【Tensorflow2.0】7、全流程model.fit模型训练方法
文章目录
- 第一种方法直接用keras的fit方法,以fashion mnist为例
- 配置超参数
- 选择指定显卡及自动调用显存
- 准备数据
- 使用tf.data来准备训练集和测试集
- 准备模型定义
- 开始定义模型,用functional方法
- 打印模型结构
- 画出模型结构图并保存
- 定义优化算法和损失函数
- 编译模型
- 定义callbacks
- 1、生成ckpt每个epoch训练完保存一个模型
- 2、当模型验证集精度长时间不再提升时停止训练
- 3、自定义学习率按需衰减,并把整个学习率变化过程保存
- 4、使用tensorboard
- 5、loss中出现nan或inf时停止训练
- 6、模型损失长时间不除时大程度降低学习率
- 7、保存训练过程中所有标量指标
- callbacks更新:
- 更新tensorboard
- 增加每次测试后画confusion matrix 保存到日志文件和tensorboard
- 综合所有的callbacks
- 开始训练模型
- 画学习率变化曲线并保存到log中
- 画模型训练及验证loss和acc曲线
- 保存模型结构及配置参数
- 对模型在测试集上进行评估
- 对模型进行推理并分析推理结果
- 显示输出文件结构
- 同样,只改变保存类型为ckpt
- 总结:
第一种方法直接用keras的fit方法,以fashion mnist为例
本文包括一个完整的深度学习模型构建过程。有tf.data读数据集的方法;使用keras callbacks来实现checkpoint,学习率衰减,Earlystop等功能。最后结合scikit-learn,对模型的推理使用做了说明。称为第一种方法是因为还有一种是使用tf.GradientTape()的动态图方法(model.fit是静态图方法),关于动态图部分,会写一篇博客来实本文model.fit中的静态方法的功能。
import tensorflow as tf
import datetime
import matplotlib
matplotlib.use("Agg")#这个设置可以使matplotlib保存.png图到磁盘
import matplotlib.pyplot as plt
from functools import partial
import numpy as np
import pandas as pd
import os
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
#jupyter 中开启该选项,否则不执行
%matplotlib inline
配置超参数
batch_size=64
epochs=5
regularizer=1e-3
total_train_samples=60000
total_test_samples=10000
lr_decay_epochs=1
output_folder="./model_output"
#用来保存模型以及我们需要的所有东西
if not os.path.exists(output_folder):
os.makedirs(output_folder)
save_format="hdf5" #或saved_model
if save_format=="hdf5":
save_path_models=os.path.join(output_folder,"hdf5_models")
if not os.path.exists(save_path_models):
os.makedirs(save_path_models)
save_path=os.path.join(save_path_models,"ckpt_epoch{epoch:02d}_val_acc{val_accuracy:.2f}.hdf5")
elif save_format=="saved_model":
save_path_models=os.path.join(output_folder,"saved_models")
if not os.path.exists(save_path_models):
os.makedirs(save_path_models)
save_path=os.path.join(save_path_models,"ckpt_epoch{epoch:02d}_val_acc{val_accuracy:.2f}.ckpt")
#用来保存日志
log_dir= os.path.join(output_folder,'logs_{}'.format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S")))
if not os.path.exists(log_dir):
os.makedirs(log_dir)
选择指定显卡及自动调用显存
physical_devices = tf.config.experimental.list_physical_devices('GPU')#列出所有可见显卡
print("All the available GPUs:\n",physical_devices)
if physical_devices:
gpu=physical_devices[0]#显示第一块显卡
tf.config.experimental.set_memory_growth(gpu, True)#根据需要自动增长显存
tf.config.experimental.set_visible_devices(gpu, 'GPU')#只选择第一块
All the available GPUs:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
准备数据
fashion_mnist=tf.keras.datasets.fashion_mnist
(train_x,train_y),(test_x,test_y)=fashion_mnist.load_data()
train_x,test_x = train_x[...,np.newaxis]/255.0,test_x[...,np.newaxis]/255.0
total_train_sample = train_x.shape[0]
total_test_sample=test_x.shape[0]
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
使用tf.data来准备训练集和测试集
train_ds = tf.data.Dataset.from_tensor_slices((train_x,train_y))
test_ds = tf.data.Dataset.from_tensor_slices((test_x,test_y))
train_ds=train_ds.shuffle(buffer_size=batch_size*10).batch(batch_size).prefetch(buffer_size = tf.data.experimental.AUTOTUNE).repeat()
