SolrCloud原理
本文为调研分布式检索系统的笔记整理,之前调研sphinx和coreseek的时候,发现国内的博客,还是讲怎么配置怎么安装多,原理性的东西并不多。本文为:官网文档阅读笔记(有些会附带上文档英文原文, 如果读者觉得我哪个地方说的不清楚,可以看英文)+各种原理博客+各种源码分析博客。
内容涉及:SolrCloud的基础知识,架构,索引创建更新、查询,故障恢复,负载均衡,leader选举等的原理。文章比较长,可以根据标题选需要的看。
一、SolrCloud与Solr,lucene关系
1、 solr与luence的关系
| Many people new to Lucene and Solr will ask the obvious question: Should I use Lucene or Solr? The answer is simple: if you're asking yourself this question, in 99% of situations, what you want to use is Solr. A simple way to conceptualize the relationship between Solr and Lucene is that of a car and its engine. You can't drive an engine, but you can drive a car. Similarly, Lucene is a programmatic library which you can't use as-is, whereas Solr is a complete application which you can use out-of-box. |
网上有这样的比喻:
(1) lucene是数据库的话,solr就是jdbc
(2) lucene是jar,solr就是一个引用这些jar来写的搜索客户端。Solr是一个可以直接用的应用,而lucene只是一些编程用的库。
2、 Solr与SolrCloud
SolrCloud是Solr4.0版本开发出的具有开创意义的基于Solr和Zookeeper的分布式搜索方案,或者可以说,SolrCloud是Solr的一种部署方式。Solr可以以多种方式部署,例如单机方式,多机Master-Slaver方式,这些方式部署的Solr不具有SolrCloud的特色功能。
二、SolrCloud配置
有两种方式:
(1) 把solr作为web应用部署到Tomcat容器,然后Tomcat与zookeeper关联
(2) 从solr 5开始, solr自身有jetty容器,不必部署到Tomcat,这样会容易一些。
我用的第二种,推荐教程:
http://blog.csdn.net/wanghui2008123/article/details/37813525
三、SolrCloud基础知识
概念
· Collection:在SolrCloud集群中逻辑意义上的完整的索引。它常常被划分为一个或多个Shard,它们使用相同的Config Set。如果Shard数超过一个,它就是分布式索引,SolrCloud让你通过Collection名称引用它,而不需要关心分布式检索时需要使用的和Shard相关参数。
· ConfigSet: Solr Core提供服务必须的一组配置文件。每个config set有一个名字。最小需要包括solrconfig.xml(SolrConfigXml)和schema.xml (SchemaXml),除此之外,依据这两个文件的配置内容,可能还需要包含其它文件。它存储在Zookeeper中。Config sets可以重新上传或者使用upconfig命令更新,使用Solr的启动参数bootstrap_confdir指定可以初始化或更新它。
· Core: 也就是Solr Core,一个Solr中包含一个或者多个Solr Core,每个Solr Core可以独立提供索引和查询功能,每个Solr Core对应一个索引或者Collection的Shard,Solr Core的提出是为了增加管理灵活性和共用资源。在SolrCloud中有个不同点是它使用的配置是在Zookeeper中的,传统的Solr core的配置文件是在磁盘上的配置目录中。
· Leader: 赢得选举的Shard replicas。每个Shard有多个Replicas,这几个Replicas需要选举来确定一个Leader。选举可以发生在任何时间,但是通常他们仅在某个Solr实例发生故障时才会触发。当索引documents时,SolrCloud会传递它们到此Shard对应的leader,leader再分发它们到全部Shard的replicas。
· Replica: Shard的一个拷贝。每个Replica存在于Solr的一个Core中。一个命名为“test”的collection以numShards=1创建,并且指定replicationFactor设置为2,这会产生2个replicas,也就是对应会有2个Core,每个在不同的机器或者Solr实例。一个会被命名为test_shard1_replica1,另一个命名为test_shard1_replica2。它们中的一个会被选举为Leader。
· Shard: Collection的逻辑分片。每个Shard被化成一个或者多个replicas,通过选举确定哪个是Leader。
· Zookeeper: Zookeeper提供分布式锁功能,对SolrCloud是必须的。它处理Leader选举。Solr可以以内嵌的Zookeeper运行,但是建议用独立的,并且最好有3个以上的主机。
· SolrCor: 单机运行时,单独的索引叫做SolrCor,如果创建多个索引,可以创建的多个SolrCore。
· 索引:一个索引可以在不同的Solr服务上,也就是一个索引可以由不同机器上的SolrCore组成。 不同机器上的SolrCore组成逻辑上的索引,这样的一个索引叫做Collection,组成Collection的SolrCore包括数据索引和备份。
· SolrCloud collection shard关系:一个SolrCloud包含多个collection,collection可以被分为多个shards, 每个shard可以有多个备份(replicas),这些备份通过选举产生一个leader,
· Optimization: 是一个进程,压缩索引和归并segment,Optimization只会在master node运行,
· Leader 和 replica
(1) leader负责保证replica和leader是一样的最新的信息
(2)replica 被分到 shard 按照这样的顺序: 在集群中他们第一次启动的次序轮询加入,
除非新的结点被人工地使用shardId参数分派到shard。
人工指定replica属于哪个shard的方法:
· This parameter is used as a system property, as in -DshardId=1, the value of which is the ID number of theshard the new node should be attached to.
