高性能SQL 第三版
目录
一、MySQL架构与历史
1、逻辑架构
2、并发控制
3、事务:
隔离级别
死锁
事务日志
MySQL事务
4、多版本并发控制MVCC:乐观悲观
5、存储引擎
引擎转换
二、基准测试
测试工具
集成测试工具
单组件测试工具
测试案例
三、服务器性能剖析profiling
剖析查询
诊断间歇性问题
单条查询问题还是服务器问题
捕获诊断数据
其他剖析工具
四、Schema与数据类型优化
1、优化数据类型
整数
实数 带小数的
字符串
选择标识符identifier
2、schema设计陷阱
3、范式和反范式
4、缓存表和汇总表
物化视图
计数器表
5、加快alter table
6、总结
五、创建高性能的索引
1、索引基础
索引类型
2、索引优点
3、高性能策略
独立的列
使用前缀索引和选择性
多列索引:多列合并为一个索引
合适的索引顺序
聚簇索引
覆盖索引
使用索引扫描来排序
压缩(前缀压缩)索引
冗余和重复
未使用的索引
索引和锁
4、案例
支持多种 过滤条件
避免多个范围条件
优化排序
5、维护索引和表
找到并修复损坏的表
更新索引统计信息
减少索引或数据碎片
6、总结
六、查询优化
1、为什么慢
2、慢查询基础:优化数据访问
是否请求了不需要的数据
扫描了额外记录
代码www.highperfmysql.com
配套网页shop.oreilly.com/product/0636920022343.do
一、MySQL架构与历史
与众不同:存储架构
1、逻辑架构
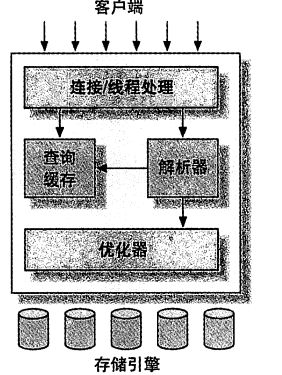
2、并发控制
表锁:Alter语句
行级锁:只在存储引擎实现,服务器层没有
3、事务:
要么全部执行成功,要么失败。ACID
隔离级别



死锁
多个事务试图以不同的顺序锁定资源时,可能发生
Innodb方法:将持有最少行级排它锁的事务进行回滚

事务日志

MySQL事务
两种事务性存储引擎:Innodb和NDB Cluster和第三方的
自动提交:默认自动提交,每个查询都被当做一个事务提交
4、多版本并发控制MVCC:乐观悲观
只在可重复读和提交读的隔离级别下工作

5、存储引擎
Innodb
表结构存在.frm文件中,数据存储在表空间;支持热备份
MyIsam
不支持事务和行级锁,崩溃无法恢复
表存在数据文件和索引文件中
加锁与并发:表锁。读取是共享锁,写入为排它锁
Archive
只支持查询和插入操作
CSV
基于excel的CSV文件
Memory
不会修改的数据可以用
引擎转换
Alter语句修改,时间很长
导入与导出
Insert...Select语句 可以分批操作
二、基准测试
指标
吞吐量:事务处理数
响应时间和延迟
并发性
可扩展性:增加资源或工作,性能也对应提高
测试工具
集成测试工具
ab:测试服务器每秒max请求 仅限单个url
http_load:测试服务器每秒max请求 多个url(Linux)
JMeter:java应用程序,多种测试
单组件测试工具
mysqlslap:模拟服务器负载
MySQL Benchmark suite:单线程,测试查询速度(自带)
Super Smack:多用户,压力测试
Database Test Suite
sysbench多线程压测
dbt2 TPC-C事务测试
测试案例
三、服务器性能剖析profiling
影响因素

慢查询日志 通用查询日志pt-query-digest
剖析查询
set profiling=1 查询information_schema表可以格式化输入日志
show STATUS
慢查询日志
诊断间歇性问题

单条查询问题还是服务器问题
1、show glabal status 把计数绘制成图表
2、show processlist 观察线程状态
3、查询日志
捕获诊断数据
使用Percona Toolkit的pt-stalk触发器监控 如超过一定时间的就收集
其他剖析工具
user_statistics表
stace查看系统调用
四、Schema与数据类型优化
1、优化数据类型
更小
更简单(ip用int型)
避免使用null
timestamp比datetime小 但范围小
整数
tiny small medium int bigint 8-64位,内部使用bigint进行计算
实数 带小数的
内部使用double进行计算
decimal存储精确类型(代价高,可扩大倍数进行bigint存储)
字符串
varchar可变长字符串,比定长省空间;有1个字节记录长度

char 定长:适合短串如MD5;经常变化的数据,碎片少;使用空格填充数据

blob和text:二进制和字符存储;blob无排序规则或字符集,text有;排序只使用前max个字节
emun:枚举类型,存储的是数字
时间日期:
datatime 1001到9999年,封装到整数中,8字节,秒级别(换bigint存微妙级别的)
timestamp 1970到2038年,1970到现在的秒数 4字节,与时区有关
位数据类型



选择标识符identifier
尽量选择int
2、schema设计陷阱
太多列;太多的关联表select;枚举;
3、范式和反范式
拆分表
优缺点

4、缓存表和汇总表
缓存表
汇总表:如group by语句。分表的统计出来 如活跃用户,最近24小时订单数
物化视图
视图:监控数据,也会同步更新;Flexviews工具
计数器表
独立表可避免查询缓存失效;可以创建多个行避免高并发,随机更新行(count等聚合函数的)
5、加快alter table
会引起表重建,引起新表和插入新表的操作
优化:如修改默认值 可直接修改.frm文件


