Redis缓存失效、雪崩、穿透、击穿、并发等案例分析难题解决方案
目录
- 如何解决Redis缓存失效、雪崩、穿透、击穿、并发等5大难题???
- 缓存失效
- 出现场景:
- 处理方法:
- 缓存雪崩
- 出现场景:
- 处理方法:
- 缓存穿透
- 出现场景:
- 处理方法:
- 缓存击穿
- 出现场景:
- 处理方法:
- 缓存并发
- 出现场景:
- 处理方法:
- 热点key
- 出现场景:
- 处理方法:
- 如何保证redis中的数据都是热点数据
- redis 提供 6种数据淘汰策略:
- Redis到底是单线程还是多线程
- Redis案例分析一 分布式锁
- Redis案例分析二 秒杀业务超卖现象
- Redis案例分析三 redis分布式主从互备的高可用方案
redis是单进程单线程应用,命令执行是one by one的,所以本身并不存在并发问题。但是实际使用中多个连接中操作时间差会带来get和set的并发脏读问题。另外当redis进行分布式部署的时候,会涉及到数据一致性的问题。实际上,Redis setnx命令可以解决上述所说的并发和一致性问题。执行成功返回1,失败返回0
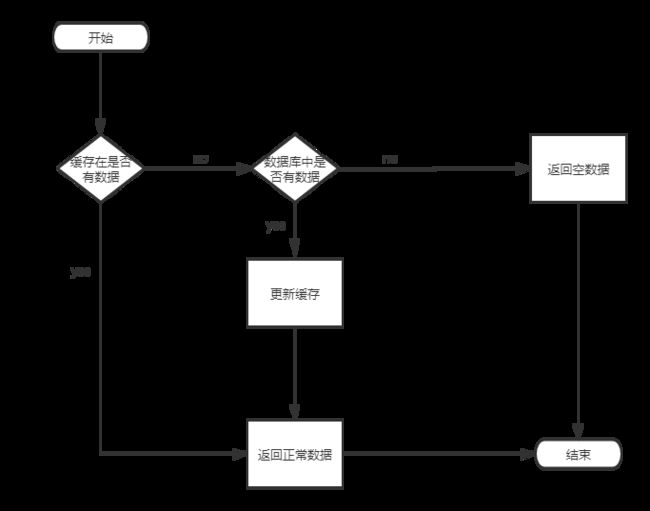
如何解决Redis缓存失效、雪崩、穿透、击穿、并发等5大难题???
缓存失效
出现场景:
主要因素是高并发下,我们一般设定一个缓存的过期时间时。并发很高时可能会出现在某一个时间同时生成了很多的缓存,并且过期时间在同一时刻,这个时候就可能引发——当过期时间到后,这些缓存同时失效,请求全部转发到DB,DB可能会压力过重。
处理方法:
一个简单方案就是将缓存失效时间分散开,不要所有缓存时间长度都设置成5分钟或者10分钟;比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存失效时产生的雪崩效应,将所有请求全部放在数据库上,这样很容易就达到数据库的瓶颈,导致服务无法正常提供。尽量避免这种场景的发生。
缓存雪崩
出现场景:
大量的key设置了相同的过期时间,导致缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
处理方法:
可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效。
缓存穿透
出现场景:
指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。当在流量较大时,出现这样的情况,一直请求DB,很容易导致服务挂掉。
处理方法:
方法1.在封装的缓存SET和GET部分增加个步骤,如果查询一个KEY不存在,就以这个KEY为前缀设定一个标识KEY;以后再查询该KEY的时候,先查询标识KEY,如果标识KEY存在,就返回一个协定好的非false或者NULL值,然后APP做相应的处理,这样缓存层就不会被穿透。当然这个验证KEY的失效时间不能太长。
方法2.如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,一般只有几分钟。
方法3.采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
方法4.接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
缓存击穿
出现场景:
一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。
处理方法:
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。
缓存并发
出现场景:
当网站并发访问高,一个缓存如果失效,可能出现多个进程同时查询DB,同时设置缓存的情况,如果并发确实很大,这也可能造成DB压力过大,还有缓存频繁更新的问题。
处理方法:
对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询。
热点key
出现场景:
缓存中的某些Key(可能对应用与某个促销商品)对应的value存储在集群中一台机器,使得所有流量涌向同一机器,成为系统的瓶颈,该问题的挑战在于它无法通过增加机器容量来解决。
处理方法:
客户端热点key缓存:将热点key对应value并缓存在客户端本地,并且设置一个失效时间。对于每次读请求,将首先检查key是否存在于本地缓存中,如果存在则直接返回,如果不存在再去访问分布式缓存的机器。
将热点key分散为多个子key,然后存储到缓存集群的不同机器上,这些子key对应的value都和热点key是一样的。当通过热点key去查询数据时,通过某种hash算法随机选择一个子key,然后再去访问缓存机器,将热点分散到了多个子key上。
如何保证redis中的数据都是热点数据
mySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据???
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。
redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
Redis到底是单线程还是多线程
redis中IO多路复用器模块是单线程执行,事件处理器也是单线程执行,两个线程不一样。依靠队列保证顺序。这样的好处是io多路复用线程接受和响应 和事件处理之间不会来回切换上下文进行处理。
单线程只是针对redis中的模块来说 比如 接受请求和响应是单线程,处理事件也是单线程 。但是线程不是同一个。
Redis案例分析一 分布式锁
1 并发穿透需要重新设置缓存
项目把查询结果存储到 Redis 当中时的伪代码如下:
$redis = new \Redis('127.0.0.1', 6379);
$cacheKey = 'query_cache';
$result = $redis->get($cacheKey);
if ($result) { // 缓存有效则直接返回。
return $result;
} else { // 缓存失效则重新获取并存储到 Redis。
$mysqlResult = [];
$redis->set($cacheKey, json_encode($mysqlResult), 3600);
return $mysqlResult;
}
上述代码初看并不会发现问题所在。通常情况下,当服务器资源压力非常小的时候,这段代码不会有任何问题。并且,真的可以提升服务器吞吐性能。
但是,假如这个位置的代码出现了单点压力呢?比如,这个功能是统计结果,查询数据库需要花 5s。而且,由于该功能比较常用,单位时间内达到了 1000 次/秒。这时就会出现并发穿透问题。
1000 个请求同时到达这个程序位置,都去读取缓存是否存在。假如此时缓存不存在。这 1000 个请求都会得到不存在的结果。并且都会执行到去数据库取缓存结果的步骤。同时也会把结果重写到 Redis。那就导致了这一瞬间单点压力导致穿透到数据库,造成数据库压力瞬间到达峰值。如果我们的数据库的性能处理不了这么大的压力,就会导致数据库服务器 CPU 直接爆满。响应给前端的数据就会陷入停顿状态。
通常我们一般都是通过简单的加锁或同步来实现并解决这个问题。
2 使用setnx() 设置分布式锁
在第一点中,我们发现了问题。我们试着去优化它,于是就有了下面的代码:
$redis = new \Redis('127.0.0.1', 6379);
$lockKey = 'query_cache_lock'; // 锁专用的 KEY。
$cacheKey = 'query_cache'; // 存储查询结果的 KEY。
$result = $redis->get($cacheKey);
if ($result) { // 缓存有效则直接返回。
return $result;
} else { // 缓存失效则重新获取并存储到 Redis。
if ($redis->setNx($lockKey) === false) {
throw new \Exception("服务器火爆,请稍候重试");
} else {
$mysqlResult = [];
$redis->set($cacheKey, json_encode($mysqlResult), 3600);
$redis->delete($lockKey); // 锁用完了要解锁。删掉就是解锁。
return $mysqlResult;
}
}
这段代码就完全避免了第一点中的并发穿透的问题。但是,相对第一点,代码也多增加了几行。不过性能依然强劲。即使如此,这段代码依然存在三个问题:
1)并发越大,第一个取到锁的请求能正常响应,后续的请求就会得到一个“服务器火爆,请稍候重试”的异常提示。这个是用户体验极差的。
2)如果代码执行到 r e d i s − > d e l e t e ( redis->delete( redis−>delete(lockKey) 之前程序异常了。那么锁就不能正常释放。后续的锁也无法正常取到锁了。
3 解决上述死锁的问题
针对上面的正常的分布式锁要满足以下几点要求:
1)能解决并发时资源争抢。这是最核心的需求。
2)锁能实现等待,否则不能最大保证用户的体验。
3)锁能正常添加与释放。不能出现死锁。
/**
* 实现Redis分布锁
*/
$key = 'test'; //要更新信息的缓存KEY
$lockKey = 'lock:'.$key; //设置锁KEY
$lockExpire = 10; //设置锁的有效期为10秒
//获取缓存信息
$result = $redis->get($key);
//判断缓存中是否有数据
if(empty($result))
{
$status = TRUE;
while ($status)
{
//设置锁值为当前时间戳 + 有效期
$lockValue = time() + $lockExpire;
/**
* 创建锁
* 试图以$lockKey为key创建一个缓存,value值为当前时间戳
* 由于setnx()函数只有在不存在当前key的缓存时才会创建成功
* 所以,用此函数就可以判断当前执行的操作是否已经有其他进程在执行了
* @var [type]
*/
$lock = $redis->setnx($lockKey, $lockValue);
/**
* 满足两个条件中的一个即可进行操作
* 1、上面一步创建锁成功;
* 2、 1)判断锁的值(时间戳)是否小于当前时间 $redis->get()
* 2)同时给锁设置新值成功 $redis->getset()
*/
if(!empty($lock) || ($redis->get($lockKey) < time() && $redis->getSet($lockKey, $lockValue) < time() ))
{
//给锁设置生存时间
$redis->expire($lockKey, $lockExpire);
//******************************
//此处执行插入、更新缓存操作...
//******************************
//以上程序走完删除锁
//检测锁是否过期,过期锁没必要删除
if($redis->ttl($lockKey))
$redis->del($lockKey);
$status = FALSE;
}else{
/**
* 如果存在有效锁这里做相应处理
* 等待当前操作完成再执行此次请求
* 直接返回
*/
sleep(2);//等待2秒后再尝试执行操作
}
}
}
Redis案例分析二 秒杀业务超卖现象
1 list列表功能应用实现消息队列 先到先得,sorted set 可以用于实现延迟队列
2 sexnx分布式锁应用
Redis案例分析三 redis分布式主从互备的高可用方案
哨兵监控集群节点状态,如果发现master宕机,从slave中选举出一台作为新master。