面试整理-Java综合高级篇
Java面试总结
1.你用过哪些集合类?
大公司最喜欢问的Java集合类面试题
40个Java集合面试问题和答案
java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。
java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。
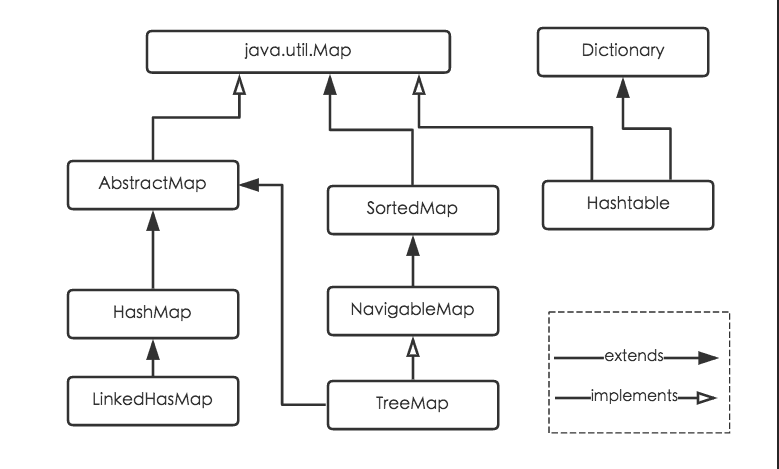
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
ArrayList、HashMap、TreeMap和HashTable类提供对元素的随机访问。
线程安全
Vector
HashTable(不允许插空值)
非线程安全
ArrayList
LinkedList
HashMap(允许插入空值)
HashSet
TreeSet
TreeMap(基于红黑树的Map实现)
2.你说说 arraylist 和 linkedlist 的区别?
ArrayList和LinkedList两者都实现了List接口,但是它们之间有些不同。
(1)ArrayList是由Array所支持的基于一个索引的数据结构,所以它提供对元素的随机访问
(2)与ArrayList相比,在LinkedList中插入、添加和删除一个元素会更快
(3)LinkedList比ArrayList消耗更多的内存,因为LinkedList中的每个节点存储了前后节点的引用
3.HashMap 底层是怎么实现的?还有什么处理哈希冲突的方法?
处理哈希冲突的方法:
解决HashMap一般没有什么特别好的方式,要不扩容重新hash要不优化冲突的链表结构
1.开放定地址法-线性探测法
2.开放定地址法-平方探查法
3.链表解决-可以用红黑树提高查找效率
HashMap简介
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的,但可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。初始容量默认是16。默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本.
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,当链表长度太长(默认超过8)时,链表就转换为红黑树.

Java8系列之重新认识HashMap
功能实现-方法
- 确定哈希桶数组索引位置 :这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
|
|
分析HashMap的put方法
扩容机制:原来的两倍

4.熟悉什么算法,还有说说他们的时间复杂度?
经典排序算法总结与实现

5.ArrayList和Vector的底层代码和他们的增长策略,它们是如何进行扩容的?
ArrayList 默认数组大小是10,其中ensureCapacity扩容,trimToSize容量调整到适中,扩展后数组大小为((原数组长度1.5)与传递参数中较大者.
Vector的扩容,是可以指定扩容因子,同时Vector扩容策略是:1.原来容量的2倍,2.原来容量+扩容参数值。
*详细内容可以配合阅读源码
6.jvm 原理。程序运行区域划分
问:Java运行时数据区域?
回答:包括程序计数器、JVM栈、本地方法栈、方法区、堆
问:方法区里存放什么?
