数据挖掘中的关联规则--面向频繁项集的A-Priori算法
文章目录
-
- 一、频繁项集与关联规则学习
-
-
- 1. 实体与关系
- 2. 支持度与频繁项集
- 3. 关联规则
-
- 二、寻找频繁项集
-
- 1.频繁项集发现的挑战
-
- 三角矩阵
- 项对计数值的三元组存储方法
- 2.频繁项集的单调性
- 3.面向项对的 A-Priori 算法
- 4.PCY 算法
-
- 哈希表创建
- 第二遍扫描
- 5、多阶段算法
- 6、多哈希算法
- 7、随机化算法
- 8、SON 算法
- 9、Toivonen 算法
- 三、频繁项集小实践:消费者购买记录
-
- 模拟数据示例
- 具体问题分析
一、频繁项集与关联规则学习
1. 实体与关系
- 项和购物篮:在购物篮数据模型中,假设存在两种实体:项(items)和购物篮(baskets)。这两者之间存在一个多对多的关系。通常情况下,购物篮与小规模的项集相关联,而项可以与多个购物篮相关联。
2. 支持度与频繁项集
- 支持度:一个项集的支持度是包含该项集所有项的购物篮数量。支持度高于某个阈值的项集被称为频繁项集。
3. 关联规则
- 关联规则:关联规则是一个蕴含式,形式为“如果一个购物篮包含某个项集 ( A ),那么它很可能也包含另一个特定的项 ( B )”。在这里,项 ( B ) 的出现概率称为规则的可信度(confidence)。规则的兴趣度(interest)指的是可信度与包含 ( B ) 的所有购物篮的比率之间的差值。
二、寻找频繁项集
1.频繁项集发现的挑战
- 项对计数瓶颈:发现频繁项集时,必须检查所有购物篮并对某个规模的项集出现次数进行计数。对于典型的数据而言,其目标是产生数量不多但最频繁的项集。通常,在内存中项对的计数会占据主要部分。因此,频繁项集发现方法通常会集中在如何最小化项对计数所需的内存大小。
三角矩阵
- 尽管可以使用一个二维数组对项对计数,但由于没有必要同时利用数组中的元素 ( [i, j] ) 和 ( [j, i] ) 来对项对 ( (i, j) ) 计数,因此使用二维数组的方式会浪费一半空间。通过安排项对 ( (i, j) ),其中按照字典序有 ( i < j ),可以使用一维数组存储所需的计数值,这样就不会浪费空间,同时能够对任意项对的计数值进行高效访问。
项对计数值的三元组存储方法
- 如果在所有可能的项对中,只有不到 ( \frac{1}{3} ) 的项对真正出现在购物篮中,那么采用三元组的方式来存储项对 ( (i, j, c) ) 的计数值将更节省空间,其中 ( c ) 是项对 ( {i, j} ) 的计数值,且 ( i < j )。采用类似哈希表的索引结构可以允许对 ( {i, j} ) 对应的三元组进行快速定位。
2.频繁项集的单调性
- 单调性:项集的一个重要性质是,如果某个项集是频繁的,则其所有子集也是频繁的。该性质的逆否形式可以用于减少对某些项集的计数,即如果某个项集是非频繁的,则其所有超集也是非频繁的。
3.面向项对的 A-Priori 算法
- A-Priori 算法通过对购物篮进行两遍扫描来得到所有的频繁项对:
- 第一遍扫描:对单个项进行计数,并确定哪些项是频繁的。
- 第二遍扫描:只对由第一遍扫描中发现的两个频繁项组成的项对进行计数。单调性理论能够证明忽略其他项对是合理的。