以后重启的时候,每个node加入之前它第一次被指派的shard。 Node如果以前是replica,当以前的leader不存在的时候,会成为leader。
架构
· 索引(collection)的逻辑图
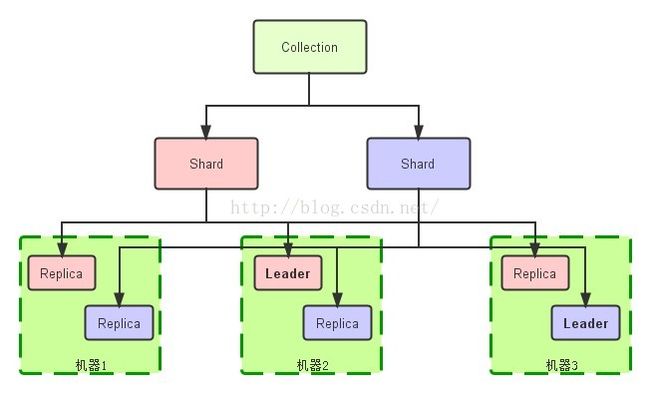
· 索引和Solr实体对照图
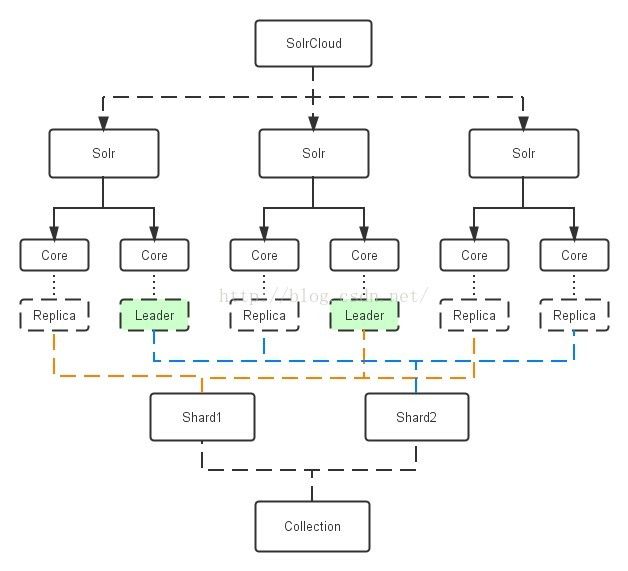
一个经典的例子:
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正在开发中的Solr4.0的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:1)集中式的配置信息 2)自动容错 3)近实时搜索 4)查询时自动负载均衡
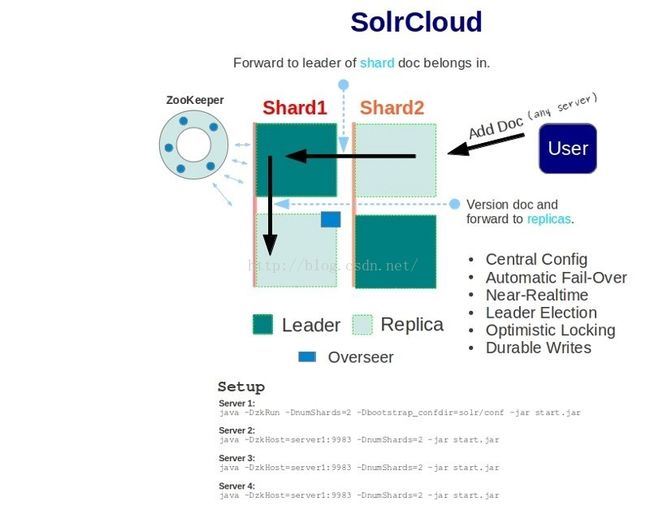
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
几种角色
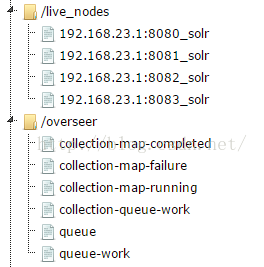
(1)zookeeper:下面的信息是zookeeper上存储的,zookeeper目录称为znode
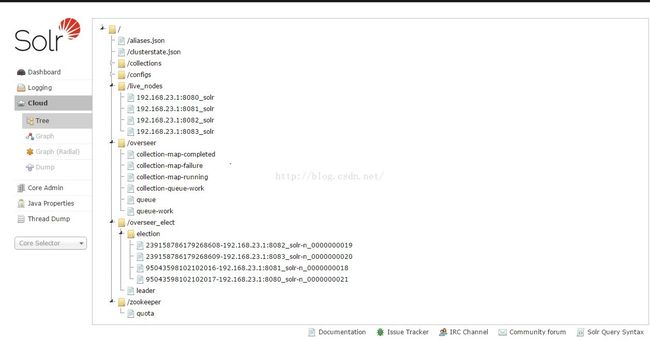
| solr在zookeeper中的结点
1、aliases.json 对colletion别名,另有妙用(solrcloud的build search分离),以后再写博客说明。 2、clusterstate.json 重要信息文件。包含了colletion ,shard replica的具体描述信息。 3、live_nodes ,下面都是瞬时的zk结点,代表当前存活的solrcloud中的节点。 4、overseer, solrcloud中的重要角色。下面存有三个重要的分布式队列,代表待执行solrcloud相关的zookeeper操作的任务队列。collection-queue-work是存放与collection相关的特办操作,如createcollection ,reloadcollection,createalias,deletealias ,splitshard 等。 5、queue则存放了所有与collection无关的操作,例如deletecore,removecollection,removeshard,leader,createshard,updateshardstate,还有包括节点的状态(down、active、recovering)的变化。 6、queue-work是一个临时队列,指正在处理中的消息。操作会先保存到/overseer/queue,在overseser进行处理时,被移到/overseer/queue-work中,处理完后消息之后在从/overseer/queue-work中删除。如果overseer中途挂了,新选举的overseer会选将/overseer/queue-work中的操作执行完,再去处理/overseer/queue中的操作。 注意:以上队列中存放的所有子结点,都是PERSISTENT_SEQUENTIAL类型的。 7、overseer_elect ,用于overseer的选举工作 8、colletcion,存放当前collection一些简单信息(主要信息都在clusterstate.json中)。 下面的leader_elect自然是用于collection中shard中副本集的leader选举的。
|

clusterstate.json
(2)overseer: overseer是经常被忽略的角色,实际上,我测试过,每次加入一台新的机器的时候,一方面,SolrCloud会多一个Solr,另一方面,会多一个oveseer(当然可能不会起到作用)。 整个SolrCloud只有一个overseer会起到作用,所有的overseer经过选举产生overseer。 Overseer和shard的leader选举方式一样,详见后面leader选举部分。
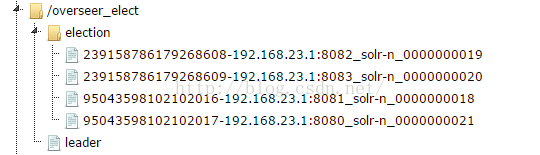
| Overseer 的zk写流程 在看solrcloud的官方文档的时候,几乎也很少有overseer的这个角色的说明介绍。相信不少成功配置solrcloud的开发者,也没有意识到这个角色的存在。 Overseer,顾名思义,是一个照看全局的角色,做总控工作。体现在代码与zk的相关操作中,就是zookeeper中大多的写操作,是由overseer去处理的,并且维护好clusterstate.josn与aliases.json这两个zk结点的内容。与我们“谁创建,谁修改”做法不同。由各个solr node发起的操作,都会publish到/overseer结点下面相应的queue中去,再由overseer去些分布式队列中去取这些操作信息,做相应的zk修改,并将整个solrcloud中相关的具体状态信息,更新到cluseterstate.json中去,最终会将个操作,从queue中删除,表示完成操作。 以一个solr node将自身状态标记为down为例。该node会将这种“state”operation的相关信息,publish到/overseer/queue中。由Overseer去从中取得这个操作,然后将node state为down的信息写入clusterstate.json。最后删除queue中的这个结点。 当然overseer这个角色,是利用zookeeper在solrcloud中内部选举出来的。
