List集合源码解析原理和用法
注:以下所用源码均基于JDK1.8基础(特殊说明除外)
先从源码入手解析:
public interface List extends Collection {} An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
Unlike sets, lists typically allow duplicate elements. More formally, lists typically allow pairs of elements e1 and e2 such that e1.equals(e2), and they typically allow multiple null elements if they allow null elements at all. It is not inconceivable that someone might wish to implement a list that prohibits duplicates, by throwing runtime exceptions when the user attempts to insert them, but we expect this usage to be rare.
根据源码注释可知:List集合接口继承至Collection接口,进行了元素排序,且允许存放相同的元素,但是由于是根据index获取元素,所以相同的元素则位置不同。增加了列表迭代器ListInterator和众多操作list的Method
与Collection接口相比,List接口新增了如下方法:
- add(int index,E element):在列表指定位置插入指定元素
- addAll(int index,Collection c):在指定位置添加集合元素
- get(int index):获取指定位置的元素
- indexOf(Object o):获取元素的第一个位置
- isEmpty():判断列表中是否有元素
- lastIndexOf(Object o):获取指定元素的最后一个位置
- listIterator():获取列表元素的列表迭代器
- listIterator(int index):从指定位置开始获取列表迭代器
- remove(int index):移除指定位置的元素
- set(int index,E element):用指定元素替换指定位置的元素
- subList(int fromIdex,int toIndex):获取fromIndex到toIndex的元素列表
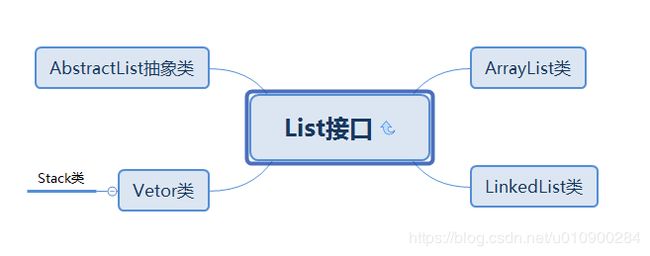
List接口实现类 有ArrayList、LinkedList、Vector和抽象类AbstractList,其中ArrayList和LinkedList较为常用,下面着重说明这两种
ArrayList:
优点:操作读取操作效率高,基于数组实现的,可以为null值,可以允许重复元素,有序,异步。
缺点:由于它是由动态数组实现的,不适合频繁的对元素的插入和删除操作,因为每次插入和删除都需要移动数组中的元素。
LinkedList:
优点:LinkedList由双链表实现,增删由于不需要移动底层数组数据,其底层是链表实现的,只需要修改链表节点指针,对元素的插入和删除效率较高。
缺点: 遍历效率较低。HashMap和双链表也有关系。
ArrayList
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable{} 根据源码可知,ArrayList继承AbstractList和实现List,新增如下接口:
注意:ensureCapacity是不同步的,ArrayList的动态改变列表大小也是基于这个方法实现的。解决不同步的方法是:使用Collections.synchronizedList 方法将该列表“包装”起来,即List list = Collections.synchronizedList(new ArrayList(...));最好在创建时完成,以防止意外对列表进行不同步的访问。
尽量不要使用ensureCapacity方法,因为改变list的容量会降低效率,改变list容量的原理是常见一个比之前更大容量的list,将原list中的数据copy到新的list,在删除原有的list。
- colone():返回ArrayList实例的浅表副本
- ensureCapacity(int minCapacity):增加ArrayList实例的容量。
- removeRange(int fromIndex,int toIndex):批量移除列表中的元素
- trimToSize():将列表容量调整至当前大小。
实现原理:
ArrayList底层是一个变长的数组,基本上等同于Vector,但是ArrayList对writeObjec()t和readObject()方法实现了同步。
If multiple threads access an ArrayList instance concurrently, and at least one of the threads modifies the list structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more elements, or explicitly resizes the backing array; merely setting the value of an element is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the list.
根据源码注释可知,ArrayList是线程不安全的,多线程环境下要通过外部的同步策略后使用,比如List list = Collections.synchronizedList(new ArrayList(…));
序列化:
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*/
private int size;其中transient 表示element这个属性不需要自动序列化,因为element存储的不是真正的元素对象,而是指向对象的地址,序列化地址是没有意义的,因为序列化的目的是为了反序列化为对象,当对地址进行反序列化后就找不到原来的对象了。所以需要手工的对元素序列化,如下是ArrayList的源码实现:
/**
* Save the state of the ArrayList instance to a stream (that
* is, serialize it).
