重温大数据---HA架构部署
说完这一讲,Hadoop四个核心模块的内容基本上就结束了。前面讲过了基础的部署,包括单机、伪分布式,虽然完全分布式其实也挺简单的,但是既然是知识的梳理,在本节我也做个讲解吧。本节最重要的内容是对HDFS的HA架构的搭建。一年前看得我头大,其实嘛没有那么难,只是被高端大气的名字给吓着了。?
先谈完全分布式架构
完全分布式的概念很好理解,就是把Namenode,ResourceManager,Datanode等,分开放置到不同的机器运行,分担主节点的压力,以达到提升集群的处理能力。百度的一张架构图,基本上就这意思。
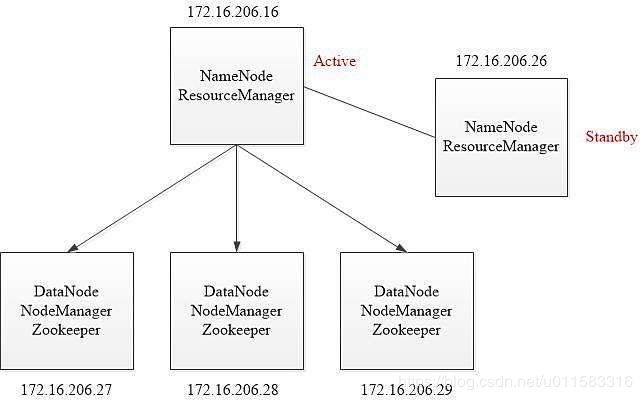
重点我们看看如何着手搭建一个分布式集群。在Hadoop初窥里面我提过一嘴(多搞几台机器 修改DataNode个数 配置slave(指定DataNode)文件 配置hosts文件 ssh OK OK不? 反正我不想打字写分布式配置了。)别看我说的倒是轻松,理清了思路,按着路子搭其实的确也轻松。后面我会用Cloudera Manager在我屋三台服务器上搭建一个企业级?的集群。那个可比手动搭建舒服太多了。具体细节我后面也会做个介绍。
硬件配置
| 192.168.1.205 | 192.168.1.206 | 192.168.1.207 |
|---|---|---|
| master | slave1 | slave2 |
| 1.5G | 1G | 1G |
| 1 CPU | 1 CPU | 1 CPU |
集群规划
HDFS:
| 192.168.1.205 | 192.168.1.206 | 192.168.1.207 |
|---|---|---|
| master | slave1 | slave2 |
| NameNode | DataNode | DataNode |
| DataNode | SecondaryNameNode |
Yarn:
| 192.168.1.205 | 192.168.1.206 | 192.168.1.207 |
|---|---|---|
| master | slave1 | slave2 |
| NodeManager | NodeManager | NodeManager |
| ResourceManager |
搭建思路:
-
第一步:机器准备
- 克隆机器
- 修改ip
- 修改主机名
- 设置好映射
-
第二步:文件配置
- HDFS
-
hadoop-env.sh 配置:java_home 就干这事
-
core-site.xml 伪分布式基础上不做什么改变
-
hdfs-site.xml
 (默认就是三个可以删掉)
(默认就是三个可以删掉)
-
slaves

-
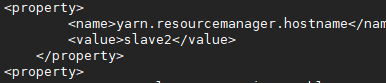
- YARN
- yarn-env.sh 配置:java_home 就干这事
- yarn-site.xml
- MapReduce
- mapred-env.sh 配置:java_home 就干这事
- mapred-site.xml 伪分布式基础上不做什么改变
- HDFS
-
第三步:SSH无密码登录
- ssh-keygen -t rsa
- ssh-copy-id 节点
- 测试
- ssh 节点
- exit
-
第四步:文件同步
-
scp -r xxx slave1:xxx/xxx
-
第五步:配置时间同步
- ntp的配置我没配,我学习环境就没弄这个,如果真实的开发一定要配置。
集群测试
-
基本测试
1. 服务启动,是否可用,简单的应用 2. HDFS创建和删除是否能够成功 3. yarn run jar 4. mapreduce -
基准测试
1. 测试集群的性能 2. hdfs:写数据、读数据 -
监控集群
1.Cloudera Manager 部署安装集群 监控集群 配置同步集群 预警
再谈实现HA
先引出一个分布式服务框架Zookeeper。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。 -----百度百科
Zookeeper架构图