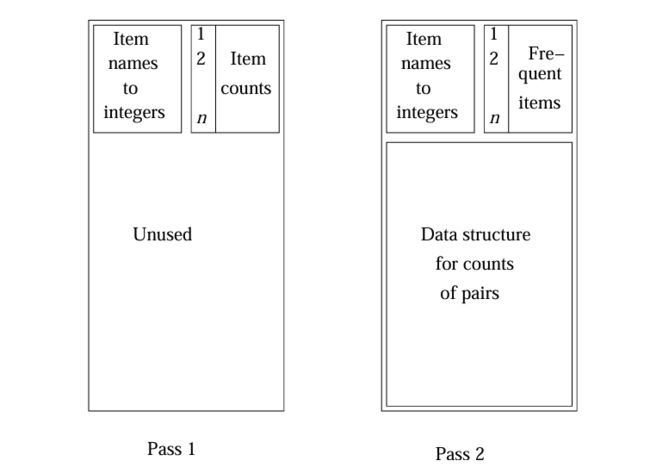
4.PCY 算法
PCY(Park-Chen-Yu)算法是对 A-Priori 算法的改进,主要通过在第一遍扫描中创建哈希表来优化项对计数的过程。其基本机制包括以下几个步骤:
哈希表创建
- 哈希处理:在第一遍扫描中,算法对项对进行哈希处理。哈希表存放的整数代表的是哈希到该桶中的项对数目,而不是直接存储项对的计数值。
- 内存利用:通过使用哈希表,PCY 算法在项计数时不需要占用所有内存空间。这种方式可以显著降低内存的使用,特别是在处理大规模数据时。
第二遍扫描
- 频繁桶计数:在第二遍扫描中,算法仅需对哈希到频繁桶的两个频繁项进行计数。频繁桶的定义是指计数值不低于支持度阈值的桶。
5、多阶段算法
- 额外扫描过程:PCY 算法的第一遍和第二遍扫描之间可以插入额外的扫描过程。在这些中间扫描过程中,将项对哈希到另外的独立哈希表中。
- 目标:在每个中间扫描过程中,仅哈希那些在以往扫描中哈希到频繁桶的两个频繁项。
6、多哈希算法
- 多哈希表:PCY 算法的第一遍扫描可以进行修改,将可用内存划分给多个哈希表。
- 计数处理:在第二遍扫描中,仅对在所有哈希表中都哈希到频繁桶的两个频繁项组成的项对进行计数。
7、随机化算法
- 样本数据处理:随机化算法不对所有数据进行扫描,而是选择所有购物篮的一个随机样本进行处理。样本的规模须足够小,以便能够放入内存,并且满足项集计数所需空间的要求。
- 支持度阈值调整:样本数据上的支持度阈值需要根据数据比例进行适当的尺度变换处理。
- 代表性期望:通过在样本数据集上找到频繁项集,算法希望这些项集能够很好地代表整个数据集。
- 限制:尽管该算法最多只需对整个数据集做一遍扫描,但它仍然受到伪正例的影响,即在样本数据中频繁而在整个数据集中不频繁的项集现象。
8、SON 算法
- 对简单随机化算法的改进是将整个购物篮文件划分成多个小段,这些段足够小以致段上的所有频繁项集都可以在内存中发现。候选项集由至少在一个段上出现的频繁项集组成。第二遍扫描可以允许我们对所有的候选项集进行计数并发现确切的频繁项集的集合。该算法特别适合于采用 MapReduce 机制来实现。
9、Toivonen 算法
- 该算法首先在抽样数据集上发现频繁项集,但是采用的支持度阈值较低,以保证在整个数据集上的频繁项集的丢失几率较低。下一步是检查购物篮整个文件,此时不仅要对所有样本数据集上的频繁项集计数,而且要对反例边界(那些自己还没发现频繁但是其所有直接子集都频繁的项集)上的项集计数。如果反例边界上的任意集合都在整个数据集上不频繁,那么结果是确切的。但是如果反例边界上的一个集合被发现是频繁的,那么需要在一个新的样本数据集上重复整个处理过程。
三、频繁项集小实践:消费者购买记录
模拟数据示例
数据集中包含了多笔交易记录,每笔交易记录由顾客购买的商品组成。具体交易如下:
- 购买了牛奶、面包和尿布
- 购买了牛奶、尿布、啤酒和鸡蛋
- 购买了牛奶、面包、尿布和啤酒
- 购买了面包和尿布
- 购买了牛奶、面包、尿布和可乐
- 购买了尿布和啤酒
- 购买了牛奶、面包和可乐
- 购买了牛奶、尿布和可乐
- 购买了面包、尿布和可乐
具体问题分析
-
消费者偏好分析:
- 问题:哪些商品是顾客偏好的组合?顾客在购物时倾向于同时购买哪些商品?