本地方法栈:和jvm栈所发挥的作用类似,区别是jvm栈为jvm执行java方法(字节码)服务,而本地方法栈为jvm使用的native方法服务。
JVM栈:局部变量表、操作数栈、动态链接、方法出口。
方法区:用于存储已被虚拟机加载的类信息,常量、静态变量、即时编译器编译后的代码等。
堆:存放对象实例。
7.minor GC 与 Full GC,分别什么时候会触发? 。分别采用哪种垃圾回收算法?简单介绍算法
GC(或Minor GC):收集 生命周期短的区域(Young area)。
Full GC (或Major GC):收集生命周期短的区域(Young area)和生命周期比较长的区域(Old area)对整个堆进行垃圾收集。
新生代通常存活时间较短基于Copying算法进行回收,将可用内存分为大小相等的两块,每次只使用其中一块;当这一块用完了,就将还活着的对象复制到另一块上,然后把已使用过的内存清理掉。在HotSpot里,考虑到大部分对象存活时间很短将内存分为Eden和两块Survivor,默认比例为8:1:1。代价是存在部分内存空间浪费,适合在新生代使用;
老年代与新生代不同,老年代对象存活的时间比较长、比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并、要么标记出来便于下次进行分配,总之目的就是要减少内存碎片带来的效率损耗。
在执行机制上JVM提供了串行GC(Serial MSC)、并行GC(Parallel MSC)和并发GC(CMS)。
Minor GC ,Full GC 触发条件
-
Minor GC触发条件:当Eden区满时,触发Minor GC。
-
Full GC触发条件:
- (1)调用System.gc时,系统建议执行Full GC,但是不必然执行
- (2)老年代空间不足
- (3)方法去空间不足
- (4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
- (5)由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
8.HashMap 实现原理
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
9.java.util.concurrent 包下使用过哪些
1.阻塞队列 BlockingQueue(
ArrayBlockingQueue,DelayQueue,LinkedBlockingQueue,SynchronousQueue,LinkedTransferQueue,LinkedBlockingDeque)
2.ConcurrentHashMap
3.Semaphore–信号量
4.CountDownLatch–闭锁
5.CyclicBarrier–栅栏
6.Exchanger–交换机
7.Executor->ThreadPoolExecutor,ScheduledThreadPoolExecutor
|
|
8.锁 Lock–
ReentrantLock,ReadWriteLock,Condition,LockSupport
|
|
10.concurrentMap 和 HashMap 区别
1.hashMap可以有null的键,concurrentMap不可以有
2.hashMap是线程不安全的,在多线程的时候需要Collections.synchronizedMap(hashMap),ConcurrentMap使用了重入锁保证线程安全。
3.在删除元素时候,两者的算法不一样。
ConcurrentHashMap和Hashtable主要区别就是围绕着锁的粒度以及如何锁,可以简单理解成把一个大的HashTable分解成多个,形成了锁分离。
11.信号量是什么,怎么使用?volatile关键字是什么?
信号量-semaphore:荷兰著名的计算机科学家Dijkstra 于1965年提出的一个同步机制。是在多线程环境下使用的一种设施, 它负责协调各个线程, 以保证它们能够正确、合理的使用公共资源。
整形信号量:表示共享资源状态,且只能由特殊的原子操作改变整型量。
同步与互斥:同类进程为互斥关系(打印机问题),不同进程为同步关系(消费者生产者)。
使用volatile关键字是解决同步问题的一种有效手段。 java volatile关键字预示着这个变量始终是“存储进入了主存”。更精确的表述就是每一次读一个volatile变量,都会从主存读取,而不是CPU的缓存。同样的道理,每次写一个volatile变量,都是写回主存,而不仅仅是CPU的缓存。
Java 保证volatile关键字保证变量的改变对各个线程是可见的。

12.阻塞队列了解吗?怎么使用

![]()
阻塞队列 (BlockingQueue)是Java util.concurrent包下重要的数据结构,BlockingQueue提供了线程安全的队列访问方式:当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。并发包下很多高级同步类的实现都是基于BlockingQueue实现的。
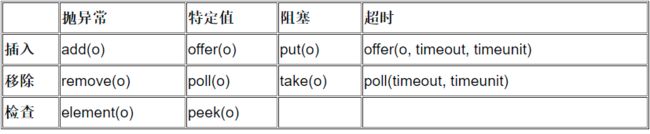

以ArrayBlockingQueue为例,我们先来看看代码:
|
|
从put方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,当被其他线程唤醒时,通过enqueue(e)方法插入元素,最后解锁。
|
|
插入成功后,通过notEmpty唤醒正在等待取元素的线程。
13.Java中的NIO,BIO,AIO分别是什么?
