高并发架构系列:详解Redis的存储类型、集群架构、以及应用场景
什么是redis
redis是一种支持Key-Value等多种数据结构的存储系统。可用于缓存、事件发布或订阅、高速队列等场景。该数据库使用ANSI C语言编写,支持网络,提供字符串、哈希、列表、队列、集合结构直接存取,基于内存,可持久化,支持多种开发语言。
redis在高并发场景下的作用不言而喻,今天主要分享Redis大家比较关心的以下几个方面。
redis的数据类型
支持多种数据类型:
1.string(字符串)
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。
常规key-value缓存应用;
2.list(列表)
Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。
使用List结构,我们可以轻松地实现最新消息排行等功能。
3.hash(散列)
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
存储部分变更的数据,如用户信息等。
4.sets (集合)
set就是一个集合,集合的概念就是一堆不重复值的组合。利用Redis提供的set数据结构,可以存储一些集合性的数据。set中的元素是没有顺序的。
5.sorted set(有序集合)
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
redis的特点
1.单线程,利用redis队列技术并将访问变为串行访问,消除了传统数据库串行控制的开销
2.redis具有快速和持久化的特征,速度快,因为数据存在内存中。
3.分布式 读写分离模式
4.支持丰富数据类型
5.支持事务,操作都是原子性,所谓原子性就是对数据的更改要么全部执行,要不全部不执行。
6.可用于缓存,消息,按key设置过期时间,过期后自动删除
redis的持久化存储
Redis支持两种数据持久化方式:RDB方式和AOF方式。前者会根据配置的规则定时将内存中的数据持久化到硬盘上,后者则是在每次执行写命令之后将命令记录下来。两种持久化方式可以单独使用,但是通常会将两者结合使用。
1.RDB持久化
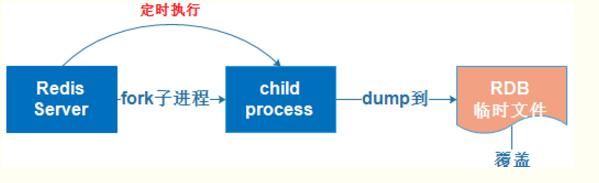
原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化。
指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
2.AOF(append only file)持久化
原理是将Reids的操作日志以追加的方式写入文件。
以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

redis的集群方案有哪些
redis 集群方案主要有两类,一是使用类 codis 的架构,按组划分,实例之间互相独立;
另一套是基于官方的 redis cluster 的方案。
1.codis 架构

codis是一个豌豆荚团队开源的使用Go语言编写的Redis
Proxy使用方法和普通的redis没有任何区别,设置好下属的多个redis实例后就可以了,使用时在本需要连接redis的地方改为连接codis,它会以一个代理的身份接收请求
并使用一致性hash算法,将请求转接到具体redis,将结果再返回codis,和之前比较流行的twitter开源的Twemproxy功能类似。
这套架构的特点:
- 分片算法:基于 slot hash桶;
- 分片实例之间相互独立,每组 一个master 实例和多个slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或etcd
- 旁路组件探活
codis是目前用的最多的集群方案,codis一个比较大的优点是可以不停机动态新增或删除数据节点,旧节点的数据也可以自动恢复到新节点。
2.基于官方 redis cluster 的方案
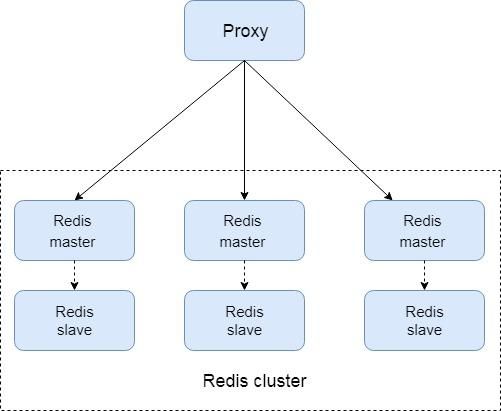
- Redis官网推出,可线性扩展到1000个节点
- 无中心架构
- 一致性哈希思想
- 客户端直连redis服务,免去了proxy代理的损耗
具体的redis cluster的搭建方案可以参考官方的搭建方案。
redis的应用场景
1、最全页面缓存
如果你使用的是服务器端内容渲染,你又不想为每个请求重新渲染每个页面,就可以使用 Redis 把常被请求的内容缓存起来,能够大大的降低页面请求的延迟。
2.排行榜/计数
Redis 基于内存,可以非常快速高效的处理增加和减少的操作,相比于使用 SQL 请求的处理方式,性能的提升是非常巨大的。
Redis可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源。
典型应用场景:
1)播放数计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1。
2)排行榜:按照时间、按照数量、按照获得的赞数等排行。
3. 共享Session
典型应用场景:用户登陆信息,Redis将用户的Session进行集中管理,每次用户更新或查询登陆信息都直接从Redis中集中获取。
4、消息队列
例如 email 的发送队列、等待被其他应用消费的数据队列,Redis 可以轻松而自然的创建出一个高效的队列。
5、发布/订阅
pub/sub 是 Redis 内置的一个非常强大的特性,例如可以创建一个实时的聊天系统、社交网络中的通知触发器等等。