- 背景:了解消费者的偏好可以帮助商家识别热销商品,制定更加有效的营销策略。
-
交叉销售机会:
- 问题:如何通过现有的购买记录找到潜在的交叉销售机会?
- 背景:如果顾客购买了尿布,是否有可能同时也购买啤酒?通过分析频繁项集,商家能够找到这些潜在的交叉销售机会,以提升销售额。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :catkin_ws
@File :A_priori.py
@IDE :PyCharm
@Author :maosw
@Date :2025/1/22 22:19
'''
import csv
from itertools import chain, combinations
from collections import defaultdict
# 创建模拟数据
data = [
['Milk', 'Bread', 'Diaper'],
['Milk', 'Diaper', 'Beer', 'Eggs'],
['Milk', 'Bread', 'Diaper', 'Beer'],
['Bread', 'Diaper'],
['Milk', 'Bread', 'Diaper', 'Cola'],
['Diaper', 'Beer'],
['Milk', 'Bread', 'Cola'],
['Milk', 'Diaper', 'Cola'],
['Bread', 'Diaper', 'Cola'],
]
# 将数据写入 CSV 文件
with open('transactions.csv', 'w', newline='') as file:
writer = csv.writer(file)
for transaction in data:
writer.writerow(transaction)
def subsets(arr):
"""返回非空子集"""
return chain(*[combinations(arr, i + 1) for i in range(len(arr))])
def get_support(itemset, transaction_list):
"""计算支持度"""
count = sum(1 for transaction in transaction_list if itemset.issubset(transaction))
return count / len(transaction_list)
def apriori(transactions, min_support):
"""实现 Apriori 算法"""
itemset = set()
for transaction in transactions:
for item in transaction:
itemset.add(frozenset([item])) # 生成 1-itemSet
# 计算频繁项集
freq_itemsets = {}
current_itemset = {item for item in itemset if get_support(item, transactions) >= min_support}
k = 1
while current_itemset:
freq_itemsets[k] = current_itemset
k += 1
current_itemset = {i.union(j) for i in current_itemset for j in current_itemset if
len(i.union(j)) == k and get_support(i.union(j), transactions) >= min_support}
return freq_itemsets
def generate_association_rules(freq_itemsets, min_confidence):
"""生成关联规则"""
rules = []
for k, itemsets in freq_itemsets.items():
if k < 2: # 只对 2项集及以上尝试生成规则
continue
for itemset in itemsets:
for subset in subsets(itemset):
remain = itemset.difference(frozenset(subset))
if remain: # 只处理非空剩余
confidence = get_support(itemset, transactions) / get_support(frozenset(subset), transactions)
if confidence >= min_confidence:
rules.append(((tuple(subset), tuple(remain)), confidence))
return rules
def print_frequent_itemsets(freq_itemsets):
"""打印频繁项集"""
for k, itemsets in freq_itemsets.items():
print(f"频繁 {k}-项集:")
for itemset in itemsets:
print(f" {set(itemset)}")
def print_association_rules(rules):
"""打印关联规则"""
print("\n生成的关联规则:")
for rule, confidence in rules:
antecedent, consequent = rule
print(f"规则: {set(antecedent)} ==> {set(consequent)} , 置信度: {confidence:.3f}")
# 读取数据
def load_transactions(filename):
transactions = []
with open(filename, 'r') as file:
reader = csv.reader(file)
for row in reader:
transactions.append(frozenset(row))
return transactions
# 主程序
if __name__ == "__main__":
transactions = load_transactions('transactions.csv')
min_support = 0.2 # 最小支持度
min_confidence = 0.6 # 最小置信度
freq_itemsets = apriori(transactions, min_support)
print_frequent_itemsets(freq_itemsets)
# 生成和打印关联规则
rules = generate_association_rules(freq_itemsets, min_confidence)
print_association_rules(rules)