初识---MyCat
项目中的一些技术的学习总结笔记,MyCat:MyCat是代替昂贵的oracle的MySQL集群中间件,某种角度上讲是在替换MySQL使用或者说是作为一个中间代理。对此自我感觉需要有一定了解。笔记MyCat在分布式以及数据库的分库分表、读写分离方面有着不可替代的地位。处于学习的目的可能也只能止步于知道MyCat是什么和MyCat的简单使用。毕竟现在还接触不到这种架构----太菜
进入正文,介绍一下MyCat,和MyCat的简单配置使用!
什么是MyCat

《MyCat》是代替昂贵的oracle的MySQL集群中间件。-----百度百科(这也说的太简单了,我这可能是个假百度)我去别地找了人家的:
- 一个彻底开源的,面向企业应用开发的“大数据库集群”
- 支持事务、ACID、可以替代Mysql的加强版数据库
- 一个可以视为“Mysql”集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、Nosql技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个数据库中间件产品
MyCAT的目标是:低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。从这一点介绍上来看,能满足数据库数据大量存储,提高了查询性能。MyCat在大数据方面的运用不容小觑啊。
MyCAT特性
- 支持 SQL 92标准
- 支持Mysql集群,可以作为Proxy使用
- 支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用
- 支持galera for mysql集群,percona-cluster或者mariadb cluster,提供高可用性数据分片集群
- 自动故障切换,高可用性
- 支持读写分离,支持Mysql双主多从,以及一主多从的模式
- 支持全局表,数据自动分片到多个节点,用于高效表关联查询
- 支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询
- 多平台支持,部署和实施简单

MyCAT的架构
用户可以把MyCAT看作是一个数据库代理,用mysql客户端工具(如Navicat)和命令访问,其核心功能就是分库分表,即将一个大表水平分割为N个小表,真正的存储在后端Mysql服务器中或其它数据库中。
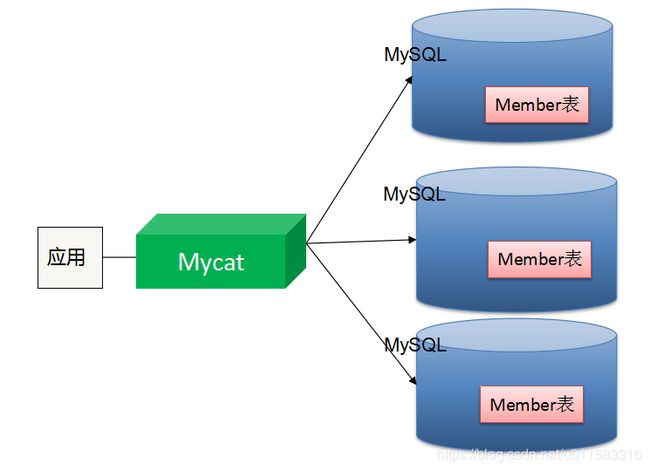
MyCat的原理:简单来说就是拦截用户发来的SQL语句,对SQL语句做了一些特定的分析,如分片分析,路由分析,读写分离分析,缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当处理,最终返回给用户。
Mycat的应用场景
- 性能问题
- 数据库连接过多
- E-R分片难处理
- 可用性问题
- 成本和伸缩性问题
前面说到了MyCat主要解决的是数据库的分库分表,以及对数据的读写分离。来达到提高数据存储量,以及提升数据查询效率等。下面就从分库分表和读写分离来具体谈谈它的方案。
分片原理
数据库分片指:通过某种特定的条件,将我们存放在一个数据库中的数据分散存放在不同的多个数据库(主机)中,这样来达到分散单台设备的负载,根据切片规则,可分为以下两种切片模式:
- 水平分片:将不同的表切分到不同的数据库中。
- 垂直分片:一个数据库中多个表格A,B,C,A存储到节点1上,B存储到节点2上,C存储到节点3上。
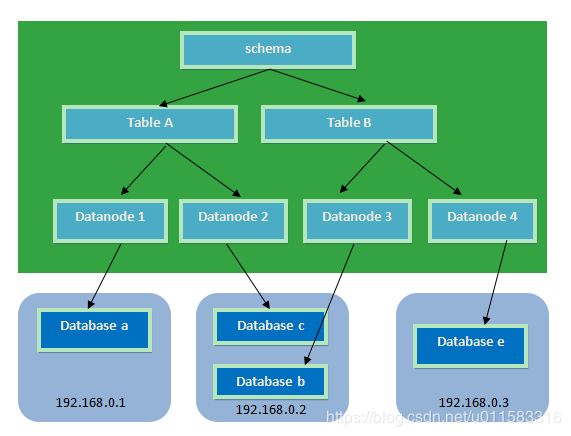
MyCAT通过定义表的分片规则则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法。
- Schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
- Table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode。在此可以指定表的分片规则。
- DataNode:MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上
- DataSource:定义某个物理库的访问地址,用于捆绑到Datanode。
读写分离
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个读节点的配置.。
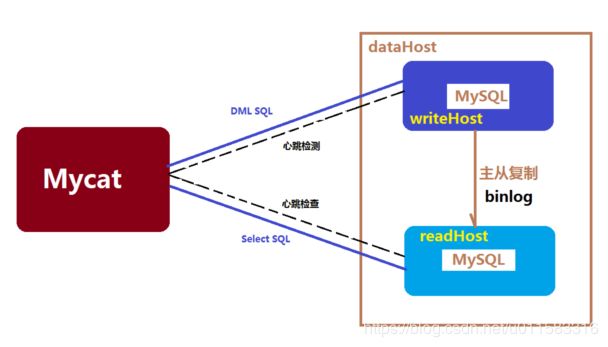
Mycat读写分离和自动切换机制,需要mysql的主从复制机制配合。也就是后面需要配置一些东西,开启MySql的主从复制机制(binlog)。
主从配置需要注意:
1、主DB server和从DB server数据库的版本一致
3、主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一
MyCat的安装配置
先说核心配置
- schema.xml用于配置文件逻辑库表及数据节点