*
* @serialData The length of the array backing the ArrayList
* instance is emitted (int), followed by all of its elements
* (each an Object) in the proper order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; iArrayList instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i 自动变长机制:
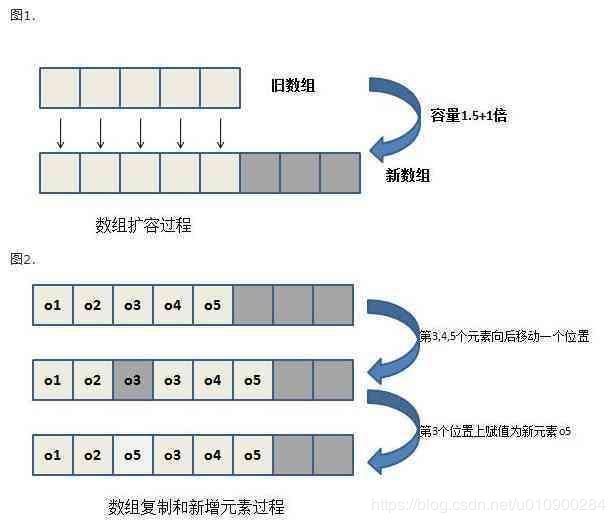
当调用add方法时,会调用ensureCapacityInternal方法进行扩容,每次扩容为原来大小的1.5倍,但是当第一次添加元素或者列表中元素个数小于10的话,列表容量默认为10.
add方法源码如下:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return true (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}根据源码可知,扩容之后,将指定元素复制到新的element数组中。
扩容原理:根据当前数组的大小,判断是否小于默认值10,如果大于,则需要扩容至当前数组大小的1.5倍,重新将新扩容的数组数据copy只当前elementData,最后将传入的元素赋值给size++位置
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
快速失败迭代器:
所谓快速失败迭代器是指再某个线程对列表进行迭代时,不允许其他线程对其进行操作,否则会抛出ConcurrentModificationException异常,只能使用interator的add和remove方法对列表进行结构性的操作。
迭代器iterator()方法的实现是返回一个私有的内部实现类ListItr,这个类继承了另一个内部类Itr。内部类中提供了add和remove方法。并且调用了get(int i ndex)方法来获取元素。
内部类Itr的源码如下:
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* The returned iterator is fail-fast.
*
* @return an iterator over the elements in this list in proper sequence
*/
public Iterator iterator() {
return new Itr();
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
内部类ListItr源码如下:
/**
* An optimized version of AbstractList.ListItr
*/
private class ListItr extends Itr implements ListIterator {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
} 上述源代码中checkForComodification方法时检测是否对修改同步(根据当前列表的修改次数和interator中的累计修改数进行对比,其中modCount是记录列表结构被修改的次数。他的作用是防止列表在迭代期间被恶意修改),源代码如下:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}ArrayList的特点是插入和删除效率低,查询效率高,为什么会有这种效果,我们通过源码分析:
- add(E e)
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return true (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}根据源码可知,当调用add插入时,首先要调用ensureCapacityInternal(size + 1)方法,上文提到这个方法是进行自动扩容的,效率低重点也就是在这个扩容上了,每次新增都要对现有的数组进行一次1.5倍的扩大,数组间值的copy等,最后等扩容完毕,有空间位置了,将数组size+1的位置放入元素e,实现新增。
- add(int index, E element)
/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}根据注释可知,给指定的index赋值element,首先rangeCheckForAdd(index)要对加入的index的位置进行check,index非法则抛出越界异常,throw new IndexOutOfBoundsException(outOfBoundsMsg(index));其他方法也有用到如:addAll(int index, Collection c),然后同理也是需要扩容ensureCapacityInternal(size + 1),完成扩容后,将数组间的数据进行一个copy,这主要是为了保证数组数据完整,空出一个index位置,不像add中的elementData[size++]就完事了,最后将指定位置的index元素赋值,个数+1。
- remove(int index)
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}根据源码可知,在删除index位置的元素时,要先调用rangeCheck(index)进行index的check,index要超过当前个数,则判定越界,抛出异常,throw new IndexOutOfBoundsException(outOfBoundsMsg(index));其他方法也有用到如:get(int index),set(int index, E element)等后面删除重点在于计算删除的index是末尾还是中间位置,末尾直接--,然后置空完事,如果是中间位置,那就要进行一个数组间的copy,重新组合数组数据了,性能就在这里得到了消耗。
- get(int index)
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}根据源码可知,获取指定index的元素,首先调用rangeCheck(index)进行index的check,通过后直接获取数组的下标index获取数据,就这么简单明了,没有任何多余操作,效率之高,相对LinkedList的遍历获取,较为方便高效。
LinkedList
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable{} 根据源码可知,LinkedList继承AbstractSequentialList和实现List接口,新增接口如下:
- addFirst(E e):将指定元素添加到刘表开头
- addLast(E e):将指定元素添加到列表末尾
- descendingIterator():以逆向顺序返回列表的迭代器
- element():获取但不移除列表的第一个元素
- getFirst():返回列表的第一个元素
- getLast():返回列表的最后一个元素
- offerFirst(E e):在列表开头插入指定元素
- offerLast(E e):在列表尾部插入指定元素
- peekFirst():获取但不移除列表的第一个元素
- peekLast():获取但不移除列表的最后一个元素
- pollFirst():获取并移除列表的最后一个元素
- pollLast():获取并移除列表的最后一个元素
- pop():从列表所表示的堆栈弹出一个元素
- push(E e);将元素推入列表表示的堆栈
- removeFirst():移除并返回列表的第一个元素
- removeLast():移除并返回列表的最后一个元素
- removeFirstOccurrence(E e):从列表中移除第一次出现的指定元素