test_ds = test_ds.batch(batch_size).prefetch(buffer_size = tf.data.experimental.AUTOTUNE)#不加repeat,执行一次就行
准备模型定义
l2 = tf.keras.regularizers.l2(regularizer)#定义模型正则化方法
ini = tf.keras.initializers.he_normal()#定义参数初始化方法
conv2d = partial(tf.keras.layers.Conv2D,activation='relu',padding='same',kernel_regularizer=l2,bias_regularizer=l2)
fc = partial(tf.keras.layers.Dense,activation='relu',kernel_regularizer=l2,bias_regularizer=l2)
maxpool=tf.keras.layers.MaxPooling2D
dropout=tf.keras.layers.Dropout
开始定义模型,用functional方法
x_input = tf.keras.layers.Input(shape=(28,28,1),name='input_node')
x = conv2d(128,(5,5))(x_input)
x = maxpool((2,2))(x)
x = conv2d(256,(5,5))(x)
x = maxpool((2,2))(x)
x = tf.keras.layers.Flatten()(x)
x = fc(128)(x)
x_output=fc(10,activation=None,name='output_node')(x)
model = tf.keras.models.Model(inputs=x_input,outputs=x_output)
打印模型结构
print("The model architure:\n")
print(model.summary())
The model architure:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_node (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 128) 3328
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 128) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 256) 819456
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 12544) 0
_________________________________________________________________
dense (Dense) (None, 128) 1605760
_________________________________________________________________
output_node (Dense) (None, 10) 1290
=================================================================
Total params: 2,429,834
Trainable params: 2,429,834
Non-trainable params: 0
_________________________________________________________________
None
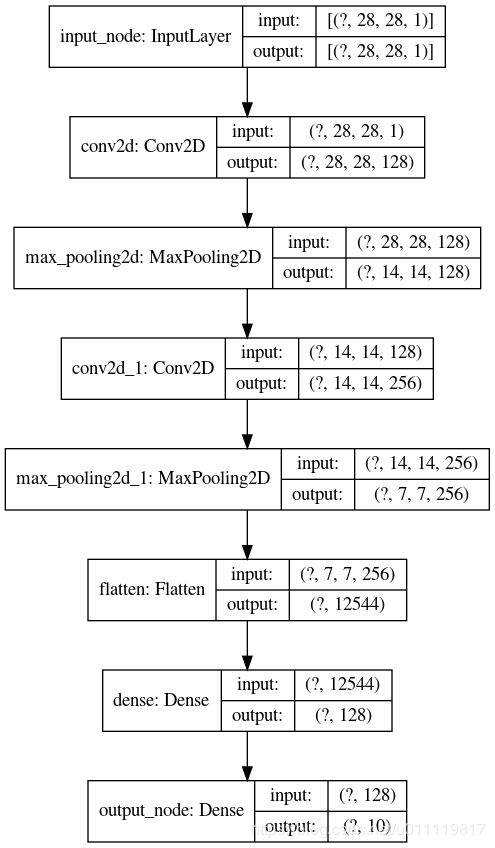
画出模型结构图并保存
tf.keras.utils.plot_model(model,to_file=os.path.join(log_dir,'model.png'),show_shapes=True,show_layer_names=True)
定义优化算法和损失函数
#学习率变化设置,使用指数衰减
train_steps_per_epoch=int(total_train_samples//batch_size)
initial_learning_rate=0.01
# lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate,
# decay_steps=1*train_steps_per_epoch,
# decay_rate=0.96,
# staircase=True)#initial_learning_rate*0.96**(step/decay_steps)
#优化算法
optimizer = tf.keras.optimizers.SGD(learning_rate=initial_learning_rate,momentum=0.95)
# optimizer = tf.keras.optimizers.SGD(learning_rate=lr_schedule,momentum=0.95)
#损失函数
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
#评价指标
# metrics=[tf.keras.metrics.SparseCategoricalAccuracy(),loss]
metrics=['accuracy','sparse_categorical_crossentropy']
#上式第二个参数会返回交叉熵的结果,用loss减去该值就会得到正则化的值(于model.losses和相等),这两种定义方式都可以,下边的会显示名称短一些
编译模型
model.compile(optimizer=optimizer,loss=loss,metrics=metrics)
定义callbacks
1、生成ckpt每个epoch训练完保存一个模型
#模型保存格式默认是saved_model,可以自己定义更改原有类来保存hdf5
ckpt = tf.keras.callbacks.ModelCheckpoint(save_path,monitor='val_accuracy',verbose=1,
save_best_only=False,save_weights_only=False,
save_freq=1)
monitor可选的内容与model.fit history的keys相同,如“loss",“val_accuracy”,“val_loss”,使用这前可以查看一下有那些;save_best_only的True或False作用显然;save_weights_only的True或False指是否只保存模型参数;verbose=1时会打印日志;另外save_path有两种格式,h5或saved model,如save_path='model.h5’将自动保存h5模型(无论save_weights_only是True还是False),save_path=‘model’,将自动保存savedmodel,这时save_weights_only是True或False情况下格式略有不同。
