系统设计面试题分析
应届生在面试的时候,大公司偶尔也会遇到一些系统设计题,而这些题目往往只是考一下你的知识面,或者对系统架构方面的了解,不会涉及编码。很多人感觉难以应对这样的题目,也不知道从何说起,在本文中,总结了回答这类题目需要哪些基础知识,以及怎样使用这些知识回答这些问题。
在正式介绍基础知识之前,先罗列几个常见的系统设计相关的笔试面试题:
(1)(百度)要求设计一个DNS的Cache结构,要求能够满足每秒5000以上的查询,满足IP数据的快速插入,查询的速度要快。(题目还给出了一系列的数据,比如:站点数总共为5000万,IP地址有1000万,等等)
解决方案:DNS服务器实现域名到IP地址的转换。
每个域名的平均长度为25个字节(在域名的命名标准中,对于域名长度是有明显限制的。其中,中国国家域名不得超过20个字符,国际通用域名不得超过26个字符),每个IP为4个字节,所以Cache的每个条目需要大概30个字节。
总共50M个条目,所以需要1.5G个字节的空间。可以放置在内存中。(考虑到每秒5000次操作的限制,也只能放在内存中。)
可以考虑的数据结构包括hash_map,字典树,红黑树等等。
我觉得比较好的解决方法是,将每一个URL字符串转化为MD5值,作为key,建立最大或最小堆,这样插入和查找的效率都是O(log(n))。
MD5是128bit的大整数也就是16byte,比直接存放URL要节省的多。
具体可应用方法:每秒5000的查询不算高啊,最土的方法使用MySQL+Memcached架构应该都能满足吧?
数据结构建议以域名的md5值为主键来存储,值可以只存储目标IP就行。Memcached用户支撑前端查询,MySQL用户存储数据,还要看总数量会有多大,如果不是特别大,直接使用MyISAM引擎来存储就行,更新插入都非常快,如果超千万,可以使用InnoDB来存储,每次有新数据插入时直接使用replace into table就行,Memcached数据的更新直接使用set。
Memcached随便用得好些,每秒上万次的get是容易达到的,MySQL你别小看,在有的测试里,以主键查询的测试,一台普通的服务器上,MySQL/InnoDB 5.1服务器上获得了750000+QPS的成绩。
总结:关于高并发系统设计。主要有以下几个关键技术点:缓存,索引,数据分片,锁粒度尽可能小。。
(2)有N台机器,M个文件,文件可以以任意方式存放到任意机器上,文件可任意分割成若干块。假设这N台机器的宕机率小于1/3,想在宕机时可以从其他未宕机的机器中完整导出这M个文件,求最好的存放与分割策略。
解决方案:涉及到现在通用的分布式文件系统的副本存放策略。一般是将大文件切分成小的block(如64MB)后,以block为单位存放三份到不同的节点上,这三份数据的位置需根据网络拓扑结构配置,一般而言,如果不考虑跨数据中心,可以这样存放:两个副本存放在同一个机架的不同节点上,而另外一个副本存放在另一个机架上,这样从效率和可靠性上,都是最优的(这个google公布的文档中有专门的证明,有兴趣的可参阅一下。)。如果考虑跨数据中心,可将两份存在一个数据中心的不同机架上,另一份放到另一个数据中心。
(3)假设有三十台服务器,每个上面都存有上百亿条数据(有可能重复),如何找出这三十台机器中,根据某关键字,重复出现次数最多的前100条?要求用Hadoop来做。
方案:针对每一台机器有100亿,类似100万时的处理方法,对数据进行切片,可以都切为100万的记录,对100万、取最前100,不同在于这前100也存入hash,如果key相同则合并value,显然100亿的数据分割完后的处理结果也要再进行类似的处理,hash表不能过长,原理其实也就是map和reduce。然后合并这30台机器的结果。
(4)设计一个系统,要求写速度尽可能高,说明设计原理。
解决方案:涉及到BigTable的模型。主要思想是将随机写转化为顺序写,进而大大提高写速度。具体是:由于磁盘物理结构的独特设计,其并发的随机写(主要是因为磁盘寻道时间长)非常慢,考虑到这一点,在BigTable模型中,首先会将并发写的大批数据放到一个内存表(称为“memtable”)中,当该表大到一定程度后,会顺序写到一个磁盘表(称为“SSTable”)中,这种写是顺序写,效率极高。说到这,可能有读者问,随机读可不可以这样优化?答案是:看情况。通常而言,如果读并发度不高,则不可以这么做,因为如果将多个读重新排列组合后再执行,系统的响应时间太慢,用户可能接受不了,而如果读并发度极高,也许可以采用类似机制。
(5)设计一个高并发系统,说明架构和关键技术要点。
方案:分布式系统中的核心的服务器的实现。可以是http服务器,缓存服务器,分布式文件系统等的内部实现。下边主要从一个高并发的大型网站出发,看一个高并发系统的设计。下边是一个高并发系统的逻辑结构:
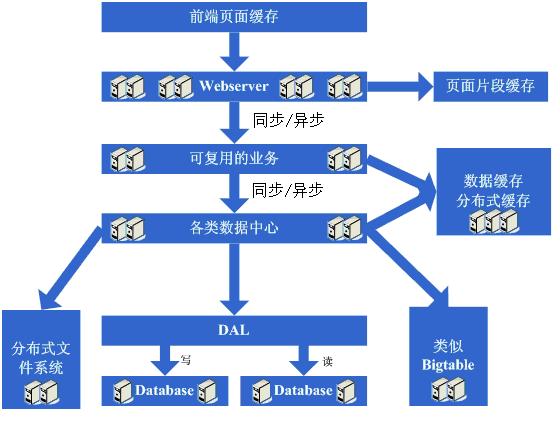
1)缓存系统:缓存是每一个高并发,高可用系统不可或缺的模块。常见的缓存系统:Squid(前端缓存)、Ehcache(对象缓存系统),动态页面静态化(页面缓存)
2)负载均衡系统:负载均衡策略有随机分配,平均分配,分布式一致性hash等。软件负载均衡有:基于DNS的负载均衡、基于LVS的负载均衡和基于lptables的负载均衡。硬件负载均衡:路由上配置nat实现负载均衡、对万网一个虚拟ip,内网映射几个内网ip。数据库负载均衡:数据库集群等。
(6)有25T的log(query->queryinfo),log在不段的增长,设计一个方案,给出一个query能快速返回queryinfo?