IO的方式通常分为几种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO
1.BIO,同步阻塞式IO,简单理解:一个连接一个线程.BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
在JDK1.4之前,用Java编写网络请求,都是建立一个ServerSocket,然后,客户端建立Socket时就会询问是否有线程可以处理,如果没有,要么等待,要么被拒绝。即:一个连接,要求Server对应一个处理线程。
2.NIO,同步非阻塞IO,简单理解:一个请求一个线程.NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
3.AIO,异步非阻塞IO,简单理解:一个有效请求一个线程.AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
14.类加载机制是怎样的
JVM中类的装载是由ClassLoader和它的子类来实现的,Java ClassLoader是一个重要的Java运行时系统组件。它负责在运行时查找和装入类文件的类。
类加载的五个过程:加载、验证、准备、解析、初始化。
从类被加载到虚拟机内存中开始,到卸御出内存为止,它的整个生命周期分为7个阶段,加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸御(Unloading)。其中验证、准备、解析三个部分统称为连接。

15.什么是幂等性
所谓幂等,简单地说,就是对接口的多次调用所产生的结果和调用一次是一致的。
那么我们为什么需要接口具有幂等性呢?设想一下以下情形:
- 在App中下订单的时候,点击确认之后,没反应,就又点击了几次。在这种情况下,如果无法保证该接口的幂等性,那么将会出现重复下单问题。
- 在接收消息的时候,消息推送重复。如果处理消息的接口无法保证幂等,那么重复消费消息产生的影响可能会非常大。
16.有哪些 JVM 调优经验
Jvm参数总结:http://linfengying.com/?p=2470
内存参数
| 参数 | 作用 | |
|---|---|---|
| -Xmx | 堆大小的最大值。当前主流虚拟机的堆都是可扩展的 | |
| -Xms | 堆大小的最小值。可以设置成和 -Xmx 一样的值 | |
| -Xmn | 新生代的大小。现代虚拟机都是“分代”的,因此堆空间由新生代和老年代组成。新生代增大,相应地老年代就减小。Sun官方推荐新生代占整个堆的3/8 | |
| -Xss | 每个线程的堆栈大小。该值影响一台机器能够创建的线程数上限 | |
| -XX:MaxPermSize= | 永久代的最大值。永久代是 HotSpot 特有的,HotSpot 用永久代来实现方法区 | |
| -XX:PermSize= | 永久代的最小值。可以设置成和 -XX:MaxPermSize 一样的值 | |
| -XX:SurvivorRatio= | Eden 和 Survivor 的比值。基于“复制”的垃圾收集器又会把新生代分为一个 Eden 和两个 Survivor,如果该参数为8,就表示 Eden | 占新生代的80%,而两个 Survivor 各占10%。默认值为8 |
| -XX:PretenureSizeThreshold= | 直接晋升到老年代的对象大小。大于这个参数的对象将直接在老年代分配。默认值为0,表示不启用 | |
| -XX:HandlePromotionFailure= | 是否允许分配担保失败。在 JDK 6 Update 24 后该参数已经失效。 | |
| -XX:MaxTenuringThreshold= | 对象晋升到老年代的年龄。对象每经过一次 Minor GC 后年龄就加1,超过这个值时就进入老年代。默认值为15 | |
| -XX:MaxDirectMemorySize= | 直接内存的最大值。对于频繁使用 nio 的应用,应该显式设置该参数,默认值为0 |
GC参数
| 垃圾收集器 | 参数 | 备注 |
|---|---|---|
| Serial(新生代) | -XX:+UseSerialGC | 虚拟机在 Client 模式下的默认值,打开此开关后,使用 Serial + Serial Old 的收集器组合。Serial 是一个单线程的收集器 |