- removeLastOccurrence(E e):从列表中移除最后一次出现的指定元素
其中有部分方法实现的功能是一样的,例如add方法和offer方法实现的功能是一样的,只是返回的类型不同,add无返回类型,offer返回boolean。remove和poll方法的不同之处是:当列表为空时,poll返回null,而remove会抛出异常。
实现原理:
LinkedList的实现是一个双向链表。在JDK1.6中是一个带空头的循环双向链表,而在JDK1.7+中则变为不带空头的双向链表,这从源码中可以看出:
JDK1.6中定义中属性为Entry类,如下:
private transient Entry header = new Entry(null, null, null);
private transient int size = 0; JDK1.7+中定义属性为Node类实例,如下:
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last; 序列化:
LinkedList也实现了writeObject方法和readObject方法的同步
/**
* Saves the state of this {@code LinkedList} instance to a stream
* (that is, serializes it).
*
* @serialData The size of the list (the number of elements it
* contains) is emitted (int), followed by all of its
* elements (each an Object) in the proper order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node x = first; x != null; x = x.next)
s.writeObject(x.item);
}
/**
* Reconstitutes this {@code LinkedList} instance from a stream
* (that is, deserializes it).
*/
@SuppressWarnings("unchecked")
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
} 内部结构-链表Node:
Doubly-linked list implementation of the {@code List} and {@code Deque} interfaces. Implements all optional list operations, and permits all elements (including {@code null}).
根据源码注释可知,LinkedList可以进行所有List的操作,因为其实现了List接口,同时LinkedList可以存放任何元素,包括null
All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
所有根据索引的查找操作都是按照双向链表的需要执行的,根据索引从前或从后开始搜索,并且从最靠近索引的一端开始。例如一个LindedList有5个元素,如果调用了get(2)方法,LinkedList将会从头开始搜索;如果调用get(4)方法,那么LinkedList将会从后向前搜索。这样做的目的可以提升查找效率。那如何做到这一点呢?在LinkedList内部有一个Node(int index)方法,它会判断从头或者从后开始查找比较快。源码如下:
/**
* Returns the (non-null) Node at the specified element index.
*/
Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} If multiple threads access a linked list concurrently, and at least one of the threads modifies the list structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more elements; merely setting the value of an element is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the list.
根据源码注释可知,LinkedList不是线程安全的,多线程环境下要通过外部的同步策略后使用,比如List list = Collections.synchronizedList(new LinkedList(…));
快速失败迭代器:
The list-iterator is fail-fast: if the list is structurally modified at any time after the Iterator is created, in any way except through the list-iterator's own {@code remove} or {@code add} methods, the list-iterator will throw a {@code ConcurrentModificationException}.
根据源码注释可知, LinkedList的iterator 是快速失败的迭代器,前面ArrayList有提到,快速失败迭代器在当前List创建后是不允许对List进行结构修改的,否则会抛出ConcurrentModificationException异常,源码如下:
public ListIterator listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private class ListItr implements ListIterator {
private Node lastReturned;
private Node next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
public boolean hasPrevious() {
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
public void forEachRemaining(Consumer action) {
Objects.requireNonNull(action);
while (modCount == expectedModCount && nextIndex < size) {
action.accept(next.item);
lastReturned = next;
next = next.next;
nextIndex++;
}
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
} 接下来说一下LinkedList的数据结构,说这个之前先看下源码:
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 根据当前源码,结合上文提到的局部变量first和last,可以得出LinkedList的每个节点都是一个Node类型的实例,每个Node中都包含着当前元素,当前元素的前节点以及后节点,这样就实现了节点之间的环环相扣,跟链条一样的具备双向的链表结构。
LinkedList的特点是插入和删除效率高,查询效率差,其实这是相对来说的,上文有提到,获取node时LinkedList是双向的,根据list的大小去选择从前还是从后查找,只是这种查找需要遍历,相对ArrayList的固定性差一些,我们看着源码解答:
- add(E e)
/**
* Appends the specified element to the end of this list.