为什么使用ZK实现HA呢?因为官方就是这样建议的。?实际上也很好理解。ZooKeeper提供了一个Leader Election机制,利用这个机制能够保证尽管集群存在多个Master可是唯独一个是Active的,其它的都是Standby,当Active的Master出现问题时。另外的一个Standby Master会被选举出来。因为集群的信息,包含Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交。对于正在进行的Job没有什么影响。懂了吧!高可用就这样来的。
Zookeeper 安装配置
- 复制配置文件:
在Zookeeper的主目录的conf文件夹下,有一个实例的配置文件zoo_sample.cfg,我们复制一份出来:
-
$ cd /opt/modules/zookeeper-3.4.5/conf
-
$ cp -a zoo_sample.cfg zoo.cfg
-
$ vi zoo.cfg
-
$ mkdir data
- 配置数据存储目录:
按照开发规范,我们通常在zookeeper的安装目录下,新建一个目录data,将这个目录作为zookeeper的数据存储目录。
-
dataDir=/opt/modules/zookeeper-3.4.5/data
-
zoo.cfg重要参数介绍:
-
tickTime:zookeeper服务器与服务器之间,或者服务器与客户端之间维持心跳的时间间隔。单位:毫秒。
-
clientPort:客户端连接zookeeper服务器的端口。默认2181
-
dataDir:Zookeeper保存数据的目录。
- 在zoo.cfg中添加服务器信息:
-
格式: server.A=B:C:D 。 在zoo.cfg中添加如下内容:
-
server.1=192.168.1.205:2888:3888
-
server.2=192.168.1.206:2888:3888
-
server.3=192.168.1.207:2888:3888
- 在每台服务器的$ZOOKEEPER_HOME/data/目录创建myid文件。
-
在master服务器(192.168.1.205)上,cd 到$ZOOKEEPER_HOME/data/目录,创建myid文件,myid文件的内容是1
-
在slave1服务器(192.168.1.206)上,cd 到$ZOOKEEPER_HOME/data/目录,创建myid文件,myid文件的内容是2
-
在slave2服务器(192.168.1.207)上,cd 到$ZOOKEEPER_HOME/data/目录,创建myid文件,myid文件的内容是3
-
在一台机器上配置好,拷贝到其他服务器:
-
$ scp -r zookeeper-3.4.5/ slave1:/opt/modules/
- 启动Zookeeper:
- $ bin/zkServer.sh start
- 查看状态
- bin/zkServer.sh status
注意:启动操作需要在三台服务器上都执行。
HDFS HA的背景
-
HDFS集群中NameNode 存在单点故障(SPOF)。对于只有一个NameNode的集群,如果NameNode机器出现意外情况,将导致整个集群无法使用,直到NameNode 重新启动。
-
影响HDFS集群不可用主要包括以下两种情况:一是NameNode机器宕机,将导致集群不可用,重启NameNode之后才可使用;二是计划内的NameNode节点软件或硬件升级,导致集群在短时间内不可用。
-
为了解决上述问题,Hadoop给出了HDFS的高可用HA方案:HDFS通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,比如处理来自客户端的RPC请求,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
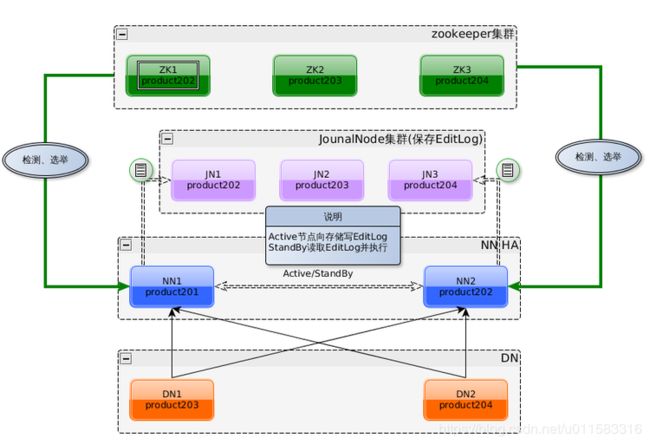
HDFS HA的架构

对这张图做个说明:
- ZKFC控制着两个Namenode,当其中一个挂掉后Zk通过选举,迅速的开启另一个Namenode进入active状态。
- 两个NN时刻保持文件系统元数据的同步和一致。
- Datanode时刻向两个NN发送report。
HDFS HA设计