2、当模型验证集精度长时间不再提升时停止训练
#当模型训练不符合我们要求时停止训练,连续5个epoch验证集精度没有提高0.001%停
earlystop=tf.keras.callbacks.EarlyStopping(monitor='val_accuracy',min_delta = 0.0001,patience=5,verbose=True)
3、自定义学习率按需衰减,并把整个学习率变化过程保存
class LearningRateExponentialDecay:
def __init__(self,initial_learning_rate,decay_epochs,decay_rate):
self.initial_learning_rate=initial_learning_rate
self.decay_epochs=decay_epochs
self.decay_rate=decay_rate
def __call__(self,epoch):
dtype =type(self.initial_learning_rate)
decay_epochs=np.array(self.decay_epochs).astype(dtype)
decay_rate=np.array(self.decay_rate).astype(dtype)
epoch = np.array(epoch).astype(dtype)
p = epoch/decay_epochs
lr = self.initial_learning_rate*np.power(decay_rate,p)
return lr
lr_schedule=LearningRateExponentialDecay(initial_learning_rate,lr_decay_epochs,0.96)
lr = tf.keras.callbacks.LearningRateScheduler(lr_schedule,verbose=1)
也可以是一个函数,如官网文档中的说明,函数有一个参数是epoch.
4、使用tensorboard
#还要加入tensorboard的使用,这种方法记录的内容有限
tensorboard = tf.keras.callbacks.TensorBoard(log_dir=log_dir)
5、loss中出现nan或inf时停止训练
这个callback不建意加,因为会调用on_train_batch_end,这样会在每个训练步后加额外的运算,影响训练速度,本文中训练一个epoch用时76秒,去掉这个会变成73秒。其它callback影响不大,因为model.fit会默认调用一些callback,都是和epoch有关的
#定义当loss出现nan或inf时停止训练的callback
terminate=tf.keras.callbacks.TerminateOnNaN()
6、模型损失长时间不除时大程度降低学习率
这个策略通常不于学习率衰减schedule同时使用,或者使用时要合理
#降低学习率(要比学习率自动周期变化有更大变化和更长时间监控)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',factor=0.1,patience=3,verbose=1,min_delta=0.0001,min_lr=0)
7、保存训练过程中所有标量指标
#保存训练过程中大数标量指标,与tensorboard同一个文件
csv_logger = tf.keras.callbacks.CSVLogger(os.path.join(log_dir,'logs.log'),separator=',')
callbacks更新:
更新tensorboard
#还要加入tensorboard的使用,这种方法记录的内容有限
tensorboard = tf.keras.callbacks.TensorBoard(log_dir=log_dir,
histogram_freq=1,#对参数和激活做直方图,一定要有测试集
write_graph=True,#模型结构图
write_images=True,#把模型参数做为图片形式存到
update_freq='epoch',#epoch,batch,整数,太频的话会减慢速度
profile_batch=2,#记录模型性能
embeddings_freq=1,
embeddings_metadata=None#这个还不太清楚如何使用
)
#各个参数的作用请参看文档,需要正确使用
profile_batch=2会使用第二次迭代来分析模型性能,在训练开始会产生warning:
Epoch 00001: LearningRateScheduler reducing learning rate to 0.01.
Epoch 1/5
936/937 [>.] - ETA: 0s - loss: 0.9190 - accuracy: 0.8054 - sparse_categorical_crossentropy: 1.5548 WARNING:tensorflow:Method (on_train_batch_end) is slow compared to the batch update (0.129513). Check your callbacks.
Epoch 00001: saving model to ./model_output/hdf5_models/ckpt_epoch01_val_acc0.87.hdf5
937/937 [==] - 79s 84ms/step - loss: 0.9186 - accuracy: 0.8055 - sparse_categorical_crossentropy: 1.5546 - val_loss: 0.6601 - val_accuracy: 0.8659 - val_sparse_categorical_crossentropy: 1.4305
增加每次测试后画confusion matrix 保存到日志文件和tensorboard
file_writer_cm = tf.summary.create_file_writer(log_dir,filename_suffix='cm')
def plot_to_image(figure,logd_ir,epoch):
"""Converts the matplotlib plot specified by 'figure' to a PNG image and
returns it. The supplied figure is closed and inaccessible after this call."""