*
* This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
根据源码和注释可知,add方法实则是将元素append至list的末尾,具体过程是:新建一个Node节点,其中将后面的那个节点last作为新节点的前置节点,后节点为null;将这个新Node节点作为整个list的后节点,如果之前的后节点l为null,将新建的Node作为list的前节点,否则,list的后节点指针指向新建Node,最后size+1,当前llist操作数modCount+1。
从这段源码分析得出,在add一个新元素时,LinkedList所关心的重要数据,一共两个变量,一个first,一个last,这大大提升了插入时的效率,且默认是追加至末尾,保证了顺序,当然指定位置插入除外。
- add(int index, E element)
/**
* Inserts the specified element at the specified position in this list.
* Shifts the element currently at that position (if any) and any
* subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}顾名思义,这个方法是根据index插入元素很好理解,需要注意的在进行插入前进行checkPositionIndex(index);这个方法是用来check传入的index是否符合list的数据要求,如果index非法,则报非法越界,throw new IndexOutOfBoundsException(outOfBoundsMsg(index));当然在LinkedList中也有很多方法需要用到checkindex,如addAll(),上文提到的快速失败迭代器等,如果传入的index正好是元素的个数那就直接追加至末尾,否则就调用linkBefore(element, node(index))方法了,这就是要说明这个add方法的重点了,先看源码:
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev;
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
} 先看注释,在非空节点succ之前插入e,所以succ必须不能为null;先获取index位置上的succ节点,这里是通过node(index)获取的,所以其实相对也有些查找上的效率问题,然后拿到succ的前置节点pred(succ.prev),新建一个要插入的节点Node,Node的前置节点就是pred,后置节点就是succ,然后再将succ的前置节点替换成新建的Node节点,跟listLast同理,如果旧的前置节点pred为null,那直接将当前LinkeList的前置节点置为新建的节点Node,否则就将旧pred的下一个节点指针指向新建节点Node,完成链表相连,最后个数+1,操作数+1。
从这段源码分析得出,指定index插入元素,关键的变量在于,一个是first,一个是当前index节点的prev节点,这个上文的listLast有一点区别,但原理是一样的。
- remove(int index)
/**
* Removes the element at the specified position in this list. Shifts any
* subsequent elements to the left (subtracts one from their indices).
* Returns the element that was removed from the list.
*
* @param index the index of the element to be removed
* @return the element previously at the specified position
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}删除指定index的元素,删除之前要调用checkElementIndex(index)去check一下index是否存在元素,如果不存在抛出throw new IndexOutOfBoundsException(outOfBoundsMsg(index));越界错误,同样这个check方法也是很多方法用到的,如:get(int index),set(int index, E element)等。
/**
* Unlinks non-null node x.
*/
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
} 先看注释,要删除的是非空的节点,这里的node节点也是通过node(index)获取的,所以其实相对也有些查找上的效率问题;分别根据当前Node得到链表上的关节要素,element,next,prev,分别对prev和next进行判断,以便对当前list的前后节点进行重新赋值,frist和last,最后将节点的element置为null,个数-1,操作数+1。
根据以上分析,remove节点关键的变量,是Node实例本身的局部变量next、prev和item重新构建内部变量指针指向,以及list的局部变量first和last保证节点相连,关心的这些变量构成remove的操作,所以删除节点效率也是很高的。
- get(int index)
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
获取指定index位置的node,获取之前还是调用checkElementIndex(index)check元素,之后通过node(index)获取元素,上文有提到,node的获取是遍历得到的元素,所以相对性能效率会低一些
上文提到的check方法,源码如下:
/**
* Tells if the argument is the index of an existing element.
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
/**
* Tells if the argument is the index of a valid position for an
* iterator or an add operation.
*/
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
/**
* Constructs an IndexOutOfBoundsException detail message.
* Of the many possible refactorings of the error handling code,
* this "outlining" performs best with both server and client VMs.
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}到此,List中ArrayList和LinkedList的源码解读和分析就基本完成了,通过以上源码分析,数据结构List集合的思路一定更加清晰,使用也会更加明确。
感谢以下博文思路指引:
https://blog.csdn.net/weixin_36930207/article/details/53811326
https://blog.csdn.net/lzjlzjlzjlzjlzjlzj/article/details/52278461