方案:1)建立适当索引;2)优化sql语句;3)实现小数据量和海量数据的通用分页显示存储过程;4)合理选择聚集索引
以上所有问题中凡是不涉及高并发的,基本可以采用google的三个技术解决,分别为:GFS,MapReduce,Bigtable,这三个技术被称为“google三驾马车”,google只公开了论文而未开源代码,开源界对此非常有兴趣,仿照这三篇论文实现了一系列软件,如:Hadoop、HBase、HDFS、Cassandra等。
在google这些技术还未出现之前,企业界在设计大规模分布式系统时,采用的架构往往是database+sharding+cache,现在很多公司(比如taobao,weibo.com)仍采用这种架构。在这种架构中,仍有很多问题值得去探讨。如采用什么数据库,是SQL界的MySQL还是NoSQL界的Redis/TFS,两者有何优劣? 采用什么方式sharding(数据分片),是水平分片还是垂直分片?据网上资料显示,weibo.com和taobao图片存储中曾采用的架构是Redis/MySQL/TFS+sharding+cache,该架构解释如下:前端cache是为了提高响应速度,后端数据库则用于数据永久存储,防止数据丢失,而sharding是为了在多台机器间分摊负载。最前端由大块大块的cache组成,要保证至少99%(该数据在weibo.com架构中的是自己猜的,而taobao图片存储模块是真实的)的访问数据落在cache中,这样可以保证用户访问速度,减少后端数据库的压力,此外,为了保证前端cache中数据与后端数据库中数据一致,需要有一个中间件异步更新(为啥异步?理由简单:同步代价太高。异步有缺定,如何弥补?)数据,这个有些人可能比较清楚,新浪有个开源软件叫memcachedb(整合了Berkeley DB和Memcached),正是完成此功能。另外,为了分摊负载压力和海量数据,会将用户微博信息经过片后存放到不同节点上(称为“sharding”)。
这种架构优点非常明显:简单,在数据量和用户量较小的时候完全可以胜任。但缺定早晚一天暴露出来,即:扩展性和容错性太差,维护成本非常高,尤其是数据量和用户量暴增之后,系统不能通过简单的增加机器解决该问题。
于是乎,新的架构便出现了。主要还是google的那一套东西,下面分别说一下:
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。现在开源界有HDFS(Hadoop Distributed File System),该文件系统虽然弥补了数据库+sharding的很多缺点,但自身仍存在一些问题,比如:由于采用master/slave架构,因而存在单点故障问题;元数据信息全部存放在master端的内存中,因而不适合存储小文件,或者说如果存储的大量小文件,那么存储的总数据量不会太大。
MapReduce是针对分布式并行计算的一套编程模型。他最大的优点是:编程接口简单,自动备份(数据默认情况下会自动备三份),自动容错和隐藏跨机器间的通信。在Hadoop中,MapReduce作为分布计算框架,而HDFS作为底层的分布式存储系统,但MapReduce不是与HDFS耦合在一起的,你完全可以使用自己的分布式文件系统替换掉HDFS。当前MapReduce有很多开源实现,如Java实现Hadoop MapReduce,C++实现Sector/sphere等,甚至有些数据库厂商将MapReduce集成到数据库中了。
BigTable俗称“大表”,是用来存储结构化数据的,个人觉得,BigTable在开源界最火爆,其开源实现最多,包括:HBase,Cassandra,levelDB等,使用也非常广泛。
除了google的这三家马车,还有其他一些技术:
Dynamo:亚马逊的key-value模式的存储平台,可用性和扩展性都很好,采用DHT(Distributed Hash Table)对数据分片,解决单点故障问题,在Cassandra中,也借鉴了该技术,在BT和电驴的中,也采用了类似算法。
虚拟节点技术:该技术常用于分布式数据分片中。具体应用场景是:有一大坨数据(maybe TB级或者PB级),我们需按照某个字段(key)分片存储到几十(或者更多)台机器上,同时想尽量负载均衡且容易扩展。传统的做法是:Hash(key) mod N,这种方法最大缺点是不容易扩展,即:增加或者减少机器均会导致数据全部重分布,代价忒大。于是乎,新技术诞生了,其中一种是上面提到的DHT,现在已经被很多大型系统采用,还有一种是对“Hash(key) mod N”的改进:假设我们要将数据分不到20台机器上,传统做法是hash(key) mod 20,而改进后,N取值要远大于20,比如是20000000,然后我们采用额外一张表记录每个节点存储的key的模值,比如:
node1:0~1000000
node2:1000001~2000000
。。。。。。
这样,当添加一个新的节点时,只需将每个节点上部分数据移动给新节点,同时修改一下这个表即可。
Thrift:Thrift是一个跨语言的RPC框架,分别解释一下“RPC”和“跨语言”,RPC是远程过程调用,其使用方式与调用一个普通函数一样,但执行体发生在远程机器上。跨语言是指不同语言之间进行通信,比如c/s架构中,server端采用C++编写,client端采用PHP编写,怎样让两者之间通信,thrift是一种很好的方式。