整合到一起
net = conv2d(net, 1024, 3, 1, name='conv8')
# detection layer:最后用一个1*1卷积去调整channel,该层没有BN层和激活函数
output = conv2d(net, filters_num=n_last_channels, filters_size=1, batch_normalize=False,
activation=None, use_bias=True, name='conv_dec')
return output
#########################################################################################################
if __name__ == '__main__':
x = tf.random_normal([1, 416, 416, 3])
model_output = darknet(x)
saver = tf.train.Saver()
with tf.Session() as sess:
# 必须先restore模型才能打印shape;导入模型时,上面每层网络的name不能修改,否则找不到
saver.restore(sess, "./yolo2_model/yolo2_coco.ckpt")
print(sess.run(model_output).shape) # (1,13,13,425)
2、decode.py:解码darknet19网络得到的参数.
YOLOv2借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。边界框的实际中心位置 (x,y) ,需要根据预测的坐标偏移值 ( t x , t y ) (t_x, t_y) (tx,ty) ,先验框的尺度 ( w a , h a ) (w_a, h_a) (wa,ha) 以及中心坐标 ( x a , y a ) (x_a, y_a) (xa,ya) (特征图每个位置的中心点)来计算:
x = ( t x × w a ) − x a x = (t_x\times w_a)-x_a x=(tx×wa)−xa
y = ( t y × h a ) − y a y=(t_y\times h_a) - y_a y=(ty×ha)−ya
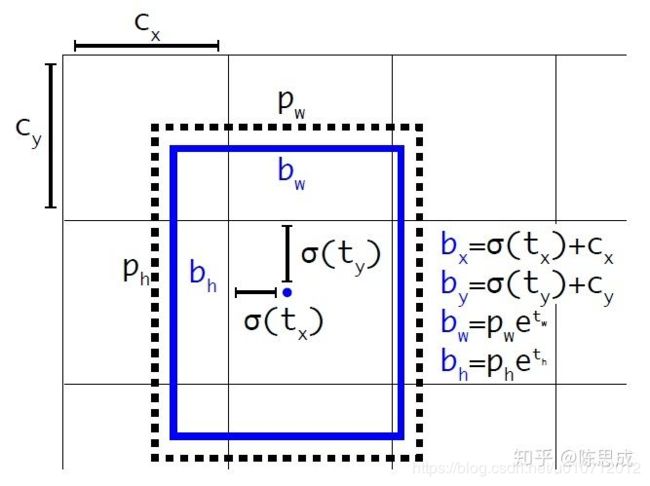
YOLOv2沿用YOLOv1的预测方式,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。总结来看,根据边界框预测的4个offsets t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th ,可以按如下公式计算出边界框实际位置和大小:
b x = σ ( t x ) + c x b_x = \sigma (t_x)+c_x bx=σ(tx)+cx
b y = σ ( t y ) + c y b_y = \sigma (t_y) + c_y by=σ(ty)+cy
b w = p w e t w b_w = p_we^{t_w} bw=pwetw
b h = p h e t h b_h = p_he^{t_h} bh=pheth
其中 ( c x , c y ) (c_x, c_y) (cx,cy) 为cell的左上角坐标,如下图,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为 (1,1) 。由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。而 p w p_w pw 和 p h p_h ph 是先验框的宽度与长度,前面说过它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。这里记特征图的大小为 (W, H) (在文中是 (13, 13) ),这样我们可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
b x = ( σ ( t x ) + c x ) / W b_x = (\sigma (t_x)+c_x)/W bx=(σ(tx)+cx)/W
b y = ( σ ( t y ) + c y ) / H b_y = (\sigma (t_y) + c_y)/H by=(σ(ty)+cy)/H
b w = p w e t w / W b_w = p_we^{t_w}/W bw=pwetw/W
b h = p h e t h / H b_h = p_he^{t_h}/H bh=pheth/H
如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。这就是YOLOv2边界框的整个解码过程。
注意:代码中将解码后的中心坐标+宽高box(x,y,w,h)表达形式 —> 左上+右下 b o x ( x m i n , y m i n , x m a x , y m a x ) box(xmin,ymin,xmax,ymax) box(xmin,ymin,xmax,ymax)表达形式,是为了opencv函数方便绘制边界框。
代码
import tensorflow as tf
import numpy as np
def decode(model_output,output_sizes=(13,13),num_class=80,anchors=None):
'''
model_output:darknet19网络输出的特征图
output_sizes:darknet19网络输出的特征图大小,默认是13*13(默认输入416*416,下采样32)
'''
H, W = output_sizes
num_anchors = len(anchors) # 这里的anchor是在configs文件中设置的
anchors = tf.constant(anchors, dtype=tf.float32) # 将传入的anchors转变成tf格式的常量列表
# 13*13*num_anchors*(num_class+5),第一个维度自适应batchsize
detection_result = tf.reshape(model_output,[-1,H*W,num_anchors,num_class+5])
# darknet19网络输出转化——偏移量、置信度、类别概率
xy_offset = tf.nn.sigmoid(detection_result[:,:,:,0:2]) # 中心坐标相对于该cell左上角的偏移量,sigmoid函数归一化到0-1
wh_offset = tf.exp(detection_result[:,:,:,2:4]) #相对于anchor的wh比例,通过e指数解码
obj_probs = tf.nn.sigmoid(detection_result[:,:,:,4]) # 置信度,sigmoid函数归一化到0-1
class_probs = tf.nn.softmax(detection_result[:,:,:,5:]) # 网络回归的是'得分',用softmax转变成类别概率