HDFS HA配置
配置HA要点
-
share edits
JournalNode (日志节点)至少三个 -
NameNode
Active,Standby -
Client
Proxy -
fence
同一时刻仅仅有一个NameNode对外提供服务 使用的方式sshfence 两个NameNode之间能够ssh无密码登录 205(NameNode) ssh -> 206 206(NameNode) ssh -> 205
规划集群
| 192.168.1.205 | 192.168.1.206 | 192.168.1.207 |
|---|---|---|
| master | slave1 | slave2 |
| NameNode | NameNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
配置HA后不需要secondarynamenode了,为什么呢?配置HA后备份的Namenode基本上替代了它。
配置细节 都是官网上的东西
hdfs-site.xml
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
// 命名空间
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
// 管理哪两个nn
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>machine1.example.com:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>machine2.example.com:8020value>
property>
// nn在哪台机器
// 配置两个nn访问端口Web
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>machine1.example.com:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>machine2.example.com:50070value>
property>
// 共享日志的目录
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/myclustervalue>
property>
// 配置客户端访问
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
//配置隔离方式 ssh隔离
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/exampleuser/.ssh/id_rsavalue>
property>
使用的方式sshfence
两个NameNode之间能够ssh无密码登录
131(NameNode) ssh -> 132
132(NameNode) ssh -> 131
// 配置日志文件写在本地那个目录
<property>
<name>dfs.journalnode.edits.dirname>
<value>
/opt/app/hadoop-2.7.3/data/dfs/jn
value>
property>
//配置 core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
最后向其他两个节点同步文件
启动顺序
- ./hadoop-daemon.sh start journalnode(每个)
- bin/hdfs namenode -format(nn1)
- sbin/hadoop-daemon.sh start namenode
- ./hdfs namenode -bootstrapStandby(nn2)
- ./hadoop-daemon.sh start datanode
- ./hdfs haadmin -transitionToActive nn1
千万不要手贱乱格式化,贼烦!
ZK实现自动故障转换

HA 自动故障转移 Zookeeper
| 192.168.1.205 | 192.168.1.206 | 192.168.1.207 |
|---|---|---|
| master | slave1 | slave2 |
| NameNode | NameNode | |
| ZKFC | ZKFC | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
启动后都是Standby,需要选举一个为Active。ZKFC实现对两个Namenode的实时监控。
配置细节:
- hdfs-site.xml
// 启动故障自动转移
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
// 依赖ZK 需要知道ZK在哪
- core-site.xml
<property>
<name>ha.zookeeper.quorumname>
<value>master:2181,slave1:2181,slave2:2181value>
property>
启动:
- 关闭所有的HDFS服务:stop-dfs.sh
- 启动zookeeper集群:zkServer.sh start
- 初始化ZK中的状态:hdfs zkfc -formatZK
- 启动HDFS服务:start-dfs.sh
这里的start-dfs.sh 启动一切 包括zkFc。
值得一提的是zk挂掉不会影响集群,只是不能故障转移了,失去了对集群的选举。最后小声说一说HA太简单了! ???
Federation联盟
NameNode
能不能有多个NameNode
NameNode NameNode NameNode
元数据 元数据 元数据
log machine 电商数据/话单数据
三个模块把数据存在所有的DataNodes节点上,于是出现了下面的架构,提供解决方案。
集中式缓存管理
HDFS允许用户将一部分文件或目录缓存在HDFS中,Namenode会通知拥有对应快的DataNodes将其缓存在datanode的内存中。
分布式拷贝
数据迁移,如将测试集群的数据拷贝到生产集群 详见官网 点我
拷贝命令:
hadoop distcp -i hftp://sourceFS:50070/src hdfs://destFS:8020/dest
Yarn的HA
在熟练配置了HDFS的HA后,Yarn的HA配置也是十分简单的,它的架构基本上和HDFS的是一样的。也是通过zk选举RM来实现高可用。

详细配置 都是官网上的东西
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>cluster1value>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>master1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>master2value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>master1:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>master2:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>zk1:2181,zk2:2181,zk3:2181value>
property>
命令详见官网 点我
$ yarn rmadmin -getServiceState rm1
active
$ yarn rmadmin -getServiceState rm2
standby
$ yarn rmadmin -transitionToStandby rm1
Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@1d8299fd
Refusing to manually manage HA state, since it may cause
a split-brain scenario or other incorrect state.
If you are very sure you know what you are doing, please
specify the forcemanual flag.
总结
HA这一块,你要是照着官方文档配置其实还是挺简单的,一年前的我直接跳过了HA,只知道是高可用。想想还是太年轻了。在应用这一块,配置好能放到生产环境基本上就可以了吧!到此呢Hadoop的四个核心模块的内容就告一段落了,花了四天时间边学边练。从早做到晚的学习我尽然不困?。可能这就是知识的力量吧!又看书又看视频还看官方文档,尽然不脱发?少年你渴望力量吗??下面的就是Hive的温习了,Hive不论对谁来说应该都比MR简单吧,我应该能很快的过过去,加紧时间学习!后面还有一大片呢!