数据挖掘十大算法----EM算法(最大期望算法)
概念
在统计计算中,最大期望(EM)算法是在概率(probabilistic)模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variable)。
最大期望经常用在机器学习和计算机视觉的数据聚类(Data Clustering)领域。
可以有一些比较形象的比喻说法把这个算法讲清楚。
比如说食堂的大师傅炒了一份菜,要等分成两份给两个人吃,显然没有必要拿来天平一点一点的精确的去称分量,最简单的办法是先随意的把菜分到两个碗中,然后观察是否一样多,把比较多的那一份取出一点放到另一个碗中,这个过程一直迭代地执行下去,直到大家看不出两个碗所容纳的菜有什么分量上的不同为止。(来自百度百科)
EM算法就是这样,假设我们估计知道A和B两个参数,在开始状态下二者都是未知的,并且知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM算法还是许多非监督聚类算法的基础(如Cheeseman et al. 1988),而且它是用于学习部分可观察马尔可夫模型(Partially Observable Markov Model)的广泛使用的Baum-Welch前向后向算法的基础。
估计k个高斯分布的均值
介绍EM算法最方便的方法是通过一个例子。
考虑数据D是一实例集合,它由k个不同正态分布的混合所得分布所生成。该问题框架在下图中示出,其中k=2而且实例为沿着x轴显示的点。
每个实例使用一个两步骤过程形成。
首先了随机选择k个正态分布其中之一。
其次随机变量xi按照此选择的分布生成。
这一过程不断重复,生成一组数据点如图所示。为使讨论简单化,我们考虑一个简单情形,即单个正态分布的选择基于统一的概率进行选择,并且k个正态分布有相同的方差σ2,且σ2已知。
学习任务是输出一个假设h=<μ1…μk>,它描述了k个分布中每一个分布的均值。我们希望对这些均值找到一个极大似然假设,即一个使P(D|h)最大化的假设h。

注意到,当给定从一个正态分布中抽取的数据实例x1,x2, …, xm时,很容易计算该分布的均值的极大似然假设。
其中我们可以证明极大似然假设是使m个训练实例上的误差平方和最小化的假设。
使用当表述一下式,可以得到:
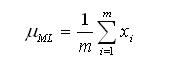 (公式一)
(公式一)
然而,在这里我们的问题涉及到k个不同正态分布的混合,而且我们不能知道哪个实例是哪个分布产生的。因此这是一个涉及隐藏变量的典型例子。
EM算法步骤
在上图的例子中,可把每个实例的完整描述看作是三元组<xi,zi1, zi2>,其中xi是第i个实例的观测值,zi1和zi2表示两个正态分布中哪个被用于产生值xi。
确切地讲,zij在xi由第j个正态分布产生时值为1,否则为0。这里xi是实例的描述中已观察到的变量,zi1和zi2是隐藏变量。如果zi1和zi2的值可知,就可以用式一来解决均值μ1和μ2。因为它们未知,因此我们只能用EM算法。
EM算法应用于我们的k均值问题,目的是搜索一个极大似然假设,方法是根据当前假设<μ1…μk>不断地再估计隐藏变量zij的期望值。然后用这些隐藏变量的期望值重新计算极大似然假设。这里首先描述这一实例化的EM算法,以后将给出EM算法的一般形式。
为了估计上图中的两个均值,EM算法首先将假设初始化为h=<μ1,μ2>,其中μ1和μ2为任意的初始值。然后重复以下的两个步骤以重估计h,直到该过程收敛到一个稳定的h值。
步骤1:计算每个隐藏变量zij的期望值E[zij],假定当前假设h=<μ1,μ2>成立。
步骤2:计算一个新的极大似然假设h´=<μ1´,μ2´>,假定由每个隐藏变量zij所取的值为第1步中得到的期望值E[zij],然后将假设h=<μ1,μ2>替换为新的假设h´=<μ1´,μ2´>,然后循环。
现在考察第一步是如何实现的。步骤1要计算每个zij的期望值。此E[zij]正是实例xi由第j个正态分布生成的概率:


因此第一步可由将当前值<μ1,μ2>和已知的xi代入到上式中实现。
在第二步,使用第1步中得到的E[zij]来导出一新的极大似然假设h´=<μ1´,μ2´>。如后面将讨论到的,这时的极大似然假设为:

注意此表达式类似于公式一中的样本均值,它用于从单个正态分布中估计μ。新的表达式只是对μj的加权样本均值,每个实例的权重为其由第j个正态分布产生的期望值。
上面估计k个正态分布均值的算法描述了EM方法的要点:即当前的假设用于估计未知变量,而这些变量的期望值再被用于改进假设。
可以证明,在此算法第一次循环中,EM算法能使似然性P(D|h)增加,除非它已达到局部的最大。因此该算法收敛到对于<μ1,μ2>的一个局部极大可能性假设。
EM算法的一般表述
上面的EM算法针对的是估计混合正态分布均值的问题。更一般地,EM算法可用于许多问题框架,其中需要估计一组描述基准概率分布的参数θ,只给定了由此分布产生的全部数据中能观察到的一部分。
在上面的二均值问题中,感兴趣的参数为θ=<μ1,μ2>,而全部数据为三元组<xi,zi1, zi2>,而只有xi可观察到,一般地令X=<x1, …,xm>代表在同样的实例中已经观察到的数据,并令Y=X∪Z代表全体数据。注意到未观察到的Z可被看作一随机变量,它的概率分布依赖于未知参数θ和已知数据X。类似地,Y是一随机变量,因为它是由随机变量Z来定义的。在后续部分,将描述EM算法的一般形式。使用h来代表参数θ的假设值,而h´代表在EM算法的每次迭代中修改的假设。
EM算法通过搜寻使E[lnP(Y|h´)]最大的h´来寻找极大似然假设h´。此期望值是在Y所遵循的概率分布上计算,此分布由未知参数θ确定。考虑此表达式究竟意味了什么。
首先P(Y|h´)是给定假设h´下全部数据Y的似然性。其合理性在于我们要寻找一个h´使该量的某函数值最大化。
其次使该量的对数lnP(Y|h´)最大化也使P(Y|h´)最大化,如已经介绍过的那样。
第三,引入期望值E[lnP(Y|h´)]是因为全部数据Y本身也是一随机变量。
已知全部数据Y是观察到的X和未观察到的Z的合并,我们必须在未观察到的Z的可能值上取平均,并以相应的概率为权值。换言之,要在随机变量Y遵循的概率分布上取期望值E[lnP(Y|h´)]。该分布由完全已知的X值加上Z服从的分布来确定。
Y遵从的概率分布是什么?一般来说不能知道此分布,因为它是由待估计的θ参数确定的。然而,EM算法使用其当前的假设h代替实际参数θ,以估计Y的分布。现定义一函数Q(h´|h),它将E[lnP(Y|h´)]作为h´的一个函数给出,在θ=h和全部数据Y的观察到的部分X的假定之下。
![]()
将Q函数写成Q(h´|h)是为了表示其定义是在当前假设h等于θ的假定下。在EM算法的一般形式里,它重复以下两个步骤直至收敛。
步骤1:估计(E)步骤:使用当前假设h和观察到的数据X来估计Y上的概率分布以计算Q(h´|h)。
![]()
步骤2:最大化(M)步骤:将假设h替换为使Q函数最大化的假设h´:
![]()
当函数Q连续时,EM算法收敛到似然函数P(Y|h´)的一个不动点。若此似然函数有单个的最大值时,EM算法可以收敛到这个对h´的全局的极大似然估计。否则,它只保证收敛到一个局部最大值。因此,EM与其他最优化方法有同样的局限性,如之前讨论的梯度下降,线性搜索和变形梯度等。
总结来说,EM算法就是通过迭代地最大化完整数据的对数似然函数的期望,来最大化不完整数据的对数似然函数。