# 构建特征图每个cell的左上角的xy坐标
height_index = tf.range(H,dtype=tf.float32) # range(0,13)
width_index = tf.range(W,dtype=tf.float32) # range(0,13)
# 变成x_cell=[[0,1,...,12],...,[0,1,...,12]]和y_cell=[[0,0,...,0],[1,...,1]...,[12,...,12]]
x_cell,y_cell = tf.meshgrid(height_index,width_index)
x_cell = tf.reshape(x_cell,[1,-1,1]) # 和上面[H*W,num_anchors,num_class+5]对应
y_cell = tf.reshape(y_cell,[1,-1,1])
# decode
bbox_x = (x_cell + xy_offset[:,:,:,0]) / W
bbox_y = (y_cell + xy_offset[:,:,:,1]) / H
bbox_w = (anchors[:,0] * wh_offset[:,:,:,0]) / W
bbox_h = (anchors[:,1] * wh_offset[:,:,:,1]) / H
# 中心坐标+宽高box(x,y,w,h) -> xmin=x-w/2 -> 左上+右下box(xmin,ymin,xmax,ymax)
bboxes = tf.stack([bbox_x-bbox_w/2, bbox_y-bbox_h/2,
bbox_x+bbox_w/2, bbox_y+bbox_h/2], axis=3)
return bboxes, obj_probs, class_probs
3、utils.py:功能函数,包含:预处理输入图片、筛选边界框NMS、绘制筛选后的边界框。
这里着重介绍NMS中IOU计算方式:yolo2中计算IOU只考虑形状,先将anchor与ground truth的中心点都偏移到同一位置(cell左上角),然后计算出对应的IOU值。
IOU计算难点在于计算交集大小:首先要判断是否有交集,然后再计算IOU。计算时候有一个trick,只计算交集部分的左上角和右下角坐标即可,通过取max和min计算:

代码
import random
import colorsys
import cv2
import numpy as np
# 【1】图像预处理(pre process前期处理)
def preprocess_image(image,image_size=(416,416)):
# 复制原图像
image_cp = np.copy(image).astype(np.float32)
# resize image
image_rgb = cv2.cvtColor(image_cp,cv2.COLOR_BGR2RGB)
image_resized = cv2.resize(image_rgb,image_size)
# normalize归一化
image_normalized = image_resized.astype(np.float32) / 225.0
# 增加一个维度在第0维——batch_size
image_expanded = np.expand_dims(image_normalized,axis=0)
return image_expanded
# 【2】筛选解码后的回归边界框——NMS(post process后期处理)
def postprocess(bboxes,obj_probs,class_probs,image_shape=(416,416),threshold=0.5):
# bboxes表示为:图片中有多少box就多少行;4列分别是box(xmin,ymin,xmax,ymax)
bboxes = np.reshape(bboxes,[-1,4])
# 将所有box还原成图片中真实的位置
bboxes[:,0:1] *= float(image_shape[1]) # xmin*width
bboxes[:,1:2] *= float(image_shape[0]) # ymin*height
bboxes[:,2:3] *= float(image_shape[1]) # xmax*width
bboxes[:,3:4] *= float(image_shape[0]) # ymax*height
bboxes = bboxes.astype(np.int32)
# (1)cut the box:将边界框超出整张图片(0,0)—(415,415)的部分cut掉
bbox_min_max = [0,0,image_shape[1]-1,image_shape[0]-1]
bboxes = bboxes_cut(bbox_min_max,bboxes)
# ※※※置信度*max类别概率=类别置信度scores※※※
obj_probs = np.reshape(obj_probs,[-1])
class_probs = np.reshape(class_probs,[len(obj_probs),-1])
class_max_index = np.argmax(class_probs,axis=1) # 得到max类别概率对应的维度
class_probs = class_probs[np.arange(len(obj_probs)),class_max_index]
scores = obj_probs * class_probs
# ※※※类别置信度scores>threshold的边界框bboxes留下※※※
keep_index = scores > threshold
class_max_index = class_max_index[keep_index]
scores = scores[keep_index]
bboxes = bboxes[keep_index]
# (2)排序top_k(默认为400)
class_max_index,scores,bboxes = bboxes_sort(class_max_index,scores,bboxes)
# ※※※(3)NMS※※※
class_max_index,scores,bboxes = bboxes_nms(class_max_index,scores,bboxes)
return bboxes,scores,class_max_index
# 【3】绘制筛选后的边界框
def draw_detection(im, bboxes, scores, cls_inds, labels, thr=0.3):
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x/float(len(labels)), 1., 1.) for x in range(len(labels))]
colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),colors))
random.seed(10101) # Fixed seed for consistent colors across runs.