# Save the plot to a PNG in memory.
buf = io.BytesIO()
plt.savefig(buf, format='png')
fig=figure
fig.savefig(os.path.join(log_dir,'during_train_confusion_epoch_{}.png'.format(epoch)))
# Closing the figure prevents it from being displayed directly inside
# the notebook.
plt.close(figure)
buf.seek(0)
# Convert PNG buffer to TF image
image = tf.image.decode_png(buf.getvalue(), channels=4)
# Add the batch dimension
image = tf.expand_dims(image, 0)
return image
def plot_confusion_matrix(cm, class_names):
"""
Returns a matplotlib figure containing the plotted confusion matrix.
Args:
cm (array, shape = [n, n]): a confusion matrix of integer classes
class_names (array, shape = [n]): String names of the integer classes
"""
figure = plt.figure(figsize = (8, 8))
plt.imshow(cm, interpolation = 'nearest', cmap = plt.cm.Blues)
plt.title("Confusion matrix")
plt.colorbar()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation = 45)
plt.yticks(tick_marks, class_names)
# Normalize the confusion matrix.
cm = np.around(cm.astype('float') / cm.sum(axis = 1)[:, np.newaxis], decimals = 2)
# Use white text if squares are dark; otherwise black.
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
color = "white" if cm.iloc[i, j] > threshold.iloc[i] else "black"
plt.text(j, i, cm.iloc[i, j], horizontalalignment = "center", color = color)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
return figure
def log_confusion_matrix(epoch, logs):
# Use the model to predict the values from the validation dataset.
test_pred_raw = model.predict(test_x)
test_pred = np.argmax(test_pred_raw, axis=1)
# Calculate the confusion matrix.
cm = confusion_matrix(test_y, test_pred)
# Log the confusion matrix as an image summary.
figure = plot_confusion_matrix(cm, class_names=class_names)
cm_image = plot_to_image(figure,log_dir,epoch)
# Log the confusion matrix as an image summary.
with file_writer_cm.as_default():
tf.summary.image("Confusion Matrix", cm_image, step=epoch)
# Define the per-epoch callback.
cm_callback = tf.keras.callbacks.LambdaCallback(on_epoch_end=log_confusion_matrix)
把所用更新都加到callbacks:
callbacks=[ckpt,earlystop,lr,tensorboard,terminate,reduce_lr,csv_logger,cm_callback]
有关自定义Callbacks的使用,将会在其它博客中写。
综合所有的callbacks
callbacks=[ckpt,earlystop,lr,tensorboard,terminate,reduce_lr,csv_logger]
开始训练模型
# H=model.fit(train_ds,epochs=epochs,steps_per_epoch=len(train_x)//batch_size,validation_data=test_ds)
train_steps_per_epoch=np.floor(otal_train_sample/batch_size).astype(np.int32)
test_steps_per_epoch = np.ceil(total_test_sample/batch_size).astype(np.int32)
H=model.fit(train_ds,epochs=epochs,
steps_per_epoch=train_steps_per_epoch,
validation_data=test_ds,
validation_steps=test_steps_per_epoch,
callbacks=callbacks,verbose=1)
#使用tf.data无法获取训练和测试总数,所以指定训练步数合使训练稳定
Train for 937 steps, validate for 157 steps
Epoch 00001: LearningRateScheduler reducing learning rate to 0.01.
Epoch 1/5
936/937 [============================>.] - ETA: 0s - loss: 0.9190 - accuracy: 0.8054 - sparse_categorical_crossentropy: 1.5548
Epoch 00001: saving model to ./model_output/hdf5_models/ckpt_epoch01_val_acc0.87.hdf5
937/937 [==============================] - 79s 84ms/step - loss: 0.9186 - accuracy: 0.8055 - sparse_categorical_crossentropy: 1.5546 - val_loss: 0.6601 - val_accuracy: 0.8659 - val_sparse_categorical_crossentropy: 1.4305
Epoch 00002: LearningRateScheduler reducing learning rate to 0.0096.