一般的zk读操作 Solr将最重要且信息最全面的内容都放在了cluseterstate.json中。这样做减少了,普通solr node需要关注的zk 结点数。除了clusterstate.json,普通的solr node在需要当前collection整体状态的时候,还会获取zk的/live_nodes中的信息,根据live_nodes中的信息,得知collection存活的node, 再从clusterstate.json获得这些node的信息。 这种处理,其实也好理解。假如一个solr node非正常下线,clusterstate.json中不一定会有变化,但/live_nodes中这个node对应的zk结点就消失了(因为是瞬时的)。
|
二、 创建索引的过程(索引更新)
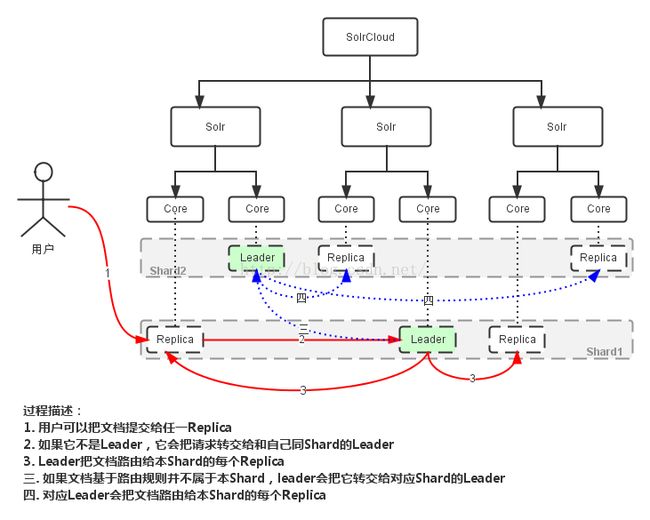
具体过程:
1、细节问题:
(1)下面所说的SolrJ是客户端,CloudSolrServcer是SolrCloud的机器
(2)文档的ID
根据我看源码,文档ID生成,一是可以自己配置,二是可以使用默认配置,这时候文档ID是使用java的UUID生成器(这个ID生成器可以生成全球唯一的ID)
(3) watch (可以看Zookeeper相关的文档
http://www.cnblogs.com/clara/archive/2013/06/10/3130922.html)
客户端(watcher)在zookeeper的数据上设置watch, watch是一次性的trigger,当数据改变的时候的时候,会触发,watch被发送信息到设置这个Watch的客户端。
ZooKeeper WatchesHere is ZooKeeper's definition of a watch: a watch event is one-time trigger, sent to the client that set the watch, which occurs when the data for which the watch was set changes. There are three key points to consider in this definition of a watch: · One-time trigger One watch event will be sent to the client when the data has changed. For example, if a client does a getData("/znode1", true) and later the data for /znode1 is changed or deleted, the client will get a watch event for /znode1. If /znode1 changes again, no watch event will be sent unless the client has done another read that sets a new watch. · Sent to the client This implies that an event is on the way to the client, but may not reach the client before the successful return code to the change operation reaches the client that initiated the change. Watches are sent asynchronously to watchers. ZooKeeper provides an ordering guarantee: a client will never see a change for which it has set a watch until it first sees the watch event. · The data for which the watch was set This refers to the different ways a node can change. It helps to think of ZooKeeper as maintaining two lists of watches: data watches and child watches. getData() and exists() set data watches. getChildren() sets child watches. Alternatively, it may help to think of watches being set according