random.shuffle(colors) # Shuffle colors to decorrelate adjacent classes.
random.seed(None) # Reset seed to default.
# draw image
imgcv = np.copy(im)
h, w, _ = imgcv.shape
for i, box in enumerate(bboxes):
if scores[i] < thr:
continue
cls_indx = cls_inds[i]
thick = int((h + w) / 300)
cv2.rectangle(imgcv,(box[0], box[1]), (box[2], box[3]),colors[cls_indx], thick)
mess = '%s: %.3f' % (labels[cls_indx], scores[i])
if box[1] < 20:
text_loc = (box[0] + 2, box[1] + 15)
else:
text_loc = (box[0], box[1] - 10)
# cv2.rectangle(imgcv, (box[0], box[1]-20), ((box[0]+box[2])//3+120, box[1]-8), (125, 125, 125), -1) # puttext函数的背景
cv2.putText(imgcv, mess, text_loc, cv2.FONT_HERSHEY_SIMPLEX, 1e-3*h, (255,255,255), thick//3)
return imgcv
######################## 对应【2】:筛选解码后的回归边界框#########################################
# (1)cut the box:将边界框超出整张图片(0,0)—(415,415)的部分cut掉
def bboxes_cut(bbox_min_max,bboxes):
bboxes = np.copy(bboxes)
bboxes = np.transpose(bboxes)
bbox_min_max = np.transpose(bbox_min_max)
# cut the box
bboxes[0] = np.maximum(bboxes[0],bbox_min_max[0]) # xmin
bboxes[1] = np.maximum(bboxes[1],bbox_min_max[1]) # ymin
bboxes[2] = np.minimum(bboxes[2],bbox_min_max[2]) # xmax
bboxes[3] = np.minimum(bboxes[3],bbox_min_max[3]) # ymax
bboxes = np.transpose(bboxes)
return bboxes
# (2)按类别置信度scores降序,对边界框进行排序并仅保留top_k
def bboxes_sort(classes,scores,bboxes,top_k=400):
index = np.argsort(-scores)
classes = classes[index][:top_k]
scores = scores[index][:top_k]
bboxes = bboxes[index][:top_k]
return classes,scores,bboxes
# (3)计算IOU+NMS
# 计算两个box的IOU
def bboxes_iou(bboxes1,bboxes2):
bboxes1 = np.transpose(bboxes1)
bboxes2 = np.transpose(bboxes2)
# 计算两个box的交集:交集左上角的点取两个box的max,交集右下角的点取两个box的min
int_ymin = np.maximum(bboxes1[0], bboxes2[0])
int_xmin = np.maximum(bboxes1[1], bboxes2[1])
int_ymax = np.minimum(bboxes1[2], bboxes2[2])
int_xmax = np.minimum(bboxes1[3], bboxes2[3])
# 计算两个box交集的wh:如果两个box没有交集,那么wh为0(按照计算方式wh为负数,跟0比较取最大值)
int_h = np.maximum(int_ymax-int_ymin,0.)
int_w = np.maximum(int_xmax-int_xmin,0.)
