AutoML
AutoML
AutoML 的理解
首先,聊聊传统的机器学习的过程;一般情况下,在确定目标的情况下,我们会对数据先一步进行EDA,对数据进行一步预处理。然后建立基本的模型,在此模型上,不断地调整优化参数,得到更优秀的模型。在此之间,有着许多人为的选择工作。AutoML的提出是希望能够自动化解决一切人为的工作,从而让机器学习的门槛更低,让更多人有机会去使用机器学习。
本人认为,神经网络地不断迭代优化正是部分解决了人为选择特征工程及调参的工作。如果让一个模型地架构能够自动化解决问题,寻找最优的方案。这是AutoML的要做的。
Pichai 在一篇博文中写道:“我们希望 AutoML 的能力能抵上现在几个博士之和,并且可以在三到五年的时间内为成千上万的开发人员设计出新的神经网络以满足他们的特殊需求。”
开源的一些 AutoML 的 架构 介绍
1. tpot (https://github.com/rhiever/tpot)
TPOP 主要也是建立在sklearn_learnning 之上,在N多原型中将会选择最优的管道;
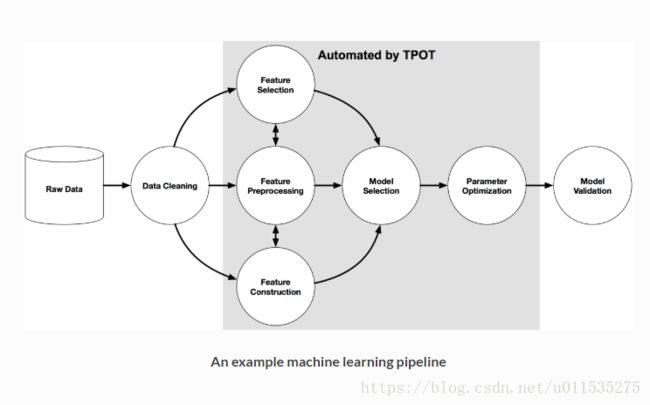
在选择通道后,通过不断优化输出模型算法;
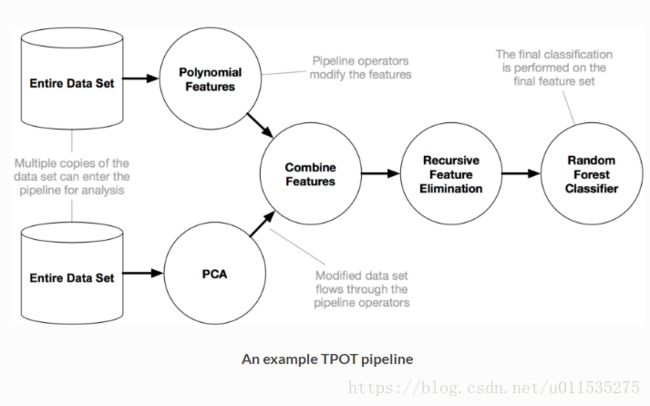
而在这边的衍生特征主要为多项式特征和PCA降维的特征;使用GP算法反复迭代,选取交叉熵最小的组合
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
pipeline_optimizer = TPOTClassifier(generations=5, population_size=20, cv=5,
random_state=42, verbosity=2)
pipeline_optimizer.fit(X_train, y_train)
print(pipeline_optimizer.score(X_test, y_test))
pipeline_optimizer.export('tpot_exported_pipeline.py')
2.auto_ml (https://github.com/ClimbsRocks/auto_ml)(machineJS (https://github.com/ClimbsRocks/machineJS)
Auto_ml 主要集成了
- DeepLearningClassifier and DeepLearningRegressor
- XGBClassifier and XGBRegressor
- LGBMClassifier and LGBMRegressor
- CatBoostClassifier and CatBoostRegressor
他能够快速地得到结果,能够详细地得到一些特征的权重。但是他对特征进行了编码,不能自动筛选相关性较高的模型,会导致模型容易过拟合。
from auto_ml import Predictor
from auto_ml.utils import get_boston_dataset
df_train, df_test = get_boston_dataset()
column_descriptions = {
'MEDV': 'output'
, 'CHAS': 'categorical'
}
ml_predictor = Predictor(type_of_estimator='regressor', column_descriptions=column_descriptions)
ml_predictor.train(df_train)
ml_predictor.score(df_test, df_test.MEDV)
3.auto_sklearn (https://github.com/automl/auto-sklearn)
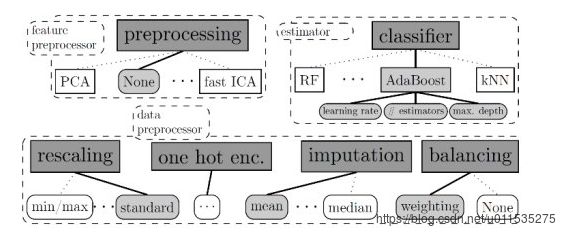
auto_sklearn 是 sklearn 的替代品,auto_sklearn 将机器学习用户从算法选择和超参数调优中解放出来。它利用了贝叶斯优化、元学习和整体结构
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
X, y = sklearn.datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = \
sklearn.model_selection.train_test_split(X, y, random_state=1)
automl = autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train, y_train)
y_hat = automl.predict(X_test)
print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))
我觉得习惯了sklearn 的同学更加喜欢用autosklearn
4.ATM (https://github.com/HDI-Project/ATM)
ATM 目前还并不是非常的完善,他只能处理分类问题。
各个框架对于最终效果的评测并未尝试。有待机会后面尝试对比下。
而AUTOML 也将会越来越完善。