to the kind of data returned. getData() and exists() return information about the data of the node, whereas getChildren() returns a list of children. Thus, setData() will trigger data watches for the znode being set (assuming the set is successful). A successful create() will trigger a data watch for the znode being created and a child watch for the parent znode. A successful delete() will trigger both a data watch and a child watch (since there can be no more children) for a znode being deleted as well as a child watch for the parent znode. Watches are maintained locally at the ZooKeeper server to which the client is connected. This allows watches to be lightweight to set, maintain, and dispatch. When a client connects to a new server, the watch will be triggered for any session events. Watches will not be received while disconnected from a server. When a client reconnects, any previously registered watches will be reregistered and triggered if needed. In general this all occurs transparently. There is one case where a watch may be missed: a watch for the existence of a znode not yet created will be missed if the znode is created and deleted while disconnected.
|
(4) lucene index是一个目录,索引的insert或者删除保持不变, 文档总是被插入新创建的file,被删除的文档不会真的从file中删除,而是只是打上tag,知道index被优化。update就是增加和删除组合。
(5)文档路由
Solr 4.1 added the ability to co-locate documents toimprove query performance.
Solr4.1添加了文档聚类(译注:此处翻译准确性需要权衡,意思是将文档归类在一起的意思)的功能来提升查询性能。
Solr 4.5 has added the ability to specify the routerimplementation with the router.name parameter. If you use the"compositeId" router, you can send documents with a prefix in thedocument ID which will be used to calculate the hash Solr uses to determine theshard a document is sent to for indexing. The prefix can be anything you'd likeit to be (it doesn't have to be the shard name, for example), but it must beconsistent so Solr behaves consistently. For example, if you wanted toco-locate documents for a customer, you could use the customer name or ID asthe prefix. If your customer is "IBM", for example, with a documentwith the ID "12345", you would insert the prefix into the document idfield: "IBM!12345". The exclamation mark ('!') is critical here, asit defines the shard to direct the document to.