# 计算IOU
int_vol = int_h * int_w # 交集面积
vol1 = (bboxes1[2] - bboxes1[0]) * (bboxes1[3] - bboxes1[1]) # bboxes1面积
vol2 = (bboxes2[2] - bboxes2[0]) * (bboxes2[3] - bboxes2[1]) # bboxes2面积
IOU = int_vol / (vol1 + vol2 - int_vol) # IOU=交集/并集
return IOU
# NMS,或者用tf.image.non_max_suppression(boxes, scores,self.max_output_size, self.iou_threshold)
def bboxes_nms(classes, scores, bboxes, nms_threshold=0.5):
keep_bboxes = np.ones(scores.shape, dtype=np.bool)
for i in range(scores.size-1):
if keep_bboxes[i]:
# Computer overlap with bboxes which are following.
overlap = bboxes_iou(bboxes[i], bboxes[(i+1):])
# Overlap threshold for keeping + checking part of the same class
keep_overlap = np.logical_or(overlap < nms_threshold, classes[(i+1):] != classes[i])
keep_bboxes[(i+1):] = np.logical_and(keep_bboxes[(i+1):], keep_overlap)
idxes = np.where(keep_bboxes)
return classes[idxes], scores[idxes], bboxes[idxes]
###################################################################################################
4、Main.py:YOLO_v2主函数
对应程序有三个步骤:
(1)输入图片进入darknet19网络得到特征图,并进行解码得到:xmin xmax表示的边界框、置信度、类别概率
(2)筛选解码后的回归边界框——NMS
(3)绘制筛选后的边界框
代码:
import numpy as np
import tensorflow as tf
import cv2
from PIL import Image
from YOLO_v2.model_darknet19 import darknet
from YOLO_v2.decode import decode
from YOLO_v2.utils import preprocess_image, postprocess, draw_detection
from YOLO_v2.config import anchors, class_names
def main():
input_size = (416,416)
image_file = './yolo2_data/car.jpg'
image = cv2.imread(image_file)
image_shape = image.shape[:2] #只取wh,channel=3不取
# copy、resize416*416、归一化、在第0维增加存放batchsize维度
image_cp = preprocess_image(image,input_size)
# 【1】输入图片进入darknet19网络得到特征图,并进行解码得到:xmin xmax表示的边界框、置信度、类别概率
tf_image = tf.placeholder(tf.float32,[1,input_size[0],input_size[1],3])
model_output = darknet(tf_image) # darknet19网络输出的特征图
output_sizes = input_size[0]//32, input_size[1]//32 # 特征图尺寸是图片下采样32倍
output_decoded = decode(model_output=model_output,output_sizes=output_sizes,
num_class=len(class_names),anchors=anchors) # 解码
model_path = "./yolo2_model/yolo2_coco.ckpt"
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,model_path)
bboxes,obj_probs,class_probs = sess.run(output_decoded,feed_dict={tf_image:image_cp})
# 【2】筛选解码后的回归边界框——NMS(post process后期处理)
bboxes,scores,class_max_index = postprocess(bboxes,obj_probs,class_probs,image_shape=image_shape)
# 【3】绘制筛选后的边界框
img_detection = draw_detection(image, bboxes, scores, class_max_index, class_names)
cv2.imwrite("./yolo2_data/detection.jpg", img_detection)
print('YOLO_v2 detection has done!')
