TensorFlow文本摘要生成 - 基于注意力的序列到序列模型
原文:https://blog.csdn.net/tensorflowshizhan/article/details/69230070
1 相关背景
维基百科对自动摘要生成的定义是, “使用计算机程序对一段文本进行处理, 生成一段长度被压缩的摘要, 并且这个摘要能保留原始文本的大部分重要信息”. 摘要生成算法主要分为抽取型(Extraction-based)和概括型(Abstraction-based)两类. 传统的摘要生成系统大部分都是抽取型的, 这类方法从给定的文章中, 抽取关键的句子或者短语, 并重新拼接成一小段摘要, 而不对原本的内容做创造性的修改. 这类抽取型算法工程上已经有很多开源的解决办法了, 例如Github上的项目sumy, pytextrank, textteaser等. 本文重点讲概括型摘要生成系统的算法思想和tensorflow实战, 算法思想源于A Neural Attention Model for Abstractive Sentence Summarization这篇论文. 本文希望帮助读者详细的解析算法的原理, 再结合github上相关的开源项目textsum讲解工程上的实际应用.本文由PPmoney大数据算法团队撰写,PPmoney是国内领先的互联网金融公司,旗下PPmoney理财总交易额超过700亿元。此外,若对TensorFlow的使用技巧和方法感兴趣,欢迎阅读本团队负责人黄文坚所著的《TensorFlow实战》。
2 算法原理
下面对A Neural Attention Model for Abstractive Sentence Summarization这篇文章, 的算法原理进行讲解. 我们将这个模型简称为NAM. 主要分为模型训练(train)和生成摘要(decode)两部分讲解.
2.1 模型训练(train)
NAM这个模型是纯数据驱动, 我们喂给它的训练集数据是由一系列{正文: 摘要}对组成. 假设正文是x=[x1,...,xM]: 模型要预测的下一个单词
下面我们举一个例子来说明训练的过程:

我们希望根据, 当前局部摘要序列yc的不同内容投入不同的关注度, 进而的到更好的结果. 模型结构如下图所示:
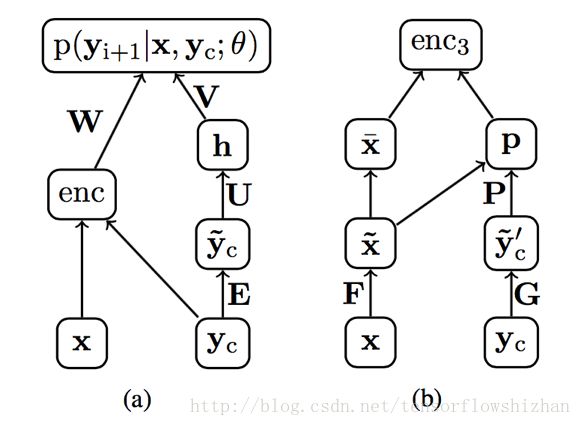
模型整体的网络结构图(具有一个额外的编码器单元):
右侧分支: 仅根据当前的序列yc再做加权, 得到encoder的输出.
下面两幅图分别是对整体结构和编码器结构的展开:

感兴趣的同学可以结合原文中的公式理解:
上图(a)中对应的公式:
我们通过使用mini-batch和随机梯度下降最小化NLL.
2.2 Beam Search生成摘要(decode)
我们现在回到生成摘要的问题. 回顾前面, 我们的目标是找到:
Beam search案例
下面举一个简单的例子来说明beam search算法的运行过程. 在这个例子里, 摘要长度N=4个词符.

Step2: 预测第2个词的时候, 我们选出新的K个词符, 对应K条备选路径. 前一阶段概率低的路径和词符, 被抛弃掉.