Solr4.5添加了通过一个router.name参数来指定一个特定的路由器实现的功能。如果你使用“compositeId”路由器,你可以在要发送到Solr进行索引的文档的ID前面添加一个前缀,这个前缀将会用来计算一个hash值,Solr使用这个hash值来确定文档发送到哪个shard来进行索引。这个前缀的值没有任何限制(比如没有必要是shard的名称),但是它必须总是保持一致来保证Solr的执行结果一致。例如,你需要为不同的顾客聚类文档,你可能会使用顾客的名字或者是ID作为一个前缀。比如你的顾客是“IBM”,如果你有一个文档的ID是“12345”,把前缀插入到文档的id字段中变成:“IBM!12345”,在这里感叹号是一个分割符号,这里的“IBM”定义了这个文档会指向一个特定的shard。
Then at query time, you include the prefix(es) into yourquery with the _route_ parameter (i.e., q=solr&_route_=IBM!)to direct queries to specific shards. In some situations, this may improvequery performance because it overcomes network latency when querying all theshards.
然后在查询的时候,你需要把这个前缀包含到你的_route_参数里面(比如:q=solr&_route_=IBM!)使查询指向指定的shard。在某些情况下,这样操作能提升查询的性能,因为它省掉了需要在所有shard上查询耗费的网络传输用时。
The _route_ parameterreplaces shard.keys, which has been deprecated and will be removed in afuture Solr release.
使用_route_代替shard.keys参数。shard.keys参数已经过时了,在Solr的未来版本中这个参数会被移除掉。
If you do not want to influence how documents are stored,you don't need to specify a prefix in your document ID.
如果你不想变动文档的存储过程,那就不需要在文档的ID前面添加前缀。
If you created the collection and defined the"implicit" router at the time of creation, you can additionallydefine a router.field parameter to use a field from each document toidentify a shard where the document belongs. If the field specified is missingin the document, however, the document will be rejected. You could also usethe _route_ parameter to name a specific shard.
如果你创建了collection并且在创建的时候指定了一个“implicit”路由器,你可以另外定义一个router.field参数,这个参数定义了通过使用文档中的一个字段来确定文档是属于哪个shard的。但是,如果在一个文档中你指定的字段没有值得话,这个文档Solr会拒绝处理。同时你也可以使用_route_参数来指定一个特定的shard。
我的理解:添加了这样聚类的好处:查询的时候,声明了route=IBM,那么就可以减少访问的shard
router.name的值可以是 implicit 或者compositeId, 'implicit' 不自动路由文档到不同的shard, 而是会按照你在indexingrequest中暗示的那样。也就是建索引的时候,如果是implicit是需要自己指定文档到哪个shard的。比如:
| curl "http://10.1.30.220:8081/solr/admin/collections?action=CREATE&name=paper&collection.configName=paper_conf&router.name=implicit&shards=shard1,shard2&createNodeSet=10.1.30.220:8081_solr,10.1.30.220:8084_solr" |