Epoch 2/5
936/937 [============================>.] - ETA: 0s - loss: 0.5597 - accuracy: 0.8831 - sparse_categorical_crossentropy: 1.3619
Epoch 00002: saving model to ./model_output/hdf5_models/ckpt_epoch02_val_acc0.88.hdf5
937/937 [==============================] - 77s 82ms/step - loss: 0.5598 - accuracy: 0.8831 - sparse_categorical_crossentropy: 1.3621 - val_loss: 0.5325 - val_accuracy: 0.8778 - val_sparse_categorical_crossentropy: 1.3255
Epoch 00003: LearningRateScheduler reducing learning rate to 0.009216.
Epoch 3/5
936/937 [============================>.] - ETA: 0s - loss: 0.4613 - accuracy: 0.8939 - sparse_categorical_crossentropy: 1.2847
Epoch 00003: saving model to ./model_output/hdf5_models/ckpt_epoch03_val_acc0.89.hdf5
937/937 [==============================] - 76s 81ms/step - loss: 0.4612 - accuracy: 0.8939 - sparse_categorical_crossentropy: 1.2847 - val_loss: 0.4671 - val_accuracy: 0.8863 - val_sparse_categorical_crossentropy: 1.2375
Epoch 00004: LearningRateScheduler reducing learning rate to 0.008847359999999999.
Epoch 4/5
936/937 [============================>.] - ETA: 0s - loss: 0.4032 - accuracy: 0.9043 - sparse_categorical_crossentropy: 1.2413
Epoch 00004: saving model to ./model_output/hdf5_models/ckpt_epoch04_val_acc0.89.hdf5
937/937 [==============================] - 76s 81ms/step - loss: 0.4030 - accuracy: 0.9043 - sparse_categorical_crossentropy: 1.2412 - val_loss: 0.4287 - val_accuracy: 0.8903 - val_sparse_categorical_crossentropy: 1.2165
Epoch 00005: LearningRateScheduler reducing learning rate to 0.008493465599999998.
Epoch 5/5
936/937 [============================>.] - ETA: 0s - loss: 0.3771 - accuracy: 0.9084 - sparse_categorical_crossentropy: 1.1971
Epoch 00005: saving model to ./model_output/hdf5_models/ckpt_epoch05_val_acc0.89.hdf5
937/937 [==============================] - 76s 81ms/step - loss: 0.3771 - accuracy: 0.9083 - sparse_categorical_crossentropy: 1.1971 - val_loss: 0.4350 - val_accuracy: 0.8884 - val_sparse_categorical_crossentropy: 1.2115
画学习率变化曲线并保存到log中
def plot(lrs,title="Learning Rate Schedule"):
#计算学习率随epoch的变化值
epochs=np.arange(len(lrs))
plt.figure()
plt.plot(epochs,lrs)
plt.xticks(epochs)
plt.scatter(epochs,lrs)
plt.title(title)
plt.xlabel("Epoch #")
plt.ylabel("Learning Rate")
plot(H.history['lr'])
plt.savefig(os.path.join(log_dir,'learning_rate.png'))
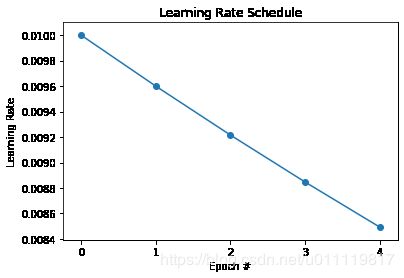
画模型训练及验证loss和acc曲线
plt.figure()
plt.plot(N,H.history['loss'],label='train_loss')
plt.scatter(N,H.history['loss'])
plt.plot(N,H.history['val_loss'],label='val_loss')
plt.scatter(N,H.history['val_loss'])
plt.plot(N,H.history['accuracy'],label='train_acc')