| ParNew(新生代) | -XX:+UseParNewGC | 强制使用 ParNew,打开此开关后,使用 ParNew + Serial Old 的收集器组合。ParNew 是一个多线程的收集器,也是 server 模式下首选的新生代收集器 |
| -XX:ParallelGCThreads= | 垃圾收集的线程数 | |
| Parallel Scavenge(新生代) | -XX:+UseParallelGC | 虚拟机在 Server 模式下的默认值,打开此开关后,使用 Parallel Scavenge + Serial Old 的收集器组合 |
| -XX:MaxGCPauseMillis= | 单位毫秒,收集器尽可能保证单次内存回收停顿的时间不超过这个值。 | |
| -XX:GCTimeRatio= | 总的用于 gc 的时间占应用程序的百分比,该参数用于控制程序的吞吐量 | |
| -XX:+UseAdaptiveSizePolicy | 设置了这个参数后,就不再需要指定新生代的大小(-Xmn)、 Eden 和 Survisor 的比例(-XX:SurvivorRatio)以及晋升老年代对象的年龄(-XX:PretenureSizeThreshold)了,因为该收集器会根据当前系统的运行情况自动调整。当然前提是先设置好前两个参数。 | |
| Serial Old(老年代) | 无 | Serial Old 是 Serial 的老年代版本,主要用于 Client 模式下的老生代收集,同时也是 CMS 在发生 Concurrent Mode Failure 时的后备方案 |
| Parallel Old(老年代) | -XX:+UseParallelOldGC | 打开此开关后,使用 Parallel Scavenge + Parallel Old 的收集器组合。Parallel Old 是 Parallel Scavenge 的老年代版本,在注重吞吐量和 CPU 资源敏感的场合,可以优先考虑这个组合 |
| CMS(老年代) | -XX:+UseConcMarkSweepGC | 打开此开关后,使用 ParNew + CMS 的收集器组合。 |
| -XX:CMSInitiatingOccupancyFraction= | CMS 收集器在老年代空间被使用多少后触发垃圾收集 | |
| -XX:+UseCMSCompactAtFullCollection | 在完成垃圾收集后是否要进行一次内存碎片整理 | |
| -XX:CMSFullGCsBeforeCompaction= | 在进行若干次垃圾收集后才进行一次内存碎片整理 |
附图:可以配合使用的收集器组合

上面有7中收集器,分为两块,上面为新生代收集器,下面是老年代收集器。如果两个收集器之间存在连线,就说明它们可以搭配使用。
其他参数
| 参数 | 作用 |
|---|---|
| -verbose:class | 打印类加载过程 |
| -XX:+PrintGCDetails | 发生垃圾收集时打印 gc 日志,该参数会自动带上 -verbose:gc 和 -XX:+PrintGC |
| -XX:+PrintGCDateStamps / -XX:+PrintGCTimeStamps | 打印 gc 的触发事件,可以和 -XX:+PrintGC 和 -XX:+PrintGCDetails 混用 |
| -Xloggc: | gc 日志路径 |
| -XX:+HeapDumpOnOutOfMemoryError | 出现 OOM 时 dump 出内存快照用于事后分析 |
| -XX:HeapDumpPath= | 堆转储快照的文件路径 |
17.分布式 CAP 了解吗?
一致性(Consistency)
可用性(Availability)
分区容忍性(Partition tolerance)
18.Java中HashMap的key值要是为类对象则该类需要满足什么条件?
需要同时重写该类的hashCode()方法和它的equals()方法。
当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但 key 不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部——具体说明继续看 addEntry() 方法的说明。
19.java 垃圾回收会出现不可回收的对象吗?怎么解决内存泄露问题?怎么定位问题源?
一般不会有不可回收的对象,因为现在的GC会回收不可达内存。
20.终止线程有几种方式?终止线程标记变量为什么是 valotile 类型?
1.线程正常执行完毕,正常结束
2.监视某些条件,结束线程的不间断运行
3.使用interrupt方法终止线程
在定义exit时,使用了一个Java关键字volatile,这个关键字的目的是使exit同步,也就是说在同一时刻只能由一个线程来修改exit的值
21.用过哪些并发的数据结构? cyclicBarrier 什么功能?信号量作用?数据库读写阻塞怎么解决
- 主要有锁机制,然后基于CAS的concurrent包。
- CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
CountDownLatch的计数器只能使用一次。而CyclicBarrier的计数器可以使用reset() 方法重置。 - Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。很多年以来,我都觉得从字面上很难理解Semaphore所表达的含义,只能把它比作是控制流量的红绿灯,比如XX马路要限制流量,只允许同时有一百辆车在这条路上行使,其他的都必须在路口等待,所以前一百辆车会看到绿灯,可以开进这条马路,后面的车会看到红灯,不能驶入XX马路,但是如果前一百辆中有五辆车已经离开了XX马路,那么后面就允许有5辆车驶入马路,这个例子里说的车就是线程,驶入马路就表示线程在执行,离开马路就表示线程执行完成,看见红灯就表示线程被阻塞,不能执行。
22.关于抽象类和接口的关系
简言之抽象类是一种功能不全的类,接口只是一个抽象方法声明和静态不能被修改的数据的集合,两者都不能被实例化。
从某种意义上说,接口是一种特殊形式的抽象类,在java语言中抽象类表示的是一种继承关系,一个类只能继承继承一个抽象类,而一个类却可以实现多个接口。在许多情况下,接口确实可以代替抽象类,如果你不需要刻意表达属性上的继承的话。
23.堆内存和栈内存的区别
寄存器:JVM内部虚拟寄存器,存取速度非常快,程序不可控制。
栈:保存局部变量的值包括:1.保存基本数据类型的值;2.保存引用变量,即堆区对象的引用(指针)。也可以用来保存加载方法时的帧。
堆:用来存放动态产生的数据,比如new出来的对象。注意创建出来的对象只包含属于各自的成员变量,并不包括成员方法。因为同一个类的对象拥有各自的成员变量,存储在各自的堆中,但是他们共享该类的方法,并不是每创建一个对象就把成员方法复制一次。
常量池:JVM为每个已加载的类型维护一个常量池,常量池就是这个类型用到的常量的一个有序集合。包括直接常量(基本类型,String)和对其他类型、方法、字段的符号引用(1)。池中的数据和数组一样通过索引访问。由于常量池包含了一个类型所有的对其他类型、方法、字段的符号引用,所以常量池在Java的动态链接中起了核心作用。常量池存在于堆中。
代码段:用来存放从硬盘上读取的源程序代码。
数据段:用来存放static修饰的静态成员(在java中static的作用就是说明该变量,方法,代码块是属于类的还是属于实例的)。

24.关于Java文件的内部类的解释?匿名内部类是什么?如何访问在其外面定义的变量?
java中的内部类总结
静态内部类不能访问外部类非静态的成员###25.关于重载和重写的区别
重载是overload,是一个类中同方法名的不同具体实现。然后重写是override,是子类重写父类中的方法。
26.String、StringBuffer与StringBuilder之间区别
1.三者在执行速度方面的比较:StringBuilder > StringBuffer > String
String:字符串常量
StringBuffer:字符串变量
StringBuilder:字符串变量2.StringBuilder:线程非安全的,StringBuffer:线程安全的
对于三者使用的总结:
1.如果要操作少量的数据用 = String
2.单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
3.多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
27.运行时异常与一般异常有何异同?常见异常
Java提供了两类主要的异常:runtime exception和checked exception
常见异常:NullPointerException、IndexOutOfBoundsException、ClassNotFoundException,IllegalArgumentException,ClassCastException(数据类型转换异常)
###28.error和exception有什么区别?
error 表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。
###29.Java异常处理机制
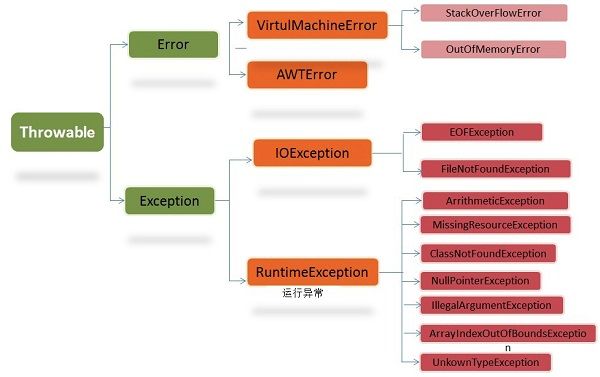
1.捕获异常:try、catch 和 finally
2.抛出异常
2.1. throws抛出异常
|
|
30.java中有几种方法可以实现一个线程?
Java多线程学习(吐血超详细总结)
40个Java多线程问题总结
1.class Thread1 extends Thread{},然后重写run方法
2.class Thread2 implements Runnable{},然后重写run方法
3.class Thread3 implements Callable{},然后new FutureTask(thread3),再用new Thread(future)封装。
|
|
如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
31.Java中常用的类,包,接口。
class: ‘Date’,’System’,’Calender’,’Math’,’ArrayList’,’HashMap’
package: ‘java.lang’,’java.util’,’java.io’,’java.sql’,’java.net’
interface: ‘Collection’,’Map’,’List’,’Runnable’,’Callable’
32.java在处理线程同步时,常用方法有:
1、synchronized关键字。
2、Lock显示加锁。
3、信号量Semaphore。
4、CAS算法
5、concurrent包
33.Spring IOC/AOP?
回答了IOC/DI、AOP的概念。
AOP(Aspect-OrientedProgramming,面向方面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善。
OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。
也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。
对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(cross-cutting)代码,
在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
依赖注入(Dependency Injection)和控制反转(Inversion of Control)是同一个概念。
当某个角色(可能是一个Java实例,调用者)需要另一个角色(另一个Java实例,被调用者)的协助时,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。
但在Spring里,创建被调用者的工作不再由调用者来完成,因此称为控制反转;创建被调用者 实例的工作通常由Spring容器来完成,然后注入调用者,因此也称为依赖注入。
不管是依赖注入,还是控制反转,都说明Spring采用动态、灵活的方式来管理各种对象。对象与对象之间的具体实现互相透明。
在理解依赖注入之前,看如下这个问题在各种社会形态里如何解决:一个人(Java实例,调用者)需要一把斧子(Java实例,被调用者)。
34.对JVM的垃圾回收的认识?
垃圾回收器的作用是查找和回收(清理)无用的对象。以便让JVM更有效的使用内存。
35.进程与线程的区别,及其通信方式
线程与进程的区别及其通信方式
区别
1.一个程序至少有一个进程,一个进程至少有一个线程.
2.进程在执行过程中拥有独立的内存单元,而多个线程共享内存
3.线程是进程的一个实体,是CPU调度和分派的基本单位
- 进程间通信
|
|
36.JVM如何GC,新生代,老年代,持久代,都存储哪些东西?
JVM的GC算法有:引用计数器算法,根搜索方法
新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
持久代主要存放的是Java类的类信息
37.JVM分为哪些区,每一个区干嘛的?
问:Java运行时数据区域?
回答:包括程序计数器、JVM栈、本地方法栈、方法区、堆
问:方法区里存放什么?
本地方法栈:和jvm栈所发挥的作用类似,区别是jvm栈为jvm执行java方法(字节码)服务,而本地方法栈为jvm使用的native方法服务。
JVM栈:局部变量表、操作数栈、动态链接、方法出口。
方法区:用于存储已被虚拟机加载的类信息,常量、静态变量、即时编译器编译后的代码等。
堆:存放对象实例。
38.GC用的引用可达性分析算法中,哪些对象可作为GC Roots对象?
- 虚拟机栈(栈帧中的本地变量表)中引用的对象;
- 方法区中类静态属性引用的对象;
- 方法区中常量引用的对象;
- 本地方法栈中JNI(即一般说的Native方法)引用的对象
39.用什么工具调试程序?jmap、jstack,JConsole,用过吗?
虚拟机性能监控与调优实战–博客
40.线程池用过吗?
线程池–并发编程网 - ifeve.com
线程池(Thread Pool)对于限制应用程序中同一时刻运行的线程数很有用。因为每启动一个新线程都会有相应的性能开销,每个线程都需要给栈分配一些内存等等。
我们可以把并发执行的任务传递给一个线程池,来替代为每个并发执行的任务都启动一个新的线程。只要池里有空闲的线程,任务就会分配给一个线程执行。在线程池的内部,任务被插入一个阻塞队列(Blocking Queue ),线程池里的线程会去取这个队列里的任务。当一个新任务插入队列时,一个空闲线程就会成功的从队列中取出任务并且执行它。
41.操作系统如何进行分页调度?–要考LRU
1.最讲置换原则-OPT
2.先进先出原则-FIFO
3.最近最少使用置换算法-LRU
4.时钟置换算法
|
|
42.讲讲LinkedHashMap
Java8 LinkedHashMap工作原理及实现
LinkedHashMap是通过哈希表和链表实现的,它通过维护一个链表来保证对哈希表迭代时的有序性,而这个有序是指键值对插入的顺序。
LinkedHashMap 的大致实现如下图所示,当然链表和哈希表中相同的键值对都是指向同一个对象,这里把它们分开来画只是为了呈现出比较清晰的结构。
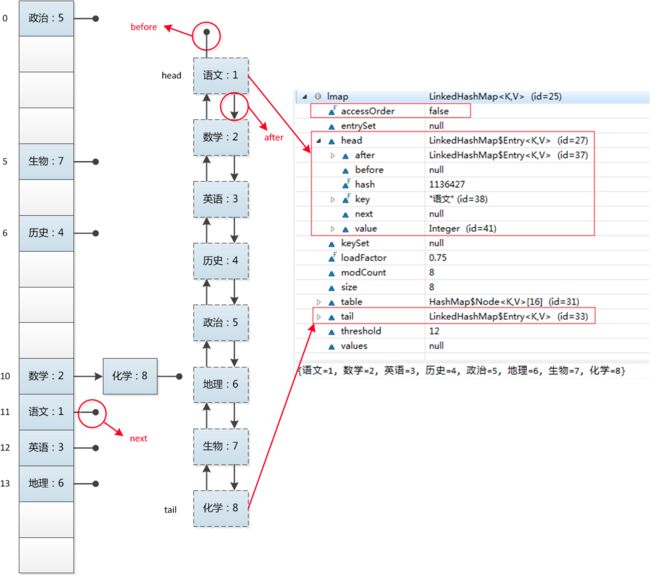
LinkedHashMap是Hash表和链表的实现,并且依靠着双向链表保证了迭代顺序是插入的顺序。
三个重点实现的函数
在HashMap中提到了下面的定义:
|
|
LinkedHashMap继承于HashMap,因此也重新实现了这3个函数,顾名思义这三个函数的作用分别是:节点访问后、节点插入后、节点移除后做一些事情。
43.线程同步与阻塞的关系?同步一定阻塞吗?阻塞一定同步吗?,同步和异步有什么区别?
同步与非同步:主要是保证互斥的访问临界资源的情况
阻塞与非阻塞:主要是从 CPU 的消耗上来说的
44.int与Integer的区别,分别什么场合使用
|
|
int是基本数据类型,Integer是包装类,类似HashMap这样的结构必须使用包装类,因为包装类继承自Object,都需要实现HashCode,所以可以使用在HashMap这类数据结构中。
45.RPC的详细过程
RPC主要的重点有:
动态代理,主要是invoke反射原理
序列化,使用Thrift的效率高
通信方式,使用Netty的NIO能提高效率
服务发现,使用zookeeper可以实现
- 1)服务消费方(client)调用以本地调用方式调用服务;
- 2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
- 3)client stub找到服务地址,并将消息发送到服务端;
- 4)server stub收到消息后进行解码;
- 5)server stub根据解码结果调用本地的服务;
- 6)本地服务执行并将结果返回给server stub;
- 7)server stub将返回结果打包成消息并发送至消费方;
- 8)client stub接收到消息,并进行解码;
- 9)服务消费方得到最终结果。
- 转载技术博客:https://nezha.github.io