2 具体过程
添加文档的过程:
(1)当SolrJ发送update请求给CloudSolrServer ,CloudSolrServer会连接至Zookeeper获取当前SolrCloud的集群状态,并会在/clusterstate.json 和/live_nodes 注册watcher,便于监视Zookeeper和SolrCloud,这样做的好处有以下几点:
CloudSolrServer获取到SolrCloud的状态后,它能跟直接将document发往SolrCloud的leader,降低网络转发消耗。
注册watcher有利于建索引时候的负载均衡,比如如果有个节点leader下线了,那么CloudSolrServer会立马得知,那它就会停止往下线leader发送document。
(2)路由document至正确的shard。CloudSolrServer 在发送document时候需要知道发往哪个shard,但是这里需要注意,单个document的路由非常简单,但是SolrCloud支持批量add,也就是说正常情况下N个document同时进行路由。这个时候SolrCloud就会根据document路由的去向分开存放document即进行分类(这里应该是有聚类,官方文档的说法见前面说的),然后进行并发发送至相应的shard,这就需要较高的并发能力。
(3)Leader接受到update请求后,先将update信息存放到本地的update log,同时Leader还会给documrnt分配新的version,对于已存在的document,Leader就会验证分配的新version与已有的version,如果新的版本高就会抛弃旧版本,最后发送至replica。
(4)当只有一个Replica的时候,replica会进入recoveing状态并持续一段时间等待leader重新上线,如果在这段时间内,leader没有上线,replica会转成leader并有一些文档损失。(我的理解:如果leader挂了,请求还会发送成功???? )
(5)最后的步骤就是commit了,commit有两种,一种是softcommit,即在内存中生成segment,document是可见的(可查询到)但是没有写入磁盘,断电后数据丢失。另一种是hardcommit,直接将数据写入磁盘且数据可见。前一种消耗较少,后一种消耗较大。
每commit一次,就会重新生成一个ulog更新日志,当服务器挂掉,内存数据丢失,就可以从ulog中恢复
三、查询
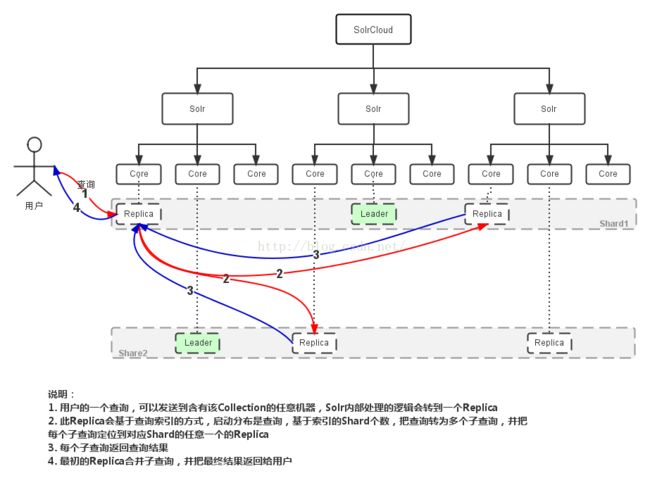
NRT 近实时搜索
SolrCloud支持近实时搜索,所谓的近实时搜索即在较短的时间内使得add的document可见可查,这主要基于softcommit机制(Lucene是没有softcommit的,只有hardcommit)。
当进行SoftCommit时候,Solr会打开新的Searcher从而使得新的document可见,同时Solr还会进行预热缓存以及查询以使得缓存的数据也是可见的。所以必须保证预热缓存以及预热查询的执行时间必须短于commit的频率,否则就会由于打开太多的searcher而造成commit失败。
最后说说在工作中近实时搜索的感受吧,近实时搜索是相对的,对于有些客户1分钟就是近实时了,有些3分钟就是近实时了。而对于Solr来说,softcommit越频繁实时性更高,而softcommit越频繁则Solr的负荷越大(commit越频率越会生成小且多的segment,于是merge出现的更频繁)。目前我们公司的softcommit频率是3分钟,之前设置过1分钟而使得Solr在Index所占资源过多大大影响了查询。所以近实时蛮困扰着我们的,因为客户会不停的要求你更加实时,目前公司采用加入缓存机制来弥补这个实时性。
四、ShardSplit
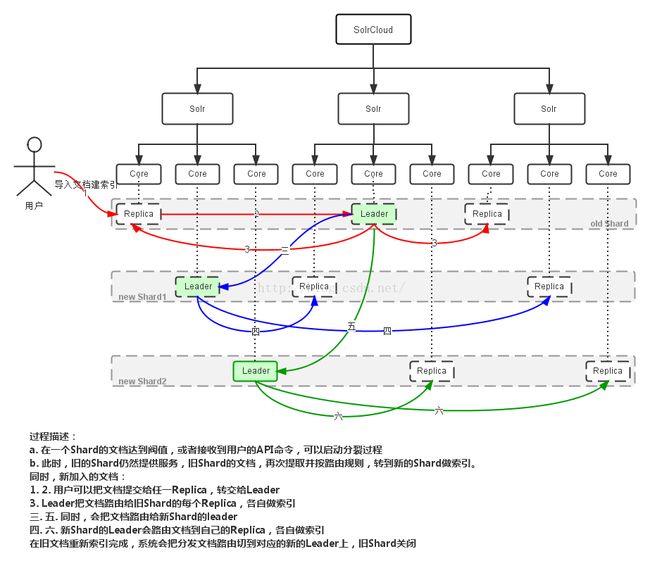
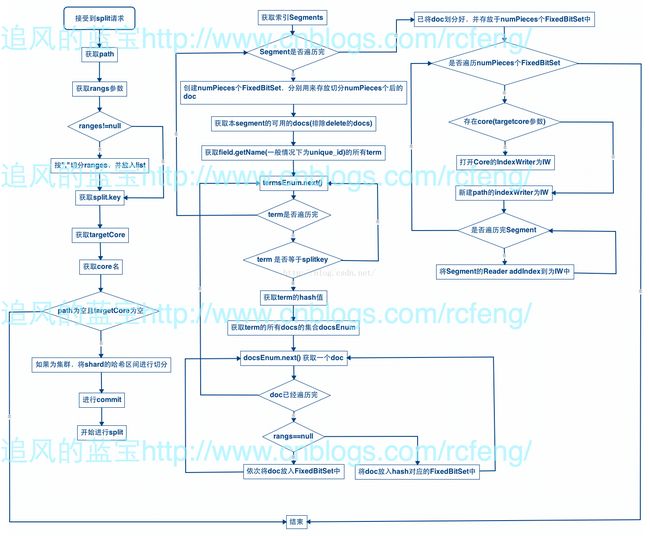
有以下几个配置参数:
· path,path是指core0索引最后切分好后存放的路径,它支持多个,比如cores?action=SPLIT&core=core0&path=path1&path=path2。
· targetCore,就是将core0索引切分好后放入targetCore中(targetCore必须已经建立),它同样支持多个,请注意path和targetCore两个参数必须至少存在一个。
· split.key, 根据该key进行切分,默认为unique_id.