6、总结

五、创建高性能的索引
1、索引基础
索引类型
B-tree索引
B tree和B+Tree详解https://www.cnblogs.com/vianzhang/p/7922426.html

![]()
B-tree索引适用于全键值(如查找name,birth的人)。键值范围(a-b的人)或键前缀(最左前缀,如查找姓,J开头)查找
 索引顺序:lastname,firstname dob
索引顺序:lastname,firstname dob
限制:


哈希索引
只有Memory引擎支持,也支持btree
限制:


自定义哈希索引:添加哈希列(需要添加/修改时维护哈希值,不要用sha1 md5因为长)
![]()
当哈希冲突时,添加列值精确查找
![]()
空间数据索引R-Tree
MyIsam支持,可用作地理数据存储
全文索引
查找文本关键字。第七章详述
其他如ToKuDB新开发的分形树索引
2、索引优点


3、高性能策略
独立的列
不能是表达式的一部分飞,不能是函数的参数
![]()
使用前缀索引和选择性
确定多少前缀让其选择性更高;
缺点:无法做order by和group by语句,无法使用前缀索引做覆盖扫描;
多列索引:多列合并为一个索引

换成

合适的索引顺序
一般将选择性最高的列放到最前;


聚簇索引
不是索引类型,是数据存储方式。B tree索引和数据行
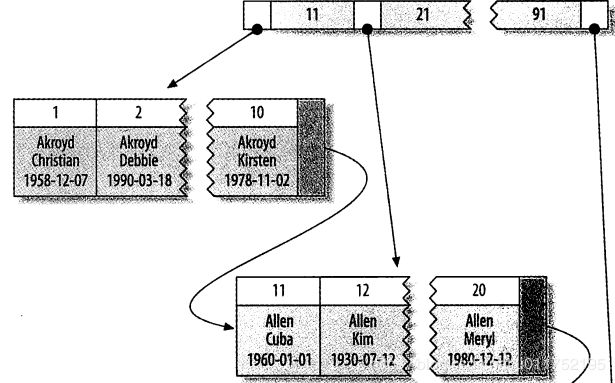


例如数据:
Myisam:主键索引图;二级索引图;(数据+行号) 与其他索引相同


Innodb:主键索引图(聚簇索引);二级索引图;支持聚簇索引,不同
不同点:是整个表,不只是索引(myisam需要独立行储存);
二级索引与聚簇索引不同:存的是主键值,不是行指针;优点:在移动是无需更新行指针


抽象图:
避免使用随机id会使插入的地方不同影响性能 如uuid为主键最好不用
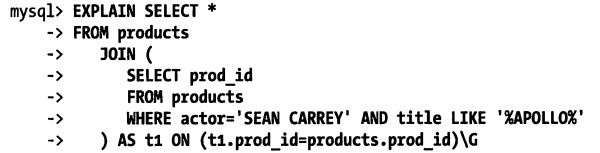
覆盖索引
定义:一个索引包含或覆盖所有需要查询的字段
好处


例如:索引覆盖查询,红线为2个索引列![]()
mysql如果只需访问这两列,就可用索引做覆盖索引。
但这个不行,选择了所有*列且有like操作(只能做比较操作):![]()
优化:延迟关联
使用索引扫描来排序

前提:索引覆盖查询的所有列;
MySQL可使用同一个索引既满足排序,又用于查找行;
只有当索引的列顺序和order by顺序一致,且所有列的排序方向一样,才能使用索引对结果做排序


例如 
此外,当查询为索引第一列提供了常量条件,而使用第二列排序,两列组合一起,就形成了最左前缀
![]()
![]()
下面的不行:
排序方向不同![]()
引用不在索引的列![]()
不是最左前缀![]()
是范围,不是常量![]()
多个等于条件![]()
优化时file actor当做第二张表![]()
压缩(前缀压缩)索引

倒序慢;cpu密集型慢;io密集型好
冗余和重复
重复索引 

大多不要冗余索引,但有些情况要:

把索引改为 key id 和key (id,city,addr)两个后,速度快了;缺点:添删改变慢了
冗余重复索引工具:pt-duplicate-key-checker; pt-upgrade
未使用的索引

索引和锁

返回234 但1会锁定。因为:

4、案例
支持多种 过滤条件
sex选择性低,几乎所有所有都可能用到的,放到索引前面;如没有sex查询,可添加in条件选择所有(男,女)
将范围查询的列放到索引后面,如age
避免多个范围条件

可以加入active字段,定时更新最近的用户,where active=1防止2个范围查询
优化排序
对选择性很低的查询,会选择出很多数据,数据可能有大量翻页,如
![]()
解决办法:延迟关联,覆盖索引

5、维护索引和表
找到并修复损坏的表
检查checj table命令;修复repair tabel 或者使用no-op操作![]()
更新索引统计信息
![]()
减少索引或数据碎片

解决方案:
![]()
![]()
![]()
工具:Perconaa的XtraBackup工具 --stats参数
6、总结

六、查询优化
1、为什么慢

2、慢查询基础:优化数据访问

是否请求了不需要的数据
分页查询:加上limit
多表关联返回全部列:
改为![]()
避免select *
查询相同数据:使用缓存
扫描了额外记录
指标
关联查询行数可能不会一样