cv2.imshow("detection_results", img_detection)
cv2.waitKey(0)
if __name__ == '__main__':
main()
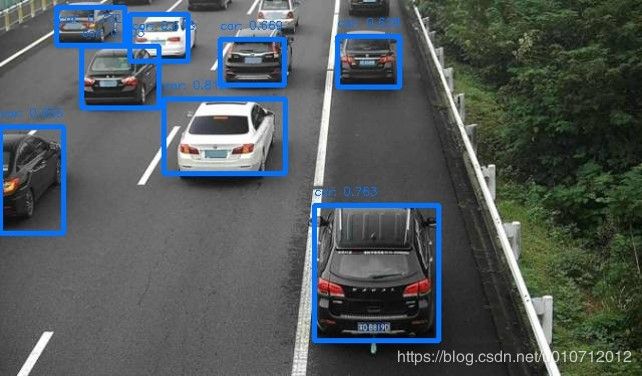
结果图:
二、tf函数小结:
1、model_darknet19.py中:
(1)tf.space_to_depth
tf.space_to_depth(
input,
block_size,
name=None,
data_format='NHWC'
)
该操作会输出输入张量的副本,其中来自维height 和width维的值将移至该depth维。block_size表示输入块大小。
- 大小不重叠的块block_size x block size在每个位置重新排列成深度。
- 输出张量的深度是block_size * block_size * input_depth。
- 输入张量的高度和宽度必须能被block_size整除。
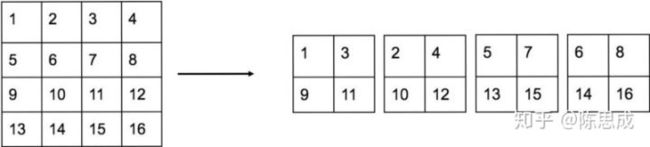
- 【eg.】26 * 26 * 256–>13 * 13 * (2 * 2 * 256)–>13 * 13 * 1024
data_format ATTR指定输入和输出张量的布局与下列选项:
“NHWC”:[ batch, height, width, channels ]
“NCHW”:[ batch, channels, height, width ]
“NCHW_VECT_C”: qint8 [ batch, channels / 4, height, width, 4 ]
例如,给定形状的输入[1, 2, 2, 1],data_format =“NHWC”和block_size = 2:
x = [[[[1], [2]],
[[3], [4]]]]
该操作将输出一个形状张量[1, 1, 1, 4]:
[[[[1, 2, 3, 4]]]]
这里,输入的批次为1,每个批次元素都具有形状[2, 2, 1],相应的输出将具有单个元素(即宽度和高度均为1),并且将具有4个通道(1 块大小块大小)的深度。输出元素的形状是[1, 1, 4]。
同样,对于以下输入形状[1 4 4 1],块大小为2:
x = [[[[1], [2], [5], [6]],
[[3], [4], [7], [8]],
[[9], [10], [13], [14]],
[[11], [12], [15], [16]]]]
操作员将返回以下张量形状[1 2 2 4]:
x = [[[[1, 2, 3, 4],
[5, 6, 7, 8]],
[[9, 10, 11, 12],
[13, 14, 15, 16]]]]
(2)tf.concat
concat(
values,
axis,
name='concat'
)
来自输入的张量沿着axis 维度加入。
输入张量的维数必须匹配,除了axis必须相等外,所有维度都必须相同。
例如:
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 0) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 1) # [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]
# tensor t3 with shape [2, 3]
# tensor t4 with shape [2, 3]
tf.shape(tf.concat([t3, t4], 0)) # [4, 3]
tf.shape(tf.concat([t3, t4], 1)) # [2, 6]
2、decode.py中:
(1)tf.meshgrid
meshgrid(
*args,
**kwargs
)
返回个点坐标列表,类似于python中的zip函数。
例子:
调用X, Y = meshgrid(x, y)张量
x = [1, 2, 3]
y = [4, 5, 6]
X, Y = tf.meshgrid(x, y)
# X = [[1, 2, 3],
# [1, 2, 3],
# [1, 2, 3]]
# Y = [[4, 4, 4],
# [5, 5, 5],
# [6, 6, 6]]
(2)tf.range
range(limit, delta=1, dtype=None, name='range')
range(start, limit, delta=1, dtype=None, name='range')
创建一个数字序列,该数字开始于start并且以增量为delta最大但不包括limit。
除非明确提供,否则得到的张量的dtype是从输入推断出来的。
就像Python内置函数一样range,start默认值为0 range(n) = range(0, n)。
例如:
start = 3
limit = 18
delta = 3
tf.range(start, limit, delta) # [3, 6, 9, 12, 15]
start = 3
limit = 1
delta = -0.5
tf.range(start, limit, delta) # [3, 2.5, 2, 1.5]
limit = 5
tf.range(limit) # [0, 1, 2, 3, 4]
3、utils.py中:
(1)tf.argmax()和np.argmax()
argmax也是基于张量的计算,求取某个方向上的最大值的下标,在做统计时十分有用。给出一个样例代码自行体会:
import tensorflow as tf
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
tf.InteractiveSession()
print(tf.argmax(a).eval())
print(tf.argmax(a, 0).eval())
print(tf.argmax(a, 1).eval())
np.argmax(a)
np.argmax(a, 0)
np.argmax(a, 1)
'''
输出:
[1 1 1]
[1 1 1]
[2 2]
5
[1 1 1]
[2 2]
'''
输出结果返回的是最大值的下标(从0开始)。注意TensorFlow与NumPy有些许差别。
参考:https://zhuanlan.zhihu.com/p/36902889
YOLOv2原理:https://blog.csdn.net/u010712012/article/details/85274711