Suricata高性能配置
一.Suricata对包的规则检测
1.为了高性能,将规则按照一定算法分很多组(例如如果出现带有UDP协议的数据包,则不需要TCP协议的所有签名)
2.更多的分组有用更高的性能,但占用更多的内存,默认配置选项
detect:
profile: medium
custom-values:
toclient-groups: 2
toserver-groups: 25
sgh-mpm-context: auto
inspection-recursion-limit: 3000
profile:可选high,medium,low,custom,high表示系统高性能配置分组,但会占用更高内存(在实际中,及时配置了high也不会占用多少内存);在使用custom的时候,custom-values中的配置才会生效,最大值为65000;
sgh-mpm-context:表示是否MPM共享一个上下文,跟具体的匹配算法有关,有些规则分组需要可以使用共享上下文,有些需要独立上下文ac和ac-gfbs,auto会自动选择这些,默认就好
Inspection-recursion-limit有时候匹配会发生错误进入死循环,这里可以配置重复操作的次数,默认就好。
以下就是对包进行检测的分组树样例:
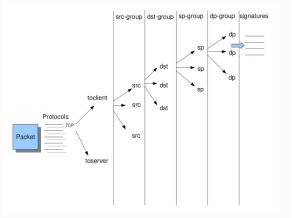

所以如果想要高性能就这样配置:
detect:
profile: custom
custom-values:
toclient-groups: 65000
toserver-groups: 65000
sgh-mpm-context: auto
inspection-recursion-limit: 3000
3.选择使用的分组匹配算法
mpm-algo: auto(默认就是ac)
spm-algo: auto(默认就是ac)
可以安装性能更好的Hyperscan,属于高性能的正则匹配表达库,suricata推荐使用。
安装步骤如下:
https://blog.csdn.net/u011311291/article/details/104388783
然后更改配置文件:
mpm-algo: hs
spm-algo: hs
二.Suricata运行模式和线程
默认配置为:
runmode: autofp
可选为single,workers,autofp
高性能官方推荐使用worker模式:
runmode: worker
1.默认runmode: autofp启动
这边使用了pfring,启动命令,捕抓2个网口的流量:
/usr/local/bin/suricata --pfring-int=em1 --pfring-int=em2 --pfring-cluster-id=99 --pfring-cluster-type=cluster_flow -c /usr/local/etc/suricata/suricata.yaml -D
每一个网口会有单个线程进行捕抓,suricata.yaml中的pfring抓包配置失效。效果如下图的左侧,可以使用top -H -p pid可以查看进程的线程情况

2.默认runmode: autofp读取pcap数据包分析
/usr/local/bin/suricata -r /xxx/xx.pcap
Suricata会启动和CPU相等的个数线程进行解析处理,如上图的右侧
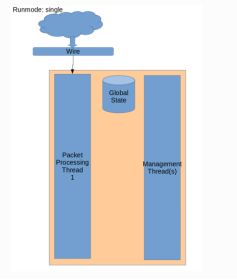
3.runmode: single
Single模式就是worker模式的单线程,一般用于开发。
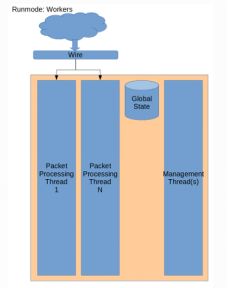
4.runmode: worker
Suricata推荐使用worker模式,更具高性能.
5.runmode模式autofp和worker模式的不同
Autofp模式线程分为3大块
(1)pcaket capture thread
(2)pcaket process thread
(3)management thread
Suricata中可以为每个模块进行CPU的配置设置,默认
set-cpu-affinity: no
cpu-affinity:
- management-cpu-set:
cpu: [ 0 ] # include only these cpus in affinity settings
- receive-cpu-set:
cpu: [ 0 ] # include only these cpus in affinity settings
- worker-cpu-set:
cpu: [ "all" ]
mode: "exclusive"
# Use explicitely 3 threads and don't compute number by using
# detect-thread-ratio variable:
# threads: 3
prio:
low: [ 0 ]
medium: [ "1-2" ]
high: [ 3 ]
default: "medium"
- verdict-cpu-set:
cpu: [ 0 ]
prio:
default: "high"
其中:
management-cpu-set - used for management (example - flow.managers, flow.recyclers)
对应management thread模块,这块占CPU很少,基本上1个CPU就够了
receive-cpu-set - used for receive and decodeworker-cpu-set - used for
对应的pcaket capture thread模块,这块占用资源适中,从实际部署看,一般2-4个CPU就够
worker-cpu-set -streamtcp,detect,output(logging),reject
对应的是pcaket process thread模块,这块占用资源最大,可从默认配置中看到CPU分配ALL
为了提高性能,可以将set-cpu-affinity设置为yes,这意味着每个线程都会绑定到指定的CPU运行。除了这个功能外,还可以通过top命令查看每一块CPU运行的状况,你会发现在高峰时期,经常处于100%的那一块CPU绑定的线程,发生丢包的数量会比别的线程大很多。
Worker模式线程分为2大块
(1)pcaket process thread
(2)management thread
基本意思就是pcaket capture合并到pcaket process合并里面了。可配的情况变成了:
management-cpu-set - used for management (example - flow.managers, flow.recyclers)
worker-cpu-set - used for receive,streamtcp,decode,detect,output(logging),respond/reject
为啥合并,我猜测是当服务器拥有足够的性能,把处理逻辑都集中在同一条线程可以减少数据包的分发,能更紧凑利用CPU处理数据包。
所以高性能配置如下
threading:
set-cpu-affinity: yes
cpu-affinity:
- management-cpu-set:
cpu: [ 0 ] # include only these CPUs in affinity settings
#threads: 1
- worker-cpu-set:
cpu: [ "1-30" ]
mode: "exclusive"
threads: 30
prio:
#low: [ 0 ]
#medium: [ "1-2" ]
high: [ "1-30" ]
default: "high"
注意:如果你的采集服务器还部署了其它组件,注意CPU要合理绑定,尽量不要出现CPU和其它消耗高资源的进程使用同一个CPU
三.max-pending-packets配置
表示每一条线程可以同时处理的数据包的个数,0-65000建议是10000或者更高,但是如果配置过高也可能会出现性能下降问题
四.IP分片重组
超过MTU的包会进行分段,在网卡处进行重组。假设网络环境中存在数据包分片,那么Suricata会对这些分片进行重组。相关的配置如下:
defrag:
memcap: 20gb #可以使用的内存
hash-size: 65536
trackers: 65535 # 对一个流跟踪的分片数量number of defragmented flows to follow
max-frags: 65535 # number of fragments to keep (higher than trackers)
prealloc: yes #当出现一个分片流,是否先开辟内存
timeout: 60
注意:其实网络中IP分片比较少,但是也根据情况而定,20gb只是一个最大值的设定,并不会直接占用
五.suricata的flow
Suricata对流的定义是5元祖(协议,源IP,目标IP,源端口,目标端口),关于flow的配置由:
flow:
memcap: 1gb #管理flow列表可以使用的内存,就一个表
hash-size: 250000 #流表
prealloc: 150000 #初始化的时候预设置的流表
emergency-recovery: 30 #这里是流过多设置的的一些紧急处理机制,恢复到30%
managers: 5 # default to one flow manager
recyclers: 5 # default to one flow recycler thread
建议在大流量下将memcap,hash-size,prealloc进行调整,如上
六.stream引擎
Stream引擎用于跟踪TCP连接,主要用于跟踪流和重组。
和flow的区别在于flow只是用于区别流,Stream更注重于整个流的数据包重组。
stream:
memcap: 2gb #stream列表可用的内存大小,和flow一样,可以设置较小
checksum-validation: yes # reject wrong csums
inline: no # auto will use inline mode in IPS mode, yes or no set it statically
prealloc-sessions: 100000
bypass: yes #如果超出了depth,后续的数据包可以直接滤过
reassembly:
memcap: 20gb #重组可以设置的内存大小
depth: 128kb # 最多还原steam大小,reassemble 1mb into a stream,初始值是1Mb
toserver-chunk-size: 2560
toclient-chunk-size: 2560
randomize-chunk-size: yes
#randomize-chunk-range: 10
#raw: yes
#segment-prealloc: 2048
#check-overlap-different-data: true
主要修改的配置为memcap,prealloc-sessions,bypass,reassembly.memcap,depth
七.应用层解析配置
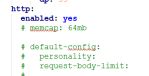
比较关注的是http,可观察suricata输出的state.json观察其占用,设置合理的值
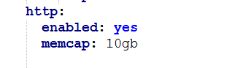
八.高性能下suricata启动的配置
(1)原始的开启方式,无法启用suricata.yaml中的pfring配置:
/usr/local/bin/suricata --pfring-int=em1 --pfring-cluster-id=99 --pfring-cluster-type=cluster_flow -c /usr/local/etc/suricata/suricata.yaml -D
(2)高性能配置,采用配置文件来设置抓包
例如:
pfring:
- interface: em1
threads: 1
cluster-id: 99
cluster-type: cluster_flow
#bypass: yes #这里可以配置如果stream的重组达到depth,由pfring来丢弃后续的包,但是这个配置要高版本的pfring才能启动
- interface: em2
threads: 1
cluster-id: 98
cluster-type: cluster_flow
- interface: em3
threads: 30
cluster-id: 97
注意:启用的线程数和CPU的配置要协调,尽量多少线程就占多少CPU
/usr/local/bin/suricata --pfring -c /usr/local/etc/suricata/suricata_test.yaml -D
九.Dns,flow信息异常原因
可能suricata输出的dns.json和flow.json统计异常
网卡中存在带有Vlan标签的数据包,可能会导致flow的跟踪出现问题,需要如下配置才能正确跟踪流,关闭使用vlanid来匹配流
vlan:
use-for-tracking: false