- rule.xml用于配置表的分片规则

- server.xml用于配置服务器权限

在说分库分表
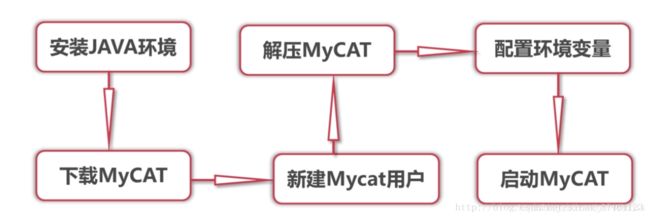
上图是大致步骤,当然在此之前需要对MySql的配置进行修改,启用二进制日志开启主从复制机制。
1).MySQL主服务器配置
- 修改my.conf文件:
在[mysqld]段下添加:
binlog-do-db=db1
binlog-ignore-db=mysql
#启用二进制日志
log-bin=mysql-bin
#服务器唯一ID,一般取IP最后一段
server-id=134
- 重启mysql服务
service mysqld restart
- 建立帐户并授权slave
mysql>GRANT FILE ON *.* TO 'backup'@'%' IDENTIFIED BY '123456';
mysql>GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'backup'@'%' identified by '123456';
一般不用root帐号,“%”表示所有客户端都可能连,只要帐号,密码正确,此处可用具体客户端IP代替,如192.168.145.226,加强安全。
3.1 刷新权限
mysql> FLUSH PRIVILEGES;
- 查询master的状态
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 120 | db1 | mysql | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set
2).MySQL主服务器配置
- 修改my.conf文件
[mysqld]
server-id=166
- 配置从服务器
mysql>change master to master_host='192.168.25.134',master_port=3306,master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=120
注意语句中间不要断开,master_port为mysql服务器端口号(无引号),master_user为执行同步操作的数据库账户,“120”无单引号(此处的120就是show master status 中看到的position的值,这里的mysql-bin.000001就是file对应的值)。
3.:启动从服务器复制功能
Mysql>start slave;
- 检查从服务器复制功能状态:
mysql> show slave status
| Slave_IO_Running: Yes //此状态必须YES | Slave_SQL_Running: Yes //此状态必须YES |
注:Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
错误处理:
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
解决方法:
删除/var/lib/mysql/auto.cnf文件,重新启动服务。
3).MaCat安装
- 把MyCat的压缩包上传到linux服务器
- 解压缩 tar zxf 压缩包名称
- 进入mycat/bin目录
- 启动命令:./mycat start
停止命令:./mycat stop
重启命令:./mycat restart
分库分表
mysql节点1环境
操作系统版本 : centos6.4
数据库版本 : mysql-5.6
mycat版本 :1.4 release
数据库名 : db1、db3
ip:192.168.25.134
mysql节点2环境
操作系统版本 : centos6.4
数据库版本 : mysql-5.6
mycat版本 :1.4 release
数据库名 : db2
ip:192.168.25.166
MyCat安装到节点1上(需要安装jdk)
1).配置schema.xml
Schema.xml介绍
Schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。
- schema 标签用于定义MyCat实例中的逻辑库
- Table 标签定义了MyCat中的逻辑表
- dataNode 标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。
- dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句
注意:若是LINUX版本的MYSQL,则需要设置为Mysql大小写不敏感,否则可能会发生表找不到的问题。
在MySQL的配置文件中my.ini [mysqld] 中增加一行
lower_case_table_names = 1
Schema.xml配置
select user()
select user()
2).配置server.xml
server.xml几乎保存了所有mycat需要的系统配置信息。最常用的是在此配置用户名、密码及权限。
Server.xml配置
test
TESTDB
true
3).配置rule.xml
rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。这个文件里面主要有tableRule和function这两个标签。在具体使用过程中可以按照需求添加tableRule和function。此配置文件可以不用修改,使用默认即可。
4).分片测试
由于配置的分片规则为“auto-sharding-long”,所以mycat会根据此规则自动分片。
每个datanode中保存一定数量的数据。根据id进行分片
经测试id范围为:
Datanode1:1~5000000
Datanode2:5000000~10000000
Datanode3:10000001~15000000
当15000000以上的id插入时报错:
[Err] 1064 - can’t find any valid datanode :TB_ITEM -> ID -> 15000001
此时需要添加节点了。
剩下的就是自己测试了,虚拟机命令太多了我就不贴图了。自己随便玩玩!
读写分离
Mycat支持MySQL主从复制状态绑定的读写分离机制,让读更加安全可靠,配置也是比较简单的配置如下
show slave status
注意
- 设置 balance="1"与writeType=“0”
Balance参数设置:
- balance=“0”, 所有读操作都发送到当前可用的writeHost上。
- balance=“1”,所有读操作都随机的发送到readHost。
- balance=“2”,所有读操作都随机的在writeHost、readhost上分发
WriteType参数设置: - writeType=“0”, 所有写操作都发送到可用的writeHost上。
- writeType=“1”,所有写操作都随机的发送到readHost。
- writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
readHost是从属于writeHost的,即意味着它从那个writeHost获取同步数据,因此,当它所属的writeHost宕机了,则它也不会再参与到读写分离中来,即“不工作了”,这是因为此时,它的数据已经“不可靠”了。基于这个考虑,目前mycat 1.3和1.4版本中,若想支持MySQL一主一从的标准配置,并且在主节点宕机的情况下,从节点还能读取数据,则需要在Mycat里配置为两个writeHost并设置banlance=1。
- 设置 switchType=“2” 与slaveThreshold=“100”
- -1:表示不自动切换
- 1 :默认值,自动切换
- 2 :基于MySQL主从同步的状态决定是否切换
Mycat心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType=“2” 与slaveThreshold=“100”,此时意味着开启MySQL主从复制状态绑定的读写分离与切换机制。Mycat心跳机制通过检测 show slave status 中的 “Seconds_Behind_Master”, “Slave_IO_Running”, “Slave_SQL_Running” 三个字段来确定当前主从同步的状态以及Seconds_Behind_Master主从复制时延。
总结
完成以上内容基本上对MyCat算有一个简单的了解,当然只是想对这个架构运用自如了解肯定是不够的,对我来说时间关系目前去深入理解还不是很现实。当然知道这个架构对于自己以后的项目开发会多一个思路吧。最近也是总结项目里面的技术,部分内容浅尝辄止吧。啊…偏向于笔记型的文章写起来真是没啥意思。当然如果你在安装配置MyCat里面出现了问题,欢迎互相交流,交流使人成长嘛。打算用将近一周时间来总结一下相关的技术,学过了得留点痕迹心里才踏实,不知道身为程序员的你有没有同样的体会·