plt.scatter(N,H.history['accuracy'])
plt.plot(N,H.history['val_accuracy'],label='val_acc')
plt.scatter(N,H.history['val_accuracy'])
plt.title('Training Loss and Accuracy on Our_dataset')
plt.xlabel('Epoch #')
plt.ylabel('Loss/Accuracy')
plt.legend()
plt.savefig(os.path.join(log_dir,'training.png'))
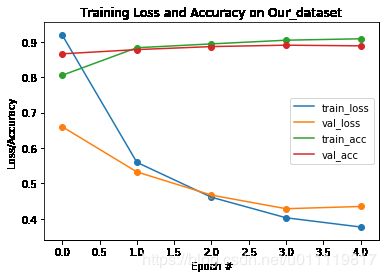
关于上图中epoch=0,随机初始化参数在验证集上精度远高于训练集的原因,将来其它博客中说明。
保存模型结构及配置参数
model_json = model.to_json()
with open(os.path.join(log_dir,'model_json.json'),'w') as json_file:
json_file.write(model_json)
对模型在测试集上进行评估
metrics=model.evaluate(test_ds,verbose=1)
print("val_loss:",metrics[0],"val_accuracy:",metrics[1])
157/157 [==============================] - 4s 26ms/step - loss: 0.4350 - accuracy: 0.8884 - sparse_categorical_crossentropy: 1.2115
val_loss: 0.43501977328282254 val_accuracy: 0.8884
对模型进行推理并分析推理结果
predictions=model.predict(test_ds,verbose=1)
157/157 [==============================] - 4s 24ms/step
def print_metrics(labels, predictions,target_names,save=False,save_path=None):
# 计算confusion result
preds=np.argmax(predictions,axis=-1)
confusion_result = confusion_matrix(labels, preds)
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1500)
confusion_result = pd.DataFrame(confusion_result, index = target_names, columns = target_names)
# classification report
report = classification_report(labels, preds, target_names = target_names, digits = 4)
result_report = 'Confuse_matrix:\n{}\n\nClassification_report:\n{} \n'.format(confusion_result, report)
print(result_report)
if save:
savepath = os.path.join(save_path,"predicted_result.txt")
print('the result saved in %s' % savepath)#如果savepath相同的话,会把所有结果保存到同一个文件中
with open(savepath, 'w') as f:
f.write(result_report)
print_metrics(test_y,predictions,class_names,True,log_dir)
Confuse_matrix:
T-shirt/top Trouser Pullover Dress Coat Sandal Shirt Sneaker Bag Ankle boot
T-shirt/top 956 0 15 10 3 1 5 0 10 0
Trouser 4 982 0 10 2 0 0 0 2 0
Pullover 24 2 897 8 53 0 12 0 4 0
Dress 44 6 13 903 23 0 7 0 4 0
Coat 3 1 94 29 853 0 18 0 2 0
Sandal 0 0 0 0 0 978 0 8 0 14
Shirt 325 2 122 18 101 0 420 0 12 0
Sneaker 0 0 0 0 0 17 0 928 1 54
Bag 4 1 2 2 1 1 0 2 987 0
Ankle boot 0 0 0 0 0 1 0 18 1 980
Classification_report:
precision recall f1-score support
T-shirt/top 0.7029 0.9560 0.8102 1000
Trouser 0.9879 0.9820 0.9850 1000
Pullover 0.7848 0.8970 0.8371 1000
Dress 0.9214 0.9030 0.9121 1000
Coat 0.8234 0.8530 0.8379 1000
Sandal 0.9800 0.9780 0.9790 1000
Shirt 0.9091 0.4200 0.5746 1000
Sneaker 0.9707 0.9280 0.9489 1000
Bag 0.9648 0.9870 0.9758 1000
Ankle boot 0.9351 0.9800 0.9570 1000
accuracy 0.8884 10000
macro avg 0.8980 0.8884 0.8818 10000
weighted avg 0.8980 0.8884 0.8818 10000