Step3: 重复前面的过程.
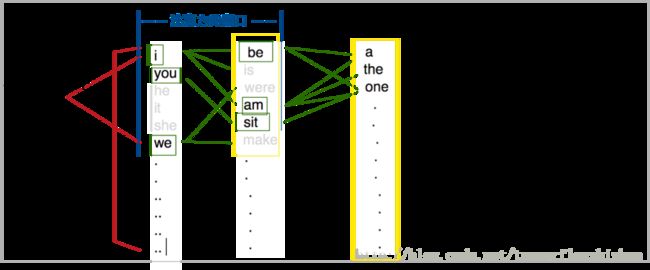
Step4: 每次beam search不一定能选出不同的K个词, 但是每次beam search都找到最优的前K个路径, 路径可以有重叠.
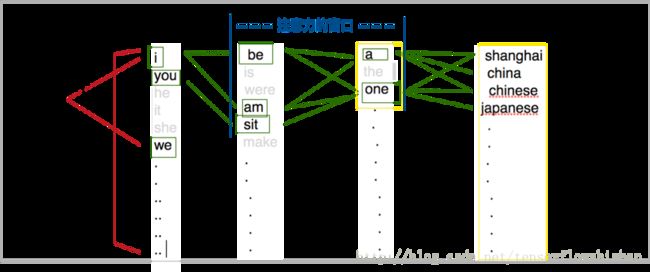
Step5: 迭代N次, 最终选出可能性最大的一条词序列路径
下面是对Beam Search算法的详细分析, 对原文的Algorithm 1逐条进行解释.
Beam Search算法分析
- π[0].
Beam Search的运算复杂度从O(NVC)个最优值都保留着相应路径上之前的所有的节点.
3 TensorFlow程序实战
NAM模型的程序最早是由facebook开源的torch版本的程序. 最近谷歌开源了TensorFlow版本的摘要生成程序textsum, Github上的项目. textsum的核心模型就是基于注意力的seq2seq(sequence-to-sequence)模型, textsum使用了LSTM和深度双向RNN.
Github上的textsum首页给出了此项目在Bazel环境下的运行方式. 如果你不想通过Bazel运行, 你可以直接在seq2seq_attention.py中设定运行参数. 设定完参数后, 直接运行python seq2seq_attention.py即可. 参数设定如下图所示:

除了上述项目运行时所需的必要参数, 模型参数也在seq2seq_attention.py中设定, 如下图所示, 包括学习率, 最小学习率(学习率会衰减但不会低于最小学习率), batch size, train模式encoder的RNN层数, 输入正文词汇数上限, 输出摘要词汇数上限, 最小长度限制, 隐层节点数, word embedding维度, 梯度截取比例, 每一个batch随机分类采样的数量.

git项目textsum给的toy数据集太小, vocab也几乎不可用(一些常见的单词都没有覆盖到). 如果希望获得好的效果, 需要自己整理可用的数据集.
主要文件说明:
- seq2seq_attention.py: 主程序, 选择程序的运行模式, 设定参数, 建立模型, 启动tensorflow
- seq2seq_attention_model.py: 建立attention-based seq2seq model, 包括算法的encoder, decoder和attention模块, 都在Seq2SeqAttentionModel中完成.
- seq2seq_attention_decode.py: 读取数据, 调用beam_search解码
beam_search.py: beam search算法的核心程序
textsum程序解析
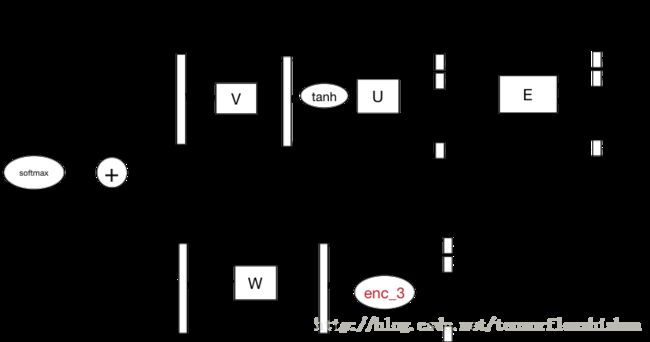
Google开源的textsum项目的具体算法是基于Hinton 2014年的Grammar as a Foreign Language这篇论文, 下面给出textsum工程中attention-based seq2seq模型的整体结构图, 图中所使用的名字与程序中的变量名一致, Seq2SeqAttentionModel是一个类, 定义在seq2seq_attention_model.py中; attention_decoder是一个函数, 定义在/tensorflow/contrib/legacy_seq2seq/python/ops/seq2seq.py中.
为了方便理解, 简单解释一下图中出现的符号,

第一个符号表示从x1,x2到y的线性变换, 红色变量是训练过程要学习出来的.

attention机制比较复杂也比较重要, 我们对这部分细化一下来看. attention decoder结构图如下: