Android常用的数据结构
Android中一般使用的数据结构有java中的基础数据结构Set, List, Map。还有一些Android中特有的几个,SparseArray(使用Map时Key是int类型的时候可以用这个代替)等。
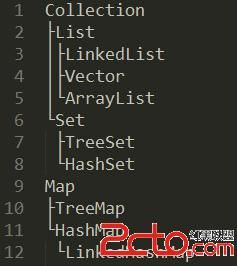
先上一张数据结构类图,还是比较清晰的。
Collection
它是所有集合类的接口,Set和List也都实现Collection接口,基本需要操作的方法都定义在这里了。
Set
一般使用的有TreeSet和HashSet
1.TreeMap
TreeSet是根据二叉树实现的,也就是TreeMap, 放入数据不能重复且不能为null,可以重写compareTo()方法来确定元素大小,从而进行升序排序。
public class DataType {
public static void main(String[] args){
Set treeSet = new TreeSet<>(new MyComparator());
treeSet.add(1);
treeSet.add(3);
treeSet.add(2);
for(Integer i : treeSet){
System.out.println(i);
}
}
static class MyComparator implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
if(o1 < o2 ){
return -1;
}
if(o1 == o2 ){
return 0;
}
if(o1 > o2 ){
return 1;
}
return 0;
}
}
} 以上代码执行结果是:
1
2
3通过传入MyComparator对象自定义的排序方法,来实现从大到小的排序。
2.HashSet
HashSet是根据hashCode来决定存储位置的,是通过HashMap实现的,所以对象必须实现hashCode()方法,存储的数据无序不能重复,可以存储null,但是只能存一个。
public class DataType {
public static void main(String[] args){
Set set = new HashSet<>();
set.add("1");
set.add("2");
set.add(null);
set.add("1");
for(String s : set){
System.out.println(s);
}
}
} 以上代码运行的结果是:
null
1
2List
List比较常用的有ArrayList和LinkedList,还有一个比较类似的Vector。
1.ArrayList
是使用动态数组来实现的,对于数据的随机get和set或是少量数据的插入或删除,效率会比较高。ArrayList是线程不安全的,在不考虑线程安全的情况下速度也比较快的。ArrayList插入数据可以重复,也是有序的,按照插入的顺序来排序。
public class ListTest {
public static void main(String[] args){
List arrayList = new ArrayList<>();
arrayList.add("1");
arrayList.add("1");
arrayList.add("2");
arrayList.remove("1");
for(String s : arrayList){
System.out.println(s);
}
}
} 内部使用动态数组来实现
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}所以根据序号读取数据只需直接获取数组对应脚表的数据就可以了。
2.LinkedList
内部是使用链表的形式来实现的,在插入大量数据的时候效率比较快。
链表实现的代码
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 往容器最后面添加元素的代码是:
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last;
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} 往容器最前面添加元素的代码
private void linkFirst(E e) {
final Node f = first;
final Node newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
} 根据序号获取数据:
public E get(int index) {
//判断index序号是否是合法的
checkElementIndex(index);
return node(index).item;
}
Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {//判断序号在总长度一半之前还是之后
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} LinkedList根据序号获取数据,是二分进行遍历,如果序号小于总长度的一半,就从链表头部开始往后遍历,直到找到对应的序号。如果序号大于总长度的一半,就从链表尾部往前进行遍历,直到找到对应的序号。拿到数据。
3.Vector
Vector的使用方法和内部实现基本和ArrayList相同,只不过它在add(), remove(), get()等方法中都加了同步。所以它是线程安全的。但是使用效率上就不如ArrayList了。
Map
1.HashMap
Map<String, String> hashMap = new HashMap<>();
hashMap.put("1", "a");//存储
hashMap.put("2", "b");
hashMap.remove("1");//根据key来删除
hashMap.get("2");//根据key获取
//map的遍历,有很多方法遍历,这里只列举一种。
for(Map.Entry<String, String> entry : hashMap.entrySet()){
entry.getKey();//获取key
entry.getValue();//获取value
}HashMap也可以说是Map的常用的使用大概就是这些了。
HashMap是基于散列链表来实现的,简单的来说,根据key算出一个hash值,确定一个存放index,但是hash值有可能会冲突重复,所以如果冲突的hash值就需要以链表的形式在同一个index存放了。关于这个,写的好的文章有很多,我就不重读造轮子了。大家看下面的文章就好了, http://blog.csdn.net/u011060103/article/details/51355763
2.TreeMap
TreeMap的使用大致跟HashMap类似,但是内部实现是根据红黑树来实现的。红黑树是一种平衡有序的二叉树,TreeMap的插入删除查询都是依据红黑树的规则来进行的。可以参考:http://blog.csdn.net/chenssy/article/details/26668941
3.Hashtable
先说下,HashMap和TreeMap都是线程不安全的,多线程操作的时候可能会造成数据错误。Hashtable是线程安全的。其他内部实现,与HashMap都是一样的。