· ranges, 哈希区间,默认按切分个数进行均分。
· 由此可见Core的Split api是较底层的借口,它可以实现将一个core分成任意数量的索引(或者core)
五、负载均衡
查询的负载均衡还是要自己做的。至于文档放到哪个shard,就是按照id做的,如果是配置route.name=implicit, 那么自己指定去哪个shard
六、故障恢复
1、故障恢复的情况
有几种情况下回进行recovering :
(1)有下线的replica
当索引更新的时候,不会顾及下线的replica,当上线的时候会有recovery进程对他们进行回复,如果转发的replica出于recovering状态,那么这个replica会把update放入update transaction日志。
(2)如果shard(我觉得)只有一个replica
当只有一个Replica的时候,replica会进入recoveing状态并持续一段时间等待leader重新上线,如果在这段时间内,leader没有上线,replica会转成leader并有一些文档损失。(我的理解:如果leader挂了,请求还会发送成功???? )
(3)SolrCloud在进行update时候,由于某种原因leader转发update至replica没有成功,会迫使replica进行recoverying进行数据同步。
2、Recovery策略
就上面的第三种,讲Recovery的策略:
(1)Peer sync, 如果中断的时间较短,recovering node只是丢失少量update请求,那么它可以从leader的update log中获取。这个临界值是100个update请求,如果大于100,就会从leader进行完整的索引快照恢复。
(2)Snapshot replication, 如果节点下线太久以至于不能从leader那进行同步,它就会使用solr的基于http进行索引的快照恢复
当你加入新的replica到shard中,它就会进行一个完整的index Snapshot。
3、两种策略的具体过程
(1)整体的过程
solr 向所有的Replica发送getVersion的请求,获取最新的nupdate个version(默认100个),并排序。获取本分片的100个version,
对比replica和replica的version,看是不是有交集:
a)有交集,就部分更新Peer sync (按document为单位)
b)没有交集,说明差距太大,那么就replication (以文件为最小单位)
(2)replication的具体过程
(a)开始Replication的时候,首先进行一次commitOnLeader操作,即发送commit命令到leader。它的作用就是将leader的update中的数据刷入到索引文件中,使得快照snap完整。
(b)各种判断之后,下载索引数据,进行replication
(c)replication的时候,shard状态时recoverying,分片可以建索引但是不能查询,同步的时候,新来的数据会进入ulog,但是这些数据从源码看不会进入索引文件(原因是:
1. 因为一旦有新数据写入旧索引文件中,索引文件发送变化了,那么下载好后的数据(索引文件)就不好替换旧的索引文件。
2. 在同步过程中,如果isFullCopyNeeded是false,那么就会close indexwriter,既然关闭了indexwriter就无法写入新的数据。而如果isFullCopyNeeded是true的话,因为整个index目录替换,所以是否关闭indexeriter也没啥意义。
3. 在recovery过程中,当同步replication结束后,会进行replay过程,该过程就是将ulog中的请求重新进行一遍。这样就可以把之前错过的都在写入。
来源:
)。
3、容错的其他方面
容错
(1)读
每个搜索的请求都被一个collection的所有的shards执行,如果有些shard没有返回结果,那么查询是失败的。这时候根据配置 shards.tolerant 参数,如果是true, 那么部分结果会被返回。
(2)写
每个节点的组织和内容的改变都会写入Transaction log,日志被用来决定节点中的哪些内容应该被包含在replica,当一个新的replica被创建的时候,通过leader和Transaction log去判断哪些内容应该被包含。同时,这个log也可以用来恢复。TransactionLog由一个保存了一系列的更新操作的记录构成,它能增加索引操作的健壮性,因为只要某个节点在索引操作过程中意外中断了,它可以重做所有未提交的更新操作。
假如一个leader节点宕机了,可能它已经把请求发送到了一些replica节点但是却没有发送到另一些却没有发送,所以在一个新的leader节点在被选举出来之前,它会依靠其他replica节点来运行一个同步处理操作。如果这个操作成功了的话,所有节点的数据就都保持一致了,然后leader节点把自己注册为活动节点,普通的操作就会被处理。如果一个replica节点的数据脱离整体同步太多了的话,系统会请求执行一个全量的基于普通的replication同步恢复。
集群的overseer会监测各个shard的leader节点,如果leader节点挂了,则会启动自动的容错机制,会从同一个shard中的其他replica节点集中重新选举出一个leader节点,甚至如果overseer节点自己也挂了,同样会自动在其他节点上启用新的overseer节点,这样就确保了集群的高可用性。
七、选举的策略
SolrCloud没有master或slave. Leader被自动选举,最初按照first-come-first-serve
然后按照zk的选举方式http://zookeeper.apache.org/doc/trunk/recipes.html#sc_leaderElection
zk的选举方式:zk给每个服务器一个id,新来的机器的id大于之前的。 如果leader宕机,所有的应用看着当前最小的编号,然后看
| 每一个 follower 对 follower 集群中对应的比自己节点序号小一号的节点(也就是所有序号比自己小的节点中的序号最大的节点)设置一个 watch 。只有当follower 所设置的 watch 被触发的时候,它才进行 Leader 选举操作,一般情况下它将成为集群中的下一个 Leader。很明显,此 Leader 选举操作的速度是很快的。因为,每一次 Leader 选举几乎只涉及单个 follower 的操作。 来源:
|
(3)如果有新的node启动,会被分配到replicas最少的shard, 如果有tie, 被指派到最小的shard ID 那个shard里面。
(4)我自己试验过,如果结点关闭在开启,那么leader的id会增大而不是用原来的。
原文:
Leader ElectionA simple way of doing leader election with ZooKeeper is to use the SEQUENCE|EPHEMERAL flags when creating znodes that represent "proposals" of clients. The idea is to have a znode, say "/election", such that each znode creates a child znode "/election/guid-n_" with both flags SEQUENCE|EPHEMERAL. With the sequence flag, ZooKeeper automatically appends a sequence number that is greater than any one previously appended to a child of "/election". The process that created the znode with the smallest appended sequence number is the leader. That's not all, though. It is important to watch for failures of the leader, so that a new client arises as the new leader in the case the current leader fails. A trivial solution is to have all application processes watching upon the current smallest znode, and checking if they are the new leader when the smallest znode goes away (note that the smallest znode will go away if the leader fails because the node is ephemeral). But this causes a herd effect: upon of failure of the current leader, all other processes receive a notification, and execute getChildren on "/election" to obtain the current list of children of "/election". If the number of clients is large, it causes a spike on the number of operations that ZooKeeper servers have to process. To avoid the herd effect, it is sufficient to watch for the next znode down on the sequence of znodes. If a client receives a notification that the znode it is watching is gone, then it becomes the new leader in the case that there is no smaller znode. Note that this avoids the herd effect by not having all clients watching the same znode. Here's the pseudo code: Let ELECTION be a path of choice of the application. To volunteer to be a leader: 1. Create znode z with path "ELECTION/guid-n_" with both SEQUENCE and EPHEMERAL flags; 2. Let C be the children of "ELECTION", and i be the sequence number of z; 3. Watch for changes on "ELECTION/guid-n_j", where j is the largest sequence number such that j < i and n_j is a znode in C; Upon receiving a notification of znode deletion: 1. Let C be the new set of children of ELECTION; 2. If z is the smallest node in C, then execute leader procedure; 3. Otherwise, watch for changes on "ELECTION/guid-n_j", where j is the largest sequence number such that j < i and n_j is a znode in C; Notes: · Note that the znode having no preceding znode on the list of children does not imply that the creator of this znode is aware that it is the current leader. Applications may consider creating a separate znode to acknowledge that the leader has executed the leader procedure. · See the note for Locks on how to use the guid in the node. http://zookeeper.apache.org/doc/trunk/recipes.html#sc_leaderElection |
参考文献(可能不太全)
1、 http://my.oschina.net/004/blog/175768
2、 http://blog.csdn.net/wanghui2008123/article/details/37813525
3、 http://www.cnblogs.com/phinecos/archive/2012/02/10/2345634.html
4、 http://zookeeper.apache.org/doc/r3.3.2/zookeeperOver.html
四篇讲原理的博客
5、http://www.cnblogs.com/phinecos/archive/2012/02/10/2345634.html
6、http://www.cnblogs.com/phinecos/archive/2012/02/15/2353007.html
7、http://www.cnblogs.com/phinecos/archive/2012/02/16/2354834.html
8、http://www.cnblogs.com/phinecos/archive/2012/02/29/2372682.html
一大坨源码分析的博客
9、http://www.cnblogs.com/rcfeng/category/659593.html
10、 SolrCloud的一个翻译
http://my.oschina.net/zengjie/blog?disp=2&p=1&catalog=150095
11、 http://www.cnblogs.com/rcfeng/p/4158828.html
12、http://www.cnblogs.com/rcfeng/p/4145349.html
13、http://www.cnblogs.com/rcfeng/p/4148733.html
14、http://blog.csdn.net/thunder4393/article/details/44992485
15、http://www.cnblogs.com/phinecos/archive/2012/02/10/2345634.html