从yesno模型入门kaldi语音识别
yesno模型
kaldi常用工具 http://blog.csdn.net/zjm750617105/article/details/52548798
kaldi官网工具大全http://kaldi-asr.org/doc/tools.html
yesno孤立词识别kaldi脚本http://www.cnblogs.com/welen/p/7485151.html
执行 run.sh入口程序
# 数据处理阶段
一. 训练和测试数据预处理阶段
执行local/prepare_data.sh waves_yesno
1. 是把waves_yeno目录下的文件名全部保存到waves_all.list中.
| ls -1 $waves_dir > data/local/waves_all.list |
2.使用perl脚本create_yesno_waves_test_train.pl把样本集一半数据共30个用作训练文件名列表存在 data/local/waves.train,另一半共30个识别测试文件名列表存到data/local/waves.test。
3.create_yesno_wav_scp.pl脚本把waves.test文件进行标注存到data/local/test_yesno_wav.scp,格式:
| 1_0_0_0_0_0_0_0 waves_yesno/1_0_0_0_0_0_0_0.wav 1_0_0_0_0_0_0_1 waves_yesno/1_0_0_0_0_0_0_1.wav .. |
4.create_yesno_wav_scp.pl脚本把waves.train进行标注存到data/local/train_yesno_wav.scp,格式:
| 0_0_0_0_1_1_1_1 waves_yesno/0_0_0_0_1_1_1_1.wav 0_0_0_1_0_0_0_1 waves_yesno/0_0_0_1_0_0_0_1.wav … |
5.create_yesno_txt.pl脚本把waves.test进行标注到data/local/test_yesno.txt,格式:
| 1_0_0_0_0_0_0_0 YES NO NO NO NO NO NO NO 1_0_0_0_0_0_0_1 YES NO NO NO NO NO NO YES … |
6.create_yesno_txt.pl脚本把waves.train进行标注到data/local/train_yesno.txt,格式:
| 0_0_0_0_1_1_1_1 NO NO NO NO YES YES YES YES 0_0_0_1_0_0_0_1 NO NO NO YES NO NO NO YES … |
7. data/local 目录创建一个文件lm_tg.arpa内容:
| \data\ ngram 1=4
\1-grams: -1 NO -1 YES -99 -1
\end\ |
8. 从WSJ样本复制阶段
8.1.创建目录data/train_yesno 和data/test_yesno
8.2. 把data/local/test_yesno_wav.scp 复制到data/test_yesno/wav.scp
把data/local/train_yesno_wav.scp 复制到data/train_yesno/wav.scp
8.3.把data/local/train_yesno.txt 复制到 data/train_yesno/text
把data/local/test_yesno .txt 复制到 data/test_yesno/text
8.4.通过awk文本处理工具处理text文本 输出到 data/train_yesno/utt2spk文件 和 data/test_yesno/utt2spk文件,这个两个文件分别是发音和人对应关系,以及人和其发音 id的对应关系.由于只有一个人的发音,所以这里都用global来表示发音.格式:
| 1_0_0_0_0_0_0_0 global 1_0_0_0_0_0_0_1 global 1_0_0_0_0_0_1_1 global ... |
8.5.通过 utils/utt2spk_to_spk2utt.pl 脚本 把 utt2spk 转换成spk2utt 格式:
| global 1_0_0_0_0_0_0_0 1_0_0_0_0_0_0_1 1_0_0_0_0_0_1_1 1_0_0_0_1_0_0_1 1_0_0_1_0_1_1_1 1_0_1_0_1_0_0_1 1_0_1_1_0_1_1_1 1_0_1_1_1_0_1_0 1_0_1_1_1_1_0_1 1_1_0_0_0_0_0_1 1_1_0_0_0_1_1_1 1_1_0_0_1_0_1_0 1_1_0_0_1_0_1_1 1_1_0_0_1_1_1_0 1_1_0_1_0_1_0_0 1_1_0_1_0_1_1_0 1_1_0_1_1_0_0_1 1_1_0_1_1_0_1_1 1_1_0_1_1_1_1_0 1_1_1_0_0_0_0_1 1_1_1_0_0_1_0_1 1_1_1_0_0_1_1_1 1_1_1_0_1_0_1_0 1_1_1_0_1_0_1_1 1_1_1_1_0_0_1_0 1_1_1_1_0_1_0_0 1_1_1_1_1_0_0_0 1_1_1_1_1_1_0_0 1_1_1_1_1_1_1_1 |
此时目录结构如下:
data
├───local
│ ├───waves.train
│ ├───waves.test
│ ├───test_yesno_wav.scp
│ ├───train_yesno_wav.scp│ ├───test_yesno.txt
│ ├───test_yesno.txt
│ ├───lm_tg.arpa
│ └───waves_all.list
├───train_yesno
│ ├───text
│ ├───utt2spk
│ ├───spk2utt
│ └───wav.scp
├───test_yesno
│ ├───text
│ ├───utt2spk
│ ├───spk2utt
│ └───wav.scp
二. 字典预处理阶段
执行local/prepare_dict.sh
1. 创建词典目录data/local/dict 和 复制文件:input/lexicon_nosil.txt 到data/local/dict/lexicon_words.txt ; input/lexicon.txt 到data/local/dict/lexicon.txt
lexicon_words.txt内容:
| YES Y NO N |
lexicon.txt 内容:
| YES Y NO N |
2. cat input/phones.txt | grep -v SIL > data/local/dict/nonsilence_phones.txt 使用反转查找(排除)文件中SIL 并且存到另一个文件 nonsilence_phones.txt 内容:
| Y N |
3. data/local/dict/silence_phones.txt 和 data/local/dict/optional_silence.txt 内容:
| SIL |
此时目录结构如下:
data├───local
│ └───dict
│ ├───lexicon_words.txt
│ ├───lexicon.txt
│ ├───nonsilence_phones.txt│ ├───silence_phones.txt
│ └───optional_silence.txt
三. 执行命令
| utils/prepare_lang.sh --position-dependent-phones false data/local/dict " |
1. 调用这个脚本处理传入的参数
| . utils/parse_options.sh |
1.1 把传入的—position-dependent-phones处理 成 position_dependent_phones 然后通过之后的代码把第二个参数false赋值给他
| name=`echo "$1" | sed s/^--// | sed s/-/_/g` |
1.2 最后左移两个参数,参数列表变为:
| utils/prepare_lang.sh data/local/dict " |
2. 四个变量,方便阅读代码
| srcdir=$1 #data/local/dict oov_word=$2 # tmpdir=$3 #data/local/lang dir=$4 #data/lang |
3. 执行不启动新的shell执行脚本 设置环境变量
| . ./path.sh |
执行 脚本 设置环境变量 KALDI_ROOT和 PATH
| kaldi/tools/env.sh |
4. 执行命令检测词典文件内容是否正确
| utils/validate_dict_dir.pl $srcdir |
检测silence_phones.txt optional_silence.txt nonsilence_phones.txt 等文件格式是否正确 (主要是匹配应该没有\r \n,是否为文件是空的,或是phones的结尾不应该是 _B, _E, _S 或 _I 这些容易混淆的符号,内容是否重复)
(检查silence_phones.txt, nonsilence_phones.txt内容互斥)
(通过 check_lexicon_pair函数 检查词典是否成对lexicon.txt lexiconp.txt )
检测data/loacal/dict/extra_questions.txt 不存在 输出"--> data/loacal/dict/extra_questions.txt is empty (this is OK)\n"
5. 检查文件$srcdir/lexicon.txt是否为普通文件,不是普通文件则执行该指令
| perl -ape 's/ (\S+\s+)\S+\s+(.+)/$1$2/;' < $srcdir/lexiconp.txt > $srcdir/lexicon.txt || exit 1; |
这个perl -ape 命令 应该是-a -p -e ,后面是字符匹配替换,$1代码第一个括号$2代 表第二个括号内容,\S+ 多个非空格 \s+ 多个空格 .+ 匹配一次或多次任何字符。
(注:本代码为普通不执行后面代码)。
6.命令 复制文件 内容:
| cp $srcdir/lexiconp.txt $tmpdir/ |
lexiconp.txt内容:
| YES 1.0 Y NO 1.0 N |
命令读取两个文件合并到phones文件,
| cat $srcdir/silence_phones.txt $srcdir/nonsilence_phones.txt | \ |
| awk '{for(n=1;n<=NF;n++) print $n; }' > $tmpdir/phones |
data/local/lang/phones文件内容:
| SIL Y N |
命令 作用是把两个文件列合并到新文件
| paste -d' ' $tmpdir/phones $tmpdir/phones > $tmpdir/phone_map.txt |
phone_map.txt内容:
| SIL SIL Y Y N N |
创建目录 data/lang/phones 一系列音素的集合
| mkdir -p $dir/phones |
官 方文档:phones目录下包含许多不同的音素集的信息,每个文件都有三种形式,扩展名为.csl, .int 和 .txt是相同信息的三种不同格式。这些文件可以用这个脚本"utils/prepare_lang.sh"创建。
方文档:phones目录下包含许多不同的音素集的信息,每个文件都有三种形式,扩展名为.csl, .int 和 .txt是相同信息的三种不同格式。这些文件可以用这个脚本"utils/prepare_lang.sh"创建。
命令主要 apply_map.pl脚本作用读入 phone_map.txt文件每行两个数据段用hash映射键值对存储,然后读入$srcdir/{,non}silence_phones.txt数据,用此数据作为键取之前hash的值并输出到sets.txt文件,在之后生成的.int文件是音素集合
| cat $srcdir/{,non}silence_phones.txt | utils/apply_map.pl $tmpdir/phone_map.txt > $dir/phones/sets.txt |
不同的silence 音素拥有不同的 GMMs. [注意: 这里所有的"shared split" 意思是对于所有状态我们可能拥有一个GMM,或者我们能够分割状态。因为他们是上下文-依赖音素(context-independent phones),他们看不到上下文context](来源:prepare_lang.sh注释)
sets.txt 内容:
| SIL Y N |
命令生成的这个roots文件让所有silence音素共享同一个概率密度函数。
| cat $dir/phones/sets.txt | awk '{print "shared", "split", $0;}' > $dir/phones/roots.txt |
roots.txt内容:
| shared split SIL shared split Y shared split Nlex_ndisambig |
7. 下面命令其中|代表管道,执行 utils/apply_map.pl 传到脚本的第一个值 $tmpdir 第二个值是$srcdir/silence_phones.txt 的内容,然后把脚本运行的结果传给后并输出到文件中属于标准输入
| cat $srcdir/silence_phones.txt | utils/apply_map.pl $tmpdir/phone_map.txt | \ awk '{for(n=1;n<=NF;n++) print $n;}' > $dir/phones/silence.txt |
silence.txt 内容:
| SIL |
8.命令生成nonsilence.txt文件
| cat $srcdir/nonsilence_phones.txt | utils/apply_map.pl $tmpdir/phone_map.txt | \ awk '{for(n=1;n<=NF;n++) print $n;}' > $dir/phones/nonsilence.txt |
nonsilence.txt 内容:
| Y N |
之后用下面两个命令把文件复制到指定目录
| cp $srcdir/optional_silence.txt $dir/phones/optional_silence.txt |
| cp $dir/phones/silence.txt $dir/phones/context_indep.txt |
optional_silence.txt内容:
| SIL |
context_indep.txt内容:
| SIL |
9. 下面命令生成data/lang/phones.txt文件
| echo " |
| awk '{n=NR-1; print $1, n;}' > $dir/phones.txt |
下面代码处理 lexiconp.txt文件每行第一个字段 并且排序去除重复 增加几个字段 并且编号 输出words.txt ,如果失败则退出。
| cat $tmpdir/lexiconp.txt | awk '{print $1}' | sort | uniq | awk ' BEGIN { print " } { if ($1 == " print " exit 1; } if ($1 == "") { print " is in the vocabulary!" | "cat 1>&2" exit 1;cat $tmpdir/lexiconp.txt | awk '{print $1}' | sort | uniq | awk ' BEGIN { print " } { if ($1 == " print " exit 1; } if ($1 == "") { print "< } printf("%s %d\n", $1, NR); } END { printf("#0 %d\n", NR+1); printf(" printf(" %d\n", NR+3); }' > $dir/words.txt || exit 1; |
lexiconp.txt 内容:
| YES 1.0 Y NO 1.0 N |
words.txt 内容:
| NO 2 YES 3 #0 4
6 |
10. 如果没有使用词-位置-依赖音素(word-position-dependent phones)的方法我们使用格词对齐(lattice word alignment)的方法,并且创建$dir/phones/align_lexicon.{txt,int} 文件。
| silphone=`cat $srcdir/optional_silence.txt` || exit 1; #silphone=SIL |
# 首先从词典移除概率通过正则匹配方法
| perl -ape 's/(\S+\s+)\S+\s+(.+)/$1$2/;' <$tmpdir/lexiconp.txt >$tmpdir/align_lexicon.txt |
# 然后增加一行"
| [ ! -z "$silphone" ] && echo " |
#读文件内容,把原文件的每行第一个字段字符多输出一遍
| cat $tmpdir/align_lexicon.txt | \ |
| perl -ane '@A = split; print $A[0], " ", join(" ", @A), "\n";' | sort | uniq > $dir/phones/align_lexicon.txt |
11. # 通过脚本命令创建 phones/align_lexicon.int 矩阵
| cat $dir/phones/align_lexicon.txt | utils/sym2int.pl -f 3- $dir/phones.txt | \ utils/sym2int.pl -f 1-2 $dir/words.txt > $dir/phones/align_lexicon.int |
其中脚本中的 $sym2int{$A[0]} = $A[1] + 0; #把从phones.txt读出来的每行两个分别 以键值存到hash中phones/align_lexicon.int
| cat $dir/phones/align_lexicon.txt | utils/sym2int.pl -f 3- $dir/phones.txt |
到这里代码输出结果为:
| NO NO 3 YES YES 2 |
(过程是通过map把存储键值,然后从另一个文件align_lexicon.txt 取第三列数据找到value值 替换结果)
经过后半段代码输出为:
| 1 1 1 0 0 1 2 2 3 3 3 2 |
(过程同上)
这段代码命令是为了生成data/lang/L.fst :
| utils/make_lexicon_fst.pl --pron-probs $tmpdir/lexiconp.txt $sil_prob $silphone | \ |
| fstcompile --isymbols=$dir/phones.txt --osymbols=$dir/words.txt \ |
| --keep_isymbols=false --keep_osymbols=false | \ |
| fstarcsort --sort_type=olabel > $dir/L.fst || exit 1; |
其中命令对概率是通过对数处理,比如ln(0.5)= 0.693147180559945
| utils/make_lexicon_fst.pl --pron-probs data/local/lang/lexiconp.txt 0.5 `cat data/local/dict/optional_silence.txt` |
执行这句话shell输出下面的结果:
| 0 1 0 1 SIL 2 1 SIL 1 1 SIL 1 1 Y YES 0.693147180559945 1 2 Y YES 0.693147180559945 1 1 N NO 0.693147180559945 1 2 N NO 0.693147180559945 1 0
|
整个命令创建L.fst文件用于训练是silence 概率,内容:
| root@wenlong:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5# fstprint data/lang/L.fst 0 1 0 0 0.693147182 0 1 1 0 0.693147182 1 1 1 1 1 1 3 2 0.693147182 1 2 3 2 0.693147182 1 1 2 3 0.693147182 1 2 2 3 0.693147182 1 2 1 1 0 |
对于fst,其打印结果,一行一般有5列。一行对应一个弧。第一列和第二列,表示这个弧的起始状态和终止状态。第三列和第四列,表示输入和输出。第五列是权重。
使用下面命令生成一个PDF文件,如下图所示
| fstdraw data/lang_test_tg/L.fst | dot -Tps | ps2pdf – L.pdf |
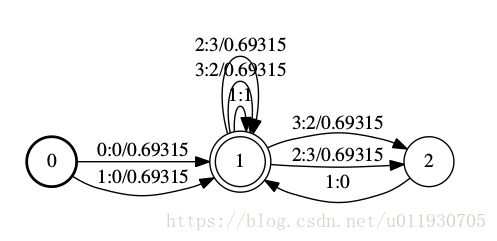
FST(Finite State Transducer)说明:
(L, see "Speech Recognition with Weighted Finite-State Transducers" by Mohri, Pereira and Riley, in Springer Handbook on SpeechProcessing and Speech Communication, 2008)
(之前以为是FSM有限状态机,FST 与FSM最主要的区别在于FST在完成状态转移的同时产生一个输出)语音这里是以音素输入,词输出结果。
| 个人理解拿L.fst为例,词: NO 2,YES 3, 初始状态0状态到1状态: 输入 音素 从1状态到2状态:3:2/0.69315 输入音素 N输出词No 权重0.69315 2:3/0.69315 输入音素 Y输出词Yes 权重0.69315 从状态2运行后必然回到状态1:1:0 输入 音素 从状态1到状态1:3:2/0.69315 输入音素 N输出词No 权重0.69315 2:3/0.69315 输入音素 Y输出词Yes 权重0.69315 1:1 输入 音素SIL 输出是 SIL 状态1是终止状态 ,结束时候可以得到该输出语句的权重总和。 (还没看到权重是直接加还是像概率那样累乘,以后完善,那种决策树算法和它有没有关系呢?) 2017年10月11日更新:权重的这个运算在下文WFST中有所说明 2.3. Composition 应该是进行模型组合运算 |
下面这段是从别处看来的fst说明,下面这段话好像是自己打上的放百度里也没有找到出处

初始状态是0.这仅仅有一个初始状态,最终状态是2权重是3.5。任何非初始最终权重的 状态都是一个最终的状态。从状态0到1输入标签a输出标签x权重0.5的arc (或转移)。这个FST 有限状态转换器中ac到xz的权重是6.5(arc的总和加上最终权重)。
12. 在训练期间这个文件 oov.txt 包含了我们将要映射词汇表之外的发音词,并通过上面的方法生成oov.int 矩阵文件。
oov.txt 内容只有一行 :
| echo "$oov_word" > $dir/oov.txt || exit 1; |
| cat $dir/oov.txt | utils/sym2int.pl $dir/words.txt >$dir/oov.int || exit 1; |
生成 wdisambig.txt文件 内容:#0
| echo '#0' >$dir/phones/wdisambig.txt |
13. 同样生成矩阵文件
| utils/sym2int.pl $dir/phones.txt <$dir/phones/wdisambig.txt>$dir/phones/wdisambig_phones.int |
| utils/sym2int.pl $dir/words.txt <$dir/phones/wdisambig.txt >$dir/phones/wdisambig_words.int |
14. 使用同样的方法创建这个矩阵文件
| for f in silence nonsilence optional_silence disambig context_indep; do utils/sym2int.pl $dir/phones.txt <$dir/phones/$f.txt >$dir/phones/$f.int utils/sym2int.pl $dir/phones.txt <$dir/phones/$f.txt | \ awk '{printf(":%d", $1);} END{printf "\n"}' | sed s/:// > $dir/phones/$f.csl || exit 1; done
for x in sets extra_questions; do utils/sym2int.pl $dir/phones.txt <$dir/phones/$x.txt > $dir/phones/$x.int || exit 1; done
utils/sym2int.pl -f 3- $dir/phones.txt <$dir/phones/roots.txt \ > $dir/phones/roots.int || exit 1;
if [ -f $dir/phones/word_boundary.txt ]; then utils/sym2int.pl -f 1 $dir/phones.txt <$dir/phones/word_boundary.txt \ > $dir/phones/word_boundary.int || exit 1; fifor f in silence nonsilence optional_silence disambig context_indep; do utils/sym2int.pl $dir/phones.txt <$dir/phones/$f.txt >$dir/phones/$f.int utils/sym2int.pl $dir/phones.txt <$dir/phones/$f.txt | \ awk '{printf(":%d", $1);} END{printf "\n"}' | sed s/:// > $dir/phones/$f.csl || exit 1; done
for x in sets extra_questions; do utils/sym2int.pl $dir/phones.txt <$dir/phones/$x.txt > $dir/phones/$x.int || exit 1; done
utils/sym2int.pl -f 3- $dir/phones.txt <$dir/phones/roots.txt \ > $dir/phones/roots.int || exit 1;
if [ -f $dir/phones/word_boundary.txt ]; then utils/sym2int.pl -f 1 $dir/phones.txt <$dir/phones/word_boundary.txt \ > $dir/phones |
15.
| silphonelist=`cat $dir/phones/silence.csl` #结果 : silphonelist=1 |
| nonsilphonelist=`cat $dir/phones/nonsilence.csl` #结果: nonsilphonelist= 2:3 |
16. 生成一个拓扑文件,允许控制这个 non-silence HMMs和 silence HMMs 的状态数
| utils/gen_topo.pl $num_nonsil_states $num_sil_states $nonsilphonelist $silphonelist >data/lang/topo |
topo内容1表示silcense,2是Y ,3是N:
| 2 3
1
|
17. 生成 L_disambig.fst文件
| utils/make_lexicon_fst.pl --pron-probs $tmpdir/lexiconp_disambig.txt $sil_prob $silphone '#'$ndisambig | \ fstcompile --isymbols=$dir/phones.txt --osymbols=$dir/words.txt \ --keep_isymbols=false --keep_osymbols=false | \ fstaddselfloops $dir/phones/wdisambig_phones.int $dir/phones/wdisambig_words.int | \ fstarcsort --sort_type=olabel > $dir/L_disambig.fst || exit 1; |
L_disambig.fst也是一个发音词典,除了L.fst的内容,还包括#1, #2这种消除岐义的符号,#0是一个自环,具体可以看Disambiguation symbols说明:
http://kaldi-asr.org/doc/graph.html#graph_disambig
使用fstprint命令得到内容:
| root@wenlong:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5# fstprint data/lang_test_tg/L_disambig.fst 0 1 0 0 0.693147182 0 2 1 0 0.693147182 1 1 1 1 1 1 3 2 0.693147182 1 3 3 2 0.693147182 1 1 2 3 0.693147182 1 3 2 3 0.693147182 1 1 4 4 1 2 1 5 0 3 2 1 0 |
使用命令得到FST状态图:
| fstdraw data/lang_test_tg/L_disambig.fst | dot -Tps | ps2pdf - L_disambig.pdf |
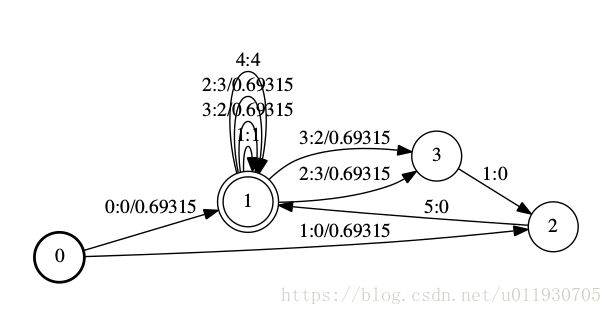
18. 通过该语句验证目录以及文件
| ! utils/validate_lang.pl $dir && echo "$(basename $0): error validating output" && exit 1; |
处理之后目录结构图:
data├───lang
│ └───phones
│ ├───align_lexicon.txt
│ ├───align_lexicon.int
│ ├───context_indep.txt
│ ├───context_indep.int
│ ├───disambig.txt
│ ├───disambig.int
│ ├───extra_questions.txt
│ ├───extra_questions.int
│ ├───nonsilence.txt
│ ├───nonsilence.int
│ ├───optional_silence.txt
│ ├───optional_silence.int
│ ├───roots.txt
│ ├───roots.int
│ ├───sets.txt
│ ├───sets.int
│ ├───silence.txt
│ ├───silence.int
│ ├───wdisambig.txt
│ ├───wdisambig_phones.int
│ ├───wdisambig_words.int
四. 执行命令 local/prepare_lm.sh 准备语言模型用于测试
LM(language model)在data/lang_test_tg 目录
1. 命令arpa2fst是一个Kaldi的C++ 程序。该程序将ARPA格式的语言模型转换为一个加权有限状态转换器(实际上是一个接收器)
| arpa2fst --disambig-symbol=#0 --read-symbol-table=$test/words.txt input/task.arpabo $test/G.fst |
--disambig-symbol=#0 用于输入侧的回退链接,去除 和
--read-symbol-table=$test/words.txt 使用已存在的符号列表,默认是“”。
words.txt内容:
| NO 2 YES 3 #0 4
6 |
ARPA是常用的语言模型存储格式, 由主要由两部分构成。模型文件头和模型文件体构成。
(词组前面的数字:概率,词组后面的数据,回退权值)
yesno的模型input/task.arpabo:
| \data\ ngram 1=4
\1-grams: -1 NO -1 YES -99 -1 \end\ |
通过arpa2fst转换的G.fst 通过fstprint函数可以看到结果:
| root@wenlong:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5# fstprint data/lang_test_tg/G.fst 0 0 2 2 2.30258512 0 0 3 3 2.30258512 0 2.30258512 |
对于fst,其打印结果,一行一般有5列。一行对应一个弧。第一列和第二列,表示这个弧的起始状态和终止状态。第三列和第四列,表示输入和输出。第五列是权重。
| fstdraw data/lang_test_tg/G.fst | dot -Tps | ps2pdf – G.pdf |
该命令生成一个PDF文件,如下图所示
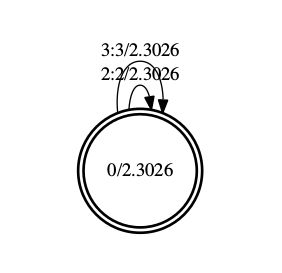
使用C++工具验证生成的G.fst文件
| fstisstochastic data/lang_test_tg/G.fst |
| 输出结果:1.20397 1.20397 |
# Create the lexicon FST with disambiguation symbols, and put it in lang_test.
# There is an extra step where we create a loop to "pass through" the
# disambiguation symbols from G.fst.
# 特征提取阶段
$x分别对与train_yesno和 test_yesno执行以下三条指令
以 train_yesno 为例
一. 命令
| steps/make_mfcc.sh --nj 1 data/$x exp/make_mfcc/$x mfcc |
其中—nj 1 表示并行任务的数量,data/$x 训练所在目录,exp/make_mfcc/$x记录make_mfcc的执行log,mfcc 特征输出目录
主要为了创建feats.scp文件
1. 创建目录/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc 和exp/make_mfcc/train_yesno
2. 如果data/train_yesno/feats.scp是普通文件,创建目录data/train_yesno/.backup并把此scp 文件移动到/.backup目录下
3. 判断两个文件是否是普通文件data/train_yesno/wav.scp 和 conf/mfcc.conf,没有则退出
4. 该脚本检测data目录中数据是否正常
| utils/validate_data_dir.sh --no-text --no-feats data/train_yesno |
5. 该脚本除非mfcc/storage/ 存在否则没用
| utils/create_data_link.pl $mfccdir/raw_mfcc_$name.$n.ark |
6.由于没有data/train_yesno/segments目录执行else之后的语句,显示提示steps/make_mfcc.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
执行命令但是由于第二个参数文件不存在,好像也没什么用
| utils/split_scp.pl $scp $split_scps || exit 1; #$scp= data/train_yesno/wav.scp $split_scps=exp/make_mfcc/train_yesno/wav_train_yesno.1.scp |
7.
| run.pl JOB=1:$nj $logdir/make_mfcc_${name}.JOB.log \ compute-mfcc-feats $vtln_opts --verbose=2 --config=$mfcc_config \ scp,p:$logdir/wav_${name}.JOB.scp ark:- \| \ copy-feats $write_num_frames_opt --compress=$compress ark:- \ ark,scp:$mfccdir/raw_mfcc_$name.JOB.ark,$mfccdir/raw_mfcc_$name.JOB.scp \ || exit 1; |
参数列表:
-
JOB=1:1
-
exp/make_mfcc/train_yesno/make_mfcc_train_yesno.JOB.log
-
compute-mfcc-feats
-
--verbose=2
-
--config=conf/mfcc.conf
-
scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.JOB.scp
-
ark:-
-
|
-
copy-feats
-
--compress=true
-
ark:-
-
ark,scp:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.JOB.ark,/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.JOB.scp
| $jobname = $1; #JOB $jobstart = $2; #1 $jobend = $3; #1 |
其中该语句根据cpu核心数量设置并行任务数;
| elsif (open(P, " while ( ) { if (m/^processor/) { $max_jobs_run++; } } |
核心就是执行该代码把shell日志存到exp/make_mfcc/$x目录下的.log文件 并生成 raw_mfcc_train_yesno.1.ark 和 raw_mfcc_train_yesno.1.scp ,raw_mfcc_train_yesno.1.scp 存放的是发音id 和 对应的总特征文件.ark中语音对应的字节偏移,官方文档说fseek() to position24, and read the data that's there.
使用fseek()定位到24字节位置读取内容。
下面这段代码利用Kaldi的compute-mfcc-feats工具计算梅尔倒谱频率特征,然后利用copy-feats工具的参数—compress=true 压缩处理存储为两个文件类型ark和scp
| compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:- | copy-feats --compress=true ark:- ark,scp:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp |
查看前几行数据内容:
| root@wenlong:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5# copy-feats ark:mfcc/raw_mfcc_train_yesno.1.ark ark,t:- | head copy-feats ark:mfcc/raw_mfcc_train_yesno.1.ark ark,t:- 0_0_0_0_1_1_1_1 [ 48.97441 -14.08838 -0.1344408 4.717922 21.6918 -0.2593708 -8.379625 8.9065 4.354931 17.00239 0.8865671 9.878274 2.105978 53.68612 -10.14593 -1.394655 -2.119211 13.08846 6.172102 8.67521 19.2422 0.4617066 5.210238 3.242958 2.333473 -0.5913677 55.30577 -10.3102 2.783288 6.130808 18.00465 0.1580257 -5.36183 5.867401 6.992276 3.769728 0.3255215 4.97998 6.144587 56.4837 -16.38814 -2.418081 8.250138 5.304474 5.584198 -14.83413 2.809654 10.13197 19.37797 -4.723887 2.218409 4.529143 59.04967 -6.238421 -3.889256 -4.782247 1.989491 8.229766 -3.262494 -3.118021 -2.301227 12.84513 -23.23007 4.634783 -2.480992 61.0052 -5.754351 -2.929794 -1.887643 9.401306 6.466054 3.297932 5.754842 6.992276 13.73597 -2.704123 -3.764996 -11.14875 61.16816 -6.399778 -4.081148 -1.308722 0.9340172 1.201521 1.067387 3.180134 5.485222 14.03292 -2.367496 -0.4280972 4.259902 61.98296 -7.206563 -1.714476 2.512154 2.200584 6.760006 -7.461166 -3.488502 2.219936 8.297047 -3.826214 9.39221 -4.559578 60.51632 -6.722493 -2.482045 -1.656075 4.485107 2.662413 -7.067541 10.36977 5.485222 6.650749 -2.591914 6.718862 -3.89821 |
8. 这段代码把raw_mfcc_test_yesno.1.scp 和raw_mfcc_train_yesno.1.scp内容拷贝到 train_yesno/feats.scp 和 test_yesno/feats.scp 中
| for n in $(seq $nj); do cat $mfccdir/raw_mfcc_$name.$n.scp || exit 1; done > $data/feats.scp || exit 1 |
feats.scp 内容格式:
| 0_0_0_0_1_1_1_1 /home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark:16 0_0_0_1_0_0_0_1 /home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark:8386 0_0_0_1_0_1_1_0 /home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark:17289 0_0_1_0_0_0_1_0 /home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark:25347 0_0_1_0_0_1_1_0 /home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark:33353 …… |
二.
| steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc |
创建文件cmvn.scp包含计算每个说话人的(cmvn)倒谱频率均值和方差归一化的统计量,以说话人编号为索引。内容如下:
| global /home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5/mfcc/cmvn_train_yesno.ark:7 |
只有一条是因为是只有一个人发音所以用global就可以了
与 feats.scp 不同,这个 scp 文件是以说话人编号为索引,而不是发音编号。
三. 在data/train_yesno 和data/test_yesno 创建两个目录 .back 然后把需要的文件复制过来
包括cmvn.scp feats.scp spk2utt text utt2spk wav.scp
| utils/fix_data_dir.sh data/$x |
文档中指出“(当然可对任何数据目录使用该命令,而不只是 data/train)。该脚本会修复排序错误,并会移除那些缺失发声人(utterances)的数据包括特征数据或标注。”
mfcc目录├───cmvn_test_yesno.ark
├───cmvn_train_yesno.ark
├───cmvn_train_yesno.ark
├───raw_mfcc_test_yesno.1.ark
├───raw_mfcc_train_yesno.1.ark
├───cmvn_test_yesno.scp
├───cmvn_train_yesno.scp
├───raw_mfcc_test_yesno.1.scp
├───raw_mfcc_train_yesno.1.scp
# Mono 训练
发现一个文档在训练阶段讲解比较详细
| http://blog.csdn.net/duishengchen/article/details/52575926 |
执行代码该语句进行单音素训练
|
|
|
|
(nj根据参数--nj 1 确定)
|
|
其中 exp/mono0a/log 存放日志文件
1. 命令
|
|
#该C++代码执行可以得到mfcc的特征维度,feat_dim这里mfcc是39维
前缀"scp:" 或 "ark:"代表文件后缀名的格式,目的告诉C++代码执行时传入的数据文件类型,其中ark是二进制文件。
从一个博客了解下面人容:
博客地址:http://blog.csdn.net/llearner/article/details/77543337|
.scp和.ark文件几个通用的点: |
更多信息看 Kaldi I/O mechanisms.(下文有简单介绍)
wspecifiers-
"t" (text) text 模式.
-
"b" (binary) 二进制.
-
"f" (flush) 每次写操作都刷新流
-
"nf" (no-flush) 每次写操作都不刷新流
-
"p" (permissive) 宽松模式, 对于scp文件 缺少一些东西,这个 "p"不会写入文件,也不会报告错误
例如:
"ark,t,f:data/my.ark"
"ark,scp,t,f:data/my.ark,|gzip -c > data/my.scp.gz"rspecifiers
-
"o" (once)
-
"p" (permissive)
-
"s" (sorted)key按照排序后的字符串读取
-
"cs" (called-sorted) 进行排序
2. 命令是混合高斯模型初始化过程和生成一个决策树,$cmd就是run.pl
|
|
在run.pl中下面这段代码:
|
|
个人理解是使得$cmd命令直接通过管道在shell中执行并且记录日志(百度没有搜到相关语法,只知道|是管道)这里是使用运行C++程序工具
从日志可以得到字符替换后的命令参数其中
|
|
输出:exp/mono0a/0.mdl 生成的模型可以使用gmm-info查看概要信息:
|
|
输出:exp/mono0a/tree 决策树
| root@wenlong:/home/wenlong/wenlong_GIT/kaldi/egs/yesno/s5# tree-info $tree tree-info exp/mono0a/tree num-pdfs 11 context-width 1 central-position 0 |
决策树是如何在 kaldi 中使用的官方文档:
http://kaldi-asr.org/doc/tree_externals.html
使用命令查看phone 树 |

C++工具draw-tree
http://www.kaldi-asr.org/doc/draw-tree_8cc.html
"输出一个决策树"
使用帮助:
| "Usage: draw-tree [options] "e.g.: draw-tree phones.txt tree | dot -Gsize=8,10.5 -Tps | ps2pdf - tree.pdf\n" |
run.pl 把参数传到shell中运行了以下C++工具
| gmm-init-mono --shared-phones=data/lang/phones/sets.int '--train-feats=ark,s,cs:apply-cmvn --utt2spk=ark:data/train_yesno/split1/1/utt2spk scp:data/train_yesno/split1/1/cmvn.scp scp:data/train_yesno/split1/1/feats.scp ark:- | add-deltas ark:- ark:- | subset-feats --n=10 ark:- ark:-|' data/lang/topo 39 exp/mono0a/0.mdl exp/mono0a/tree
subset-feats --n=10 ark:- ark:-
add-deltas ark:- ark:-
apply-cmvn --utt2spk=ark:data/train_yesno/split1/1/utt2spk scp:data/train_yesno/split1/1/cmvn.scp scp:data/train_yesno/split1/1/feats.scp ark:- |
3. 命令
|
|
#其中$cmd是run.pl脚本 JOB=1:$nj是并行处理 $dir/log/compile_graphs.JOB.log 是记录日志
|
|
执行完成会在日志输出以下结果
|
|
参考官方文档相关:Decoding-graph creation recipe (training time)
http://kaldi-asr.org/doc/graph_recipe_train.html
4. 命令
|
|
运行原理类似上一个命令,执行 align-equal-compiled程序把结果利用管道当成输出执行第二个程序 gmm-acc-stats-ali
5. gmm-est工具是基于GMM的最大似然重估声学模型
|
|
6. 在while循环中使用gmm-acc-stats-ali(GMM训练累积状态)和gmm-est工具进行训练,并且按照 realign_iters="1 2 3 4 5 6 7 8 9 10 12 14 16 18 20 23 26 29 32 35 38";这些次数时候使用gmm-align-compiled工具重新对齐数据
# Graph compilation
一. 该脚本创建一个完整的可扩展的解码图HCLG
| utils/mkgraph.sh data/lang_test_tg exp/mono0a exp/mono0a/graph_tgpr |
描绘了所有语言模型G,发声词典(lexicon)L,上下文依赖(context-dependecy)C,还有我们模型HMM的结构H,输出结果是有限状态转换器(FST),在输出中有word-ids,pdf-ids(有求解GMM的indexes),具体过程查看官方文档Decoding-graph creation recipe (test time)
http://kaldi-asr.org/doc/graph_recipe_test.html
http://blog.csdn.net/quhediegooo/article/details/70037062 这篇文档关于HCLG知识
1. 初始化参数表
| lang=$1 # data/lang_test_tg tree=$2/tree #exp/mono0a/tree model=$2/final.mdl #exp/mono0a/final.mdl dir=$3 #exp/mono0a/graph_tgpr
mkdir -p $dir |
2. 上下文音素窗(Phonetic context windows)
具体参考官方文档 How decision trees are used in Kaldi 中的Phonetic context windows部分内容
http://kaldi-asr.org/doc/tree_externals.html
| N=$(tree-info $tree | grep "context-width" | cut -d' ' -f2) || { echo "Error when getting context-width"; exit 1; } #N=1 P=$(tree-info $tree | grep "central-position" | cut -d' ' -f2) || { echo "Error when getting central-position"; exit 1; } #P=0 |
N 代表上下文相关音素窗的宽度,P 表示指定中心音素。
| Name in code |
Name in command-line arguments |
Value (triphone) |
Value (monophone) |
| N |
–context-width=? |
3 |
1 |
| P |
–central-position=? |
1 |
0 |
三音素:
// probably not valid C++
vector
假设 N=3和 P=1,这个就代表音素15有一个右边的上下文21和左边的上下文12。
vector
表示音素15有一个左上下文和没有右上下文,在决策树代码里为了方便,我们不把后续符号放在这些上下文窗中,我们直接给其赋0。
单音素:
vector
所以单音素系统是上下文相关系统的一个特殊情况,窗的大小 N=1和一个不做任何事情的树。
3. 四个变量对应的值:
| clg=$lang/tmp/CLG_${N}_${P}.fst clg_tmp=$clg.$$ ilabels=$lang/tmp/ilabels_${N}_${P} ilabels_tmp=$ilabels.$$ #$$代表当前进程的id号 |
clg = data/lang_test_tg/tmp/CLG_1_0.fst
clg_tmp = data/lang_test_tg/tmp/CLG_1_0.fst.5129
ilabels = data/lang_test_tg/tmp/ilabels_1_0
ilabels_tmp =data/lang_test_tg/tmp/ilabels_1_0.5129
4.生成一个exp/mono0a/graph_tgpr/Ha.fst文件,在后面脚本中为了节省空间把它删除
| if [[ ! -s $dir/Ha.fst || $dir/Ha.fst -ot $model \ || $dir/Ha.fst -ot $lang/tmp/ilabels_${N}_${P} ]]; then make-h-transducer --disambig-syms-out=$dir/disambig_tid.int \ --transition-scale=$tscale $lang/tmp/ilabels_${N}_${P} $tree $model \ > $dir/Ha.fst.$$ || exit 1; mv $dir/Ha.fst.$$ $dir/Ha.fst fi |
kaldi工具 make-h-transducer
|
5. 使用kaldi工具进行fst的组合,确定化,去除符号,去除空转移,最小化,是否随机?
(还得好好学习以下fst相关知识)
| fsttablecompose $dir/Ha.fst "$clg" | fstdeterminizestar --use-log=true \ | fstrmsymbols $dir/disambig_tid.int | fstrmepslocal | \ fstminimizeencoded > $dir/HCLGa.fst.$$ || exit 1; mv $dir/HCLGa.fst.$$ $dir/HCLGa.fst fstisstochastic $dir/HCLGa.fst || echo "HCLGa is not stochastic" |
该实例shell输出信息:
| fsttablecompose exp/mono0a/graph_tgpr/Ha.fst data/lang_test_tg/tmp/CLG_1_0.fst fstdeterminizestar --use-log=true fstrmsymbols exp/mono0a/graph_tgpr/disambig_tid.int fstrmepslocal fstminimizeencoded fstisstochastic exp/mono0a/graph_tgpr/HCLGa.fst 0.5342 -0.000299216 HCLGa is not stochastic |
6. 使用工具add-self-loops 增加自环
| add-self-loops --self-loop-scale=$loopscale --reorder=true \ $model < $dir/HCLGa.fst | fstconvert --fst_type=const > $dir/HCLG.fst.$$ || exit 1; |
# Decoding
附录1 Kaldi for Dummies tutorial 官网内容:
#数据准备阶段
一. 语音数据:文件格式是.wav,每个文件包含几个英文单词,文件名对应格式例如(1_5_6.wav.到“one,five,six”)
数据集一般是这样:
1. 10和不同的说话人(ASR自动语音识别必须在不同的人训练和测试,人越多效果越好)
2. 每个人说10个不同的句子。
3. 100个*.wav文件放入10个文件夹,每个文件夹10个*.wav文件
4. 300个词(从数字0到9)
5. 每个句子/话语由3个词组成。
一般在egs文件夹下构建自己的训练测试项目文件夹,比如MyAudio文件夹在它下面创建两个文件夹train和test选取一个人以人名命名的文件夹放到test文件夹用于测试,剩下9个人分别创建9个文件夹放到train中用于训练
二. 声学数据
创建一些test文件(每个string一行对应数字)必须是有序的,使用utils/validate_data_dir.sh验证数据,使用fix_data_dir.sh脚本修复存在的错误
在MyAudio文件夹下创建data文件夹,然后创建train和test两个子文件夹,在每个文件夹都有下列文件:
1. spk2gender
该文件是说话人和说话人的性别的对应关系(f=female,m=male)
pattern:
2. wav.scp
发言人与音频文件的对应关系
pattern:
3. text
包含每个发音人匹配的文本标音
pattern:
4. utt2spk
每个发音人表述内容对应的说话人
Pattern:
dad_4_4_2 dad
july_1_2_5 july
july_6_8_3 july
# and so on…
5. corpus.txt
data文件夹下创建的一个子文件夹local,在里面创建一个文件corpus.txt 每行代表一个音频文件的标音
pattern:
三. 语言数据
是语言模型文件相关的,主要是在data/local目录下创建dict子目录,该目录有以下的文件: 1. lexicon.txt
包含每个词的音素的标音
pattern:
eight ey t
five f ay v
four f ao r
# and so on…
2. nonsilence_phones.txt
该文件把非静音音素放入一个列表
pattern:
ah
ao
ay
# and so on…
3. silence_phones.txt
静音音素
pattern:
sil
spn
4. optional_silence.txt
可选的silence音素
pattern :
sil
四. 工具脚本主要放在utils和steps中
五.评分脚本在local/score.sh 获得解码结果
六. 配置文件
创建一个文件夹conf创建下面2个文件
1. decode.config
first_beam=10.0
beam=13.0
lattice_beam=6.0
2.mfcc.conf
--use-energu=false
一般来说,训练主要是MONO但音素训练,简单三音素训练两种方式。
附录2 Kaldi 的I/O机制
(由于调用C++程序对参数不太理解,查了资料需要学习这个机制)
I/O机制代码级别官方文档:http://www.kaldi-asr.org/doc/io.html
命令行的I/O机制:http://www.kaldi-asr.org/doc/io_tut.html
一. Non-table I/O
所涉及的文件或者流仅仅包含一到两个对象(声学模型文件,变换矩阵
1. kaldi文件默认是2进制的,如果flag –binary=false输出则是非2进制
2. 有许多符合 "copy" 程序, e.g. copy-matrix 或gmm-copy, 可以使用 –binary=false 这个标志转换成text格式, e.g. "copy-matrix --binary=false foo.mat -".
3.磁盘上的文件应该和内存中的C++的object对象一致,e.g. a matrix of floats,尽管一些文件比这个object对象多(对于声学模型文件有 TransitionModel object 和一个声学模型)
4. kaldi程序需要知道它要读的文件的类型,而不是从流中读出类型。(PS:所以要加scp:)
5. 同样地,对于perl一个文件名能够被 - 所替换或是一个例如"|gzip -c >foo.gz" or "gunzip -c foo.gz|" 的string
6. 对于读文件,也支持如 “foo:1045” 表示从 foo 文件偏移 1045 个字节开始读取。
例如: echo '[ 0 1 ]' | copy-matrix --binary=false - - 其中 | 代表管道把输出变为下面的输入
或是这样:echo '[ 0 1 ]|' 'copy-matrix - - | copy-matrix --binary=false - -' 传入两个参数得到一样效果
二. Table I/O
处理strings字符串索引的数据集合,比如通过utterance-ids索引的特征矩阵或是通过speaker-ids索引的speaker-adaptation 变化矩阵,strings必须非空。
一个表可能存在两种格式:一个是 "archive" 或是 "script ".不同是 archive包含真实的数据,script文件定位一个数据的位置。
"rspecifier" 程序从表中读,告诉我们如何读一个索引的数据
"wspecifier"程序把数据写入表中
rspecifiers的共同的类型是"ark:-", 从标准输入中作为一个archive读取数据,或是"scp:foo.scp",代表从script文件foo.scp读取数据
-
对于 rspecifiers的 ark,s,cs:- 代表我们从标准输入读已经排序的keys (,s) 我们认为他们将按顺序被读取, (,cs)意味着我们知道程序将 按顺序访问他们(如果条件不满足,程序将会崩溃),好处就是可以随机访问而不会浪费大量的内存。
-
对于数据不是很大还有不方便确保顺序 (e.g. transforms for speaker adaptation), 省略,s,cs.几乎没有坏处
-
通常程序会采用多个 rspecifiers 的对于第一个通常不需要",s,cs"
-
对于scp,p:foo.scp, 这个 ,p 意味着如果这些引用的文件不存在则我们不应该让程序崩溃 (对于archives,如果这个 archive 损坏和截断p 将阻止崩溃.)
-
对于写数据这个选项 ,t 意味着text模式, e.g. in ark,t:-. 这个 –binary 命令行选项将不会影响到这个archives.
附录3 Kaldi常用工具
参考kaldi常用工具 http://blog.csdn.net/zjm750617105/article/details/52548798
kaldi官网工具大全http://kaldi-asr.org/doc/tools.html
附录4 FST(Finite State Transducer)总结:
一般使用的是WFST(Weightd Finite State Transducer)加权有限状态转换器
看了那篇论文挑选一些重点(L, see "Speech Recognition with Weighted Finite-State Transducers" by Mohri, Pereira and Riley, in Springer Handbook on SpeechProcessing and Speech Communication, 2008)
(没看完,以后有时间再看它,先看脚本了)
OpenFst资源:OpenFst website
http://www.openfst.org/twiki/bin/view/FST/WebHome
一篇中文博客讲解WFST中epsilon removal和determinization操作
http://blog.csdn.net/l_b_yuan/article/details/50954425
2.1. Weighted Acceptors 加权接收器
A finite-state transducer is a finite automaton whose state transitions are labeled with both input and output symbols. Therefore, a path through the transducer encodes a mapping from an input symbol sequence, or string, to an output string. A weighted transducer puts weights on transitions in addition to the input and output symbols. Weights may encode probabilities, durations, penalties, or any other quantity that accumulates along paths to compute the overall weight of mapping an input string to an out-put string. Weighted transducers are thus a natural choice to represent the probabilistic finite-state models prevalent in speech processing.
一个有限状态转义器是一个有限状态机,他的转义转换是用输入输出符号标记。因此,一个路径通过转换器编码一个从输入序列或字符串到输出符号的映射。权重转换器除了输入输出符号外还把权重放到转移过程上。权重可能是编码概率,持续时间,惩罚因子或是其他沿着路径计算全部输入字符串到输出字符串的映射权重的积累量。权重转换器因此也是代表流行在语音处理方面概率有限状态模型的一个自然选择。
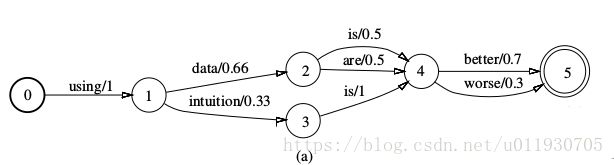
图1 (a)
The automaton in Figure 1(a) is a toy finite-state language model. The legal word strings are specified by the words along each complete path, and their probabilities by the product of the corresponding transition probabilities.
这个图是一个微不足道的有限状态语言模型。合法词字符串被沿着每个完整路径的词所指定,他们的概率和通过符合转移概率的乘积得到。

图1 (b)
The automaton in Figure 1(b) gives the possible pro-nunciations of one word, data, used in the language model. Each legal pronunciation is the phone strings along a complete path, and its probability is given by the product of the corresponding transition probabil-ities.
这个图的自动机给了一个词,数据在语言模型的发音可能。每个合法的发音是沿着完整路径的音素串,它的可能性也是通过符合转移概率的乘积取得。

图1(c)
Finally, the automaton in Figure 1(c) encodes a typical left-to-right, three-distribution-HMM struc-ture for one phone, with the labels along a complete path specifying legal strings of acoustic distributions for that phone.
这个图编码了一个典型的从左到右,三分布(音素)HMM结构的音素,这个标签沿着一个完整路径指定音素的发音分布的合法字符串。
These automata consist of a set of states, an ini-tial state, a set of final states (with final weights), and a set of transitions between states. Each transition has a source state, a destination state, a label and a weight. Such automata are called weighted finite-state acceptors (WFSA), since they accept or recog-nize each string that can be read along a path from the start state to a final state. Each accepted string is assigned a weight, namely the accumulated weights along accepting paths for that string, including final weights. An acceptor as a whole represents a set of strings, namely those that it accepts. As a weighted acceptor, it also associates to each accepted string the accumulated weights of their accepting paths.
这些自动机由一组状态组成,一个初始状态,一组终止状态(终止权重)和一组转台之间的转移。每个转移都有一个来源状态一个目标状态,一个标签和一个权重组成。这样的自动机成为加权有限状态转换器(WFST),因为他们能够沿着从开始状态到终止状态的一条路径读取到接收或识别的每个字符串。每个接收的字符串分配一个权重,也就是沿着接收路径字符串的累积权重,包括最终的权重。(我在想上面的概率是乘,这里的权重不知道是加还是乘或是什么?)。作为一个整体代表一组字符串的接收器,即那些它接收的。作为一个加权的接收器,它还将每个接受的字符串与其接受路径的累积权重相关联。
2.2. Weighted Transducers 加权转换器
Our approach uses finite-state transducers, rather than acceptors, to represent the n-gram grammars, pronunciation dictionaries, context-dependency specifications, HMM topology, word, phone or HMM segmentations, lattices and n-best output lists encountered in ASR. The transducer representation provides general methods for combining models and optimizing them, leading to both simple and flexible ASR decoder design。
我们不用接收器而用有限状态转换器表示在自动语音识别(ASR)遇到的n-gram 语法,发音词典,上下文依赖规范,HMM拓扑结构,词,音素或者HMM分段(HMM segmentations),点阵和n-best输出列表。这个转换器代表对于组合模型和优化他们提供一般的方法,主导了简单而又灵活的ASR解码器的设计。
A weighted finite-state transducer (WFST) is quite similar to a weighted acceptor except that it has an input label, an output label and a weight on each of its transitions.
加权有限状态转换器和加权接收器特别的相似,就是多了一个输入标签,输出标签和每个转换的权重。
The examples in Figure 2 encode (a superset of) the information in the WFSAs of Fig-ure 1(a)-(b) as WFSTs. Figure 2(a) represents the same language model as Figure 1(a) by giving each transition identical input and output labels. This adds no new information, but is a convenient way we use often to treat acceptors and transducers uniformly.
图2将图1的WFSA的信息编码成为WFST。通过给每个转换相同的输入输出标签使得图2(a)和图1(a)表示相同的语言模型。虽然没有增加新信息,但是这给了我们使用处理接收器和转换器一致性的便利方法。
图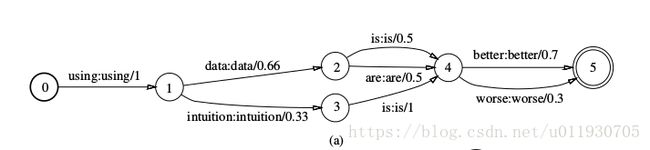 2 (a)
2 (a)
Figure 2(b) represents a toy pronunciation lexi-con as a mapping from phone strings to words in the lexicon, in this example data and dew, with probabilities representing the likelihoods of alternative pronunciations. It transduces a phone string that can be read along a path from the start state to a final state to a word string with a particular weight. The word corresponding to a pronunciation is out-put by the transition that consumes the first phone for that pronunciation. The transitions that consume the remaining phones output no further symbols, indicated by the null symbol ε as the transition’s output label. In general, an ε input label marks a transition that consumes no input, and an # output label marks a transition that produces no output.
图2(b)表示一个作为一个在词典中从音素串到词的映射的简单的发音词典,在这个例子中data和dew,用概率表示选择发音的最大死然度。沿着从开始状态到终止状态的一个特殊权重的词串能够读取出来转换的一个音素串。与一个发音一致的词是通过这个转换消耗第一个发音的音素的输出。这个转换消耗剩余音素不会有更多符号输出,表示通过null符号#作为转换的结果符号。一般来说,一个 ε符号标记了一个转换没有消耗输入,一个 ε符号的输出标签标记的一个转换不会产生输出。
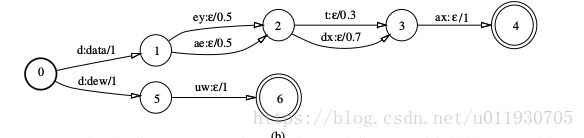
图2 (b)
This transducer has more information than the WFSA in Figure 1(b). Since words are encoded by the output label, it is possible to combine the pronunciation transducers for more than one word without losing word identity.Similarly, HMM structures of the form given in Figure 1(c) can be combined into a single transducer that preserves phone model identity.
通过输出标签编码的词可以组合更多词的发音转换器而不会丢失词的独一性。同样图1(c)这种格式的HMM结构也能组合这种单独转换器保存音素模型的独一性。
This illustrates the key advantage of a transducer over an acceptor: the transducer can
represent a rela-tionship between two levels of representation, for in-stance between phones and words or between HMMs and context-independent phones.
优势是转换器能够保存两个表示级别的相对关系,例如音素和词之间或者HMM和上下文依赖音素之间。
More precisely, a transducer specifies a binary relation between strings: two strings are in the relation when there is a path from an initial to a final state in the transducer that has the first string as the sequence of input labels along the path, and the second string as the sequence of output labels along the path (� symbols are left out in both input and output). In general, this is a relation rather than a function since the same input string might be transduced to different strings along two distinct paths. For a weighted transducer, each string pair is also associated with a weight.
准确的说,一个转换器指定字符串之间的二元关系:当有一个在转换器从一个初始到终止状态的路径,第一个字符串作为这条路经输入标签顺序和第二个字符串作为这条路经的输出标签顺序。一般来说,这是一个关系而不是一个函数,因为相同的输入字符串可能沿着两条不同路径被转换成不同的字符串。对于权重转换器每队字符串都与权重相关联。
We rely on a common set of weighted transducer operations to combine,optimize, search and prune them [Mohri et al., 2000]. Each operation implements a single, well-defined function that has its foundations in the mathematical theory of rational power series [Salomaa and Soittola, 1978, Bers-tel and Reutenauer, 1988,Kuich and Salomaa, 1986]. Many of those operations are the weighted transducer generalizations of classical algorithms for un-weighted acceptors.
用这个加权转换器的操作去组合,优化,查找,修剪。每个操作实现一个单一的,明确定义的函数,这个函数已经在有理幂级数数学理论中建立起来。许多操作都是对非加权接收器的经典算法进行加权转换概括处理。
2.3. Composition 应该是进行模型组合运算
Composition is the transducer operation for combining different levels of representation. For instance, a pronunciation lexicon can be composed with a word-level grammar to produce a phone-to-word transducer whose word strings are restricted to the grammar. A variety of ASR transducer com-bination techniques, both context-independent and context-dependent, are conveniently and efficiently implemented with composition.
转换器运算----组合是结合不同级别的表示。例如一个发声词典能够与词级别的语法结合产生一个音素到词的转换器,这个转换器的词串被语法约束。不同的ASR转换器结合技术(包括上下文不依赖和上下文依赖)既便利又效率的组合实现。
As previously noted, a transducer represents a bi-nary relation between strings. The composition of two transducers represents their relational composi-tion. In particular, the composition T = T 1 ◦ T 2 of two transducers T 1 and T 2 has exactly one path mapping string u to string w for each pair of paths, the first in T 1 mapping u to some string v and the sec-ond in T 2 mapping v to w. The weight of a path in T is computed from the weights of the two corre-sponding paths in T 1 and T 2 with the same operation that computes the weight of a path from the weights of its transitions. If the transition weights represent probabilities, that operation is the product. If instead the weights represent log probabilities or negative log probabilities as is common in ASR for numerical stability, the operation is the sum. More generally, the weight operations for a weighted transducer can be specified by a semiring [Salomaa and Soittola, 1978, Berstel and Reutenauer, 1988, Kuich and Salomaa, 1986],as discussed in more detail in Section 3.
正如之前指出,一个转换器表示一个字符串的二元关系。这两个转换器的组合表示了他们的关系。特别是这个组合T = T 1 ◦ T 2,两个转换器T1和T2有一个正确的路径映射每条路径上的字符u和字符w ,第一步在T1映射字符u到字符v然后在第二步T2映射v到w。在T 的这个路径权重是从T1和T2相同操作两个符合路径的权重计算的,这相同的操作从其转换权重计算路径的权重。如果这个权重表示为概率,这个运算就是乘积。如果在ASR中这个权重换作表示log概率或者负log概率作为数字的稳定性,那么运算就是和的形式。一般来说对于权重转换器的权重运算能够通过一个半环所指定。(需要学习下群和半环)


例如,取B=(0,3),A=(1,2),则B-A=(0,1]U[2,3)
不能写出有限个互不相交的开区间的并,不是半环。
例如:取B=[0,3),A=[1,2),则B-A=[0,1)U[2,3)是两个半开区间的并是半环。