在python中使用评分卡技术
最近发现了一款使用python实现的评分卡相关技术的插件woe,这里总结分享一下。项目网址:https://github.com/boredbird/woe,安装方式十分简单,直接使用pip安装即可:
pip install woe
或者
pip installgit+https://github.com/boredbird/woe
一、 相关概念
1.1 最优分组
最优分组或者最优分群是一种进行变量分组划分的常用技术,它划分的最终结果是该变量的iv值或者其他参考指标最大化。它首先将变量按照一定步长,分为100或者N个小组,然后根据IV值,对这些小组进行划分(树分裂),划分成2、3、4、5、、、直到指定分组数目。
1.2 K-S值
将评估样本总体进行10等分(比如按照预测的欺诈分值),并按照违约概率进行降序排序,计算每一等份中违约与正常百分比的累计分布,绘制出两者之间的差异。K-s曲线中的最大值被称作k-s统计量。
1.3 相关系数
简单相关系数:又叫相关系数或线性相关系数,一般用字母r表示,用来度量两个变量间的线性关系。


1.4 Wald test
scipy.stats.wald
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.wald.html
1.5 IV与WOE
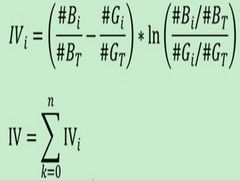
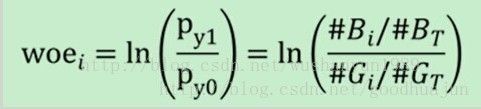
IV衡量的是某一个变量的信息量,从公式来看的话,相当于是自变量woe值的一个加权求和,其值的大小决定了自变量对于目标变量的影响程度;从另一个角度来看的话,IV公式与信息熵的公式极其相似。
可以看出来,经过WOE的变化之后,模型的效果好多了。事实上,WOE也可以用违约概率来代替,两者没有本质的区别。用WOE来对自变量做编码的一大目的就是实现这种“条件似然比”变换,极大化辨识度。
二、 使用介绍
2.1 特点
支持基于信息熵的树分裂(最优分组、最优分群);
丰富的模型评估方法
按照一定格式输入,输出设置方便
存储树结构(pkl文件),方便在后续测试时或者转换其他数据时使用
2.2 模块功能树
|-__init__
|-config.py
| |-- config:参数配置
| |-- __init__:初始化执行参数配置
| |-- change_config_var_dtype():配置待处理变量类型
| |-- load_file():加载csv格式的数据文件
|-eval.py
| |-- compute_ks():ks分值估计(from scipy.stats import ks_2samp)
| |-- eval_data_summary():统计样本信息(好坏分布),并输出结果到csv文件中
| |-- eval_feature_detail():统计特征信息(好坏分布)
| |-- eval_feature_stability():特征稳定性验证,分层统计是否均匀
| |-- eval_feature_summary():统计变量的相关统计信息(iv、coef)
| |-- eval_model_stability():模型稳定性评估,分值分段统计
| |-- eval_model_summary():
| |-- eval_segment_metrics():分段计算ks值
| |-- plot_ks():ks曲线画图
| |-- proc_cor_eval():计算相关系数(numpy.corrcoef)
| |-- proc_validation():
| |-- wald_test():计算waldtest
|-feature_process.py
| |-- binning_data_split() :执行数据划分
| |-- calculate_iv_split():指定划分节点,计算iv值
| |-- calulate_iv():计算iv值
| |-- change_feature_dtype():更改数据类型
| |-- check_point():
| |-- fillna():替换空缺值
| |-- format_iv_split():给定数据集和划分节点,返回iv值
| |-- proc_woe_continuous():计算连续变量的woe值
| |-- proc_woe_discrete():计算离散变量的woe值
| |-- process_train_woe():训练集的woe转换
| |-- process_woe_trans():处理woe转换
| |-- search()
| |-- woe_trans()
|-ftrl.py
| |-- FTRL()
| |-- LR()
|-GridSearch.py:参数的网格搜索
| |-- fit_single_lr()
| |-- grid_search_lr_c()
| |-- grid_search_lr_c_main()
| |--grid_search_lr_validation()
3.2 数据配置
如项目文件夹example中的HereWeGo.py程序示例,需按照config.csv中的示例进行配置,
| var_name |
var_dtype |
is_tobe_bin |
is_candidate |
is_modelfeature |
Label列必须命名为target
is_tobe_bin:表示是否要进行分组
is_candidate:表示该变量是否入模
is_modelfeature:该变量是否加入模型参数的网格搜索