Hadoop 之Mapreduce wordcount词频统计案例
首先我们来看一张描述MapReduce运行过程的图。
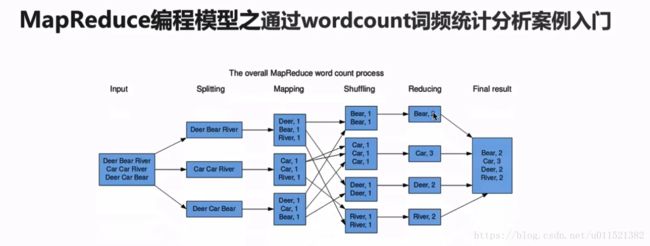
首先input就是输入文件。
spliting:把文件按行经行拆分。
Mapping:把每行的word进行计数。
Shuffing:混洗。将相同的word分发到相同的节点。
Reduceing:对每个节点的word进行统计。
以上就是简单的Mapreduce作业过程。下面看下官网的介绍:
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
一个MapReduce作业通常会把输入的文件分割成独立的块。这些块由map任务以并行的方式进行处理。然后mapreuce框架对map的处理结果进行排序,拍完序的结果作为reduce阶段的输入。通常输入和输出结果都是在一个文件系统进行排序的,框架负责任务的监控,调度,以及失败后的重执行。
Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
通常计算的节点和存储的节点是同一个,这也就是说,Map Reduce框架和HDFS文件系统是跑在同一系列节点上的,这样的配置可以是框架能够有效地调度已存节点上的任务,也能够使集群的带宽利用率非常高。
The MapReduce framework operates exclusively on 【key, value】 pairs, that is, the framework views the input to the job as a set of 【key, value 】pairs and produces a set of 【key, value】 pairs as the output of the job, conceivably of different types.
MapReduce框架只操作【key,value】键值对。即,框架把输入的作业作为一系列的【key,value】键值对,并且将一系列的【key,value】键值对作为作业的输出结果。
(发现csdn 编辑的一个bug,就是出现尖括号会导致后面的内容不显示,只能用中括号代替了。。。)
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)以上描述可以通过下图理解下:
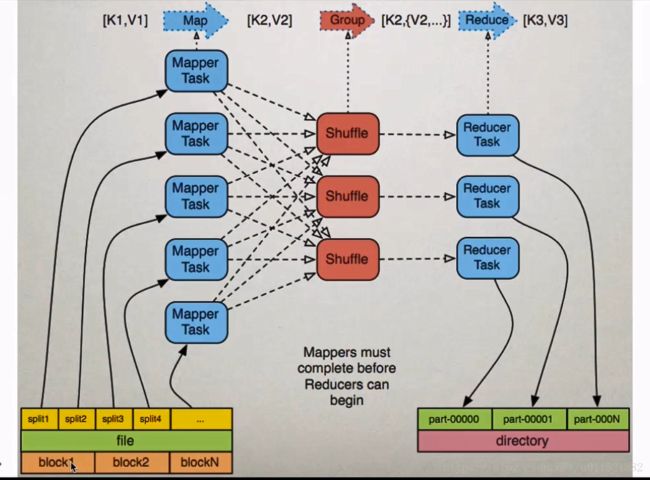
我们再看一张图来理解下,mapreuce的过程。
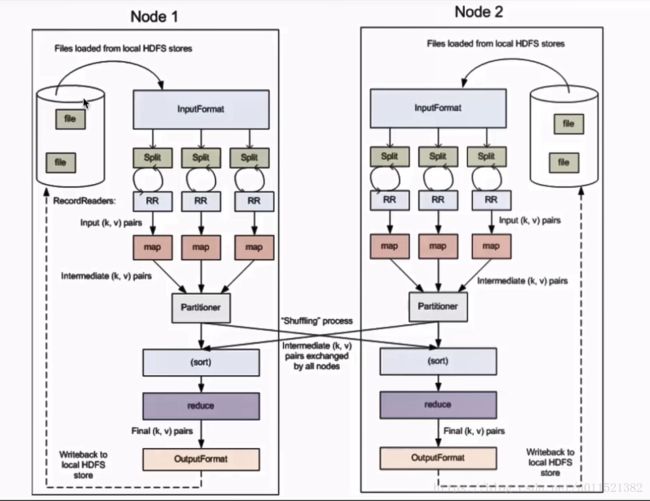
Split:交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元
HDFS:blocksize 是HDFS中最小的存储单元 128M
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议)
InputFormat: 将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
TextInputFormat: 处理文本格式的数据。
下面看下具体实现:
package com.yoyocheknow.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 类说明
*
* @author yoyocheknow
* @date 2018/8/3 15:19
*/
public class WordCountApp {
/**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
LongWritable one=new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//接受到的每一行数据
String line =value.toString();
//按照指定的分隔符进行拆分
String[] words = line.split(" ");
for(String word:words)
{
//通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
}
}
/**
* Reduce:归并操作
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long sum=0;
for(LongWritable value:values){
//求key出现的次数总和
sum+=value.get();
}
//最终统计结果的输出
context.write(key,new LongWritable(sum));
}
}
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args)throws Exception {
//创建Configuration
Configuration configuration=new Configuration();
//创建job
Job job =Job.getInstance(configuration,"wordcount");
//创建job的处理类
job.setJarByClass(WordCountApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
然后执行打包命令:
mvn clean package -DskipTests上传到服务器:scp target/hadoop-train-1.0.jar root@hadoopMaster:~/data
运行:
hadoop jar /data/hadoop-train-1.0.jar com.yoyocheknow.hadoop.mapreduce.WordCountApp /hello.txt /output/wc以上是Mapreduce wordcount词频统计案例。后续再贴一下运行结果图。