the result saved in ./model_output/logs_20191121-132954/predicted_result.txt
显示输出文件结构
%%bash
tree model_output
model_output
├── hdf5_models
│ ├── ckpt_epoch01_val_acc0.87.hdf5
│ ├── ckpt_epoch02_val_acc0.88.hdf5
│ ├── ckpt_epoch03_val_acc0.89.hdf5
│ ├── ckpt_epoch04_val_acc0.89.hdf5
│ └── ckpt_epoch05_val_acc0.89.hdf5
└── logs_20191121-132954
├── learning_rate.png
├── logs.log
├── model_json.json
├── model.png
├── predicted_result.txt
├── train
│ ├── events.out.tfevents.1574314212.ubuntu.7877.401.v2
│ ├── events.out.tfevents.1574314215.ubuntu.profile-empty
│ └── plugins
│ └── profile
│ └── 2019-11-21_13-30-15
│ └── local.trace
├── training.png
└── validation
└── events.out.tfevents.1574314291.ubuntu.7877.5942.v2
7 directories, 15 files
补充更新callbacks后的文件结构会多很东西:
model_output
├── hdf5_models_20191212_212719
│ ├── ckpt_epoch01_val_acc0.86.hdf5
│ ├── ckpt_epoch02_val_acc0.87.hdf5
│ ├── ckpt_epoch03_val_acc0.90.hdf5
│ ├── ckpt_epoch04_val_acc0.89.hdf5
│ ├── ckpt_epoch05_val_acc0.89.hdf5
│ └── ckpt_epoch06_val_acc0.89.hdf5
└── logs_20191212_212719
├── during_train_confusion_epoch_0.png
├── during_train_confusion_epoch_1.png
├── during_train_confusion_epoch_2.png
├── during_train_confusion_epoch_3.png
├── during_train_confusion_epoch_4.png
├── during_train_confusion_epoch_5.png
├── events.out.tfevents.1576157273.cuda10.12617.406cm
├── logs.log
├── model_json.json
├── model.png
├── predicted_result.txt
├── projector_config.pbtxt
├── train
│ ├── checkpoint
│ ├── events.out.tfevents.1576157276.cuda10.12617.416.v2
│ ├── events.out.tfevents.1576157278.cuda10.profile-empty
│ ├── keras_embedding.ckpt-0.data-00000-of-00002
│ ├── keras_embedding.ckpt-0.data-00001-of-00002
│ ├── keras_embedding.ckpt-0.index
│ ├── keras_embedding.ckpt-1.data-00000-of-00002
│ ├── keras_embedding.ckpt-1.data-00001-of-00002
│ ├── keras_embedding.ckpt-1.index
│ ├── keras_embedding.ckpt-2.data-00000-of-00002
│ ├── keras_embedding.ckpt-2.data-00001-of-00002
│ ├── keras_embedding.ckpt-2.index
│ ├── keras_embedding.ckpt-3.data-00000-of-00002
│ ├── keras_embedding.ckpt-3.data-00001-of-00002
│ ├── keras_embedding.ckpt-3.index
│ ├── keras_embedding.ckpt-4.data-00000-of-00002
│ ├── keras_embedding.ckpt-4.data-00001-of-00002
│ ├── keras_embedding.ckpt-4.index
│ ├── keras_embedding.ckpt-5.data-00000-of-00002
│ ├── keras_embedding.ckpt-5.data-00001-of-00002
│ ├── keras_embedding.ckpt-5.index
│ └── plugins
│ └── profile
│ └── 2019-12-12_21-27-58
│ └── local.trace
├── training.png
└── validation
└── events.out.tfevents.1576157286.cuda10.12617.5957.v2
7 directories, 42 files
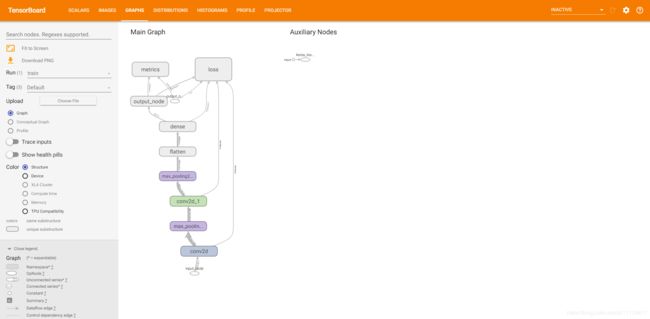
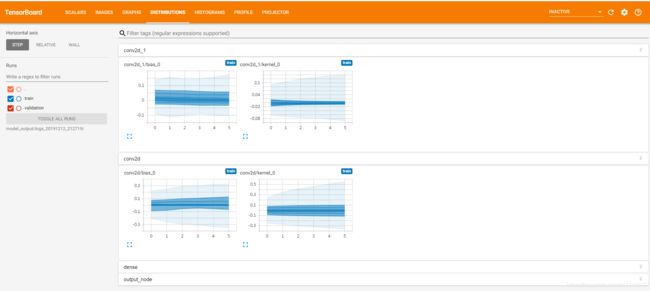
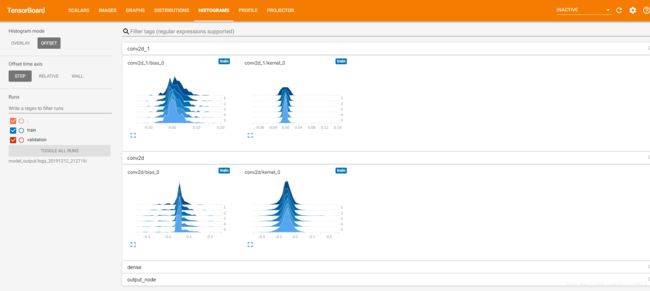
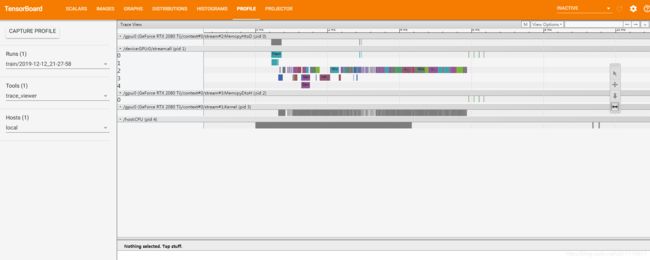
打开tensorboard可以看到:
scalars:

images:
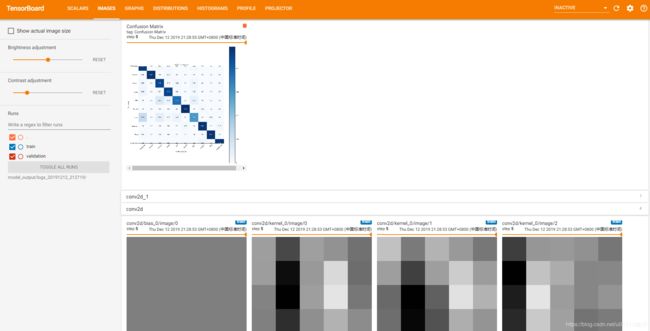
graphs:
distributions:
histograms:
profile:
projector:这个是动态的
同样,只改变保存类型为ckpt
%%bash
tree model_output
model_output
├── logs_20191121-130455
│ ├── learning_rate.png
│ ├── logs.log
│ ├── model_json.json
│ ├── model.png
│ ├── predicted_result.txt
│ ├── train
│ │ ├── events.out.tfevents.1574312711.ubuntu.7321.401.v2
│ │ ├── events.out.tfevents.1574312713.ubuntu.profile-empty
│ │ └── plugins
│ │ └── profile
│ │ └── 2019-11-21_13-05-13
│ │ └── local.trace
│ ├── training.png
│ └── validation
│ └── events.out.tfevents.1574312790.ubuntu.7321.7346.v2
├── logs_20191121-131145
│ ├── logs.log
│ ├── model.png
│ └── train
│ ├── events.out.tfevents.1574313110.ubuntu.7470.401.v2
│ ├── events.out.tfevents.1574313113.ubuntu.profile-empty
│ └── plugins
│ └── profile
│ └── 2019-11-21_13-11-53
│ └── local.trace
├── logs_20191121-131222
│ ├── learning_rate.png
│ ├── logs.log
│ ├── model_json.json
│ ├── model.png
│ ├── predicted_result.txt
│ ├── train
│ │ ├── events.out.tfevents.1574313156.ubuntu.7563.401.v2
│ │ ├── events.out.tfevents.1574313159.ubuntu.profile-empty
│ │ └── plugins
│ │ └── profile
│ │ └── 2019-11-21_13-12-39
│ │ └── local.trace
│ ├── training.png
│ └── validation
│ └── events.out.tfevents.1574313236.ubuntu.7563.7346.v2
└── saved_models
├── ckpt_epoch01_val_acc0.86.ckpt
│ ├── assets
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00002
│ ├── variables.data-00001-of-00002
│ └── variables.index
├── ckpt_epoch02_val_acc0.88.ckpt
│ ├── assets
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00002
│ ├── variables.data-00001-of-00002
│ └── variables.index
├── ckpt_epoch03_val_acc0.88.ckpt
│ ├── assets
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00002
│ ├── variables.data-00001-of-00002
│ └── variables.index
├── ckpt_epoch04_val_acc0.89.ckpt
│ ├── assets
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00002
│ ├── variables.data-00001-of-00002
│ └── variables.index
└── ckpt_epoch05_val_acc0.90.ckpt
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
33 directories, 45 files
总结:
多写一句,在tensorflow2.x中还是尽量少用原先keras风格的代码来做模型比较好,因为tensorflow2.x中的keras是将tensorflow与keras整合,所以tf.keras与原来keras的语法相同,但就我所知和个人遇到的一些情况,有些参数keras与tf.keras中完全相同(所说的语法相同),但是在tf.keras中却不起作用。比如
tf.keras.optimezers.SGD(clipnorm) clipnorm这个参数,在tensorflow2.x中仍然存在,能传参,但是在使用时却不起作用了。这个在用ensorflow1.15(最后一个tf1.x的版本中)中用tf.keras时有过warnning(2020年4月11日补充:曾发现相同参数,以tensorflow为后端的keras和tf2.x这前的tensorflow版本中的tf.keras中的功能相同,但唯独在tf2.x中不起作用,这是因为在tf2.x中是bug,随着tf2.x版本升级会得到改进)
